Representation-Guided Discrete Molecular Graph Retrosynthesis
Pith reviewed 2026-06-30 13:59 UTC · model grok-4.3
The pith
Guiding molecular graph generators with pretrained representations improves retrosynthesis accuracy and efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Graph-oriented Representation Guidance (GRG) achieves 58.6 / 77.2 / 83.4 / 87.1 top-1 / 3 / 5 / 10 accuracy on USPTO-50k by injecting teacher molecular representations into the denoiser, while increasing diversity to 15.5 and reducing training epochs by 35 percent, with consistent gains in out-of-distribution settings.
What carries the argument
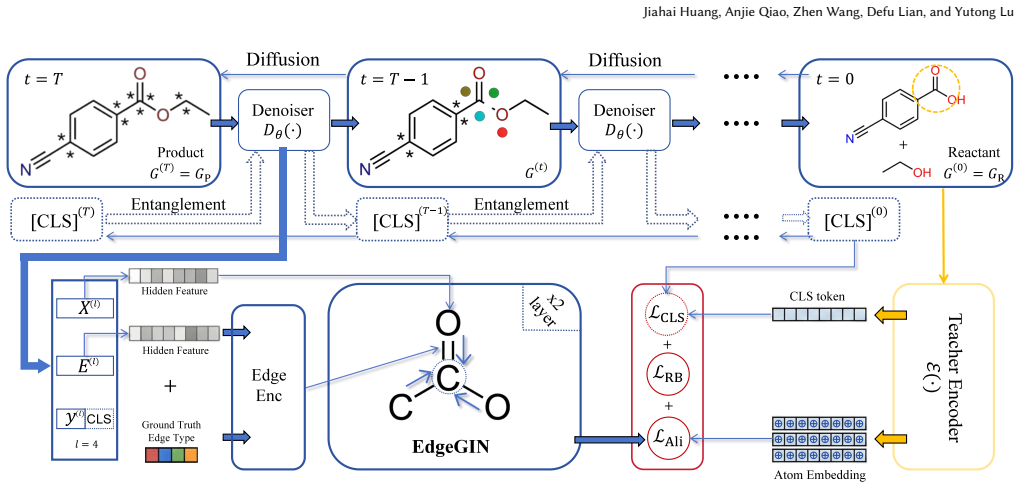
Graph-oriented Representation Guidance (GRG), which systematically selects teacher representations, endpoints, injection depths, correspondence strategies and guidance schemes to inject semantics into the discrete graph denoiser.
If this is right
- GRG consistently improves all top-k metrics in out-of-distribution settings.
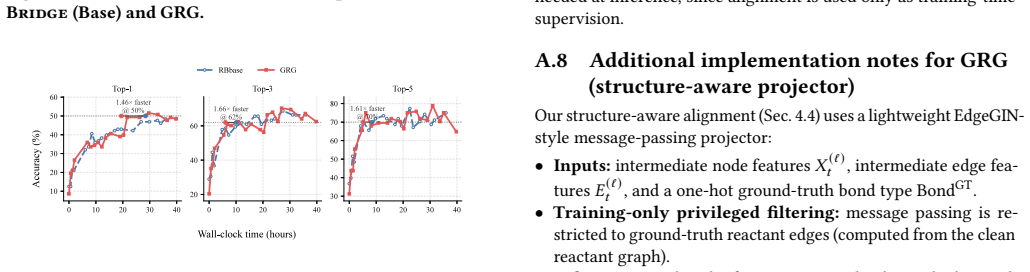
- The guidance reduces the number of epochs by 35% and wall-clock time by 30% to reach comparable performance.
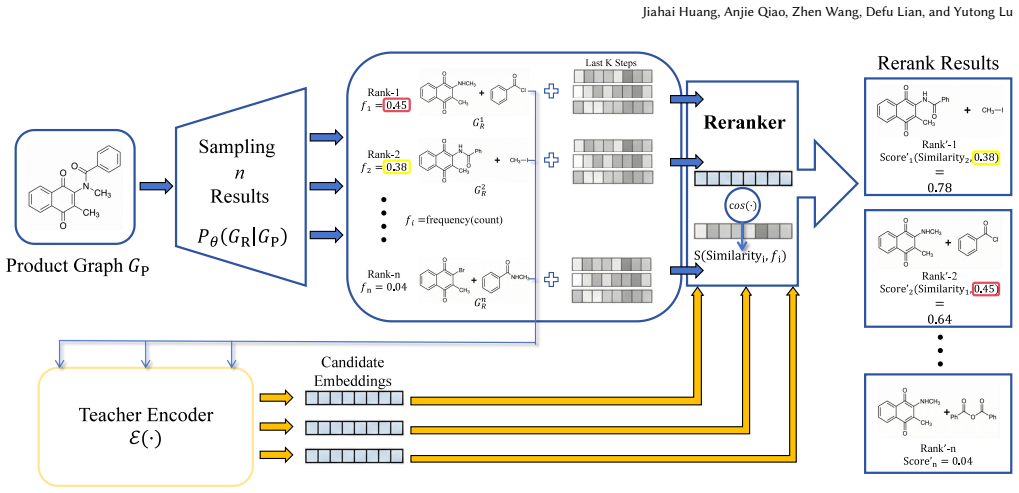
- A representation-similarity-based reranking mechanism further improves the top of the ranked list without additional training.
- Representation guidance facilitates the acquisition of intrinsic chemical semantics in the generator.
Where Pith is reading between the lines
- If the gains come from distilling semantics, combining multiple pretrained encoders could yield further improvements.
- The design space study may generalize to other discrete graph generation tasks beyond retrosynthesis.
- Similar guidance could be tested on larger datasets to confirm scalability.
Load-bearing premise
The assumption that representation guidance from pretrained encoders can be effectively injected into the denoiser for discrete molecular graphs to distill chemistry-relevant semantics that the base model lacks.
What would settle it
Observing no improvement in top-k accuracy or OOD performance when applying the guidance scheme to a held-out retrosynthesis benchmark would falsify the central claim.
Figures
read the original abstract
Stochastic process-based molecular graph generators have become the state of the art for template-free single-step retrosynthesis. However, these models are typically trained only on product-reactant pairs, thereby acquiring chemistry-relevant representations in an indirect and implicit manner. Meanwhile, recent advances in computer vision demonstrate that offering representation guidance to a generator can effectively distill semantics from pretrained encoders into DiTs, substantially improving both convergence and generation quality. Whether similar gains extend to the retrosynthesis task, and what graph-specific design choices can make them work, remains an open question. To address these questions, we conduct a systematic empirical study over a unified design space spanning teacher molecular representations, endpoint and granularity choices, injection depths in the denoiser, correspondence strategies and guidance scheme. Guided by these considerations, we develop Graph-oriented Representation Guidance (GRG), which achieves 58.6 / 77.2 / 83.4 / 87.1 top-1 / 3 / 5 / 10 accuracy on USPTO-50k, while increasing diversity to 15.5, both substantially outperforming the adopted base generator. Notably, GRG consistently improves all top-k metrics in out-of-distribution settings, suggesting that representation guidance facilitates the acquisition of intrinsic chemical semantics. Meanwhile, the introduced representation guidance reduces the number of epochs by 35% and the wall-clock time by 30% to reach comparable performance. In addition, we introduce a simple yet effective representation-similarity-based reranking mechanism, which further improves the top of the ranked list without training an additional verifier.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Graph-oriented Representation Guidance (GRG) to improve stochastic process-based template-free single-step retrosynthesis models. It performs a systematic empirical study over teacher representations, injection endpoints/granularity, denoiser depths, correspondence strategies, and guidance schemes, then develops GRG that reports 58.6/77.2/83.4/87.1 top-1/3/5/10 accuracy on USPTO-50k (plus higher diversity of 15.5), consistent gains on out-of-distribution splits, 35% fewer epochs and 30% less wall-clock time versus the base generator, and a representation-similarity reranker that further boosts top-ranked results.
Significance. If the reported gains hold under full experimental scrutiny, the work demonstrates that pretrained representation guidance can be injected into discrete graph denoisers to acquire intrinsic chemical semantics that implicit training on product-reactant pairs misses. The systematic sweep over graph-specific design choices and the dual benefits in accuracy/diversity plus training efficiency constitute a concrete, reproducible contribution to molecular generation methods.
minor comments (3)
- [§4] §4 (experimental setup): confirm that all baselines, data splits, and hyperparameter choices for the base generator are stated with sufficient detail to allow exact reproduction of the reported top-k numbers and training-time reductions.
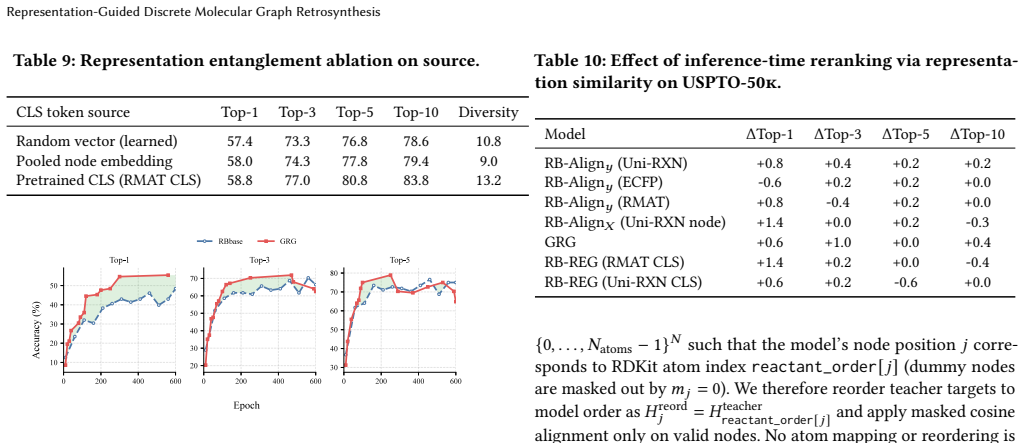
- [Figure 3] Figure 3 and Table 2: ensure error bars or statistical tests accompany the top-k and diversity metrics, and that OOD split definitions are explicitly tabulated.
- The reranking mechanism is described as 'simple yet effective'; add a short ablation showing its contribution independent of GRG to strengthen the claim that it improves the ranked list without an additional verifier.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our manuscript, the accurate summary of our contributions, and the recommendation for minor revision. We are encouraged that the significance of the systematic empirical study, the dual benefits in performance and efficiency, and the potential for representation guidance in discrete graph models is recognized.
Circularity Check
No significant circularity
full rationale
The paper is an empirical study that sweeps over teacher representations, injection points, correspondence strategies, and guidance schemes to develop GRG, then reports concrete top-k accuracies, diversity, and training-time improvements on USPTO-50k (including OOD splits) against a direct base-generator comparator. No equations, derivations, or predictions are presented that reduce by construction to fitted quantities, self-defined terms, or load-bearing self-citations. The central claims rest on externally measurable experimental outcomes rather than internal redefinitions or ansatzes imported from the authors' prior work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg
Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. 2021. Structured denoising diffusion models in discrete state-spaces. In Advances in Neural Information Processing Systems (NeurIPS). 17981–17993. 8 Representation-Guided Discrete Molecular Graph Retrosynthesis
2021
-
[2]
Shuangjia Chen and Yongjin Jung. 2021. Deep retrosynthetic reaction prediction using local reactivity and global attention.JACS Au1, 10 (2021), 1612–1620
2021
-
[3]
Hanjun Dai, Chengtao Li, Connor Coley, Bo Dai, and Le Song. 2019. Retrosyn- thesis prediction with conditional graph logic network. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 32
2019
-
[4]
Yuqiang Han, Xiaoyang Xu, Chang-Yu Hsieh, Keyan Ding, Hongxia Xu, Renjun Xu, Tingjun Hou, Qiang Zhang, and Huajun Chen. 2024. Retrosynthesis predic- tion with an iterative string editing model.Nature Communications15, 1 (2024),
2024
-
[5]
doi:10.1038/s41467-024-50617-1
-
[6]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 33. 6840–6851
2020
- [7]
-
[8]
Park, and Young-Seon Choi
Euijoon Kim, Donghyeon Lee, Yujin Kwon, Min S. Park, and Young-Seon Choi
-
[9]
Valid, plausible, and diverse retrosynthesis using tied two-way transformers with latent variables.Journal of Chemical Information and Modeling61, 1 (2021), 123–133
2021
-
[10]
Najwa Laabid, Severi Rissanen, Markus Heinonen, Arno Solin, and Vikas Garg
-
[11]
InInternational Conference on Learning Representations (ICLR)
Equivariant denoisers cannot copy graphs: align your graph diffusion models. InInternational Conference on Learning Representations (ICLR). doi:10. 48550/arXiv.2405.17656 arXiv:2405.17656
- [12]
- [13]
-
[14]
William Peebles and Saining Xie. 2023. Scalable diffusion models with transform- ers. InIEEE/CVF International Conference on Computer Vision (ICCV). 4172–4182
2023
-
[15]
Bo Qiang, Yiran Zhou, Yuheng Ding, Ningfeng Liu, Song Song, Liangren Zhang, Bo Huang, et al. 2023. Bridging the gap between chemical reaction pretraining and conditional molecule generation with a unified model.Nature Machine Intelligence5, 12 (2023), 1476–1485. doi:10.1038/s42256-023-00764-9
-
[16]
Anjie Qiao, Zhen Wang, Jiahua Rao, Yuedong Yang, and Zhewei Wei. 2025. Advancing Retrosynthesis with Retrieval-Augmented Graph Generation. InPro- ceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 20004–20013. doi:10.1609/aaai.v39i19.34203
-
[17]
David Rogers and Mathew Hahn. 2010. Extended-connectivity fingerprints. Journal of Chemical Information and Modeling50, 5 (2010), 742–754. doi:10.1021/ ci100050t
2010
-
[18]
Mikołaj Sacha, Mateusz Błaż, Piotr Byrski, Paweł Dąbrowski-Tumański, Mateusz Chromiński, Rafał Loska, Piotr Włodarczyk-Pruszyński, and Stanisław Jastrzęb- ski. 2021. Molecule edit graph attention network: modeling chemical reactions as sequences of graph edits.Journal of Chemical Information and Modeling61, 7 (2021), 3273–3284
2021
-
[19]
Nadine Schneider, Daniel M. Lowe, Roger A. Sayle, Michael A. Tarselli, and Gre- gory A. Landrum. 2016. Big data from pharmaceutical patents: a computational analysis of medicinal chemists’ bread and butter.Journal of Medicinal Chemistry 59, 9 (2016), 4385–4402. doi:10.1021/acs.jmedchem.6b00153
-
[20]
Hunter, Costas Bekas, and Alpha A
Philippe Schwaller, Teodoro Laino, Théophile Gaudin, Peter Bolgar, Christo- pher A. Hunter, Costas Bekas, and Alpha A. Lee. 2019. Molecular transformer: a model for uncertainty-calibrated chemical reaction prediction.ACS Central Science5, 9 (2019), 1572–1583. doi:10.1021/acscentsci.9b00576
-
[21]
Philippe Schwaller, Riccardo Petraglia, Valentino Zullo, Vishnu H Nair, Ralph A Haeuselmann, Riccardo Pisoni, Costas Bekas, Antonio Iuliano, and Teodoro Laino
-
[22]
Predicting retrosynthetic pathways using transformer-based models and a hyper-graph exploration strategy.Chemical Science11, 12 (2020), 3316–3325
2020
-
[23]
Marwin H. S. Segler, Mike Preuss, and Mark P. Waller. 2018. Planning chemical syntheses with deep neural networks and symbolic AI.Nature555, 7698 (2018), 604–610
2018
-
[24]
Chence Shi, Muhan Xu, Hongyu Guo, Ming Zhang, and Jian Tang. 2020. A graph to graphs framework for retrosynthesis prediction. InInternational Conference on Machine Learning (ICML). 8818–8827
2020
- [25]
-
[26]
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli
-
[27]
In International Conference on Machine Learning (ICML)
Deep unsupervised learning using nonequilibrium thermodynamics. In International Conference on Machine Learning (ICML). 2256–2265
-
[28]
Somnath, Charlotte Bunne, Connor Coley, Andreas Krause, and Regina Barzilay
Vrinda R. Somnath, Charlotte Bunne, Connor Coley, Andreas Krause, and Regina Barzilay. 2021. Learning graph models for retrosynthesis prediction. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 34. 9405–9415
2021
-
[29]
Felix Strieth-Kalthoff, Frank Sandfort, Marwin H. S. Segler, and Frank Glorius
-
[30]
Machine learning the ropes: principles, applications and directions in synthetic chemistry.Chemical Society Reviews49, 17 (2020), 6154–6168
2020
-
[31]
Tetko, Petr Karpov, Robert Van Deursen, and Guillaume Godin
Igor V. Tetko, Petr Karpov, Robert Van Deursen, and Guillaume Godin. 2020. State-of-the-art augmented NLP transformer models for direct and single-step retrosynthesis.Nature Communications11, 1 (2020), 5575
2020
-
[32]
Zhen Tu and Connor W. Coley. 2022. Permutation invariant graph-to-sequence model for template-free retrosynthesis and reaction prediction.Journal of Chem- ical Information and Modeling62, 15 (2022), 3503–3513
2022
-
[33]
Dmitry Ulyanov, Andrea Vedaldi, and Victor Lempitsky. 2016. Instance normaliza- tion: The missing ingredient for fast stylization.arXiv preprint arXiv:1607.08022 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[34]
Clément Vignac, Igor Krawczuk, Aymeric Siraudin, Bin Wang, Volkan Cevher, and Pascal Frossard. 2023. DiGress: discrete denoising diffusion for graph gener- ation. InInternational Conference on Learning Representations (ICLR)
2023
-
[35]
Yu Wan, Cheng-Yu Hsieh, Bo Liao, and Shengyu Zhang. 2022. Retroformer: pushing the limits of end-to-end retrosynthesis transformer. InInternational Conference on Machine Learning (ICML). 22475–22490
2022
-
[36]
Xiaorui Wang, Yujie Li, Jie Qiu, Guangyong Chen, Haibo Liu, Bo Liao, Cheng-Yu Hsieh, and Xin Yao. 2021. RetroPrime: a diverse, plausible and transformer-based method for single-step retrosynthesis predictions.Chemical Engineering Journal 420 (2021), 129845
2021
-
[37]
Yiming Wang, Yuxuan Song, Yiqun Wang, Minkai Xu, Rui Wang, Hao Zhou, and Wei-Ying Ma. 2025. RetroDiff: retrosynthesis as multi-stage distribution interpolation. InProceedings of The 28th International Conference on Artificial Intelligence and Statistics (Proceedings of Machine Learning Research, Vol. 258), Yingzhen Li, Stephan Mandt, Shipra Agrawal, and E...
-
[38]
David Weininger. 1988. SMILES, a chemical language and information system. 1. Introduction to methodology and encoding rules.Journal of Chemical Information and Computer Sciences28, 1 (1988), 31–36
1988
-
[39]
Ge Wu, Shen Zhang, Ruijing Shi, Shanghua Gao, Zhenyuan Chen, Lei Wang, Zhaowei Chen, Hongcheng Gao, Yao Tang, Jian Yang, Ming-Ming Cheng, and Xiang Li. 2025. Representation entanglement for generation: training diffusion transformers is much easier than you think.arXiv preprint arXiv:2507.01467 (2025)
-
[40]
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. 2019. How powerful are graph neural networks?. InInternational Conference on Learning Representa- tions (ICLR)
2019
-
[41]
Chaochao Yan, Qiankun Ding, Peilin Zhao, Sheng Zheng, Jun Yang, Yang Yu, and Junzhou Huang. 2020. RetroXpert: decompose retrosynthesis prediction like a chemist. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 33. 11248–11258
2020
-
[42]
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. 2024. Representation alignment for genera- tion: training diffusion transformers is easier than you think.arXiv preprint arXiv:2410.06940(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Shuangjia Zheng, Jiahua Rao, Zeyi Zhang, Jun Xu, and Yuedong Yang. 2019. Predicting retrosynthetic reactions using self-corrected transformer neural net- works.Journal of Chemical Information and Modeling60, 1 (2019), 47–55
2019
-
[44]
birth” into atoms (or “die
Gengmo Zhou, Zhifeng Gao, Qiankun Ding, Hang Zheng, Hongteng Xu, Zhewei Wei, Linfeng Zhang, and Guolin Ke. 2023. Uni-Mol: a universal 3D molecular representation learning framework. InInternational Conference on Learning Representations (ICLR). A Additional Details A.1 Evaluation metrics and protocol Top-𝑘 exact match.Top- 𝑘 exact-match accuracy is the fr...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.