Peak-Then-Collapse and the Four Interface Channels of Knowledge-Graph Tool Use
Pith reviewed 2026-06-29 21:18 UTC · model grok-4.3
The pith
Reinforcement learning on a minimal knowledge-graph tool API produces a peak-then-collapse in tool-grounded answers because failures yield no natural-language signal.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
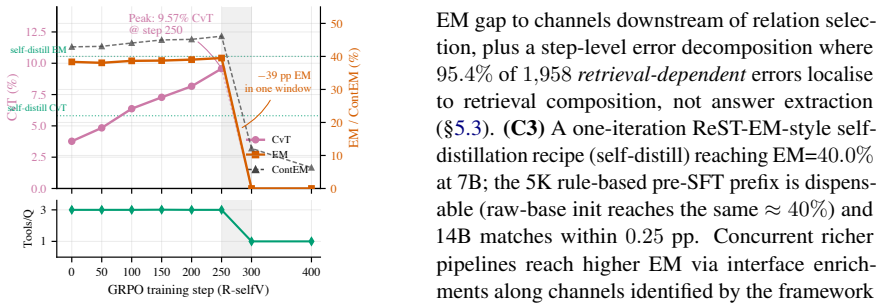
When GRPO is run on Qwen2.5-7B-Instruct against the four-verb Freebase API under a self-verifiable retrieval reward, tool-grounded answer rate climbs from 3.8 percent to 9.6 percent then falls to zero; the collapse is replicated across seeds and across reward variants that only relocate the failure mode. Gold-relation injection raises exact-match accuracy by 0.20 points, showing that 95.4 percent of retrieval-dependent errors are composition failures. One-iteration self-distillation yields 40.0 percent exact match at 7B and remains essentially unchanged at 14B, indicating the performance ceiling is set by the interface rather than model capacity.
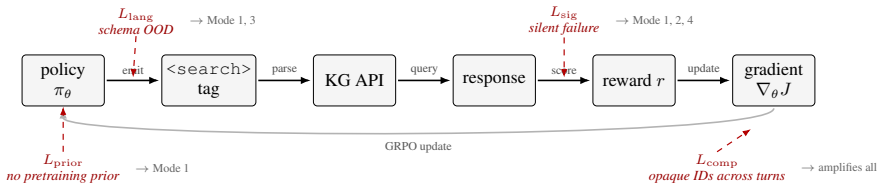
What carries the argument
The KG interface's lack of natural-language feedback on tool outcomes, which prevents the model from receiving the pretraining-aligned signals that Python, web, and JSON interfaces supply when they fail.
If this is right
- Denser or more targeted proxy rewards only relocate the failure mode rather than eliminating collapse.
- Supplying gold relations at every step improves exact-match accuracy by only 0.20 percentage points.
- 95.4 percent of retrieval-dependent errors are composition failures rather than answer-extraction failures.
- One-iteration self-distillation reaches 40.0 percent exact match and shows no meaningful improvement when capacity doubles to 14B.
Where Pith is reading between the lines
- The interface-bound ceiling suggests that future work should focus on redesigning the tool API itself rather than further reward engineering.
- Other structured-data tools that return opaque results may exhibit analogous degradation under RL training.
- Adding synthetic natural-language feedback to KG responses would provide a direct test of whether the missing signal is sufficient to stabilize training.
- The capacity-invariance of the self-distillation result implies that scaling model size alone will not overcome interface limitations within the 7B-14B range.
Load-bearing premise
The observed peak-then-collapse and recurring failure modes are caused primarily by the absence of natural-language feedback in the knowledge-graph interface.
What would settle it
Augmenting every KG tool response with an explicit natural-language description of the result (for example, 'the query returned an empty list') and checking whether the collapse still occurs under identical RL training.
Figures



read the original abstract
We test the standard RLVR tool-use recipe -- GRPO on Qwen2.5-7B-Instruct -- on a deliberately minimal knowledge-graph tool API: four Freebase navigation verbs over Complex WebQuestions. Under a self-verifiable retrieval reward, the policy's tool-grounded answer rate climbs from $3.8\%$ to $9.6\%$ over 250 steps, then collapses to $0\%$ within a single 50-step window -- a \emph{peak-then-collapse} pattern replicated across four seeds. Across seven reward designs, we find four recurring failure modes: adding denser or more targeted proxy rewards shifts the failure mode rather than eliminating it. We argue that a key difference from Python interpreters, web search, and JSON APIs is interface feedback: their failures often leak natural-language signal the model saw in pretraining. A Python traceback names the failing line; an empty Freebase result \texttt{[]} does not. Stripping away that surface exposes a degradation regime that same-family reward redesigns do not fix. A direct oracle ablation rules out relation selection: injecting gold relations at every retrieval call lifts exact-match accuracy by only $+0.20$~pp, and $95.4\%$ of retrieval-dependent errors are retrieval-composition failures rather than answer-extraction failures. As a mitigation, one-iteration self-distillation reaches $40.0\%$ EM at 7B and is capacity-invariant: doubling capacity to 14B improves EM by only $0.25$~pp, and initialization barely matters -- the ceiling appears interface-bound within the 7B--14B range tested.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines the application of GRPO-based RLVR to a minimal knowledge-graph tool API consisting of four Freebase navigation verbs on Complex WebQuestions using Qwen2.5-7B-Instruct. It reports a peak-then-collapse pattern in tool-grounded answer rate under self-verifiable retrieval reward (3.8% to 9.6% then to 0% within 50 steps), replicated across four seeds, identifies four recurring failure modes across seven reward designs, attributes the degradation to the absence of natural-language feedback leakage in the KG interface (unlike Python tracebacks or web results), shows via oracle ablation that injecting gold relations yields only +0.20 pp EM lift with 95.4% of errors being retrieval-composition failures, and demonstrates that one-iteration self-distillation reaches 40.0% EM at 7B with negligible gains from doubling to 14B.
Significance. If the peak-then-collapse pattern and its attribution to interface feedback hold after controlled testing, the work identifies a degradation regime in RL tool-use where reward redesign merely shifts failure modes rather than resolving them, and where self-distillation provides a capacity-invariant mitigation. The oracle ablation is a useful control ruling out relation selection as the primary bottleneck. The multi-seed replication and direct measurement of training dynamics are strengths. However, the causal generalization to 'four interface channels' rests on observational contrast rather than isolation of the feedback signal.
major comments (3)
- [Discussion section (interface feedback argument)] The central claim that the peak-then-collapse and four failure modes are driven primarily by the lack of natural-language feedback in the KG interface (as opposed to other RL training dynamics or dataset specifics) is load-bearing for the generalization beyond the tested setup. All runs use the identical four-verb Freebase interface and Complex WebQuestions; the seven reward variants and oracle ablation test reward density and relation selection but do not vary feedback phrasing or signal type while holding task, state space, and reward structure fixed. This leaves the mechanism unisolated (see the argument contrasting with Python/web/JSON interfaces).
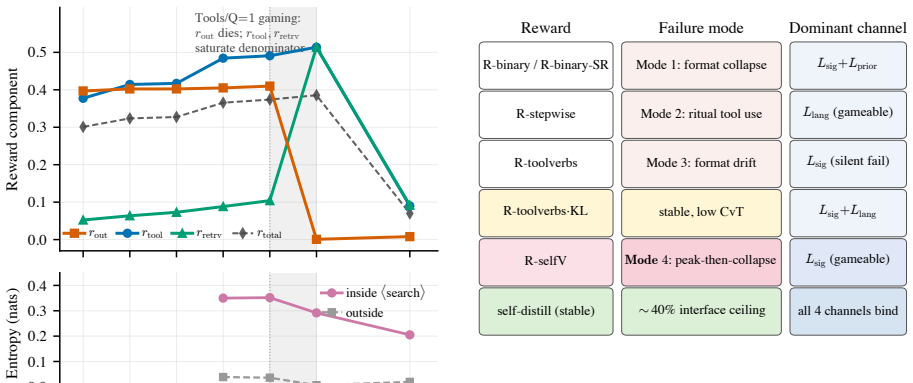
- [Results on reward variants] The taxonomy of four recurring failure modes across the seven reward designs is presented as evidence that denser proxy rewards shift rather than eliminate the degradation. Without explicit definitions, measurement criteria, or per-design counts for each mode (and confirmation that the taxonomy is exhaustive rather than post-hoc), it is difficult to evaluate whether the claim that 'same-family reward redesigns do not fix' the regime is fully supported.
- [Oracle ablation paragraph] The oracle ablation reports a +0.20 pp EM lift and states that 95.4% of retrieval-dependent errors are composition failures. To support the conclusion that relation selection is not the bottleneck, the section must specify the exact injection mechanism (e.g., whether gold relations alter the state representation seen by the policy or only the retrieval outcome) and confirm that the ablation preserves the original interface feedback properties.
minor comments (2)
- [Abstract] The abstract states replication across four seeds and collapse 'within a single 50-step window' but does not report per-seed variance, exact step counts at peak, or the precise definition of 'tool-grounded answer rate'; adding these details would strengthen verifiability.
- [Self-distillation results] The self-distillation result is described as 'capacity-invariant' with a 0.25 pp gain from 7B to 14B; confirming whether this holds under the same reward and interface conditions as the main RL runs would clarify the scope.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below with the strongest honest defense of the manuscript, proposing targeted revisions to improve clarity and rigor where the comments identify gaps.
read point-by-point responses
-
Referee: [Discussion section (interface feedback argument)] The central claim that the peak-then-collapse and four failure modes are driven primarily by the lack of natural-language feedback in the KG interface (as opposed to other RL training dynamics or dataset specifics) is load-bearing for the generalization beyond the tested setup. All runs use the identical four-verb Freebase interface and Complex WebQuestions; the seven reward variants and oracle ablation test reward density and relation selection but do not vary feedback phrasing or signal type while holding task, state space, and reward structure fixed. This leaves the mechanism unisolated (see the argument contrasting with Python/web/JSON interfaces).
Authors: We agree that a direct isolation experiment varying only feedback phrasing or signal type (while fixing task, state space, and reward) would strengthen the causal attribution. The manuscript's design deliberately employs a minimal four-verb interface to remove natural-language leakage by construction, and the peak-then-collapse plus failure-mode shifts are observed directly in this controlled minimal setting. The contrast to Python/web/JSON interfaces is drawn from the broader tool-use literature rather than new experiments. We will revise the Discussion to explicitly characterize the interface-feedback argument as resting on this observational contrast within a minimal setup, while acknowledging the lack of a feedback-signal ablation as a limitation and suggesting it as future work. This preserves the core empirical findings without overclaiming isolation. revision: partial
-
Referee: [Results on reward variants] The taxonomy of four recurring failure modes across the seven reward designs is presented as evidence that denser proxy rewards shift rather than eliminate the degradation. Without explicit definitions, measurement criteria, or per-design counts for each mode (and confirmation that the taxonomy is exhaustive rather than post-hoc), it is difficult to evaluate whether the claim that 'same-family reward redesigns do not fix' the regime is fully supported.
Authors: The taxonomy was obtained via manual trajectory inspection across all seven designs. To address the concern, we will add a dedicated appendix that provides (i) explicit definitions for each of the four modes, (ii) the annotation criteria (e.g., based on action sequences, reward trajectories, and collapse timing), (iii) per-design counts, and (iv) a statement that the taxonomy is exhaustive for the observed behaviors. This will make the claim that same-family reward redesigns shift rather than resolve the degradation more rigorously evaluable. revision: yes
-
Referee: [Oracle ablation paragraph] The oracle ablation reports a +0.20 pp EM lift and states that 95.4% of retrieval-dependent errors are composition failures. To support the conclusion that relation selection is not the bottleneck, the section must specify the exact injection mechanism (e.g., whether gold relations alter the state representation seen by the policy or only the retrieval outcome) and confirm that the ablation preserves the original interface feedback properties.
Authors: The abstract states that gold relations are injected 'at every retrieval call,' meaning the tool-response state passed to the policy is overwritten with gold relations while the interface feedback format (including empty-list outputs) remains unchanged. We will expand the oracle ablation paragraph to explicitly describe this state-representation injection mechanism and confirm that no additional natural-language signals are introduced, thereby preserving the original interface feedback properties. This clarification directly supports the conclusion that relation selection is not the primary bottleneck. revision: yes
Circularity Check
No circularity; all reported quantities are direct empirical measurements from training runs and ablations
full rationale
The paper reports measured quantities (tool-grounded answer rates climbing from 3.8% to 9.6% then collapsing, EM scores of 40.0%, oracle ablation +0.20 pp, capacity invariance between 7B and 14B) obtained from explicit RL training runs, reward variants, and self-distillation on fixed datasets. No equations, fitted parameters, or self-citations are used to derive these values; the central generalization about interface feedback is presented as an interpretation of the observed patterns rather than a reduction to prior self-referential definitions or inputs. No self-definitional, fitted-input-called-prediction, or load-bearing self-citation steps exist in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The reward signal based on final-answer exact match is self-verifiable and sufficient for policy optimization.
- ad hoc to paper The four-verb Freebase navigation interface is representative of tools whose failures provide no natural-language signal.
Reference graph
Works this paper leans on
-
[1]
HyperGraphPro: Progress-Aware Reinforcement Learning for Structure-Guided Hypergraph RAG
The effects of reward misspecification: Map- ping and mitigating misaligned models. InInter- national Conference on Learning Representations (ICLR). Jinyoung Park, Sanghyeok Lee, Omar Zia Khan, Hyun- woo J. Kim, and Joo-Kyung Kim. 2026. Hyper- GraphPro: Progress-aware reinforcement learning for structure-guided hypergraph RAG.Preprint, arXiv:2601.17755. C...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Transactions on Machine Learning Research (TMLR) , year =
Beyond human data: Scaling self-training for problem-solving with language models.Preprint, arXiv:2312.06585. Joar Skalse, Nikolaus H. R. Howe, Dmitrii Krashenin- nikov, and David Krueger. 2022. Defining and char- acterizing reward hacking. InAdvances in Neural Information Processing Systems (NeurIPS). Yanlin Song, Ben Liu, Víctor Gutiérrez-Basulto, Zhiwe...
-
[3]
Parse τ into <think>, <search>, <tool_response>,<answer>spans
-
[4]
Ifr EM(a, y) = 1: • if no<search>call:correct-no-tool; • else if ∃t∈ T with entity-in-answer:correct- via-tool; • else:correct-via-memory
-
[5]
Full implementation: scripts/task16_classify.py in the release bundle
Else (EM=0): • if no<search>call:wrong-no-tool; • if any <search> call parses invalid:tool- misuse; • if all responses empty or disjoint from gold sub-graph:kg-incomplete; • otherwise:wrong-answer. Full implementation: scripts/task16_classify.py in the release bundle. Edge cases (degenerate loops, over- long outputs, malformed <answer> envelopes) are logg...
-
[6]
Relation typo (≤1 edit)70.4%(n=576)
-
[7]
Correct entity, wrong relation 18.7% (n=153)
-
[8]
Wrong entity, near-miss relation 8.6% (n=70)
-
[9]
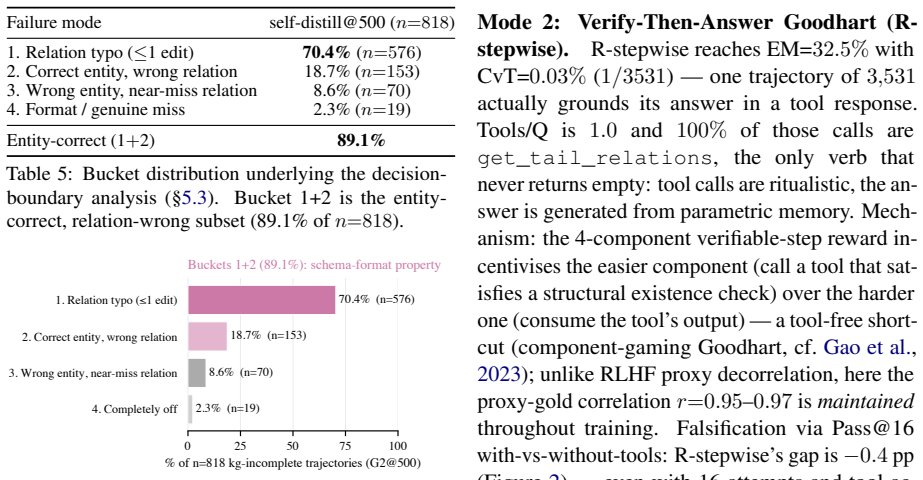
Bucket 1+2 is the entity- correct, relation-wrong subset (89.1% ofn=818)
Format / genuine miss 2.3% (n=19) Entity-correct (1+2)89.1% Table 5: Bucket distribution underlying the decision- boundary analysis (§5.3). Bucket 1+2 is the entity- correct, relation-wrong subset (89.1% ofn=818). 0 25 50 75 100 % of n=818 kg-incomplete trajectories (G2@500)
-
[10]
Relation typo (≤1 edit)
-
[11]
Correct entity, wrong relation
-
[12]
Wrong entity, near-miss relation
-
[13]
unable to retrieve X
Completely off 70.4% (n=576) 18.7% (n=153) 8.6% (n=70) 2.3% (n=19) Buckets 1+2 (89.1%): schema-format property Figure 5:Decision-boundary view of the schema- format property.Visual of Table 5: 70.4% of 818 kg-incomplete trajectories from self-distill@500 are exact-relation-typo( ≤1 edit from a gold relation); buck- ets 1+2 (89.1%) are entity-correct, rela...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.