A Multimodal Framework for Dementia Detection via Linguistic and Acoustic Representation Learning
Pith reviewed 2026-06-29 20:56 UTC · model grok-4.3
The pith
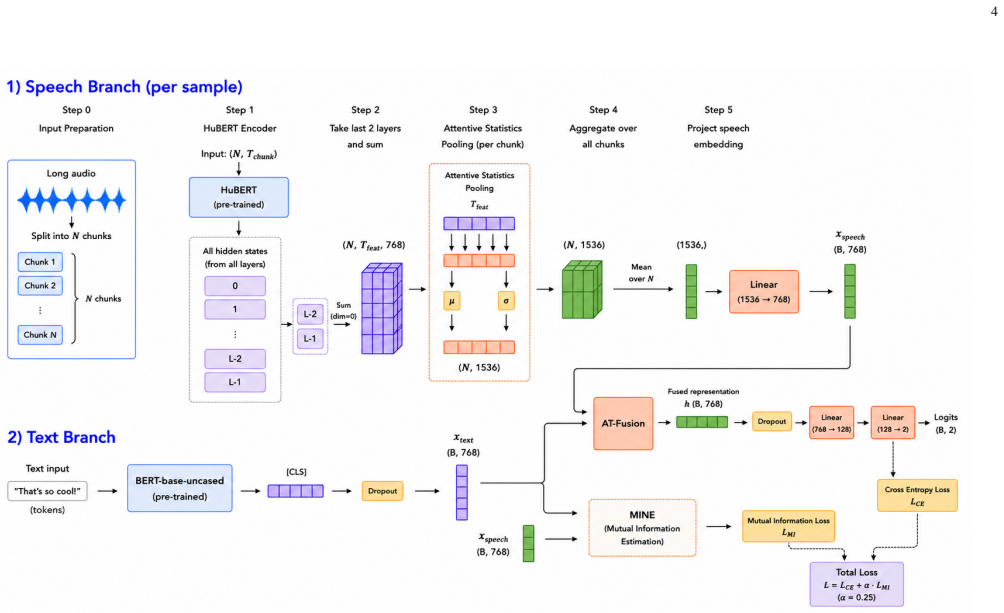
A multimodal framework fuses pre-trained HuBERT acoustic and BERT linguistic representations with attention and mutual information maximization to detect dementia from speech.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that jointly training a fusion of HuBERT-derived acoustic representations and BERT-derived linguistic embeddings, enhanced by attention-based fusion and a mutual information maximization objective, enables robust dementia detection from spontaneous speech on standard benchmark datasets.
What carries the argument
The Audio-Text Fusion (AT-Fusion) attention mechanism together with the MINE objective that explicitly maximizes dependency between speech and transcript representations.
If this is right
- The fused representation improves classification accuracy over independent modality models or simple concatenation.
- The framework works without requiring domain-specific fine-tuning of the base encoders.
- Attentive statistics pooling captures temporal characteristics in speech better than standard pooling for this task.
- The approach shows robustness across the ADReSS and PROCESS-2 datasets.
Where Pith is reading between the lines
- Similar fusion strategies could extend to other neurodegenerative conditions detectable in speech.
- Replacing the pre-trained models with dementia-specific fine-tuned versions might further improve performance if biomarkers are not fully captured.
- Real-time applications could segment live speech into 10-second clips for ongoing monitoring.
Load-bearing premise
That general-purpose pre-trained HuBERT and BERT models already contain the acoustic and linguistic biomarkers relevant to dementia without any domain adaptation.
What would settle it
A direct comparison on the ADReSS dataset showing that the multimodal model with AT-Fusion and MINE does not achieve higher accuracy than a strong unimodal baseline or a simple concatenation baseline.
Figures
read the original abstract
Alzheimer's disease (AD) is a progressive neurodegenerative disorder and the leading cause of dementia, affecting memory, reasoning, communication, and daily functioning. Early diagnosis is particularly important, as timely intervention may help slow cognitive decline and improve patient care. Recent studies have demonstrated that spontaneous speech contains valuable linguistic and acoustic biomarkers associated with dementia. However, existing approaches often rely on independently trained modality-specific models, feature concatenation strategies, ensemble methods, or attention-based fusion mechanisms that do not explicitly maximize the dependency between speech and transcript representations. In this work, we propose a multimodal deep learning framework for automatic dementia detection that jointly exploits speech and transcript information in an end-to-end trainable manner. Specifically, speech recordings are divided into 10-second segments and passed through a pre-trained HuBERT model to extract contextualized acoustic representations. To better capture informative temporal speech characteristics, attentive statistics pooling is employed to aggregate frame-level acoustic embeddings. For the textual modality, transcripts are encoded using a pre-trained BERT model, where the [CLS] token representation is used as the linguistic embedding. The acoustic and textual representations are subsequently combined using an attention-based Audio-Text Fusion (AT-Fusion) mechanism. In addition, we introduce a MINE objective to maximize the mutual information between modalities and improve multimodal representation alignment. The fused multimodal representation is finally used for dementia classification. Experiments conducted on the publicly available ADReSS Challenge and PROCESS-2 dataset demonstrate the effectiveness and robustness of the proposed approach for speech-based dementia assessment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a multimodal framework for dementia detection that processes 10-second speech segments through a pre-trained HuBERT model followed by attentive statistics pooling for acoustic embeddings, encodes transcripts via a pre-trained BERT model's [CLS] token for linguistic embeddings, fuses them with an attention-based Audio-Text Fusion (AT-Fusion) mechanism, applies a MINE objective to maximize mutual information between modalities, and feeds the result to a classifier. Experiments on the ADReSS Challenge and PROCESS-2 datasets are stated to demonstrate the effectiveness and robustness of this end-to-end approach over prior modality-specific or simple fusion methods.
Significance. If the experimental results hold and show gains attributable to the AT-Fusion and MINE components rather than the final classifier, the work would contribute a concrete method for explicitly aligning acoustic and linguistic representations in dementia assessment, addressing a noted limitation in existing concatenation or ensemble strategies. The reliance on unmodified general-purpose pre-trained models is a potential efficiency advantage if the biomarkers are already encoded.
major comments (2)
- [Abstract] Abstract (pipeline description): The central claim that the framework demonstrates effectiveness depends on the assumption that unmodified pre-trained HuBERT and BERT models already encode dementia-relevant acoustic (e.g., prosody) and linguistic (e.g., syntactic) biomarkers that AT-Fusion and MINE can usefully combine; no evidence or adaptation step is described to confirm these signals are present or extractable from the pre-training corpora, which risks attributing any reported gains to dataset artifacts or the downstream classifier instead.
- [Abstract] Abstract: The assertion that experiments 'demonstrate the effectiveness and robustness' supplies no numerical results, baselines, statistical tests, or error analysis, preventing evaluation of whether the multimodal components improve over unimodal or simpler fusion baselines as claimed.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract (pipeline description): The central claim that the framework demonstrates effectiveness depends on the assumption that unmodified pre-trained HuBERT and BERT models already encode dementia-relevant acoustic (e.g., prosody) and linguistic (e.g., syntactic) biomarkers that AT-Fusion and MINE can usefully combine; no evidence or adaptation step is described to confirm these signals are present or extractable from the pre-training corpora, which risks attributing any reported gains to dataset artifacts or the downstream classifier instead.
Authors: The manuscript explicitly uses unmodified pre-trained HuBERT and BERT as feature extractors to obtain general contextualized representations, consistent with standard transfer-learning practice for speech and text. The contribution centers on the AT-Fusion mechanism and MINE objective for cross-modal alignment rather than on domain-specific adaptation of the backbones. We agree the abstract phrasing could be tightened to avoid implying direct encoding of dementia biomarkers. We will revise the abstract to state that the pre-trained models supply general acoustic and linguistic representations and that the proposed components are responsible for their task-specific combination. revision: yes
-
Referee: [Abstract] Abstract: The assertion that experiments 'demonstrate the effectiveness and robustness' supplies no numerical results, baselines, statistical tests, or error analysis, preventing evaluation of whether the multimodal components improve over unimodal or simpler fusion baselines as claimed.
Authors: Abstract length limits preclude inclusion of full numerical tables or statistical details. The full manuscript reports comparative results against unimodal and simpler fusion baselines on both ADReSS and PROCESS-2. To strengthen the abstract, we will add concise quantitative statements (e.g., accuracy or F1 improvements) that directly reference the multimodal gains while remaining within typical abstract constraints. revision: yes
Circularity Check
No circularity: framework uses external pre-trained models and standard losses without self-referential derivations
full rationale
The paper presents an empirical multimodal pipeline (HuBERT + attentive pooling for audio, BERT [CLS] for text, AT-Fusion, MINE objective) whose central claim rests on experimental results on ADReSS and PROCESS-2 rather than any derivation. No equations appear that define a quantity in terms of itself or rename a fitted parameter as a prediction. MINE is an independently published external loss; pre-trained models are cited as off-the-shelf components. No self-citation chain is invoked to justify uniqueness or forbid alternatives. The derivation chain is therefore self-contained against external benchmarks and datasets.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Available online at: https://www
World Health Organization.Dementia. Available online at: https://www. who.int/news-room/fact-sheets/detail/dementia, 2021
2021
-
[2]
Explainable identification of dementia from transcripts using transformer networks.IEEE Journal of Biomedical and Health Informatics, 26(8):4153–4164, 2022
Loukas Ilias and Dimitris Askounis. Explainable identification of dementia from transcripts using transformer networks.IEEE Journal of Biomedical and Health Informatics, 26(8):4153–4164, 2022
2022
-
[3]
Harris, Jennifer C
Yilin Pan, Bahman Mirheidari, Jennifer M. Harris, Jennifer C. Thomp- son, Matthew Jones, Julie S. Snowden, Daniel Blackburn, and Heidi Christensen. Using the Outputs of Different Automatic Speech Recogni- tion Paradigms for Acoustic- and BERT-Based Alzheimer’s Dementia Detection Through Spontaneous Speech. InInterspeech 2021, pages 3810–3814, 2021
2021
-
[4]
Integrating pause information with word embeddings in language models for alzheimer’s disease detection from spontaneous speech
Yu Pu and Wei-Qiang Zhang. Integrating pause information with word embeddings in language models for alzheimer’s disease detection from spontaneous speech. InICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5, 2025
2025
-
[5]
Linguistic features extracted by GPT-4 improve Alzheimer’s disease detection based on spontaneous speech
Jonathan Heitz, Gerold Schneider, and Nicolas Langer. Linguistic features extracted by GPT-4 improve Alzheimer’s disease detection based on spontaneous speech. In Owen Rambow, Leo Wanner, Marianna Apidianaki, Hend Al-Khalifa, Barbara Di Eugenio, and Steven Schockaert, editors,Proceedings of the 31st International Conference on Computational Linguistics, p...
-
[6]
Association for Computational Linguistics
-
[7]
Alzheimer Disease Recognition Using Speech-Based Embeddings From Pre-Trained Models
Lara Gauder, Leonardo Pepino, Luciana Ferrer, and Pablo Riera. Alzheimer Disease Recognition Using Speech-Based Embeddings From Pre-Trained Models. InInterspeech 2021, pages 3795–3799, 2021
2021
-
[8]
Comparing Acoustic- Based Approaches for Alzheimer’s Disease Detection
Aparna Balagopalan and Jekaterina Novikova. Comparing Acoustic- Based Approaches for Alzheimer’s Disease Detection. InInterspeech 2021, pages 3800–3804, 2021
2021
-
[9]
Consen: Complementary and simultaneous ensemble for alzheimer’s disease detection and mmse score prediction
Longbin Jin, Yealim Oh, Hyunseo Kim, Hyuntaek Jung, Hyo Jin Jon, Jung Eun Shin, and Eun Yi Kim. Consen: Complementary and simultaneous ensemble for alzheimer’s disease detection and mmse score prediction. InICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–2, 2023
2023
-
[10]
Priyanka and K
G. Priyanka and K. Amshakala. Predicting dementia through audio: En- semble and deep learning approaches using acoustic features.Computers in Biology and Medicine, 197:111078, 2025
2025
-
[11]
A dual-stage time-context network for speech-based alzheimer’s disease detection.IEEE Signal Processing Letters, 33:788–792, 2026
Yifan Gao, Long Guo, and Hong Liu. A dual-stage time-context network for speech-based alzheimer’s disease detection.IEEE Signal Processing Letters, 33:788–792, 2026
2026
-
[12]
Zakaria Kurdi
M. Zakaria Kurdi. Integrating acoustic, prosodic, and phonological features for automatic alzheimer’s detection.Frontiers in Aging Neuroscience, V olume 18 - 2026, 2026
2026
-
[13]
Multimodal deep learning models for detecting dementia from speech and transcripts.Frontiers in Aging Neuroscience, V olume 14 - 2022, 2022
Loukas Ilias and Dimitris Askounis. Multimodal deep learning models for detecting dementia from speech and transcripts.Frontiers in Aging Neuroscience, V olume 14 - 2022, 2022
2022
-
[14]
Detecting dementia from speech and transcripts using transformers.Computer Speech & Language, 79:101485, 2023
Loukas Ilias, Dimitris Askounis, and John Psarras. Detecting dementia from speech and transcripts using transformers.Computer Speech & Language, 79:101485, 2023
2023
-
[15]
A multimodal ap- proach for dementia detection from spontaneous speech with tensor fusion layer
Loukas Ilias, Dimitris Askounis, and John Psarras. A multimodal ap- proach for dementia detection from spontaneous speech with tensor fusion layer. In2022 IEEE-EMBS International Conference on Biomedical and Health Informatics (BHI), pages 1–5, 2022
2022
-
[16]
Flores Vizcaya-Moreno, and Marco Leo
David Ortiz-Perez, Pablo Ruiz-Ponce, David Tomás, Jose Garcia- Rodriguez, M. Flores Vizcaya-Moreno, and Marco Leo. A deep learning-based multimodal architecture to predict signs of dementia. Neurocomputing, 548:126413, 2023
2023
-
[17]
Yilin Pan, Bahman Mirheidari, Daniel Blackburn, and Heidi Christensen. A two-step attention-based feature combination cross-attention system for speech-based dementia detection.IEEE Transactions on Audio, Speech and Language Processing, 33:896–907, 2025
2025
-
[18]
Trunfio, and Enrico Grosso
Filippo Casu, Andrea Lagorio, Pietro Ruiu, Giuseppe A. Trunfio, and Enrico Grosso. Integrating fine-tuned llm with acoustic features for enhanced detection of alzheimer’s disease.IEEE Journal of Biomedical and Health Informatics, pages 1–14, 2025
2025
-
[19]
A dual-modal fusion framework for detection of mild cognitive impairment based on autobiographical memory.IEEE Journal of Biomedical and Health Informatics, 29(6):4474–4485, 2025
Ho-Ling Chang, Thiri Wai, Yu-Shan Liao, Sheng-Ya Lin, Yu-Ling Chang, and Li-Chen Fu. A dual-modal fusion framework for detection of mild cognitive impairment based on autobiographical memory.IEEE Journal of Biomedical and Health Informatics, 29(6):4474–4485, 2025
2025
-
[20]
Zhenglin Zhang, Tengfei Wang, Zian Hu, Li-Zhuang Yang, and Hai Li. Dementia: A hybrid attention-based multimodal and multi-task learning framework with expert knowledge for alzheimer’s disease assessment from speech.IEEE Journal of Biomedical and Health Informatics, 29(4):2957–2968, 2025
2025
-
[21]
An unsupervised alignment feature fusion system for spoken language-based dementia detection
Yilin Pan, Ziteng Gong, Sui Wang, Zhuoran Tian, Tsy Yih, and Lihe Huang. An unsupervised alignment feature fusion system for spoken language-based dementia detection. InICASSP 2026 - 2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 15597–15601, 2026
2026
-
[22]
Admarker: A multi-modal federated learning system for monitoring digital biomarkers of alzheimer’s disease
Xiaomin Ouyang, Xian Shuai, Yang Li, Li Pan, Xifan Zhang, Heming Fu, Sitong Cheng, Xinyan Wang, Shihua Cao, Jiang Xin, Hazel Mok, Zhenyu Yan, Doris Sau Fung Yu, Timothy Kwok, and Guoliang Xing. Admarker: A multi-modal federated learning system for monitoring digital biomarkers of alzheimer’s disease. InProceedings of the 30th Annual International Conferen...
2024
-
[23]
Catarina Botelho, David Gimeno-Gómez, Francisco Teixeira, John Mendonça, Patrícia Pereira, Diogo A. P. Nunes, Thomas Rolland, Anna Pompili, Rubén Solera-Ureña, Maria Ponte, David Martins de Matos, Carlos-D. Martínez-Hinarejos, Isabel Trancoso, and Alberto Abad. Acoustic and Linguistic Biomarkers for Cognitive Impairment Detection from Speech. InInterspeec...
2025
-
[24]
Comparing Natural Language Processing Techniques for Alzheimer’s Dementia Prediction in Spontaneous Speech
Thomas Searle, Zina Ibrahim, and Richard Dobson. Comparing Natural Language Processing Techniques for Alzheimer’s Dementia Prediction in Spontaneous Speech. InInterspeech 2020, pages 2192–2196, 2020
2020
-
[25]
To BERT or not to BERT: Comparing Speech and Language- Based Approaches for Alzheimer’s Disease Detection
Aparna Balagopalan, Benjamin Eyre, Frank Rudzicz, and Jekaterina Novikova. To BERT or not to BERT: Comparing Speech and Language- Based Approaches for Alzheimer’s Disease Detection. InInterspeech 2020, pages 2167–2171, 2020
2020
-
[26]
Multi-Modal Fusion with Gating Using Audio, Lexical and Disfluency Features for Alzheimer’s Dementia Recognition from Spontaneous Speech
Morteza Rohanian, Julian Hough, and Matthew Purver. Multi-Modal Fusion with Gating Using Audio, Lexical and Disfluency Features for Alzheimer’s Dementia Recognition from Spontaneous Speech. In Interspeech 2020, pages 2187–2191, 2020. 11
2020
-
[27]
Batsis, and Robert M
Youxiang Zhu, Xiaohui Liang, John A. Batsis, and Robert M. Roth. Exploring deep transfer learning techniques for alzheimer’s dementia detection.Frontiers in Computer Science, V olume 3 - 2021, 2021
2021
-
[28]
Liu, Shu-wen Yang, Po-Han Chi, Po-chun Hsu, and Hung-yi Lee
Andy T. Liu, Shu-wen Yang, Po-Han Chi, Po-chun Hsu, and Hung-yi Lee. Mockingjay: Unsupervised speech representation learning with deep bidirectional transformer encoders. InICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6419–6423, 2020
2020
-
[29]
Alzheimer’s Dementia Recognition Through Spontaneous Speech: The ADReSS Challenge
Saturnino Luz, Fasih Haider, Sofia de la Fuente, Davida Fromm, and Brian MacWhinney. Alzheimer’s Dementia Recognition Through Spontaneous Speech: The ADReSS Challenge. InInterspeech 2020, pages 2172–2176, 2020
2020
-
[30]
Becker, François Boiler, Oscar L
James T. Becker, François Boiler, Oscar L. Lopez, Judith Saxton, and Karen L. McGonigle. The natural history of alzheimer’s disease: Description of study cohort and accuracy of diagnosis.Archives of Neurology, 51(6):585–594, 06 1994
1994
-
[31]
PROCESS-2: A Benchmark Speech Corpus for Early Cognitive Impairment Detection
Madhurananda Pahar, Caitlin H. Illingworth, Bahman Mirheidari, Hend Elghazaly, Fritz Peters, Sophie Young, Wing-Zin Leung, Labhpreet Kaur, Daniel Blackburn, and Heidi Christensen. PROCESS-2: A benchmark speech corpus for early cognitive impairment detection.arXiv preprint arXiv:2605.14888, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Attentive Statistics Pooling for Deep Speaker Embedding
Koji Okabe, Takafumi Koshinaka, and Koichi Shinoda. Attentive Statistics Pooling for Deep Speaker Embedding. InInterspeech 2018, pages 2252– 2256, 2018
2018
-
[33]
Mutual information neural estimation
Mohamed Ishmael Belghazi, Aristide Baratin, Sai Rajeshwar, Sherjil Ozair, Yoshua Bengio, Aaron Courville, and Devon Hjelm. Mutual information neural estimation. In Jennifer Dy and Andreas Krause, editors,Proceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 531–540. PMLR, 10–15 Jul 2018
2018
-
[34]
LoRA-MER: Low- Rank Adaptation of Pre-Trained Speech Models for Multimodal Emotion Recognition Using Mutual Information
Yunrui Cai, Zhiyong Wu, Jia Jia, and Helen Meng. LoRA-MER: Low- Rank Adaptation of Pre-Trained Speech Models for Multimodal Emotion Recognition Using Mutual Information. InInterspeech 2024, pages 4658–4662, 2024
2024
-
[35]
Context-Dependent Domain Adversarial Neural Network for Multimodal Emotion Recognition
Zheng Lian, Jianhua Tao, Bin Liu, Jian Huang, Zhanlei Yang, and Rongjun Li. Context-Dependent Domain Adversarial Neural Network for Multimodal Emotion Recognition. InInterspeech 2020, pages 394–398, 2020
2020
-
[36]
wav2vec 2.0: a framework for self-supervised learning of speech representations
Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, and Michael Auli. wav2vec 2.0: a framework for self-supervised learning of speech representations. InProceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’20, Red Hook, NY , USA,
-
[37]
Curran Associates Inc
-
[38]
XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale
Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, and Michael Auli. XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale. InInterspeech 2022, pages 2278–2282, 2022
2022
-
[39]
Gated multimodal networks.Neural Computing and Applications, pages 1–20, 2020
John Arevalo, Thamar Solorio, Manuel Montes-y Gomez, and Fabio A González. Gated multimodal networks.Neural Computing and Applications, pages 1–20, 2020
2020
-
[40]
Mutan: Multimodal tucker fusion for visual question answering
Hedi Ben-younes, Remi Cadene, Matthieu Cord, and Nicolas Thome. Mutan: Multimodal tucker fusion for visual question answering. InICCV, pages 2631–2639, 2017
2017
-
[41]
Beyond bilinear: Generalized multimodal factorized high-order pooling for visual question answering.IEEE TNNLS, 2018
Zhou Yu, Jun Yu, Chenchao Xiang, Jianping Fan, and Dacheng Tao. Beyond bilinear: Generalized multimodal factorized high-order pooling for visual question answering.IEEE TNNLS, 2018
2018
-
[42]
Block: Bilinear superdiagonal fusion for visual question answering and visual relationship detection.AAAI, (01), 2019
Hedi Ben-younes, Remi Cadene, Nicolas Thome, and Matthieu Cord. Block: Bilinear superdiagonal fusion for visual question answering and visual relationship detection.AAAI, (01), 2019
2019
-
[43]
Decompositions of a higher-order tensor in block terms—part ii: Definitions and uniqueness.SIMAX, 30(3):1033–1066, 2008
Lieven De Lathauwer. Decompositions of a higher-order tensor in block terms—part ii: Definitions and uniqueness.SIMAX, 30(3):1033–1066, 2008
2008
-
[44]
eckart-young
J Douglas Carroll and Jih-Jie Chang. Analysis of individual differences in multidimensional scaling via an n-way generalization of “eckart-young” decomposition.Psychometrika, 35(3):283–319, 1970
1970
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.