LearnedCache: An eBPF-Integrated Perceptron-Based Eviction Policy for the Linux Page Cache
Pith reviewed 2026-06-29 20:00 UTC · model grok-4.3
The pith
A perceptron model embedded via eBPF outperforms FIFO eviction by up to 10 percent insertion rate in Linux page cache under tested workloads.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
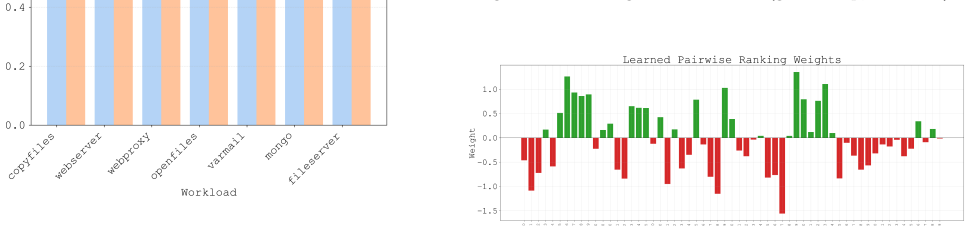
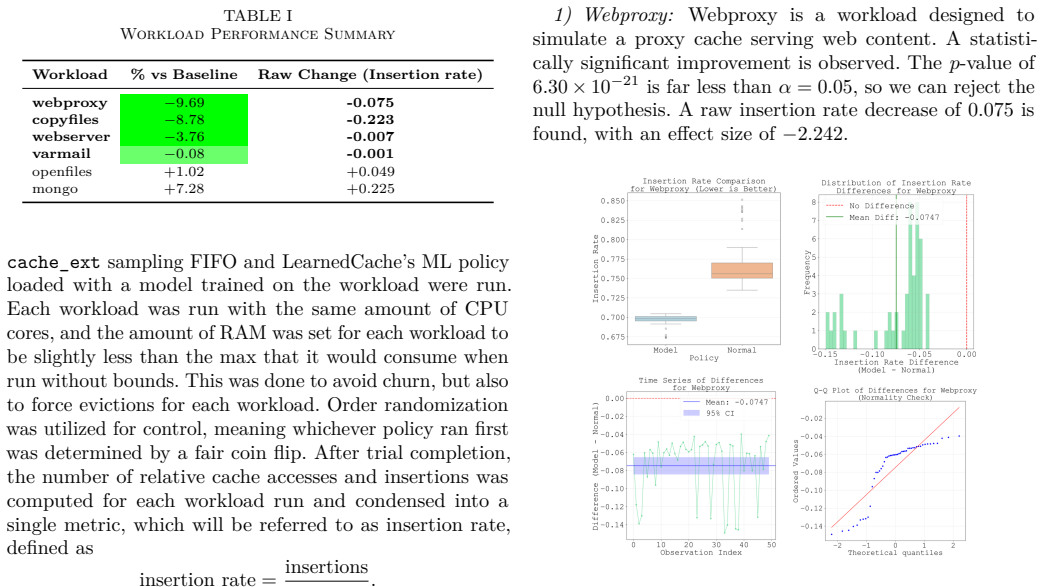
LearnedCache trains linear perceptron models offline on kernel-collected page traces from diverse workloads, embeds the compact models inside the kernel via eBPF, and uses them at eviction time to rank pages by predicted reuse distance; statistical tests against FIFO show the ML policy produces higher insertion rates (a frequency-adjusted hit-rate metric) by margins reaching 10 percent in specific workloads while adding negligible runtime cost.
What carries the argument
The single-layer perceptron that models page reuse time and is executed inside the kernel by an eBPF program attached to the page-cache eviction path.
If this is right
- Machine-learning eviction policies become feasible inside the production Linux kernel rather than only in user-space applications.
- Insertion-rate gains of several percent translate directly into fewer disk reads under the tested access patterns.
- Statistical significance testing over repeated paired trials provides evidence that the improvements are repeatable rather than noise.
- The same offline-training-plus-eBPF-embedding pattern can be applied to other kernel decisions that currently rely on fixed heuristics.
Where Pith is reading between the lines
- If the same embedding technique works for perceptrons, it could also support slightly larger models or online retraining inside the kernel.
- Workloads where the perceptron underperforms FIFO might benefit from ensemble or workload-specific model selection at load time.
- The approach opens a route for other operating systems to adopt kernel-resident ML policies without rewriting core data structures.
Load-bearing premise
Models trained offline on traces from several workloads can be loaded and executed in real time through eBPF without introducing kernel bugs or overhead that erase the measured performance gains.
What would settle it
A kernel run in which the eBPF program either panics, consumes more than a few percent extra CPU, or produces insertion rates statistically indistinguishable from or worse than FIFO across the same workload set.
Figures





read the original abstract
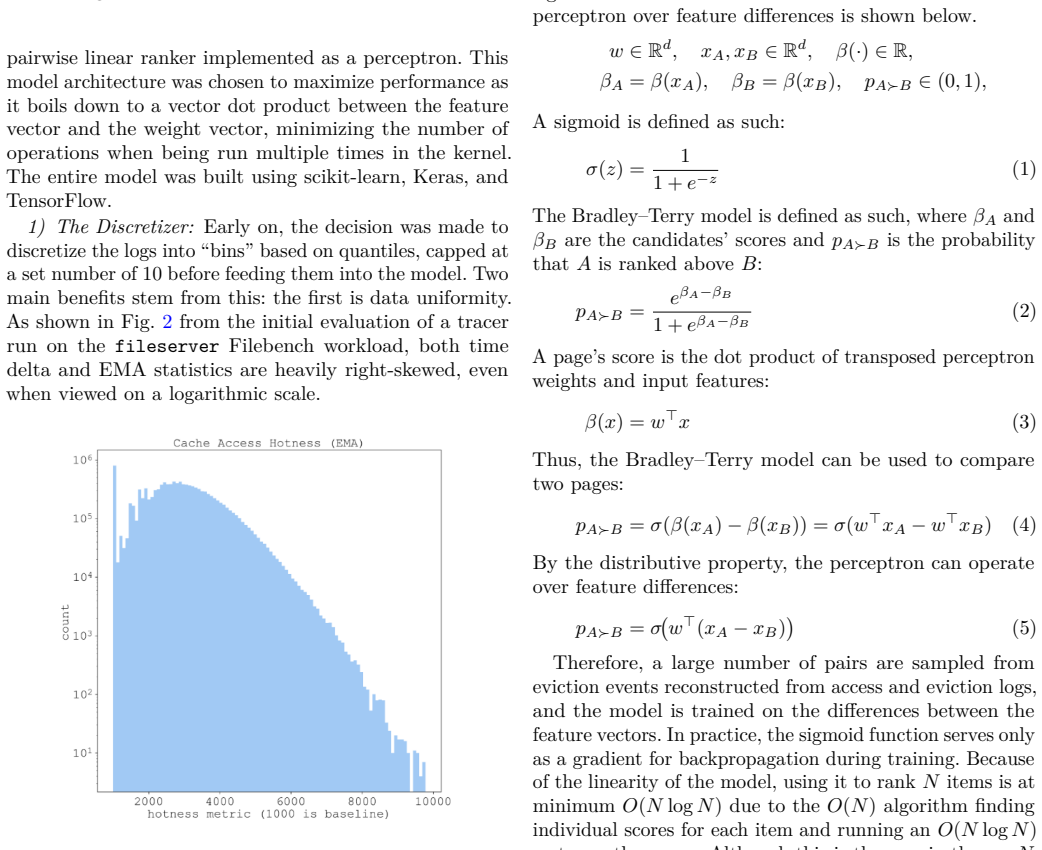
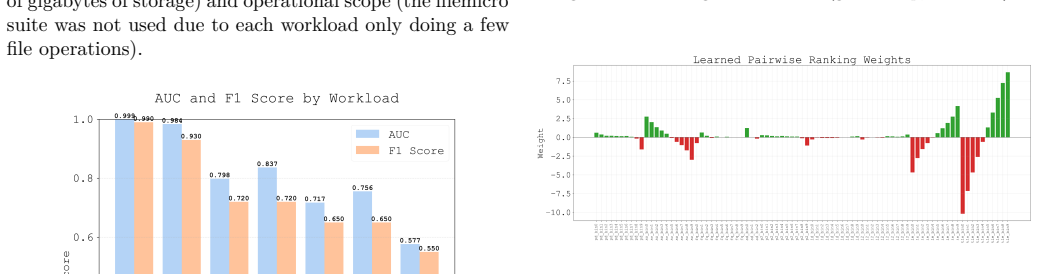
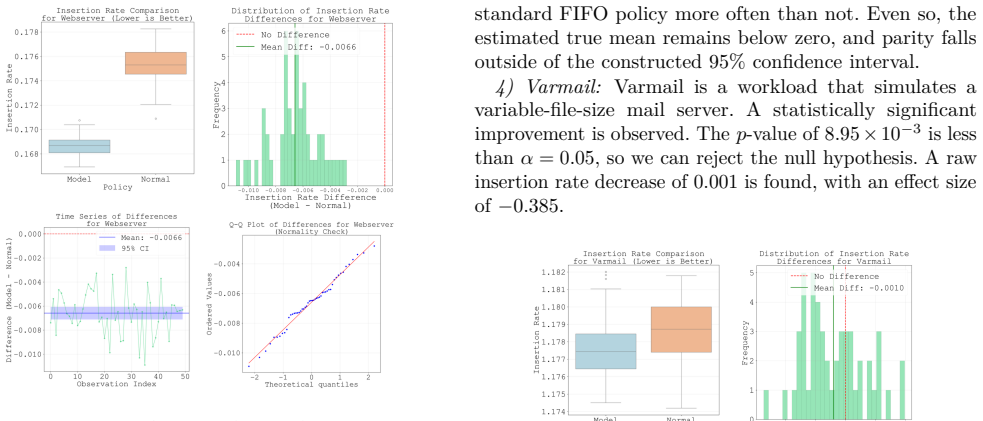
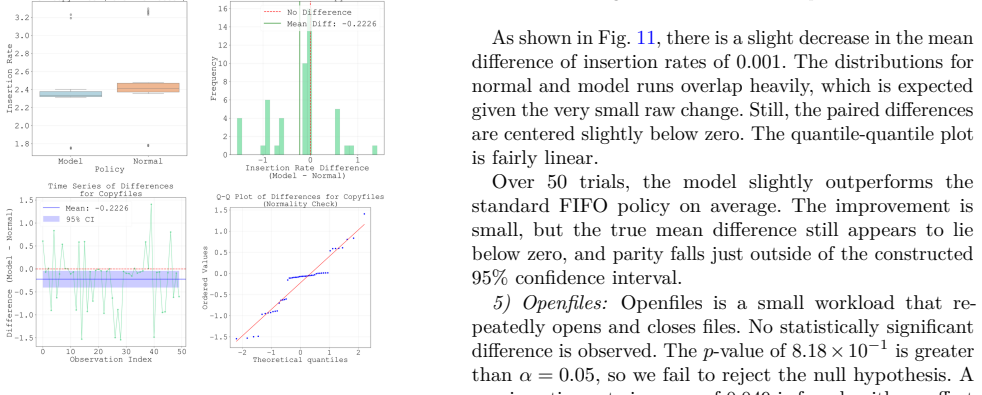
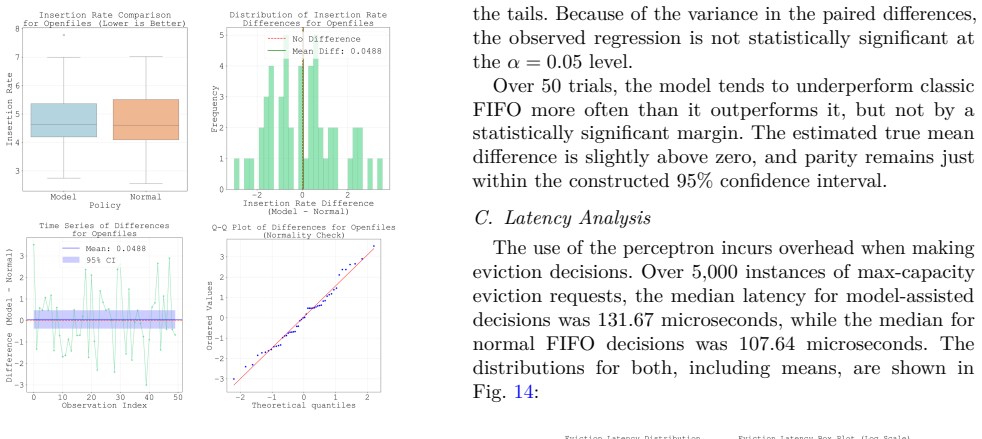
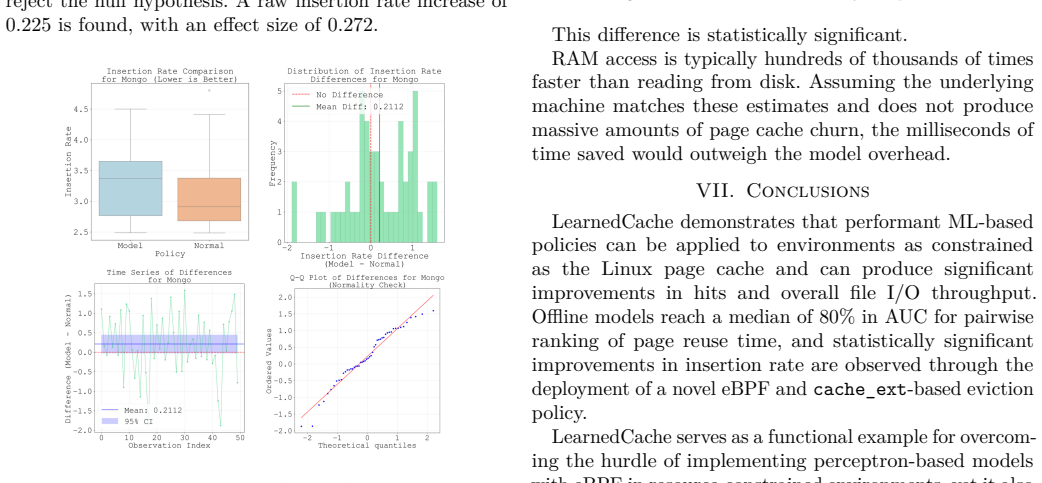
Linux is the foundation of the digital age, accounting for the majority of the cloud and mobile OS markets. Any device that runs Linux uses the Linux page cache, a central pillar in OS and application performance, serving to reduce extraneous disk access. Many page cache eviction policies have been developed but remain bound by the rigidity of heuristics. The rise of AI-driven tools in recent years, melded with the ever-increasing variety of workloads for Linux devices, sets the stage for machine-learning-driven cache eviction policies. Promising research has been done in this field, but only in the field of user-space applications such as CDNs. We develop LearnedCache, an eBPF-integrated single-layer perceptron-based cache eviction policy for the Linux page cache, trained on real kernel data from diverse workloads. We demonstrate median AUCs of nearly 80% over multiple linear models modeling page reuse time, then take a step further by embedding these models inside the Linux kernel for real-time performance evaluation. Through statistical testing over 50 paired trials against a baseline of FIFO for each workload, LearnedCache reveals that machine-learning-derived cache eviction policies are practical in the Linux kernel under representative empirical workloads and are able to surpass conventional FIFO by statistically significant margins of up to 10% in insertion rate, a frequency-adjusted derivation of cache hit rate, in specific workloads while incurring minimal overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents LearnedCache, an eBPF-integrated single-layer perceptron model for Linux page cache eviction. Models are trained offline on real kernel data from diverse workloads to predict page reuse time (median AUC near 80%). The work embeds these models in the kernel and evaluates them via 50 paired trials per workload against a FIFO baseline, reporting statistically significant gains of up to 10% in insertion rate (a frequency-adjusted cache hit rate metric) in specific workloads while claiming minimal overhead.
Significance. If the embedding, overhead, and statistical claims hold after verification, the result would demonstrate that simple ML models can be practically integrated into the Linux kernel's page cache path and outperform conventional heuristics under representative workloads. Strengths include the use of real kernel-collected training data, direct eBPF embedding for real-time evaluation, and the paired-trial statistical design. This could support broader exploration of learned policies in OS components.
major comments (2)
- [Abstract] Abstract: the central practicality claim requires that the perceptron executes in the real-time eviction path without overhead that erodes the reported insertion-rate gains, yet no per-decision latency figures, invocation details (per eviction candidate or page fault), eBPF map access costs, or verifier-limit discussion are supplied. This directly undermines the 'minimal overhead' assertion and the conclusion that the AUC results translate to net kernel benefit.
- [Abstract] Abstract: the reported median AUC near 80%, 10% insertion-rate gains, and statistical significance over 50 paired trials rest on unspecified training procedures, data-collection methods, page-exclusion rules, and exact statistical tests. Without these, the soundness of the empirical comparison to FIFO cannot be verified and the main claim remains uncheckable.
minor comments (1)
- [Abstract] Abstract: 'insertion rate' is described as a frequency-adjusted derivation of cache hit rate, but an explicit equation or definition would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for these focused comments on the abstract. Both points identify areas where additional detail would strengthen verifiability and the practicality claim. We will revise the manuscript to supply the requested information.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central practicality claim requires that the perceptron executes in the real-time eviction path without overhead that erodes the reported insertion-rate gains, yet no per-decision latency figures, invocation details (per eviction candidate or page fault), eBPF map access costs, or verifier-limit discussion are supplied. This directly undermines the 'minimal overhead' assertion and the conclusion that the AUC results translate to net kernel benefit.
Authors: We agree that the abstract does not contain per-decision latency numbers, invocation frequency, map-access costs, or verifier-limit discussion. The current manuscript reports aggregate overhead but lacks these granular figures. We will add measured per-decision latencies (in cycles and nanoseconds), clarify that the model is invoked once per eviction candidate, quantify eBPF map lookup costs, and discuss verifier constraints in a revised abstract and a new methods paragraph. This revision will directly support the minimal-overhead claim. revision: yes
-
Referee: [Abstract] Abstract: the reported median AUC near 80%, 10% insertion-rate gains, and statistical significance over 50 paired trials rest on unspecified training procedures, data-collection methods, page-exclusion rules, and exact statistical tests. Without these, the soundness of the empirical comparison to FIFO cannot be verified and the main claim remains uncheckable.
Authors: We accept that the abstract omits these methodological specifics, rendering the numerical claims difficult to verify from the abstract alone. We will expand the abstract with concise statements on training (offline supervised learning on kernel-collected reuse traces), data-collection procedure, page-exclusion criteria, and the statistical test (paired Wilcoxon signed-rank test across 50 trials). A corresponding methods subsection will provide full procedural detail so that the AUC, insertion-rate gains, and significance claims become reproducible. revision: yes
Circularity Check
No circularity; empirical evaluation is self-contained
full rationale
The paper trains single-layer perceptrons offline on kernel-collected reuse-time data from diverse workloads, embeds the models via eBPF, and reports median AUC ~80% plus insertion-rate gains versus FIFO measured over 50 paired trials per workload. No equations, self-citations, or derivations are present that reduce the reported performance margins to fitted parameters by construction or to prior author work. The central claim is therefore an external empirical result rather than a tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Linux cloud infrastructure (CSE-41369),
UC San Diego Division of Extended Studies, “Linux cloud infrastructure (CSE-41369),” UC San Diego Division of Extended Studies, accessed: 2026-02-20. [Online]. Available: https://extendedstudies.ucsd.edu/courses/ linux-cloud-infrastructure-cse-41369
2026
-
[2]
Android global market share statistics,
CommandLinux, “Android global market share statistics,” CommandLinux, accessed: 2026-02-20. [Online]. Available: https://commandlinux.com/android/ android-global-market-share-statistics/
2026
-
[3]
Operating system support for database management,
M. Stonebraker, “Operating system support for database management,”Communications of the ACM, vol. 24, no. 7, pp. 412–418, Jul. 1981. [Online]. Available: https://doi.org/10.1145/ 358699.358703
-
[4]
The multi-generational LRU,
J. Corbet, “The multi-generational LRU,” LWN.net, Apr. 2021, accessed: 2026-02-20. [Online]. Available: https://lwn.net/ Articles/851184/
2021
-
[5]
D. Lee, I. Choi, C. Lee, S. Lee, and J. Kim, “P2Cache: An application-directed page cache for improving performance of data-intensive applications,” inProceedings of the 15th ACM Workshop on Hot Topics in Storage and File Systems (HotStorage ’23). New York, NY, USA: Association for Computing Machinery, Jul. 2023, pp. 31–36. [Online]. Available: https://do...
-
[6]
T. Zussman, I. Zarkadas, J. Carin, A. Cheng, H. Franke, J. Pfefferle, and A. Cidon, “cache_ext: Customizing the page cache with eBPF,” inProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles (SOSP ’25), ser. SOSP ’25. New York, NY, USA: Association for Computing Machinery, Oct. 2025, pp. 462–478, published as cache_ext; arXiv prepri...
-
[7]
The eBPF runtime in the Linux kernel,
B. Gbadamosi, L. Leonardi, T. Pulls, T. Høiland-Jørgensen, S. Ferlin-Reiter, S. Sorce, and A. Brunström, “The eBPF runtime in the Linux kernel,” 2024, arXiv:2410.00026. [Online]. Available: https://arxiv.org/abs/2410.00026
-
[8]
LHD: Improving cache hit rate by maximizing hit density,
N. Beckmann, H. Chen, and A. Cidon, “LHD: Improving cache hit rate by maximizing hit density,” in15th USENIX Symposium on Networked Systems Design and Implementation (NSDI 18). Renton, WA: USENIX Association, Apr. 2018, pp. 389–403. [Online]. Available: https://www.usenix.org/conference/nsdi18/ presentation/beckmann
2018
-
[9]
ML-CLOCK: Efficient page cache algorithm based on perceptron-based neural network,
M. Cho and D. Kang, “ML-CLOCK: Efficient page cache algorithm based on perceptron-based neural network,” Electronics, vol. 10, no. 20, p. 2503, 2021. [Online]. Available: https://www.mdpi.com/2079-9292/10/20/2503
2021
-
[10]
A learned cache eviction framework with minimal overhead,
D. Yang, D. S. Berger, K. Li, and W. Lloyd, “A learned cache eviction framework with minimal overhead,” 2023, arXiv:2301.11886. [Online]. Available: https://arxiv.org/abs/ 2301.11886
-
[11]
HALP: Heuristic aided learned preference eviction policy for YouTube content delivery network,
Z. Song, K. Chen, N. Sarda, D. Altınbüken, E. Brevdo, J. Coleman, X. Ju, P. Jurczyk, R. Schooler, and R. Gummadi, “HALP: Heuristic aided learned preference eviction policy for YouTube content delivery network,” in20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23). Boston, MA: USENIX Association, Apr. 2023, pp. 1149–1163. [Onlin...
2023
-
[12]
eBPF: Introduction, tutorials, and community resources,
eBPF Community, “eBPF: Introduction, tutorials, and community resources,” eBPF.io, 2024, accessed: 2026-03-25. [Online]. Available: https://ebpf.io/
2024
-
[13]
Silberschatz, P
A. Silberschatz, P. B. Galvin, and G. Gagne,Operating System Concepts, 10th ed. Hoboken, NJ: Wiley, 2018
2018
-
[14]
The state of the page in 2025,
J. Corbet, “The state of the page in 2025,” LWN.net, Mar. 2025, accessed: 2026-03-25. [Online]. Available: https: //lwn.net/Articles/1015320/
-
[15]
BPF design Q&A,
The Linux Kernel Organization, “BPF design Q&A,” Linux kernel documentation, accessed: 2026-03-25. [Online]. Available: https://docs.kernel.org/bpf/bpf_design_QA.html
2026
-
[16]
eBPF verifier,
——, “eBPF verifier,” Linux kernel documentation, accessed: 2026-03-25. [Online]. Available: https://docs.kernel.org/bpf/ verifier.html
2026
-
[17]
Floating-point API,
——, “Floating-point API,” Linux kernel documentation, accessed: 2026-03-25. [Online]. Available: https://docs.kernel. org/core-api/floating-point.html
2026
-
[18]
Filebench: A flexible framework for file system benchmarking,
V. Tarasov, E. Zadok, and S. Shepler, “Filebench: A flexible framework for file system benchmarking,”;login: The USENIX Magazine, vol. 41, no. 1, pp. 6–12, 2016, spring 2016. [Online]. Available: https://www.usenix.org/publications/login/ spring2016/tarasov
2016
-
[19]
folio_mark_accessed() — linux kernel source,
The Linux Kernel Organization, “ folio_mark_accessed() — linux kernel source,” Linux kernel source code, 2023, linux kernel v6.6.8; Accessed: 2026-03-25. [Online]. Avail- able: https://git.kernel.org/pub/scm/linux/kernel/git/stable/ linux.git/tree/mm/swap.c?h=v6.6.8
2023
-
[20]
Rank analysis of incomplete block designs: I. the method of paired comparisons,
R. A. Bradley and M. E. Terry, “Rank analysis of incomplete block designs: I. the method of paired comparisons,”Biometrika, vol. 39, no. 3/4, pp. 324–345, 1952. [Online]. Available: https://doi.org/10.1093/biomet/39.3-4.324
-
[21]
Lecture 24: The Bradley-Terry model,
Z. Fan, “Lecture 24: The Bradley-Terry model,” STATS 200: Introduction to Statistical Inference, Stanford University, 2016, autumn 2016. [Online]. Available: https://web.stanford.edu/ class/archive/stats/stats200/stats200.1172/Lecture24.pdf
2016
-
[22]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” inInternational Conference on Learning Representations (ICLR), 2015, arXiv:1412.6980. [Online]. Available: https://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[23]
SciPy 1.0--Fundamental Algorithms for Scientific Computing in Python
P. Virtanen, R. Gommers, T. E. Oliphant, M. Haberland, T. Reddy, D. Cournapeau, E. Burovski, P. Peterson, W. Weckesser, J. Bright, S. J. van der Walt, M. Brett, J. Wilson, K. J. Millman, N. Mayorov, A. R. J. Nelson, E. Jones, R. Kern, E. Larson, C. J. Carey, İ. Polat, Y. Feng, E. W. Moore, J. VanderPlas, D. Laxalde, J. Perktold, R. Cimrman, I. Henriksen, ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s41592-019-0686-2 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.