Partner-Aware Hierarchical Skill Discovery for Robust Human-AI Collaboration
Pith reviewed 2026-06-30 13:59 UTC · model grok-4.3
The pith
PASD conditions hierarchical skills on partner behavior via contrastive rewards to enable robust adaptation in human-AI collaboration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
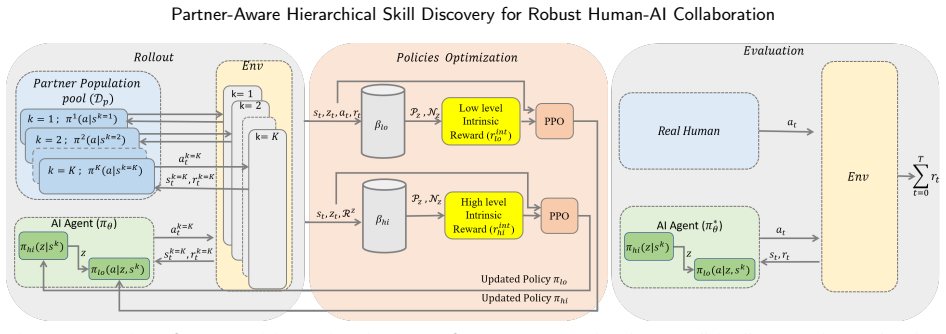
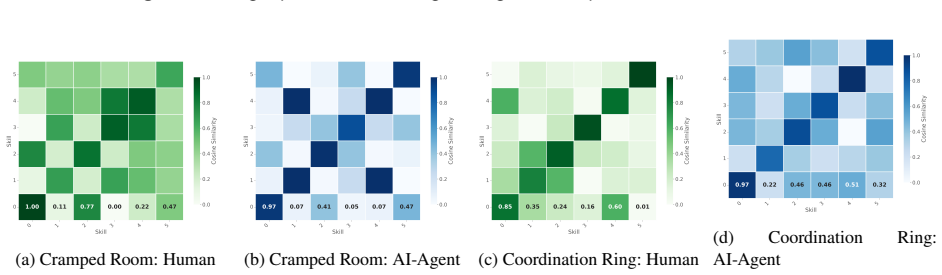
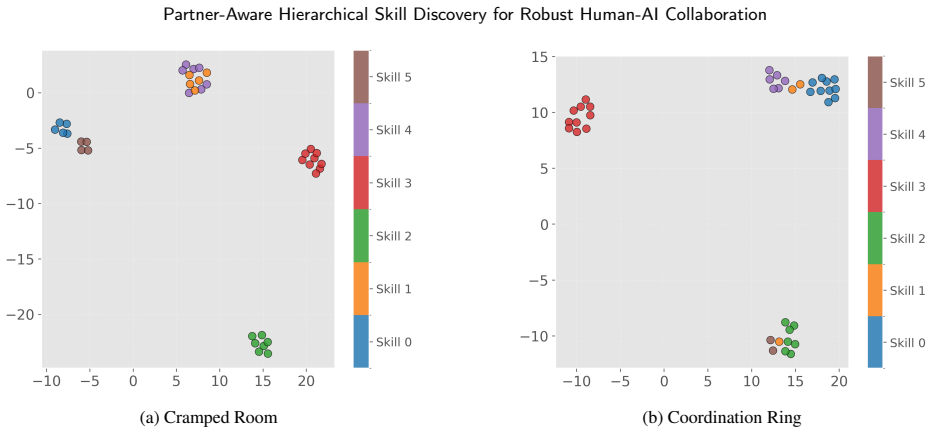
PASD is a DHRL framework that learns skills conditioned on partner behavior. It introduces a contrastive intrinsic reward to capture patterns emerging from partner interactions, aligning skill representations across similar partners while maintaining discriminability across diverse strategies. By structuring the skill space based on partner interactions, this approach mitigates shortcut learning and promotes behavioral consistency, enabling robust and adaptive coordination.
What carries the argument
The contrastive intrinsic reward that conditions skill learning on patterns from partner interactions.
If this is right
- Skills become transferable across a wide range of partner behaviors without retraining.
- Agents achieve more consistent coordination with partners of varying skill levels and play styles.
- Shortcut learning is reduced in hierarchical RL for multi-agent collaboration tasks.
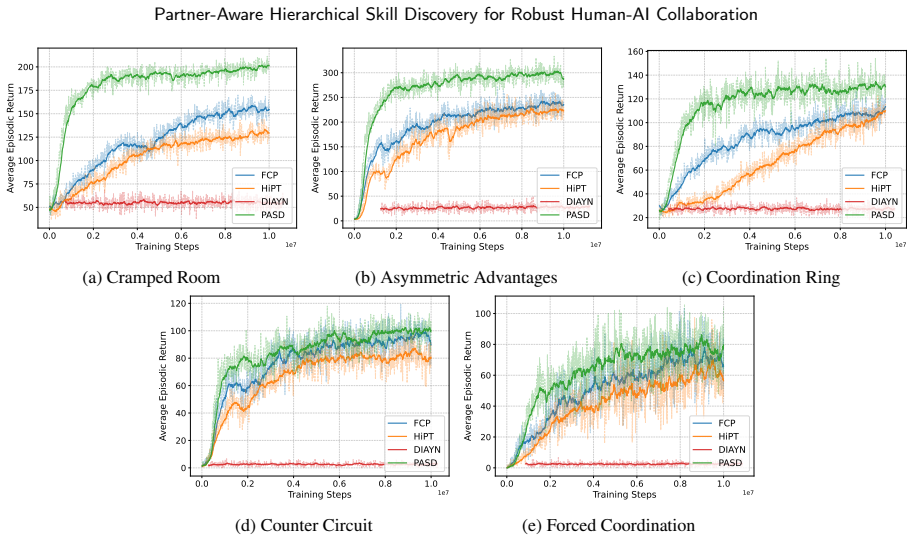
- Performance improves over standard population-based and hierarchical methods in benchmarks like Overcooked-AI.
Where Pith is reading between the lines
- The approach may extend to collaborative domains beyond cooking simulations, such as shared navigation or joint planning.
- Integrating partner modeling earlier in the hierarchy could further reduce reliance on large training populations.
- Real-time human testing beyond proxy models would provide a direct check on transfer to live interactions.
Load-bearing premise
Structuring the skill space based on partner interactions with a contrastive intrinsic reward will mitigate shortcut learning and enable robust adaptation to novel partners.
What would settle it
A test showing that PASD performs no better than baselines or introduces new coordination failures when facing partners with behaviors outside the training distribution would falsify the generalization claim.
Figures

read the original abstract
Multi-agent collaboration, especially in human-AI teaming, requires agents that can adapt to novel partners with diverse and dynamic behaviors. Conventional Deep Hierarchical Reinforcement Learning (DHRL) methods focus on agent-centric rewards and overlook partner behavior, leading to shortcut learning, where skills exploit spurious information instead of adapting to partners' dynamic behaviors. This limitation undermines agents' ability to adapt and coordinate effectively with novel partners. We introduce Partner-Aware Skill Discovery (PASD), a DHRL framework that learns skills conditioned on partner behavior. PASD introduces a contrastive intrinsic reward to capture patterns emerging from partner interactions, aligning skill representations across similar partners while maintaining discriminability across diverse strategies. By structuring the skill space based on partner interactions, this approach mitigates shortcut learning and promotes behavioral consistency, enabling robust and adaptive coordination. We extensively evaluate PASD in the Overcooked-AI benchmark with a diverse population of partners characterized by varying skill levels and play styles. We further evaluate the approach with human proxy models trained from human-human gameplay trajectories. PASD consistently outperforms existing population-based and hierarchical baselines, demonstrating transferable skill learning that generalizes across a wide range of partner behaviors. Analysis of learned skill representations shows that PASD adapts effectively to diverse partner behaviors, highlighting its robustness in human-AI collaboration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Partner-Aware Skill Discovery (PASD), a deep hierarchical reinforcement learning (DHRL) framework for multi-agent collaboration in human-AI teaming. PASD conditions skills on partner behavior via a contrastive intrinsic reward that aligns representations across similar partners while preserving discriminability, with the goal of mitigating shortcut learning in conventional DHRL. The approach is evaluated on the Overcooked-AI benchmark using a diverse population of partners with varying skill levels and play styles, plus human proxy models derived from human-human trajectories; the central claim is that PASD consistently outperforms population-based and hierarchical baselines while enabling transferable, generalizable skill learning across novel partner behaviors.
Significance. If the empirical results and generalization claims hold under rigorous evaluation, the work could meaningfully advance robust human-AI collaboration by demonstrating how partner-aware structuring of the skill space addresses limitations of agent-centric rewards. The contrastive reward mechanism for capturing interaction patterns offers a concrete direction for improving behavioral consistency and adaptation in partially observable multi-agent settings.
major comments (1)
- [Abstract] Abstract: the central claim that PASD 'consistently outperforms existing population-based and hierarchical baselines' and 'demonstrates transferable skill learning that generalizes across a wide range of partner behaviors' is asserted without any reported metrics, statistical tests, ablation studies, or experimental details; this renders the soundness of the primary empirical contribution unverifiable from the provided text.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We address the single major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that PASD 'consistently outperforms existing population-based and hierarchical baselines' and 'demonstrates transferable skill learning that generalizes across a wide range of partner behaviors' is asserted without any reported metrics, statistical tests, ablation studies, or experimental details; this renders the soundness of the primary empirical contribution unverifiable from the provided text.
Authors: We agree that the abstract would be strengthened by including concrete quantitative support for the claims. The full manuscript reports extensive results, ablations, and statistical comparisons in the experimental sections, but the abstract itself summarizes without metrics. In the revision we will update the abstract to report key metrics (e.g., mean rewards with standard errors on the Overcooked-AI tasks) and note the statistical significance of the outperformance, while preserving conciseness. revision: yes
Circularity Check
No significant circularity; empirical framework only
full rationale
The paper presents PASD as an empirical DHRL framework evaluated on Overcooked-AI and human proxy models, with claims of outperformance resting on experimental results rather than any derivation chain, equations, or parameter reductions. No self-definitional steps, fitted inputs called predictions, or load-bearing self-citations appear in the provided text; the contrastive reward and skill structuring are described as design choices validated by generalization tests, not tautological by construction. The central claim is falsifiable via benchmarks and does not reduce to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
team player
GaryKlein,DavidD.Woods,JeffreyM.Bradshaw,RobertR.Hoffman,andPaulJ.Feltovich. Tenchallengesformakingautomationa"team player" in joint human-agent activity.IEEE Intell. Syst., 19:91–95, 2004
2004
-
[2]
Rachid Alami, Aurélie Clodic, Vincent Montreuil, Emrah Akin Sisbot, and R. Chatila. Toward human-aware robot task planning. InAAAI Spring Symposium: To Boldly Go Where No Human-Robot Team Has Gone Before, 2006
2006
-
[3]
The hanabi challenge: A new frontier for ai research.Artificial Intelligence, 280:103216, 2020
Nolan Bard, Jakob N Foerster, Sarath Chandar, Neil Burch, Marc Lanctot, H Francis Song, Emilio Parisotto, Vincent Dumoulin, Subhodeep Moitra, Edward Hughes, et al. The hanabi challenge: A new frontier for ai research.Artificial Intelligence, 280:103216, 2020
2020
-
[4]
Towardsplaying full moba games with deep reinforcement learning.Advances in Neural Information Processing Systems, 33:621–632, 2020
DehengYe,GuibinChen,WenZhang,ShengChen,BoYuan,BoLiu,JiaChen,ZhaoLiu,FuhaoQiu,HongshengYu,etal. Towardsplaying full moba games with deep reinforcement learning.Advances in Neural Information Processing Systems, 33:621–632, 2020
2020
-
[5]
other-play
Hengyuan Hu, Adam Lerer, Alex Peysakhovich, and Jakob Foerster. “other-play” for zero-shot coordination. InInternational Conference on Machine Learning, pages 4399–4410. PMLR, 2020
2020
-
[6]
Ontheutilityoflearningabouthumans for human-ai coordination.Advances in neural information processing systems, 32, 2019
MicahCarroll,RohinShah,MarkKHo,TomGriffiths,SanjitSeshia,PieterAbbeel,andAncaDragan. Ontheutilityoflearningabouthumans for human-ai coordination.Advances in neural information processing systems, 32, 2019
2019
-
[7]
Diversity is all you need: Learning skills without a reward function
Benjamin Eysenbach, Julian Ibarz, Abhishek Gupta, and Sergey Levine. Diversity is all you need: Learning skills without a reward function. In7th International Conference on Learning Representations, ICLR 2019, 2019
2019
-
[8]
A hierarchical approach to population training for human-ai collaboration
Yi Loo, Chen Gong, and Malika Meghjani. A hierarchical approach to population training for human-ai collaboration. InIJCAI, 2023
2023
-
[9]
Online prototype learning for online continual learning.2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 18718–18728, 2023
Yujie Wei, Jiaxin Ye, Zhizhong Huang, Junping Zhang, and Hongming Shan. Online prototype learning for online continual learning.2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 18718–18728, 2023
2023
-
[10]
Karol Gregor, Danilo Jimenez Rezende, and Daan Wierstra. Variational intrinsic control.ArXiv, abs/1611.07507, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[11]
Explore, discover and learn: Unsupervised discovery of state-covering skills
Víctor Campos, Alexander Trott, Caiming Xiong, Richard Socher, Xavier Giró-i Nieto, and Jordi Torres. Explore, discover and learn: Unsupervised discovery of state-covering skills. InInternational conference on machine learning, pages 1317–1327. PMLR, 2020
2020
-
[12]
Unsupervised skill discovery via recurrent skill training.Advances in Neural Information Processing Systems, 35:39034–39046, 2022
Zheyuan Jiang, Jingyue Gao, and Jianyu Chen. Unsupervised skill discovery via recurrent skill training.Advances in Neural Information Processing Systems, 35:39034–39046, 2022
2022
-
[13]
Bcr-drl:Behavior-andcontext-awarerewardfordeepreinforcement learning in human-ai coordination
XinHao,BaharehNakisa,MohmmadNaimRastgoo,andGaoyangPang. Bcr-drl:Behavior-andcontext-awarerewardfordeepreinforcement learning in human-ai coordination. 2024
2024
-
[14]
Collaborating with humans without human data.Advances in neural information processing systems, 34:14502–14515, 2021
DJ Strouse, Kevin McKee, Matt Botvinick, Edward Hughes, and Richard Everett. Collaborating with humans without human data.Advances in neural information processing systems, 34:14502–14515, 2021
2021
-
[15]
Trajectory diversity for zero-shot coordination
Andrei Lupu, Brandon Cui, Hengyuan Hu, and Jakob Foerster. Trajectory diversity for zero-shot coordination. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 7204–7213. PMLR, 18–24 Jul 2021
2021
-
[16]
Pickyourbattles:Interactiongraphsaspopulation-levelobjectivesforstrategicdiversity
MartaGarnelo,WojciechMarianCzarnecki,SiqiLiu,DhruvaTirumala,JunhyukOh,GauthierGidel,HadovanHasselt,andDavidBalduzzi. Pickyourbattles:Interactiongraphsaspopulation-levelobjectivesforstrategicdiversity. InProceedingsofthe20thInternationalConference on Autonomous Agents and MultiAgent Systems, pages 1501–1503, 2021. :Preprint submitted to Elsevier Page 14 of...
2021
-
[17]
Maximum entropy population-based trainingforzero-shothuman-aicoordination
Rui Zhao, Jinming Song, Yufeng Yuan, Haifeng Hu, Yang Gao, Yi Wu, Zhongqian Sun, and Wei Yang. Maximum entropy population-based trainingforzero-shothuman-aicoordination. InProceedingsoftheAAAIConferenceonArtificialIntelligence,volume37,pages6145–6153, 2023
2023
-
[18]
Learning zero-shot cooperation with humans, assuming humans are biased
Chao Yu, Jiaxuan Gao, Weilin Liu, Botian Xu, Hao Tang, Jiaqi Yang, Yu Wang, and Yi Wu. Learning zero-shot cooperation with humans, assuming humans are biased. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[19]
Cross-environment cooperation enables zero-shot multi-agent coordination
Kunal Jha, Wilka Carvalho, Yancheng Liang, Simon Shaolei Du, Max Kleiman-Weiner, and Natasha Jaques. Cross-environment cooperation enables zero-shot multi-agent coordination. InForty-second International Conference on Machine Learning, 2025
2025
-
[20]
Sutton, Doina Precup, and Satinder Singh
Richard S. Sutton, Doina Precup, and Satinder Singh. Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning.Artificial Intelligence, 112(1):181–211, 1999
1999
-
[21]
The promise of hierarchical reinforcement learning.The Gradient, 9, 2019
Yannis Flet-Berliac. The promise of hierarchical reinforcement learning.The Gradient, 9, 2019
2019
-
[22]
Hierarchical reinforcement learning: A comprehensive survey.ACM Computing Surveys (CSUR), 54(5):1–35, 2021
Shubham Pateria, Budhitama Subagdja, Ah-hwee Tan, and Chai Quek. Hierarchical reinforcement learning: A comprehensive survey.ACM Computing Surveys (CSUR), 54(5):1–35, 2021
2021
-
[23]
Pierre-LucBacon,JeanHarb,andDoinaPrecup.Theoption-criticarchitecture.InProceedingsoftheAAAIconferenceonartificialintelligence, volume 31, 2017
2017
-
[24]
Feudal networks for hierarchical reinforcement learning
Alexander Sasha Vezhnevets, Simon Osindero, Tom Schaul, Nicolas Heess, Max Jaderberg, David Silver, and Koray Kavukcuoglu. Feudal networks for hierarchical reinforcement learning. InInternational conference on machine learning, pages 3540–3549. PMLR, 2017
2017
-
[25]
Hierarchicalmulti-agentskilldiscovery
MingyuYang,YaodongYang,ZhenboLu,WengangZhou,andHouqiangLi. Hierarchicalmulti-agentskilldiscovery. InA.Oh,T.Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 61759– 61776. Curran Associates, Inc., 2023
2023
-
[26]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Representation Learning with Contrastive Predictive Coding
Aäron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.ArXiv, abs/1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[28]
Online continual learning through mutual information maximization
Yiduo Guo, Bing Liu, and Dongyan Zhao. Online continual learning through mutual information maximization. InInternational conference on machine learning, pages 8109–8126. PMLR, 2022
2022
-
[29]
Hierarchical multi-agent skill discovery.Advances in Neural Information Processing Systems, 36:61759–61776, 2023
Mingyu Yang, Yaodong Yang, Zhenbo Lu, Wengang Zhou, and Houqiang Li. Hierarchical multi-agent skill discovery.Advances in Neural Information Processing Systems, 36:61759–61776, 2023
2023
-
[30]
Overcooked.https://store.steampowered.com/app/448510/Overcooked/, 2016
Ghost Town Games. Overcooked.https://store.steampowered.com/app/448510/Overcooked/, 2016. Video game. :Preprint submitted to Elsevier Page 15 of 15
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.