LipoAgent: Coordinating Fine-Tuned LLM Agents for Safer Lipid Design
Pith reviewed 2026-06-30 00:20 UTC · model grok-4.3
The pith
LipoAgent uses fine-tuned LLM agents to enforce toxicity checks before predicting mRNA delivery efficiency in lipids.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
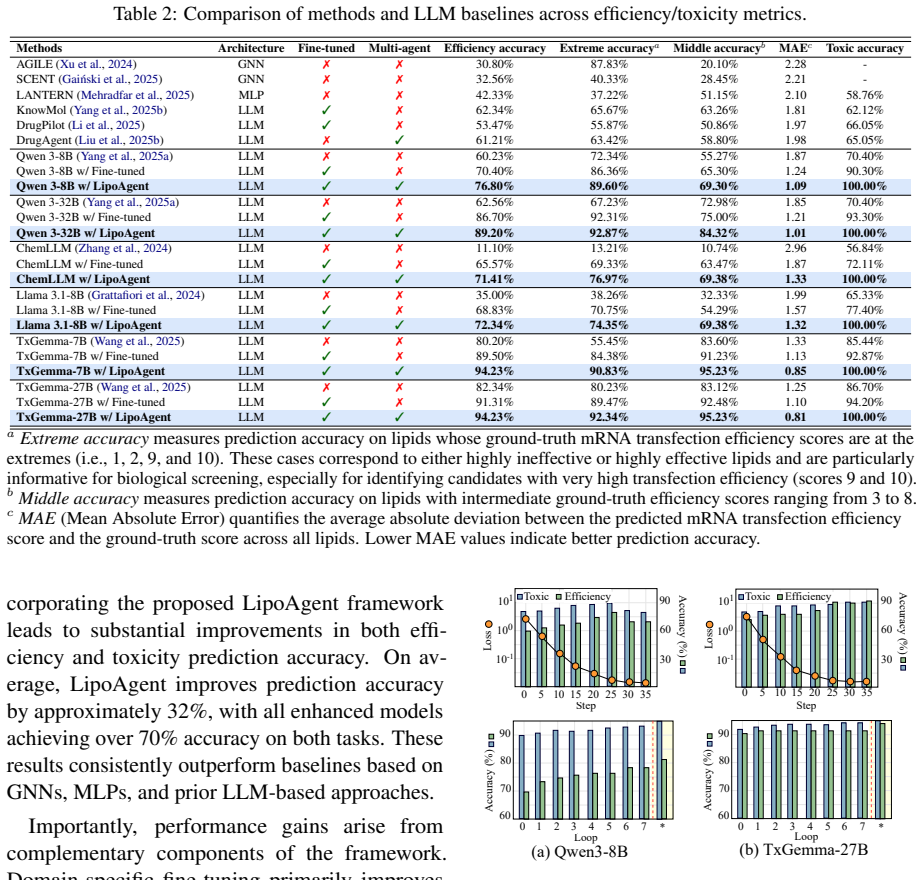
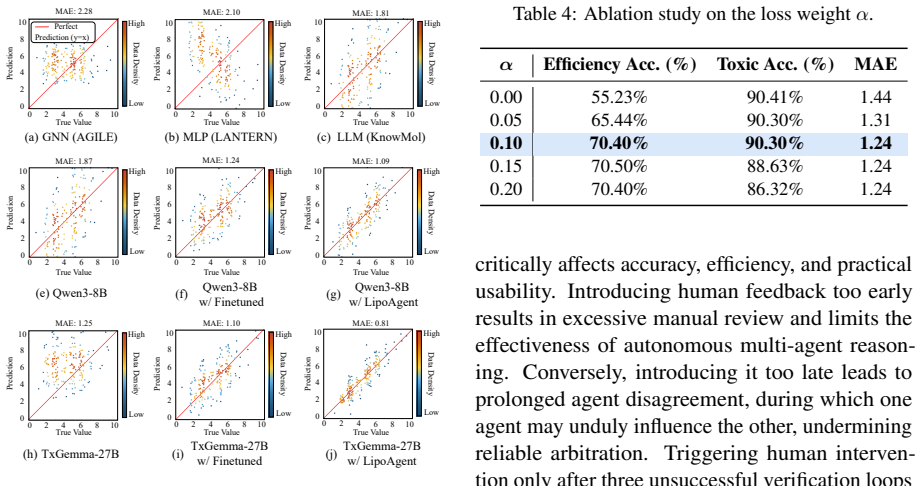
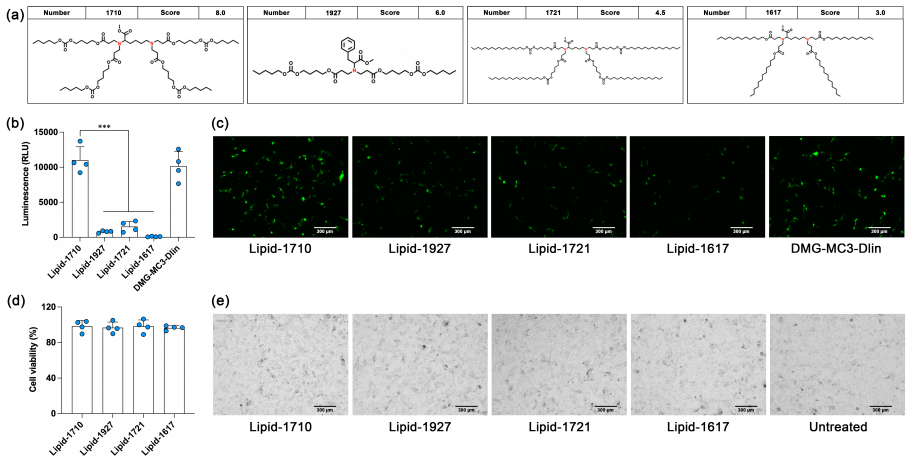
LipoAgent achieves an average 32% relative improvement in mRNA transfection efficiency prediction across multiple foundation models by combining domain-specific fine-tuning with a conditional prediction objective that enforces toxicity as a prerequisite for efficiency prediction, along with multi-agent verification.
What carries the argument
The conditional prediction objective that requires toxicity assessment as a prerequisite before making efficiency predictions, supported by multi-agent verification.
If this is right
- The system produces predictions that are clinically more relevant by filtering toxic candidates early.
- Virtual screening with LipoAgent can reduce reliance on costly and time-consuming wet-lab experiments for initial screening.
- The approach works across different base language models, suggesting it is not tied to one specific model.
- Wet-lab validation shows that the predicted rankings match actual mRNA transfection results in cells.
Where Pith is reading between the lines
- Similar conditional safety checks could be applied to AI models for other types of drug or material design where toxicity is a key concern.
- The multi-agent setup might help in other scientific domains where multiple verification steps improve reliability of AI predictions.
- If the method generalizes, it could accelerate the development of new delivery systems for vaccines and gene therapies.
Load-bearing premise
The predictions from the toxicity-first conditional model and multi-agent checks will remain accurate when applied to lipids that were not seen during training.
What would settle it
A lipid ranked as highly efficient and safe by LipoAgent that turns out to have poor transfection efficiency or high toxicity when tested in actual laboratory cell assays would falsify the central claim.
Figures

read the original abstract
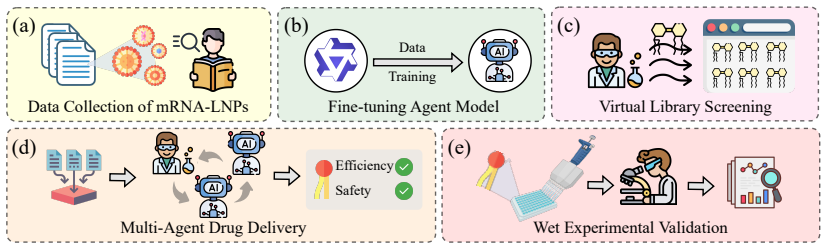
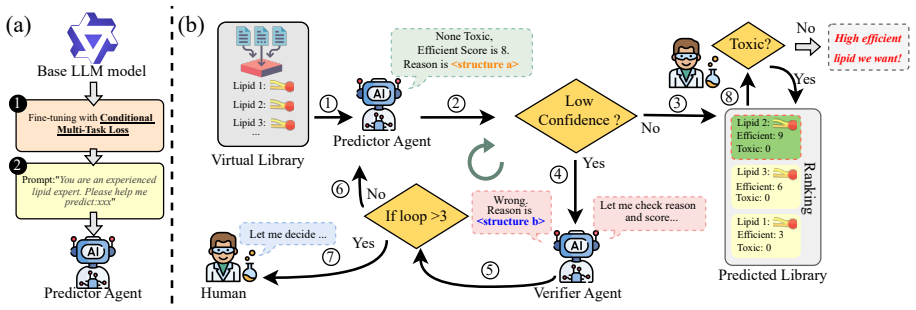
Lipid nanoparticles (LNPs) are among the most clinically mature platforms for nucleic acid delivery, yet designing lipids that are both effective and biologically safe remains a major bottleneck. In practical screening, toxicity is a decision-level constraint: if a lipid is toxic, its efficiency prediction is clinically irrelevant. We propose LipoAgent, a safety-aware multi-agent LLM framework for lipid discovery. LipoAgent combines domain-specific finetuning with a conditional prediction objective that enforces toxicity as a prerequisite for efficiency prediction, and further improves reliability via multi-agent verification with lightweight human oversight when disagreement persists. Across multiple foundation models, LipoAgent achieves an average 32% relative improvement in mRNA transfection efficiency prediction compared with other reported models for lipid design. Wet-lab validation confirms that virtual screening rankings reliably translate to biological transfection outcomes. The code is publicly available at https://github.com/SAI-Lab-NYU/LipoAgent.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LipoAgent, a multi-agent LLM framework for lipid nanoparticle design that combines domain-specific fine-tuning with a conditional prediction objective (toxicity as prerequisite for efficiency) and multi-agent verification. It reports an average 32% relative improvement in mRNA transfection efficiency prediction across foundation models versus prior models for lipid design, with wet-lab validation showing that virtual screening rankings translate to biological outcomes. Code is released publicly.
Significance. If the performance claims and generalization hold, the work could advance safer LNP design by embedding toxicity constraints directly into the prediction pipeline. Public code release supports reproducibility and is a clear strength.
major comments (3)
- [Abstract] The central 32% relative improvement claim (abstract) is presented without any description of baseline models, dataset sizes, data splits, or statistical tests; this information is load-bearing for evaluating whether the gain is attributable to the conditional objective or to other factors.
- [Evaluation / Results] No out-of-distribution split, scaffold diversity analysis, or chemical-space coverage (e.g., via molecular fingerprints) is reported to test whether the toxicity-first conditional objective plus multi-agent verification generalizes to structurally novel lipids outside the training distribution; this directly bears on the safety-aware generalization claim.
- [Methods] The precise implementation of the conditional prediction objective (how toxicity is enforced as a prerequisite) and the multi-agent verification protocol are not specified, preventing assessment of whether reported gains could arise from hyperparameter tuning or data selection rather than the proposed mechanisms.
minor comments (1)
- [Abstract] The abstract is information-dense; expanding the methods summary to include at least one sentence on dataset scale and evaluation protocol would improve readability without lengthening the paper.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] The central 32% relative improvement claim (abstract) is presented without any description of baseline models, dataset sizes, data splits, or statistical tests; this information is load-bearing for evaluating whether the gain is attributable to the conditional objective or to other factors.
Authors: We agree the abstract should provide more context on the evaluation setup. In the revision we will add a concise description of the baseline models compared, dataset size, and note that statistical significance was evaluated using paired t-tests as reported in Section 4. Full experimental details remain in the Methods and Results sections. revision: yes
-
Referee: [Evaluation / Results] No out-of-distribution split, scaffold diversity analysis, or chemical-space coverage (e.g., via molecular fingerprints) is reported to test whether the toxicity-first conditional objective plus multi-agent verification generalizes to structurally novel lipids outside the training distribution; this directly bears on the safety-aware generalization claim.
Authors: The current evaluation uses the full available dataset with wet-lab confirmation. We will add a new analysis subsection reporting scaffold diversity via Bemis-Murcko scaffolds and Tanimoto similarity on Morgan fingerprints to characterize chemical-space coverage. A strict temporal or scaffold-based OOD split is not feasible with the existing data without new synthesis; we will explicitly discuss this limitation and the implications for generalization. revision: partial
-
Referee: [Methods] The precise implementation of the conditional prediction objective (how toxicity is enforced as a prerequisite) and the multi-agent verification protocol are not specified, preventing assessment of whether reported gains could arise from hyperparameter tuning or data selection rather than the proposed mechanisms.
Authors: We will expand Section 3.2 to include the exact formulation of the conditional objective (toxicity prediction first, efficiency only if toxicity score below threshold, with the mathematical conditioning) and Section 3.3 to specify the multi-agent protocol (three agents, majority vote, disagreement threshold triggering lightweight human review). Pseudocode and all hyperparameters will be added to ensure reproducibility. revision: yes
Circularity Check
No circularity; empirical comparisons and external validation stand independently
full rationale
The paper introduces LipoAgent as a multi-agent LLM framework with a conditional objective and reports relative improvements versus external baselines plus wet-lab confirmation. No equations, self-citations, or fitted parameters are shown reducing the claimed 32% gain or generalization claim to the inputs by construction. The conditional toxicity-first objective is a modeling choice, not a redefinition of the target metric. Absence of OOD analysis is a generalization concern, not circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
CAMEL: Communicative Agents for "Mind" Exploration of Large Language Model Society
Lipid nanoparticles for mrna delivery.Nature Reviews Materials, 6:1078–1094. Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, and 1 others. 2022. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3. Kexin Huang, Tianfan Fu, Lucas M Glass, Marinka Zit- nik, Cao Xiao, and Jimeng Sun. 2020....
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Reflexion: Language agents with verbal rein- forcement learning.Preprint, arXiv:2303.11366. K. Su, J. Qiu, T. Xu, and S. Liu. 2026a. Artifi- cial intelligence-guided design of lipid nanoparticles for mrna delivery.Acta Pharmaceutica Sinica B, 16(2):709–727. Kexin Su, Junjie Qiu, Tengfei Xu, and Shuai Liu. 2026b. Artificial intelligence-guided design of li...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Yizhen Zheng, Huan Yee Koh, Maddie Yang, Li Li, Lau- ren T
Rational design of lipid nanoparticles: over- coming physiological barriers for selective intracel- lular mrna delivery.Current Opinion in Chemical Biology, 81:102499. Yizhen Zheng, Huan Yee Koh, Maddie Yang, Li Li, Lau- ren T. May, Geoffrey I. Webb, Shirui Pan, and George Church. 2024. Large language models in drug dis- covery and development: From disea...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.