Learning Protein Structure-Function Relationships through Knowledge-guided Representation Decomposition
Pith reviewed 2026-06-30 22:18 UTC · model grok-4.3
The pith
ProtDiS decomposes pretrained protein embeddings into biologically grounded dimensions via knowledge guidance and the information bottleneck principle.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
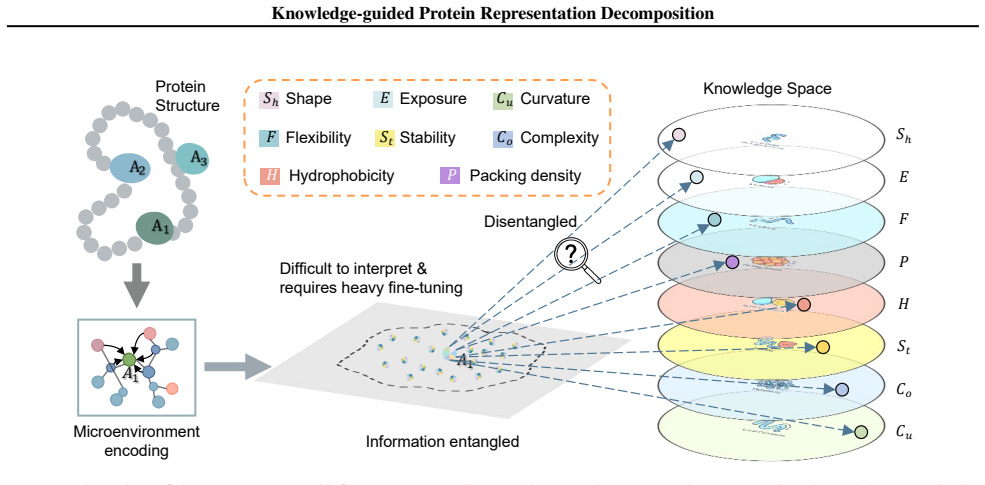
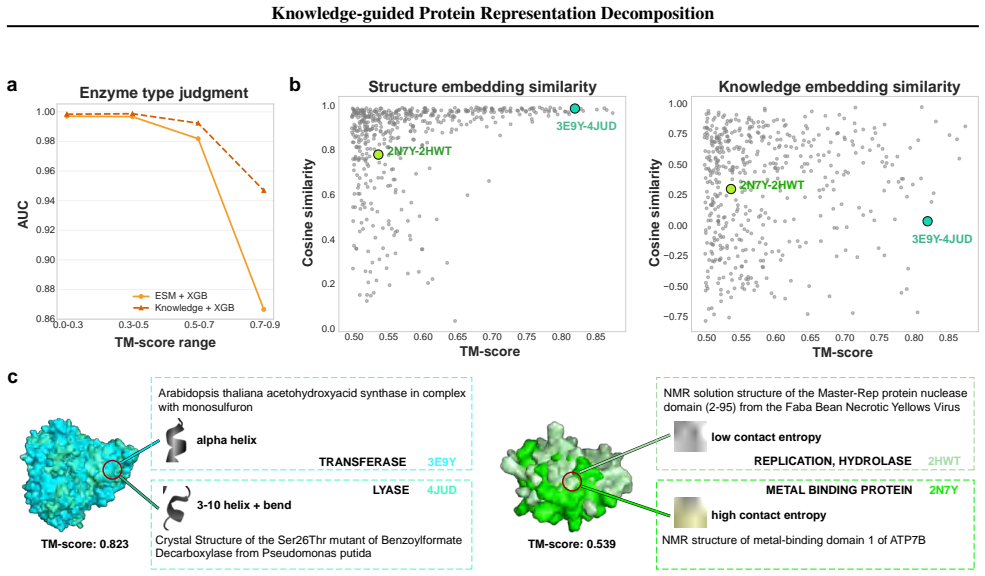
ProtDiS decomposes pretrained protein micro-environment embeddings into biologically grounded and task-relevant dimensions, yielding structural features that are more specific, independent, and information-efficient, and achieving consistent improvements across twelve downstream tasks, with the largest gains under structure-based splits.
What carries the argument
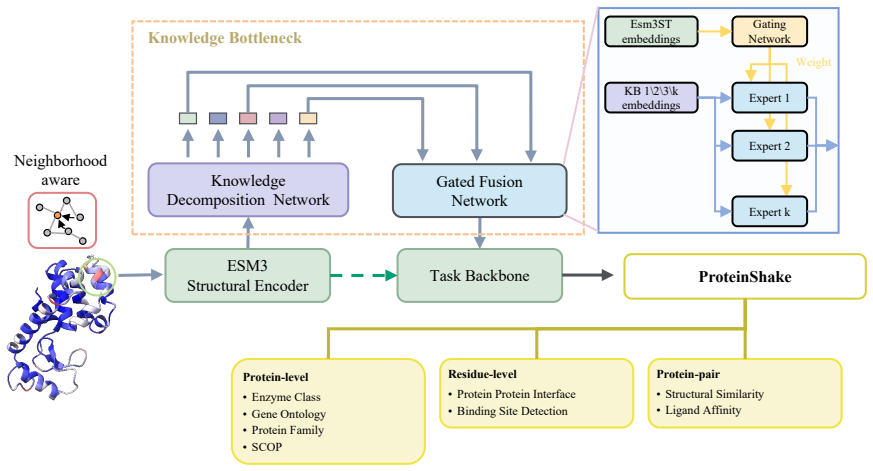
ProtDiS, the knowledge-guided decomposition framework that applies the information bottleneck principle to separate entangled signals in protein embeddings into independent dimensions.
Load-bearing premise
That the information bottleneck principle combined with knowledge guidance can reliably separate entangled signals in pretrained embeddings into independent biologically meaningful dimensions without discarding task-critical information or introducing artifacts.
What would settle it
Observing no improvement or outright worse performance on structure-based splits across the twelve downstream protein tasks after applying the decomposition would falsify the central claim.
Figures

read the original abstract
Proteins encode diverse functions within complex three-dimensional structures, yet most deep learning representations remain highly entangled, obscuring the biophysical signals that underlie function. Here we introduce ProtDiS, a knowledge-guided framework that decomposes pretrained protein micro-environment embeddings into biologically grounded and task-relevant dimensions. Inspired by the information bottleneck principle, ProtDiS learns representations that balance informativeness and compression, yielding structural features that are more specific, independent, and information-efficient, and achieving consistent improvements across twelve downstream tasks, with the largest gains under structure-based splits. Protein- and residue-level analyses further show that ProtDiS differentiates proteins with similar folds but divergent functions and captures fine-grained biophysical signals critical. These findings suggest that knowledge-guided decomposition provides a general and interpretable approach for structuring latent spaces in protein structural modeling. The source code and implementation details are publicly available at https://github.com/AI-HPC-Research-Team/ProtDiS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ProtDiS, a knowledge-guided framework that decomposes pretrained protein micro-environment embeddings via the information bottleneck principle to produce more specific, independent, and information-efficient structural features. It claims consistent performance gains across twelve downstream tasks (largest under structure-based splits), improved differentiation of similar-fold proteins with divergent functions, and capture of fine-grained biophysical signals, with code released publicly.
Significance. If the reported gains hold under the described splits and controls, the work offers a general, interpretable method for disentangling entangled pretrained embeddings in protein modeling. The emphasis on structure-based evaluation and residue-level analysis strengthens the case for biological grounding; public code supports reproducibility.
minor comments (4)
- The abstract states 'consistent improvements across twelve downstream tasks' without any numerical values, baselines, or error bars; move a concise quantitative summary (e.g., average Δ and range) into the abstract for immediate clarity.
- Section describing the knowledge-guidance term (likely §3.2 or Eq. (3)–(5)) should explicitly state how the auxiliary supervision is constructed and whether it is task-specific or held fixed across the twelve tasks.
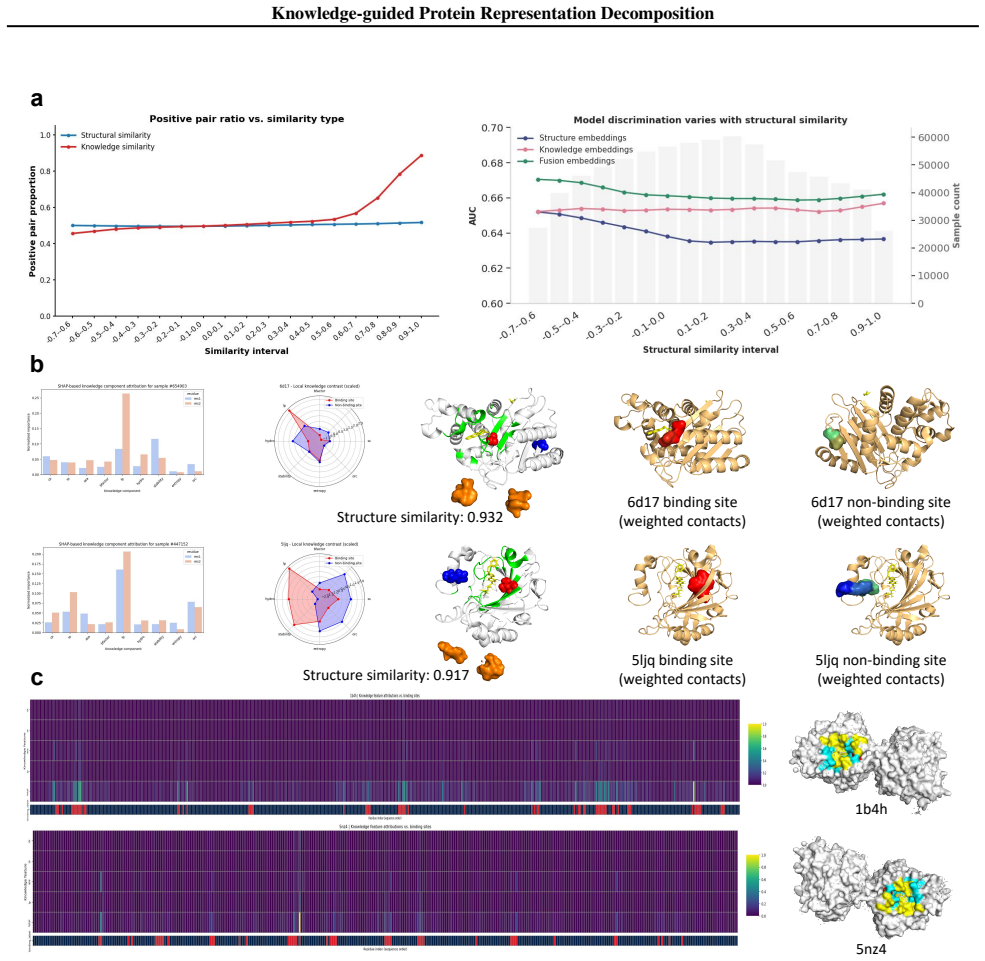
- Figure 3 or the corresponding results table: clarify whether the structure-based split protocol (sequence identity <30 % or TM-score threshold) is applied uniformly to all twelve tasks or only to a subset.
- The information-bottleneck trade-off hyperparameter is listed as a free parameter in the axiom ledger; add a short sensitivity analysis (one paragraph or supplementary table) showing that performance remains above baselines across a reasonable range of the trade-off weight.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of ProtDiS, recognition of the gains under structure-based splits, and recommendation for minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity detected
full rationale
The provided abstract and context describe ProtDiS as a knowledge-guided decomposition framework inspired by the information bottleneck principle, applied to pretrained embeddings for downstream tasks. No equations, self-citations, fitted parameters renamed as predictions, or uniqueness theorems are quoted that reduce the central claim to its inputs by construction. The method is presented as a standard application of existing principles with reported empirical gains under structure-based splits, and code is released, making the derivation self-contained against external benchmarks without load-bearing circular steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- informativeness-compression trade-off
axioms (1)
- domain assumption Pretrained protein micro-environment embeddings contain entangled representations that can be decomposed into independent biologically grounded dimensions
Reference graph
Works this paper leans on
-
[1]
Baek, M., DiMaio, F., Anishchenko, I., Dauparas, J., Ovchinnikov, S., Lee, G
URL https://proceedings.mlr.press/ v267/adams25a.html. Baek, M., DiMaio, F., Anishchenko, I., Dauparas, J., Ovchinnikov, S., Lee, G. R., Wang, J., Cong, Q., Kinch, L. N., Schaeffer, R. D., et al. Accurate prediction of pro- tein structures and interactions using a three-track neural network.Science, 373(6557):871–876, 2021. Barrio-Hernandez, I., Yeo, J., ...
-
[2]
Kucera, T., Oliver, C., Chen, D., and Borgwardt, K
PMLR, 2018. Kucera, T., Oliver, C., Chen, D., and Borgwardt, K. Pro- teinshake: Building datasets and benchmarks for deep learning on protein structures.Advances in Neural Infor- mation Processing Systems, 36:58277–58289, 2023. Kyte, J. and Doolittle, R. F. A simple method for display- ing the hydropathic character of a protein.Journal of molecular biolog...
-
[3]
URL https://openreview.net/forum? id=to3qCB3tOh9. OpenReview. Zhao, S., Song, J., and Ermon, S. Infovae: Balancing learn- ing and inference in variational autoencoders.Proceed- ings of the AAAI Conference on Artificial Intelligence, 33(01):5885–5892, Jul. 2019. doi: 10.1609/aaai.v33i01. 33015885. URL https://ojs.aaai.org/index. php/AAAI/article/view/4538....
-
[4]
This design deliberately avoids scale-mismatch issues that would arise from integrating macroscopic (e.g., global fold classes) or microscopic (e.g., quantum mechanical) labels
Scale Consistency and Functional Relevance:The chosen dimensions are strictly constrained to a unified, residue-level scale, encompassing local geometric and physicochemical properties. This design deliberately avoids scale-mismatch issues that would arise from integrating macroscopic (e.g., global fold classes) or microscopic (e.g., quantum mechanical) l...
-
[5]
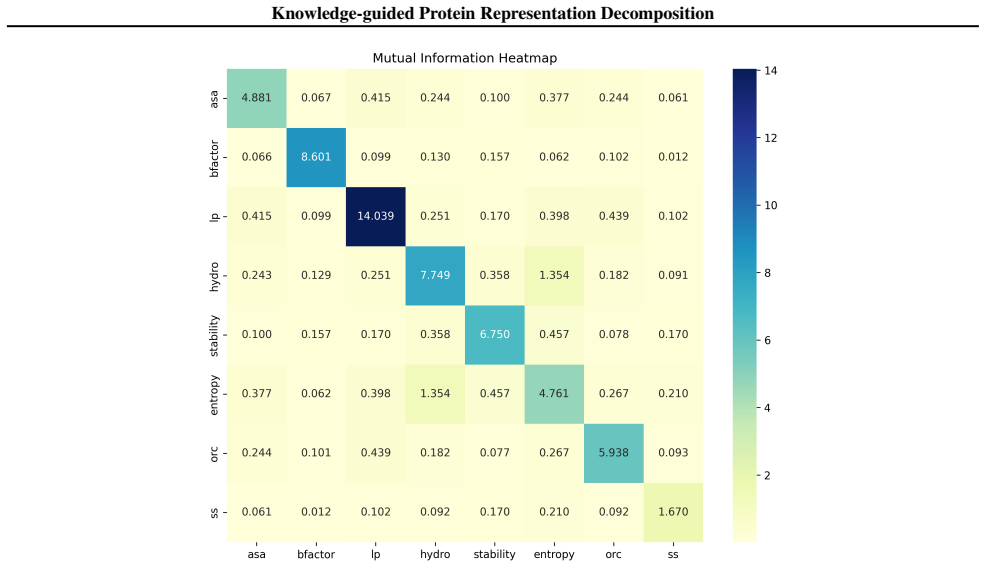
As illustrated in Figure 6, the off-diagonal MI values remain predominantly low (for instance, the MI between Secondary Structure and other labels is 0.012∼0.210 )
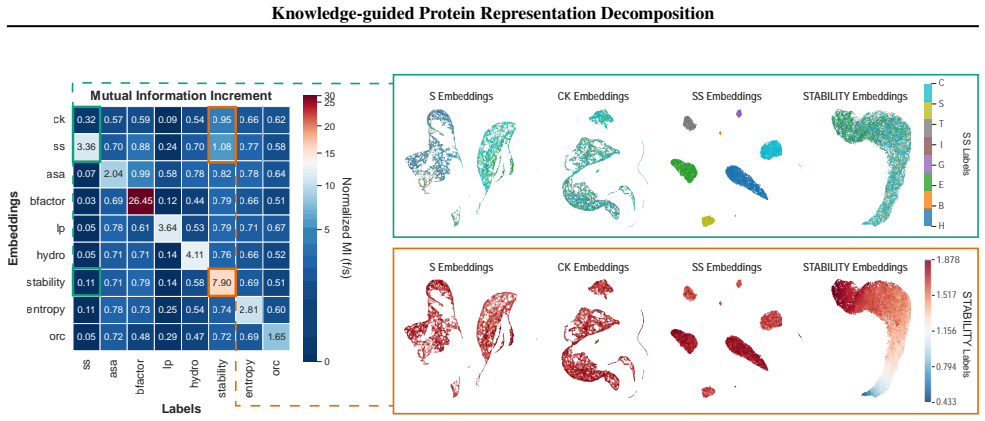
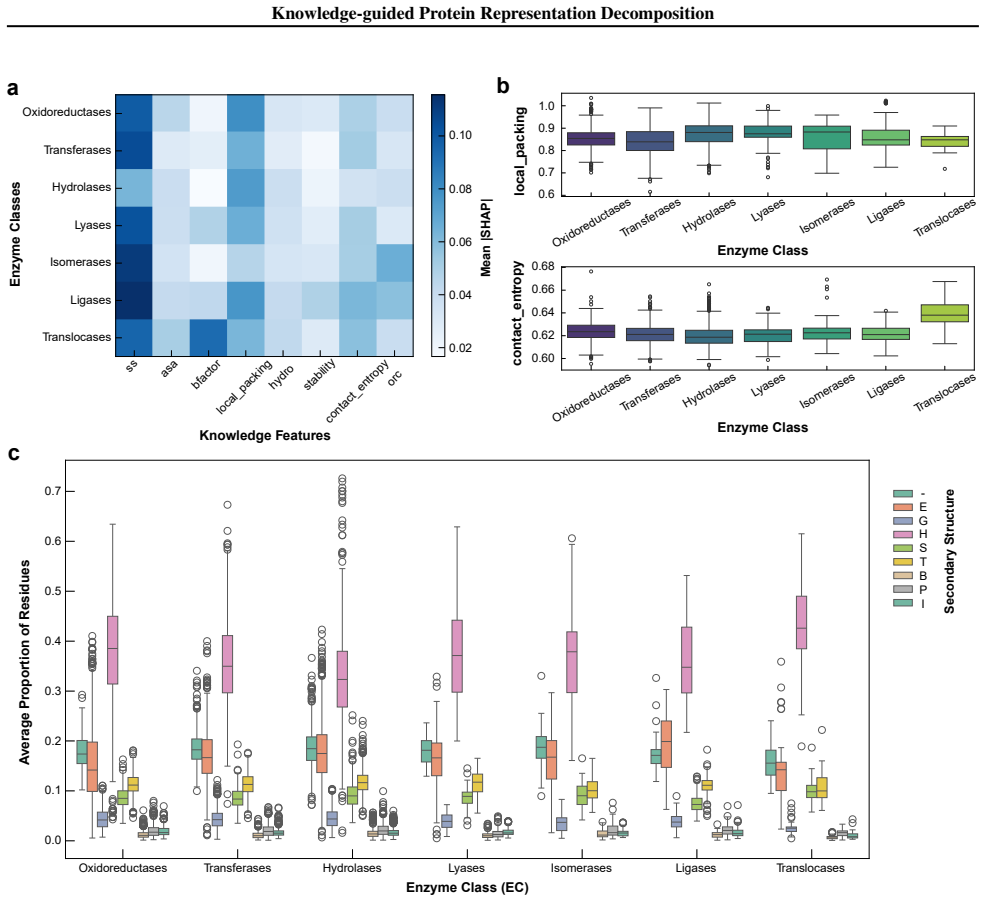
Relative Independence:To ensure that the selected dimensions provide distinct supervisory signals, we evaluated their relative independence by computing the Mutual Information (MI) among all eight labels. As illustrated in Figure 6, the off-diagonal MI values remain predominantly low (for instance, the MI between Secondary Structure and other labels is 0....
-
[6]
common knowledge
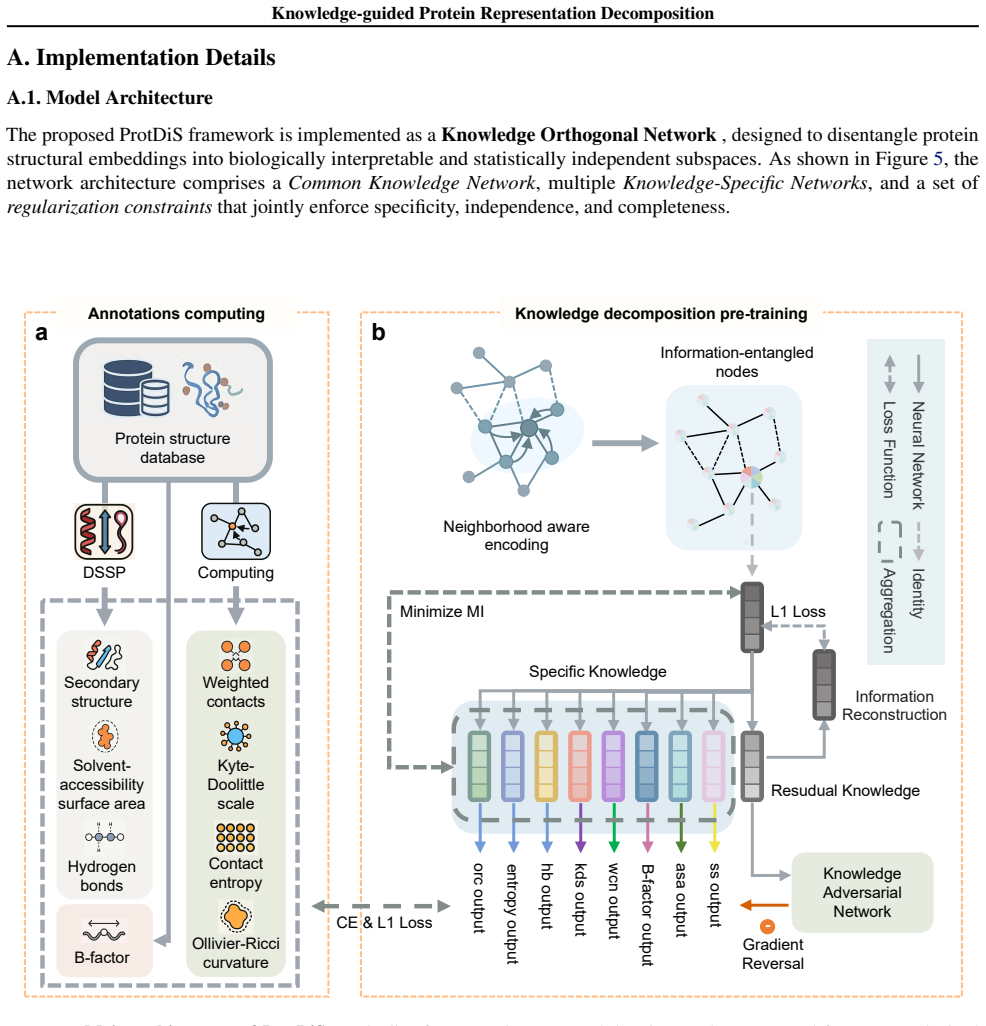
Computational Feasibility:Given the massive scale of the requisite pretraining datasets (encompassing structures from both the PDB and AlphaFoldDB), the empirical viability of our framework heavily relies on highly scalable supervision. The selected eight dimensions can be deterministically and rapidly computed using standardized algorithms (e.g., DSSP) w...
2023
-
[7]
As shown in Figure 15, in the absence of Lred, the decoupled channels suffer from severe non-linear feature collapse
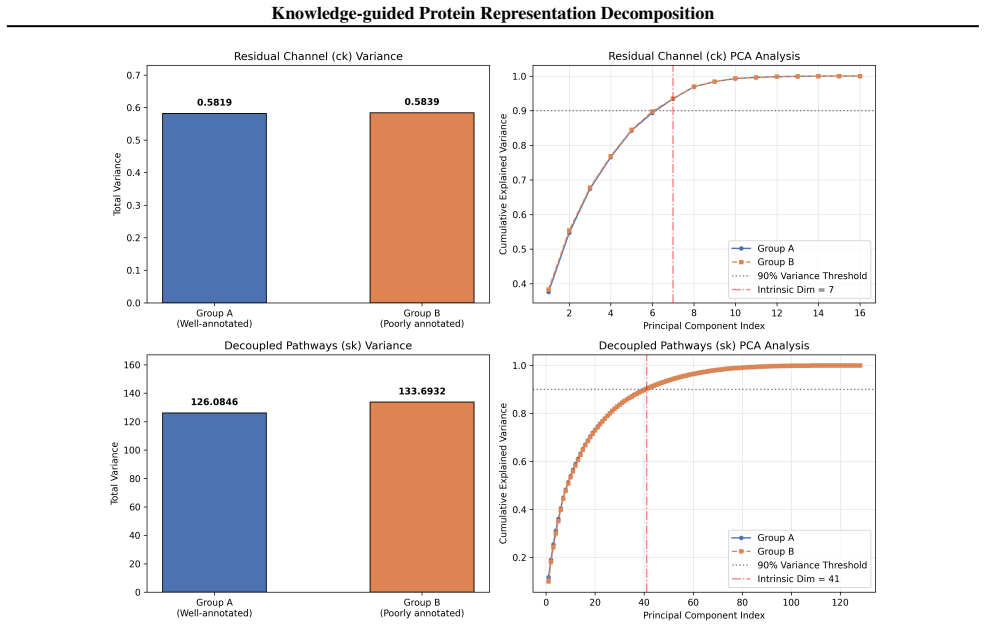
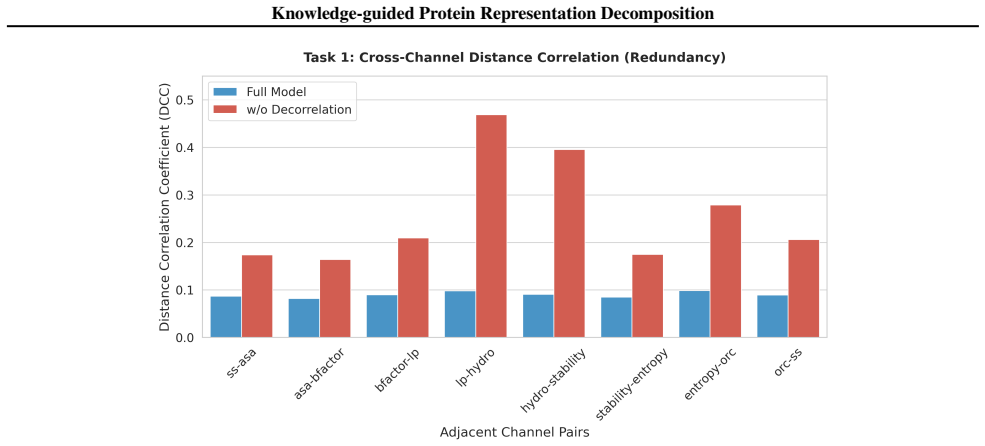
Necessity of Cross-Channel Decorrelation ( Lred)We evaluated the impact of the decorrelation penalty using the inter-channel Distance Correlation (DCC). As shown in Figure 15, in the absence of Lred, the decoupled channels suffer from severe non-linear feature collapse. For instance, the DCC between Local Packing and Hydrophobicity surges to 0.4688. Conve...
-
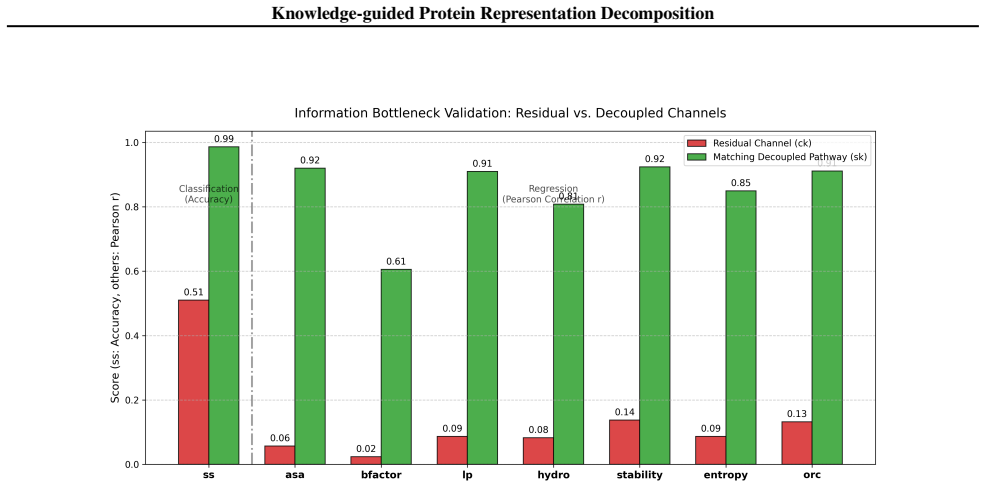
[8]
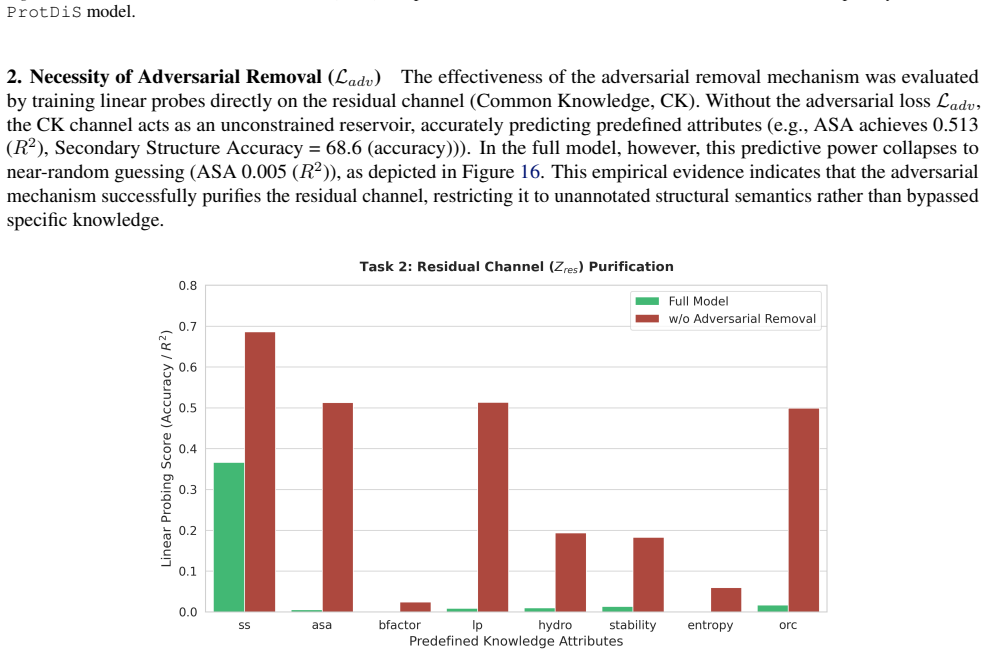
Necessity of Adversarial Removal ( Ladv)The effectiveness of the adversarial removal mechanism was evaluated by training linear probes directly on the residual channel (Common Knowledge, CK). Without the adversarial lossLadv, the CK channel acts as an unconstrained reservoir, accurately predicting predefined attributes (e.g., ASA achieves 0.513 (R2), Seco...
-
[9]
Removing the KL bottleneck LKL allows the model to overfit by memorizing high-frequency structural noise
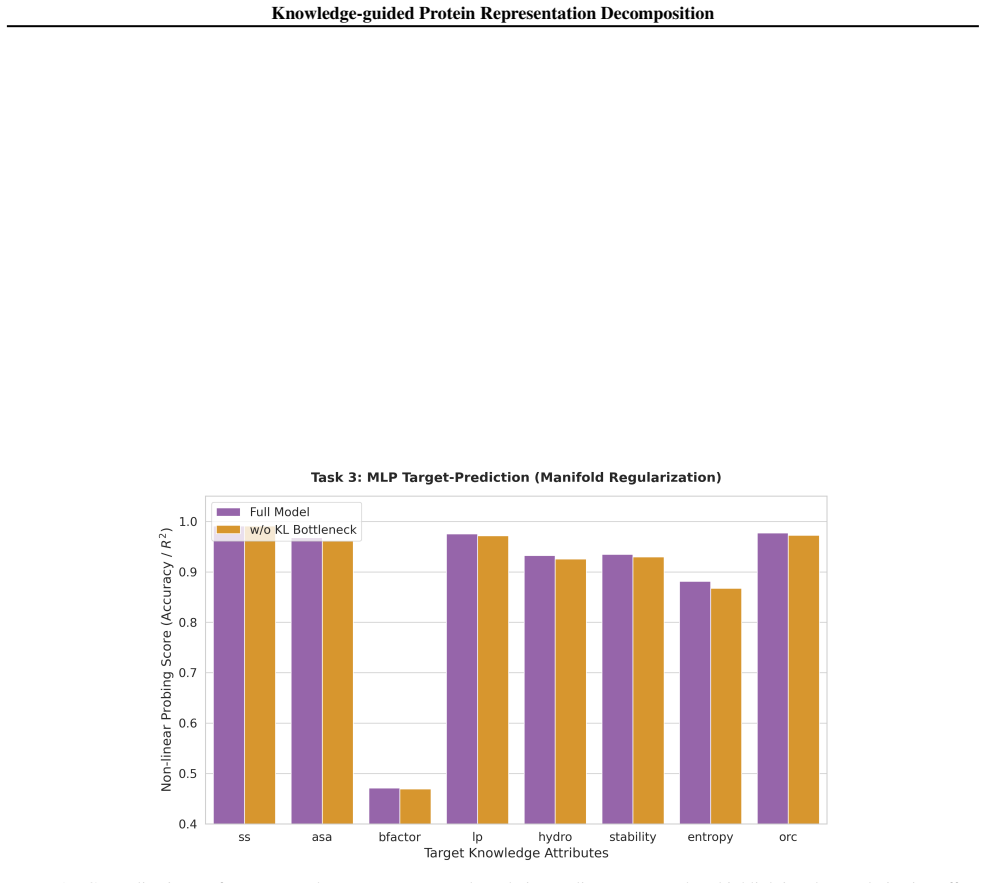
Role of the KL Bottleneck ( LKL)The regularization effect of the KL divergence bottleneck was assessed using a non-linear MLP probe on the unseen test set. Removing the KL bottleneck LKL allows the model to overfit by memorizing high-frequency structural noise. The introduction of LKL acts as a crucial manifold regularizer, compelling the model to learn a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.