Multi-Agent Coordination Adaptation via Structure-Guided Orchestration
Pith reviewed 2026-06-29 19:33 UTC · model grok-4.3
The pith
MACA learns a task- and budget-conditioned structural prior to guide orchestration as approximate posterior inference over joint structure and coordination decisions in LLM multi-agent systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
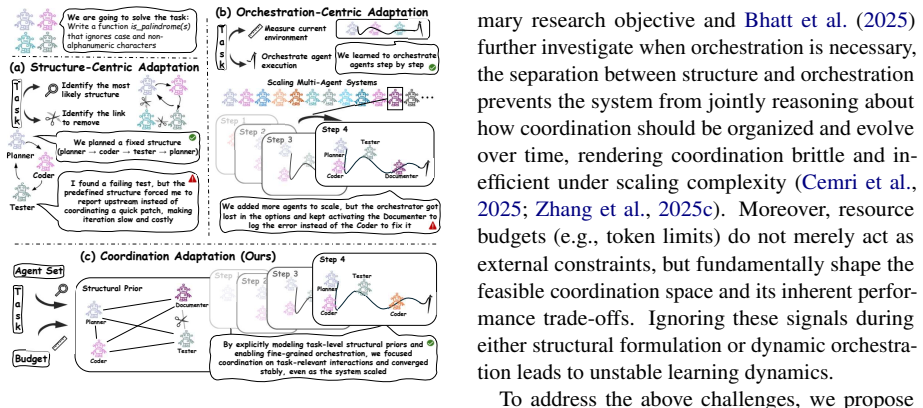
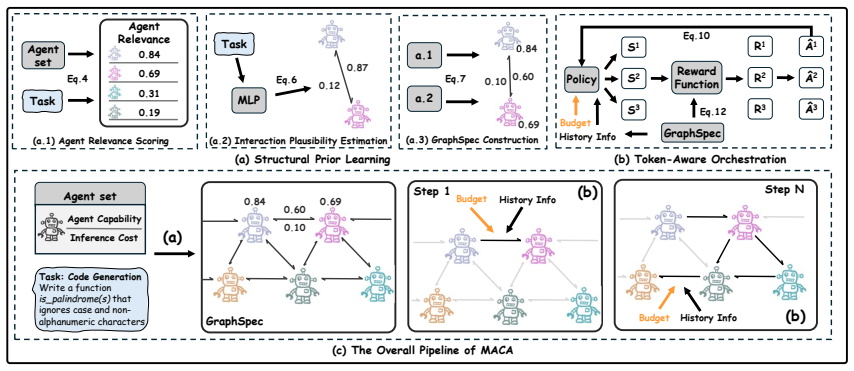
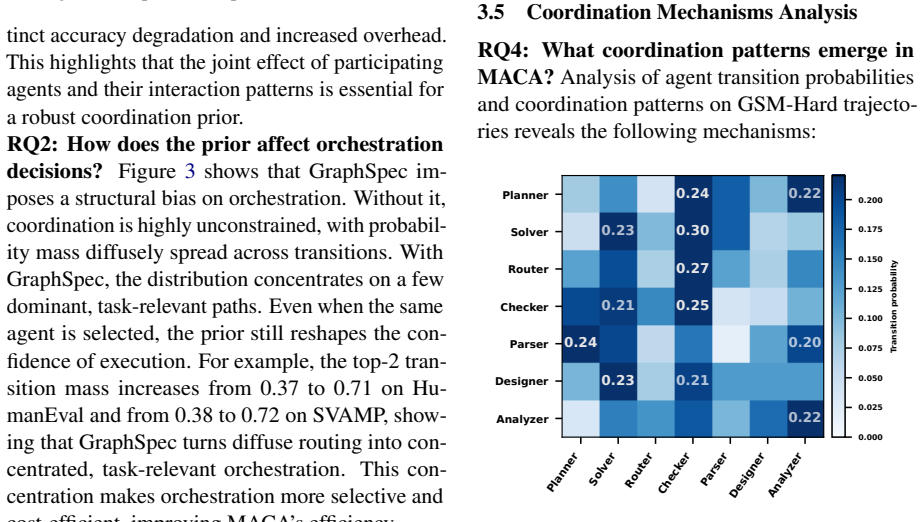
We introduce MACA, an automated coordination framework that learns a task- and budget-conditioned structural prior over agent participation and interactions. This prior guides a policy-based orchestration as an approximation to posterior inference, enabling efficient solutions with fine-grained control. Across benchmarks, MACA outperforms adaptive multi-agent baselines by an average of 8.42% while using 43.19% fewer tokens. Further investigation reveals that joint adaptation of structure and orchestration suppresses redundant interactions, converging coordination toward task-effective execution.
What carries the argument
A learnable task- and budget-conditioned structural prior over agent participation and interactions that guides policy-based orchestration as an approximation to posterior inference over the joint distribution of structure and orchestration.
If this is right
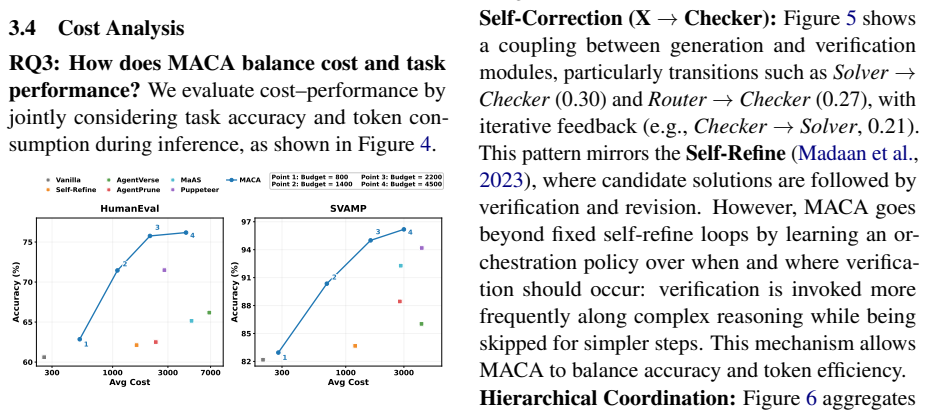
- Joint adaptation of structure and orchestration yields higher task performance than either structure-centric or orchestration-centric methods alone.
- Coordination converges toward task-effective execution by suppressing redundant interactions.
- Systems gain fine-grained control while maintaining structural stability.
- Token consumption drops substantially on complex tasks without loss of capability.
Where Pith is reading between the lines
- The same prior-guided inference pattern could be tested on non-LLM multi-agent control problems where interaction cost is a budget constraint.
- If the prior can be learned from limited demonstrations, it may reduce the need for hand-designed coordination graphs in new domains.
- Scaling the budget-conditioning to very large agent teams could expose whether the approximation remains tractable.
Load-bearing premise
That a learnable task- and budget-conditioned structural prior over agent participation and interactions can be obtained and used as an effective guide for posterior inference in orchestration.
What would settle it
Running the reported benchmarks and finding that MACA does not outperform the adaptive baselines by the stated margin or fails to reduce token usage by the stated amount.
Figures






read the original abstract
As large language model (LLM)-based multi-agent systems scale to handle increasingly complex tasks, balancing structural stability and dynamic adaptability becomes increasingly challenging. Existing systems typically adopt either structure-centric methods, committing to structures determined upfront that limit fine-grained control, or orchestration-centric methods, adapting decisions dynamically while leaving coordination structure implicit and unstable. To address this challenge, we revisit multi-agent coordination from a probabilistic perspective, casting it as posterior inference over the joint distribution of structure and orchestration. We introduce MACA, an automated coordination framework that learns a task- and budget-conditioned structural prior over agent participation and interactions. This prior guides a policy-based orchestration as an approximation to posterior inference, enabling efficient solutions with fine-grained control. Across benchmarks, MACA outperforms adaptive multi-agent baselines by an average of 8.42% while using 43.19% fewer tokens. Further investigation reveals that joint adaptation of structure and orchestration suppresses redundant interactions, converging coordination toward task-effective execution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MACA, a framework for LLM-based multi-agent coordination that revisits the problem from a probabilistic perspective by casting coordination as posterior inference over the joint distribution p(structure, orchestration | task, budget). It learns a task- and budget-conditioned structural prior over agent participation and interactions, which then guides a policy-based orchestration procedure presented as an approximation to that posterior. The approach is claimed to enable joint adaptation that suppresses redundant interactions. Empirical results across benchmarks report an average 8.42% outperformance over adaptive multi-agent baselines together with a 43.19% reduction in token usage.
Significance. If the probabilistic construction can be shown to deliver the reported gains through an explicit generative model and inference procedure rather than through an ordinary learned heuristic, the work would supply a principled mechanism for trading off structural stability against dynamic adaptability while controlling interaction cost. The token-reduction result would be particularly valuable for scaling multi-agent LLM systems. At present the absence of the required modeling details prevents attribution of the performance numbers to the claimed probabilistic framing.
major comments (1)
- [Abstract] Abstract, paragraph 3: the central claim that coordination is cast as posterior inference over p(structure, orchestration | task, budget) and that the orchestration policy approximates this posterior is unsupported by any likelihood, observation model, explicit prior form, or derivation showing the approximation (e.g., variational, amortized, or MCMC). Without these elements the reported 8.42% gain and 43.19% token reduction cannot be attributed to the joint probabilistic adaptation rather than to a conventional learned controller; this is load-bearing for the paper’s main contribution.
Simulated Author's Rebuttal
We thank the referee for the careful reading and the identification of a load-bearing issue in the probabilistic framing. We address the single major comment below and will incorporate the requested modeling details in a revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract, paragraph 3: the central claim that coordination is cast as posterior inference over p(structure, orchestration | task, budget) and that the orchestration policy approximates this posterior is unsupported by any likelihood, observation model, explicit prior form, or derivation showing the approximation (e.g., variational, amortized, or MCMC). Without these elements the reported 8.42% gain and 43.19% token reduction cannot be attributed to the joint probabilistic adaptation rather than to a conventional learned controller; this is load-bearing for the paper’s main contribution.
Authors: We agree that the current manuscript does not supply an explicit likelihood, observation model, or derivation of the approximation, which prevents rigorous attribution of the reported gains to the claimed posterior-inference construction. The structural prior is learned as a task- and budget-conditioned distribution over agent graphs, and the orchestration policy is trained to produce structures and interaction schedules that perform well under the budget; however, these components are not derived from a generative model with a stated likelihood. In the revision we will add a new section that (1) defines the generative model with an observation model based on task outcome likelihood, (2) specifies the prior as a graph-structured distribution parameterized by a neural network, and (3) presents the policy as an amortized variational approximation whose training objective is the evidence lower bound. The abstract and introduction will be updated to reflect these additions. This change will allow readers to evaluate whether the performance numbers arise from the probabilistic mechanism rather than from a conventional controller. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper frames multi-agent coordination as posterior inference over a joint distribution of structure and orchestration, with a learned task- and budget-conditioned structural prior guiding a policy-based orchestration approximation. This is presented explicitly as a modeling choice rather than derived from equations that reduce the claimed 8.42% performance gain or token reduction to a fitted parameter or self-referential definition. No load-bearing self-citations, uniqueness theorems, or ansatzes are quoted that collapse the joint adaptation result to its inputs by construction. The derivation remains self-contained as an empirical modeling approach supported by benchmark comparisons, with no exhibited reductions of the form Eq. X = Eq. Y.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-agent coordination can be usefully cast as posterior inference over the joint distribution of structure and orchestration.
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code.Preprint, arXiv:2107.03374. Weize Chen, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Chi-Min Chan, Heyang Yu, Yaxi Lu, Yi-Hsin Hung, Chen Qian, and 1 others. 2024. Agent- verse: Facilitating multi-agent collaboration and ex- ploring emergent behaviors. InICLR. Yixing Chen, Yiding Wang, Siqi Zhu, Haofe...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
arXiv preprint arXiv:2401.03428
Exploring large language model based intel- ligent agents: Definitions, methods, and prospects. arXiv preprint arXiv:2401.03428. Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv:1803.05457v1. Yufan Dang,...
-
[3]
A survey on llm-based multi-agent sys- tems: workflow, infrastructure, and challenges.Vici- nagearth, 1(1):9. Zhixun Li, Liang Wang, Xin Sun, Yifan Luo, Yanqiao Zhu, Dingshuo Chen, Yingtao Luo, Xiangxin Zhou, Qiang Liu, Shu Wu, and 1 others. 2023b. Gslb: the graph structure learning benchmark.Advances in Neural Information Processing Systems, 36:30306– 30...
-
[4]
Arkil Patel, Satwik Bhattamishra, and Navin Goyal
Making sense of reinforcement learn- ing and probabilistic inference.arXiv preprint arXiv:2001.00805. Arkil Patel, Satwik Bhattamishra, and Navin Goyal
-
[5]
Are NLP Models really able to Solve Simple Math Word Problems?
Are nlp models really able to solve simple math word problems?arXiv preprint arXiv:2103.07191. Adnan Qayyum, Abdullatif Albaseer, Junaid Qadir, Ala Al-Fuqaha, and Mohamed Abdallah. 2025. Llm- driven multi-agent architectures for intelligent self- organizing networks.IEEE Network. Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Ya...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Yashar Talebirad and Amirhossein Nadiri
Llm-based multi-agent reinforcement learn- ing: Current and future directions.arXiv preprint arXiv:2405.11106. Yashar Talebirad and Amirhossein Nadiri. 2023. Multi- agent collaboration: Harnessing the power of intelli- gent llm agents.arXiv preprint arXiv:2306.03314. Xiangru Tang, Anni Zou, Zhuosheng Zhang, Ziming Li, Yilun Zhao, Xingyao Zhang, Arman Coha...
-
[7]
Large Language Model-based Data Science Agent: A Survey,
Agentinit: Initializing llm-based multi-agent systems via diversity and expertise orchestration for effective and efficient collaboration. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 11870–11902. Xiaoguang Tu, Zhi He, Yi Huang, Zhi-Hao Zhang, Ming Yang, and Jian Zhao. 2024. An overview of large ai models and their applic...
-
[8]
Mingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and Jürgen Schmidhuber
Autotqa: Towards autonomous tabular ques- tion answering through multi-agent large language models.Proceedings of the VLDB Endowment, 17(12):3920–3933. Mingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and Jürgen Schmidhuber. 2024. Gptswarm: Language agents as optimizable graphs. InForty-first International Conference on Mach...
2024
-
[9]
SC (CoT×5).We apply self-consistency (Wang et al., 2022) by sampling five CoT reasoning paths and aggregating the final answer
and let a single LLM iteratively generate, critique, and refine its answer. SC (CoT×5).We apply self-consistency (Wang et al., 2022) by sampling five CoT reasoning paths and aggregating the final answer. DyLAN.We follow the collaborative discussion setting of DyLAN (Liu et al., 2024). MacNet.We use MacNet (Qian et al., 2024b) with a fixed fully connected ...
2022
-
[10]
13 C.3 Computational Resources All experiments are conducted on servers equipped with8 NVIDIA A800 GPUs, and mixed-precision training is used throughout
as an orchestration-centric baseline where a controller dynamically selects which agent to in- voke at each step. 13 C.3 Computational Resources All experiments are conducted on servers equipped with8 NVIDIA A800 GPUs, and mixed-precision training is used throughout. The underlying large language model is deployed throughvLLM(Kwon et al., 2023) during bot...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.