WhenLoss: Diagnosing Write and Retrieval Bottlenecks in Long-Context Memory Systems
Pith reviewed 2026-06-30 13:46 UTC · model grok-4.3
The pith
Write-stage compression losses exceed retrieval losses in fixed-budget long-context memory systems, and predictive compression at write time closes most of the gap.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
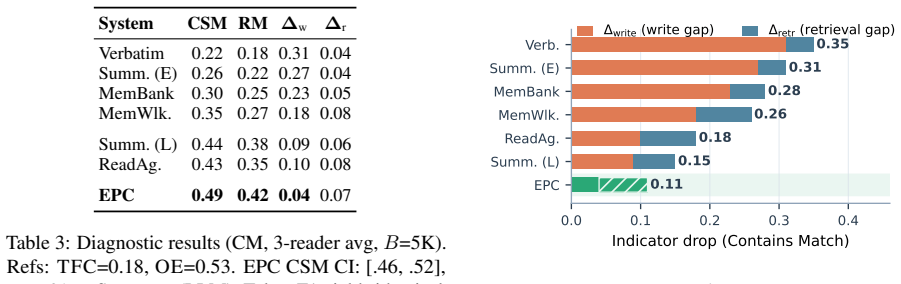
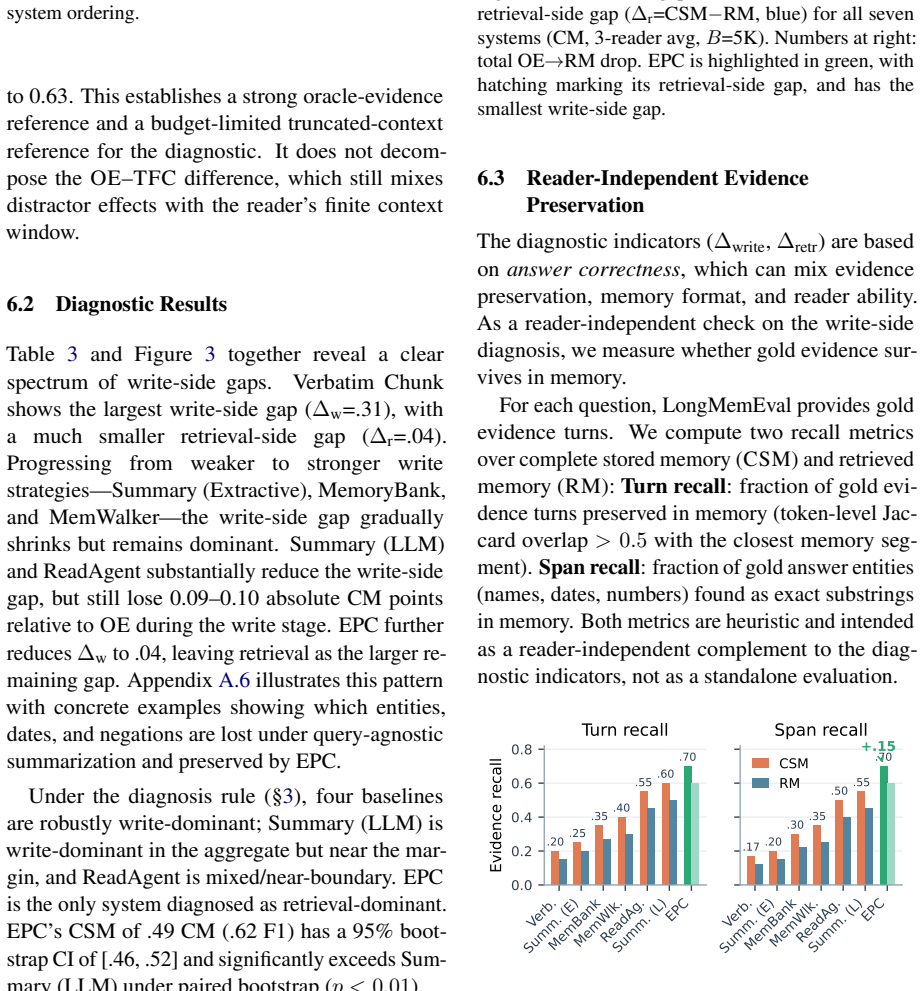
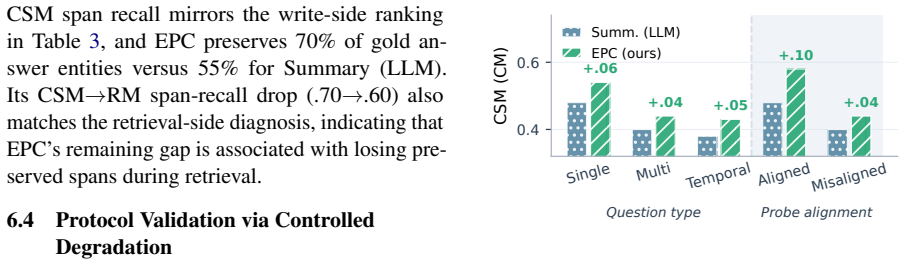
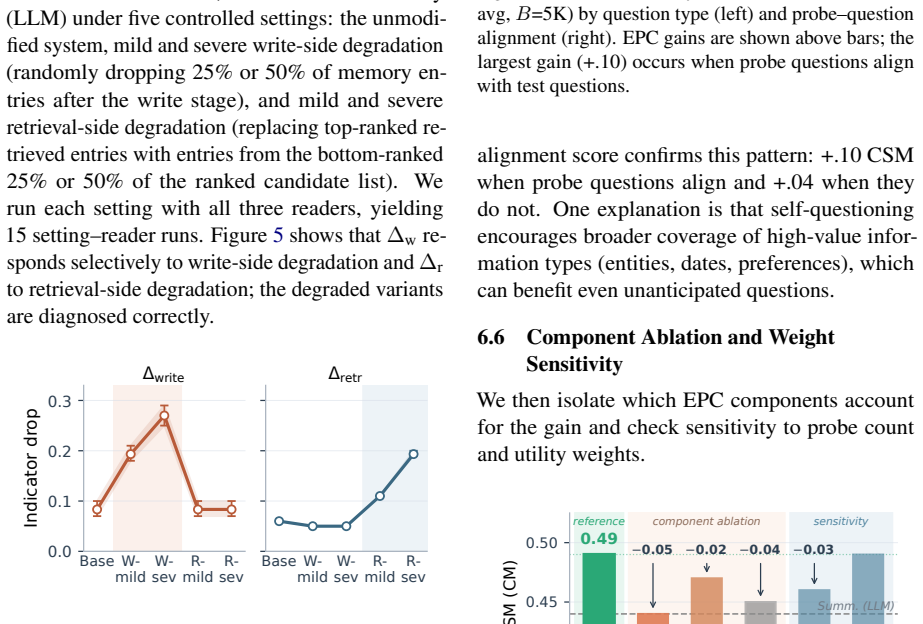
Under the fixed-budget LongMemEval setup, write-side gaps exceed retrieval-side gaps for most tested baselines, with four of six baselines robustly write-dominant under the default diagnosis margin. EPC achieves the highest CSM scores (0.49 vs. 0.44) and reduces Delta_write to 0.04 while leaving Delta_retr comparable to other LLM-based systems.
What carries the argument
Four-condition diagnostic protocol (TFC, OE, CSM, RM) that isolates write losses from retrieval losses by comparing performance under different memory conditions, plus Expected Predictive Compression (EPC) that moves the retention decision to write time by anticipating future questions.
If this is right
- Improving evidence preservation at write time produces larger end-to-end gains than improving retrieval under fixed budgets.
- EPC raises complete stored memory quality without changing retrieval behavior or reader models.
- The diagnosis margin identifies systems where write-stage changes are the higher-leverage intervention.
- Anticipating questions at compression time outperforms generic summarization baselines on this benchmark.
Where Pith is reading between the lines
- The same four-condition split could be applied to other memory architectures to locate their dominant loss stage.
- Task-aware compression at write time may reduce token waste in any system that must answer varied future queries from a fixed store.
- If question prediction can be made cheaper, predictive compression could become a standard preprocessing step before storage.
Load-bearing premise
The four-condition protocol cleanly separates write losses from retrieval losses without confounding effects from the reader model or the LongMemEval question distribution.
What would settle it
Re-running the four-condition protocol on the same six baselines and LongMemEval questions but finding retrieval gaps larger than write gaps for more than two systems would falsify the write-dominance diagnosis.
Figures


read the original abstract
Long-context memory systems often fail under fixed budgets, but end-to-end evaluation does not reveal whether evidence was discarded during compression or preserved but never retrieved. We introduce a four-condition diagnostic protocol that evaluates a fixed reader under truncated full context (TFC), oracle evidence (OE), complete stored memory (CSM), and retrieved memory (RM). Under this fixed-budget LongMemEval setup, write-side gaps exceed retrieval-side gaps for most tested baselines, with four of six baselines robustly write-dominant under our default diagnosis margin. Motivated by this diagnosis, we propose Expected Predictive Compression (EPC), which moves the key decision--what information to retain--to write time by using an LLM to anticipate likely future questions and preserve the minimal supporting evidence under the token budget, while leaving retrieval unchanged at question time. Across all 500 LongMemEval questions with three readers (GPT-5.2, Claude Sonnet 4, Gemini 2.5 Pro), EPC achieves the highest CSM scores among all systems (0.49 vs. 0.44 for Summary (LLM), the strongest baseline), reducing Delta_write to 0.04 while leaving Delta_retr comparable to other LLM-based systems. These results suggest that, on this benchmark and evaluation setup, improving what the write stage preserves is a key avenue for performance gains in the tested systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a four-condition diagnostic protocol (TFC, OE, CSM, RM) to separate write-stage from retrieval-stage losses in fixed-budget long-context memory systems. On LongMemEval it reports that write-side gaps exceed retrieval-side gaps for most baselines (four of six robustly write-dominant), and proposes Expected Predictive Compression (EPC) that uses an LLM at write time to anticipate questions and retain minimal supporting evidence; EPC attains the highest CSM score (0.49) and reduces Delta_write to 0.04 while leaving Delta_retr comparable to other LLM baselines, across three readers.
Significance. If the protocol cleanly isolates the two stages, the diagnosis that write losses are the dominant bottleneck and the concrete gains from EPC would identify a high-leverage direction for memory-system design. The work supplies a reusable evaluation harness and reports results with multiple readers on a fixed benchmark, which strengthens the empirical case.
major comments (2)
- [evaluation protocol] The central interpretation that Delta_write (OE vs. CSM gap) measures pure write-stage loss and Delta_retr (CSM vs. RM gap) measures retrieval-only loss rests on the untested premise that the fixed reader exhibits no differential sensitivity to memory format or compression artifacts; the abstract and evaluation description provide no ablation that varies the reader while holding memory content fixed, leaving open the possibility that reported write-dominance is partly an artifact of the chosen reader models.
- [LongMemEval setup] The claim that LongMemEval question distribution does not systematically favor evidence that is easy to write but hard to retrieve (or vice versa) is required for the four-condition protocol to generalize beyond this benchmark; no analysis of question-evidence alignment or cross-benchmark validation is reported, which directly affects the robustness of the "four of six baselines robustly write-dominant" conclusion.
minor comments (1)
- The abstract states results "across all 500 LongMemEval questions" but does not specify how the 500 questions were sampled or whether they overlap with any training data used by the EPC predictor; a brief clarification would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation protocol and benchmark assumptions. We address each major comment below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [evaluation protocol] The central interpretation that Delta_write (OE vs. CSM gap) measures pure write-stage loss and Delta_retr (CSM vs. RM gap) measures retrieval-only loss rests on the untested premise that the fixed reader exhibits no differential sensitivity to memory format or compression artifacts; the abstract and evaluation description provide no ablation that varies the reader while holding memory content fixed, leaving open the possibility that reported write-dominance is partly an artifact of the chosen reader models.
Authors: We acknowledge the validity of this concern regarding the core assumption of the protocol. The manuscript already evaluates the full set of conditions across three readers (GPT-5.2, Claude Sonnet 4, Gemini 2.5 Pro) and finds consistent write-dominance patterns, which offers some empirical support for robustness. However, we did not perform the specific ablation of holding memory content fixed while varying only the reader to isolate format sensitivity. We will add an explicit discussion of this assumption and its potential implications in the revised manuscript. revision: partial
-
Referee: [LongMemEval setup] The claim that LongMemEval question distribution does not systematically favor evidence that is easy to write but hard to retrieve (or vice versa) is required for the four-condition protocol to generalize beyond this benchmark; no analysis of question-evidence alignment or cross-benchmark validation is reported, which directly affects the robustness of the "four of six baselines robustly write-dominant" conclusion.
Authors: We agree that no question-evidence alignment analysis or cross-benchmark validation is present. Our claims and the reported write-dominance conclusion are scoped specifically to LongMemEval under the fixed-budget protocol, as already stated in the abstract. We will revise the manuscript to more prominently emphasize this scope limitation and the absence of such analyses, without asserting broader generalizability. revision: yes
Circularity Check
No circularity in derivation or evaluation chain
full rationale
The paper introduces an empirical four-condition protocol (TFC/OE/CSM/RM) and reports direct measurements of CSM scores and Delta_write/Delta_retr gaps on the fixed LongMemEval benchmark using external readers. No equations, fitted parameters, or self-citations are shown that reduce the reported metrics to inputs by construction. The EPC proposal is motivated by the observed gaps but evaluated independently on the same benchmark. The derivation chain consists of straightforward experimental comparisons and is self-contained against the stated benchmark and readers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The four conditions TFC, OE, CSM, and RM cleanly separate write-stage loss from retrieval-stage loss.
Reference graph
Works this paper leans on
-
[1]
InProceedings of the International Conference on Learning Representations (ICLR)
MemGPT: Towards LLMs as operating sys- tems. InProceedings of the International Conference on Learning Representations (ICLR). Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Menglin Xia, Xufang Luo, Jue Zhang, Qingwei Lin, Victor Ruhle, Yuqing Yang, Chin-Yew Lin, and 1 others
-
[2]
A Survey on the Memory Mechanism of Large Language Model based Agents
LLMLingua-2: Data distillation for efficient and faithful task-agnostic prompt compression. In Findings of the Association for Computational Lin- guistics: ACL 2024. Nils Reimers and Iryna Gurevych. 2019. Sentence- BERT: Sentence embeddings using siamese BERT- networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processi...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.