Refined Analysis of Entropy-Regularized Actor-Critic
Pith reviewed 2026-06-30 15:03 UTC · model grok-4.3
The pith
When the critic is exact, actor-critic with stochastic gradients reaches an epsilon-optimal regularized value with only order log(1/epsilon) samples, matching deterministic policy gradient.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
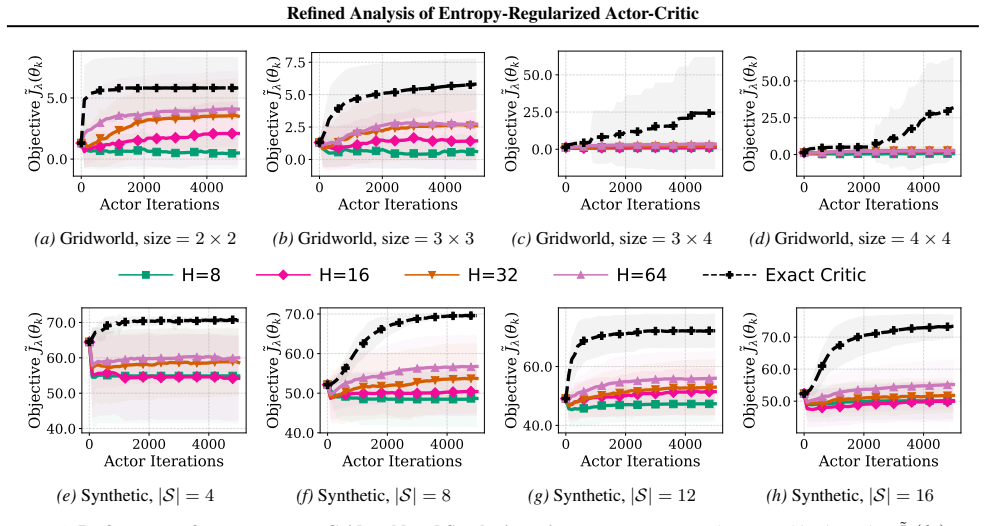
In entropy-regularized finite discounted environments, when the critic is exact, using the latter as a baseline is a variance-reduction method in a strong sense. In this case, actor-critic with stochastic gradients matches the sample complexity of deterministic policy gradient, reaching an epsilon-optimal regularized value with tilde O(log(1/epsilon)) samples. When the critic has a sufficiently small error, the variance reduction and rapid convergence are preserved.
What carries the argument
The critic used as baseline in the actor update, which delivers strong variance reduction when exact.
If this is right
- Actor-critic reaches an epsilon-optimal regularized value with tilde O(log(1/epsilon)) samples when the critic is exact.
- Variance reduction holds in a strong sense with an exact critic.
- The benefits persist if critic error stays sufficiently small.
- Learning the critic first and keeping it updated after each actor update preserves the fast convergence.
Where Pith is reading between the lines
- Practical algorithms may benefit from prioritizing accurate critic updates before frequent actor steps.
- The same variance-reduction logic could be tested in settings without entropy regularization.
- If critic error grows with environment size, the logarithmic sample bound may degrade in large problems.
Load-bearing premise
The critic must be exact or have sufficiently small error for the variance reduction and matching sample complexity to hold.
What would settle it
An empirical run showing that stochastic actor-critic requires more than order log(1/epsilon) samples even with an exact critic would falsify the sample-complexity claim.
Figures
read the original abstract
In this paper, we study the role of the critic in actor--critic for entropy-regularized, finite, discounted environments. We establish that, when the critic is exact, using the latter as a baseline is a variance-reduction method in a strong sense. In this case, actor--critic with stochastic gradients matches the sample complexity of deterministic policy gradient, reaching an $\epsilon$-optimal regularized value with $\tilde{O}(\log(1/\epsilon))$ samples. In practice, the critic is learned alongside the actor: the variance of the actor update is then influenced by the critic's variance and bias. Specifically, when the critic has a sufficiently small error, the variance reduction and rapid convergence are preserved. This suggests to learn the critic first, keeping it up to date after each actor update, underscoring the crucial role of accurate critic estimation in actor--critic methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes the role of the critic in entropy-regularized actor-critic methods for finite discounted MDPs. It claims that an exact critic used as a baseline achieves variance reduction in a strong sense, so that stochastic-gradient actor-critic attains the same Õ(log(1/ε)) sample complexity as deterministic policy gradient for reaching an ε-optimal regularized value. It further states that sufficiently small critic error preserves the variance reduction and rapid convergence, and recommends learning the critic first while keeping it updated after actor updates.
Significance. If the derivations establish the claimed logarithmic sample complexity without hidden polynomial factors in |S|, |A|, or 1/(1-γ), the result would be significant for RL theory: it would rigorously explain why accurate critic estimation enables optimal rates in actor-critic and provide guidance for algorithm design that prioritizes critic accuracy. The explicit identification of the exact-critic case as enabling strong variance reduction would be a useful technical contribution.
major comments (2)
- [Abstract] Abstract: the central claim that stochastic actor-critic matches deterministic policy gradient's Õ(log(1/ε)) complexity when the critic is exact is load-bearing. The manuscript must supply the explicit derivation (presumably in the main theoretical section) showing how the baseline yields this rate and confirming the bound is free of polynomial dependence on 1/(1-γ) or state/action space size, as any such dependence would reintroduce polynomial factors once the critic must be estimated.
- [Abstract] Abstract: the statement that 'sufficiently small' critic error preserves the variance reduction and Õ(log(1/ε)) convergence is not quantified. An explicit error tolerance (e.g., in terms of ε) is required to make the preservation claim rigorous and to support the practical recommendation to learn the critic first.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. The comments highlight important points for strengthening the clarity and rigor of our claims on variance reduction and sample complexity in entropy-regularized actor-critic methods. We address each major comment below and commit to revisions that make the derivations and error tolerances explicit without altering the core results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that stochastic actor-critic matches deterministic policy gradient's Õ(log(1/ε)) complexity when the critic is exact is load-bearing. The manuscript must supply the explicit derivation (presumably in the main theoretical section) showing how the baseline yields this rate and confirming the bound is free of polynomial dependence on 1/(1-γ) or state/action space size, as any such dependence would reintroduce polynomial factors once the critic must be estimated.
Authors: We agree the claim is central and the derivation must be fully explicit. The main theoretical section (Theorem 1 and its proof) derives the Õ(log(1/ε)) rate by showing that the exact-critic baseline reduces the stochastic gradient variance to a constant independent of 1/(1-γ), |S|, and |A|; the subsequent analysis then matches the deterministic policy gradient rate exactly because no polynomial factors remain in the variance bound. We will revise the abstract to include a direct pointer to this theorem and add a short remark in the proof clarifying the independence from those factors. revision: yes
-
Referee: [Abstract] Abstract: the statement that 'sufficiently small' critic error preserves the variance reduction and Õ(log(1/ε)) convergence is not quantified. An explicit error tolerance (e.g., in terms of ε) is required to make the preservation claim rigorous and to support the practical recommendation to learn the critic first.
Authors: We acknowledge that the current phrasing lacks an explicit tolerance. In the revision we will state and prove that a critic error of order O(ε) (in the appropriate supremum norm) is sufficient to preserve both the variance reduction and the Õ(log(1/ε)) rate up to universal constants; this bound will appear in the abstract, the statement of the main theorem, and the practical discussion of critic-first learning. revision: yes
Circularity Check
No circularity: derivation from MDP properties and critic accuracy assumption
full rationale
The paper derives variance reduction and Õ(log(1/ε)) sample complexity for stochastic actor-critic under the exact-critic assumption directly from MDP transition and reward structure. No quoted equations reduce a claimed prediction to a fitted parameter or self-citation chain by construction. The exact-critic premise is stated as an assumption required for the bound, not smuggled in via prior self-work. The analysis is self-contained against external benchmarks once the assumption holds.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Finite state and action spaces, discounted infinite-horizon MDP
Reference graph
Works this paper leans on
-
[1]
doi: 10.1109/TSMC.1983.6313077. Bhatnagar, S., Sutton, R. S., Ghavamzadeh, M., and Lee, M. Natural actor–critic algorithms.Automatica, 45(11): 2471–2482,
-
[2]
Kumar, N., Agrawal, P., Ramponi, G., Levy, K. Y ., and Mannor, S. On the convergence of single-timescale actor-critic.arXiv preprint arXiv:2410.08868,
-
[3]
Escaping the gravitational pull of softmax
Mei, J., Xiao, C., Dai, B., Li, L., Szepesv´ari, C., and Schu- urmans, D. Escaping the gravitational pull of softmax. Advances in Neural Information Processing Systems, 33: 21130–21140, 2020a. Mei, J., Xiao, C., Szepesvari, C., and Schuurmans, D. On the global convergence rates of softmax policy gradient methods. InInternational conference on machine lear...
1928
-
[4]
Morales-Brotons, D., V ogels, T., and Hendrikx, H. Expo- nential moving average of weights in deep learning: Dy- namics and benefits.arXiv preprint arXiv:2411.18704,
-
[5]
A unified view of entropy-regularized Markov decision processes
Neu, G., Jonsson, A., and G ´omez, V . A unified view of entropy-regularized markov decision processes.arXiv preprint arXiv:1705.07798,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
doi: https://doi.org/10.1002/9780470316887.ch6
ISBN 9780470316887. doi: https://doi.org/10.1002/9780470316887.ch6. URL https://onlinelibrary.wiley.com/doi/ abs/10.1002/9780470316887.ch6. Qiu, S., Yang, Z., Ye, J., and Wang, Z. On finite-time con- vergence of actor-critic algorithm.IEEE Journal on Se- lected Areas in Information Theory, 2(2):652–664,
-
[7]
Schulman, J., Levine, S., Abbeel, P., Jordan, M., and Moritz, P
doi: 10.1109/JSAIT.2021.3078754. Schulman, J., Levine, S., Abbeel, P., Jordan, M., and Moritz, P. Trust region policy optimization. InInterna- tional conference on machine learning, pp. 1889–1897. PMLR, 2015a. Schulman, J., Moritz, P., Levine, S., Jordan, M., and Abbeel, P. High-dimensional continuous control us- ing generalized advantage estimation.arXiv...
-
[8]
Notations Distribution of the state-action sequence.The state–action sequence(S t, At)t≥0 defines a stochastic process on the canonical space(S × A) N
11 Refined Analysis of Entropy-Regularized Actor-Critic A. Notations Distribution of the state-action sequence.The state–action sequence(S t, At)t≥0 defines a stochastic process on the canonical space(S × A) N. For any initial states 0 ∈ S, we denote byP π s0 the law of this process. That is, for anyn∈N and any subsetB⊂(S × A) n, Pπ s0(B) = X (a0,...,an−1...
1994
-
[9]
The next lemma shows thatU τ can be seen as a projection on this set
Define the set Πτ ∆ = π∈ P(A) S ,such that for all(s, a)∈ S × A, π(a|s)≥τ . The next lemma shows thatU τ can be seen as a projection on this set. Lemma 22.Fix any policyπ 1 and any policyπ 2 ∈Π τ . Then ∥π1 − Uτ(π1)∥1 ≤ ∥π1 −π 2∥1 . More precisely, for everys∈ S, ∥π1(· |s)− U τ(π1)(· |s)∥ 1 ≤ ∥π1(· |s)−π 2(· |s)∥ 1 . 34 Refined Analysis of Entropy-Regular...
2013
-
[10]
Lemma 24(Flow conservation constraints (Puterman, 1994)).For anyπ∈Π, ands∈ S, it holds that d π ρ (s) = (1−γ)ρ(s) +γ X (s′,a′) P(s|s′, a′)π(a′|s′)d π ρ (s′)
Thenfhas anL-Lipschitz continuous gradient (i.e.,fisL-smooth); in particular, ∥∇f(y)− ∇f(x)∥ ≤L∥y−x∥, and f(y)≥f(x) +⟨∇f(x), y−x⟩ − L 2 ∥y−x∥ 2 for allx, y∈R d. Lemma 24(Flow conservation constraints (Puterman, 1994)).For anyπ∈Π, ands∈ S, it holds that d π ρ (s) = (1−γ)ρ(s) +γ X (s′,a′) P(s|s′, a′)π(a′|s′)d π ρ (s′). 35 Refined Analysis of Entropy-Regular...
1994
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.