Representation Without Control: Testing the Realization Effect in Language Models
Pith reviewed 2026-06-30 10:58 UTC · model grok-4.3
The pith
LLMs show behavioral sensitivity to realization status and contain a linearly readable signal for it, yet steering that signal leaves risk decisions unchanged.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Behavioral sensitivity, latent readout, and causal control are three distinct properties that do not automatically co-occur, and successful latent readout is insufficient evidence that a model behaviorally relies on a representation during downstream decision-making.
What carries the argument
Linear readout of a realization-status direction in the residual stream at layer 18, followed by activation steering to test whether that direction exerts causal control over risk choices.
If this is right
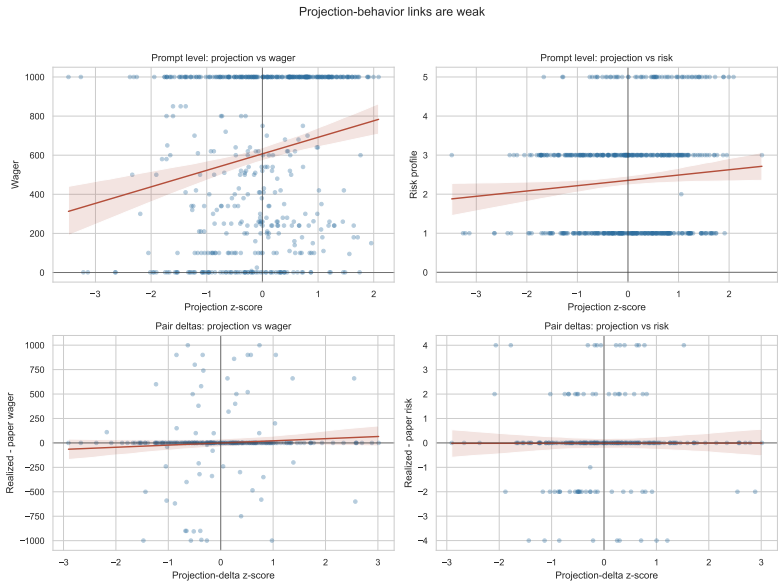
- Prompt-only behavioral sensitivity to realization status does not match the directional pattern predicted by human studies.
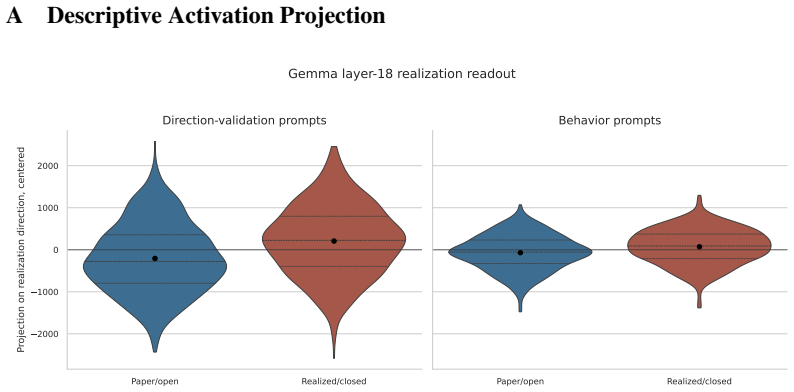
- A linearly decodable realization-status signal exists in the residual stream at layer 18 and generalizes to held-out prompts.
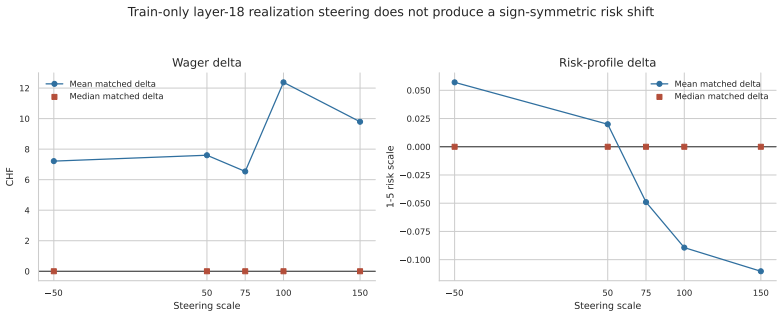
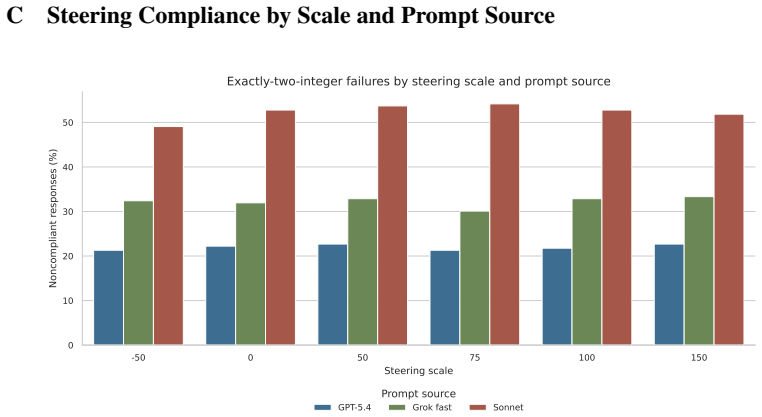
- Steering along the decoded direction fails to shift risk choices across positive scales and in a negative sign-symmetry condition.
Where Pith is reading between the lines
- The dissociation suggests models may use non-linear or distributed features for decisions that linear probes do not capture.
- Similar tests could be applied to other economic or cognitive concepts to check whether readable representations are causally active.
- If the null steering result holds under other intervention methods, it would strengthen the claim that readout alone is weak evidence of functional use.
Load-bearing premise
That steering along the linearly decoded realization-status direction at layer 18 constitutes a sufficient test of whether the representation is causally used in risk decisions.
What would settle it
An experiment in which steering the realization-status direction at layer 18 produces a consistent, measurable change in the model's risk-taking responses across held-out prompts.
Figures

read the original abstract
Large language models are increasingly used as behavioral simulators, but it remains unclear when their outputs reflect human-like cognitive mechanisms rather than prompt-sensitive surface patterns. We study this question through the realization effect, a well-characterized finding in behavioral economics in which risk-taking differs systematically after paper versus realized gains and losses. We evaluate LLM behavior at three levels: prompt-only behavioral sensitivity, linear readout of internal representations, and causal control via activation steering. Prompt-only results show systematic condition sensitivity, but the directional pattern does not reproduce human realization-effect predictions. Gemma's residual stream contains a linearly decodable realization-status signal at layer 18 that generalizes to held-out prompts. Steering along this direction does not, however, reliably shift downstream risk choices, a null result that holds across positive scales and in a negative sign-symmetry run. Behavioral sensitivity, latent readout, and causal control are three distinct properties that do not automatically co-occur, and successful latent readout is insufficient evidence that a model behaviorally relies on a representation during downstream decision-making.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs exhibit the realization effect at three distinct levels: prompt-only behavioral sensitivity (systematic but not matching human directional predictions), linear decodability of realization status from Gemma's residual stream at layer 18 (generalizing to held-out prompts), and causal control (null result from activation steering along this direction, holding across scales and sign-symmetry). It concludes that behavioral sensitivity, latent readout, and causal control do not automatically co-occur, and that successful readout is insufficient evidence of behavioral reliance on the representation during downstream risk decisions.
Significance. If the null steering result proves robust, the work is significant for LLM interpretability and the validity of using models as behavioral simulators, as it provides concrete evidence of a dissociation between decodable representations and causal influence on outputs. The multi-level empirical design (prompt behavior, linear probes, and steering with held-out generalization and sign-symmetry checks) is a methodological strength that could serve as a template for testing representation-behavior links.
major comments (2)
- [§3 (Methods)] §3 (Methods): The manuscript provides no details on prompt construction, number of runs, statistical thresholds for declaring null results, or controls for prompt sensitivity. This is load-bearing for the central claim, as the dissociation rests on interpreting the steering null as evidence against causal use, yet these omissions make it impossible to assess robustness.
- [§4.3 (Steering results)] §4.3 (Steering results): The null outcome from linear steering at layer 18 is taken to show the representation is not relied upon for risk decisions. This interpretation assumes the single-layer linear intervention is sufficient to detect causal involvement; if integration occurs via distributed, multi-layer, or nonlinear pathways, the null would not support the claimed dissociation, and additional tests (e.g., multi-layer or nonlinear interventions) are needed to substantiate it.
minor comments (2)
- [Abstract] Abstract and §4.1: The statement that the directional pattern 'does not reproduce human realization-effect predictions' would benefit from a one-sentence summary of the expected human pattern for reader context.
- [Figures] Figure captions (throughout): Ensure all panels report exact sample sizes and error-bar definitions to aid evaluation of the behavioral sensitivity and null steering claims.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on methodological transparency and the interpretation of our steering results. We provide point-by-point responses below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [§3 (Methods)] §3 (Methods): The manuscript provides no details on prompt construction, number of runs, statistical thresholds for declaring null results, or controls for prompt sensitivity. This is load-bearing for the central claim, as the dissociation rests on interpreting the steering null as evidence against causal use, yet these omissions make it impossible to assess robustness.
Authors: We agree that these details are critical for evaluating the robustness of the null steering result. In the revised manuscript, we will expand the Methods section (§3) to provide: full details on prompt construction including the base templates and variations used to test sensitivity; the number of runs (1000 generations per condition across 5 random seeds); the statistical thresholds (we declare null if p > 0.05 in two one-sided tests for practical equivalence with a smallest effect size of interest of 5 percentage points, supported by a power analysis); and controls for prompt sensitivity including results from alternative phrasings. These additions will strengthen the assessment of our central claims. revision: yes
-
Referee: [§4.3 (Steering results)] §4.3 (Steering results): The null outcome from linear steering at layer 18 is taken to show the representation is not relied upon for risk decisions. This interpretation assumes the single-layer linear intervention is sufficient to detect causal involvement; if integration occurs via distributed, multi-layer, or nonlinear pathways, the null would not support the claimed dissociation, and additional tests (e.g., multi-layer or nonlinear interventions) are needed to substantiate it.
Authors: This is a valid point regarding the scope of our intervention. Our results show that steering along the linearly decodable direction at layer 18 does not affect risk choices, supporting the claim that linear decodability alone does not imply behavioral reliance on that representation. We do not claim to have exhaustively tested all possible causal mechanisms. We will revise the text in §4.3 and the discussion to explicitly acknowledge that our intervention is limited to linear, single-layer steering and that more complex pathways remain possible. This clarification will better frame the dissociation we report without overclaiming. New experiments with multi-layer or nonlinear methods are left for future work. revision: partial
Circularity Check
Purely empirical study with no derivations or self-referential reductions
full rationale
The paper reports experimental outcomes across prompt-only behavior, linear probing for realization-status signals, and activation steering interventions. No equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations appear in the abstract or described methods. All central claims rest on observed null results and generalization tests rather than reducing by construction to definitions or prior author work. This matches the default expectation of a non-circular empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The realization effect is a well-characterized finding in behavioral economics in which risk-taking differs systematically after paper versus realized gains and losses.
Reference graph
Works this paper leans on
-
[1]
Aher, Rosa I
Gati V . Aher, Rosa I. Arriaga, and Adam Tauman Kalai. Using large language models to simulate multiple humans and replicate human subject studies. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 337–371. PMLR, 2023
2023
-
[2]
Predicting results of social science experiments using large language models
Anand Ashokkumar, Lester Hewitt, Isaias Ghezae, and Robb Willer. Predicting results of social science experiments using large language models. Stanford University, unpublished manuscript, 2024
2024
-
[3]
Synthetic replacements for human survey data? the perils of large language models.Political Analysis, 32(4):401–416, 2024
James Bisbee, Joshua D Clinton, Cassy Dorff, Brenton Kenkel, and Jennifer M Larson. Synthetic replacements for human survey data? the perils of large language models.Political Analysis, 32(4):401–416, 2024
2024
-
[4]
Can ai language models replace human participants?Trends in Cognitive Sciences, 27(7):597–600, 2023
Danica Dillion, Niket Tandon, Yuling Gu, and Kurt Gray. Can ai language models replace human participants?Trends in Cognitive Sciences, 27(7):597–600, 2023. 9
2023
-
[5]
Raphael Flepp, Philippe Meier, and Egon Franck. The effect of paper outcomes versus realized outcomes on subsequent risk-taking: Field evidence from casino gambling.Organizational Behavior and Human Decision Processes, 165:45–55, 2021
2021
-
[6]
Take caution in using llms as human surrogates.Proceedings of the National Academy of Sciences, 122(24):e2501660122, 2025
Yulan Gao, Dokyun Lee, Gordon Burtch, and Sina Fazelpour. Take caution in using llms as human surrogates.Proceedings of the National Academy of Sciences, 122(24):e2501660122, 2025
2025
-
[7]
Ai language models cannot replace human research participants.Ai & Society, 39(5):2603–2605, 2024
Jacqueline Harding, William D’Alessandro, NG Laskowski, and Robert Long. Ai language models cannot replace human research participants.Ai & Society, 39(5):2603–2605, 2024
2024
-
[8]
Horton, Apostolos Filippas, and Benjamin S
John J. Horton, Apostolos Filippas, and Benjamin S. Manning. Large language models as simu- lated economic agents: What can we learn from homo silicus?arXiv preprint arXiv:2301.07543, 2023
-
[9]
The realization effect: Risk-taking after realized versus paper losses.American Economic Review, 106(8):2086–2109, 2016
Alex Imas. The realization effect: Risk-taking after realized versus paper losses.American Economic Review, 106(8):2086–2109, 2016
2086
-
[10]
Closing a mental account: The realization effect for gains and losses.Experimental Economics, 24(1):303–329, 2021
Christoph Merkle, Jan Müller-Dethard, and Martin Weber. Closing a mental account: The realization effect for gains and losses.Experimental Economics, 24(1):303–329, 2021
2021
-
[11]
The linear representation hypothesis and the geometry of large language models
Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of large language models. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 39643–39666. PMLR, 2024
2024
-
[12]
Alex Salinas and Fred Morstatter. The butterfly effect of altering prompts: How small changes and jailbreaks affect large language model performance.arXiv preprint arXiv:2401.03729, 2024
-
[13]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J. Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering language models with activation engineering.arXiv preprint arXiv:2308.10248, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Leo Yeykelis, Kiran Pichai, James J Cummings, and Byron Reeves. Using large language models to create ai personas for replication, generalization and prediction of media effects: An empirical test of 133 published experimental research findings.arXiv preprint arXiv:2408.16073, 2024
-
[15]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J. Zico Kolter, and Dan Hendrycks. Representation engineering: A top-down approach to a...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.