Joint Instance Segmentation and Geometric Attribute Regression for Roof Structures in Aerial Imagery
Pith reviewed 2026-06-29 22:21 UTC · model grok-4.3
The pith
Joint prediction of roof segment masks with height, slope and azimuth from one aerial image enables reconstruction of simplified 3D building models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The predicted per-segment masks and attributes are sufficient to reconstruct simplified 3D building models (LoD2) from a single overhead image, requiring expensive 3D reference data only for training.
What carries the argument
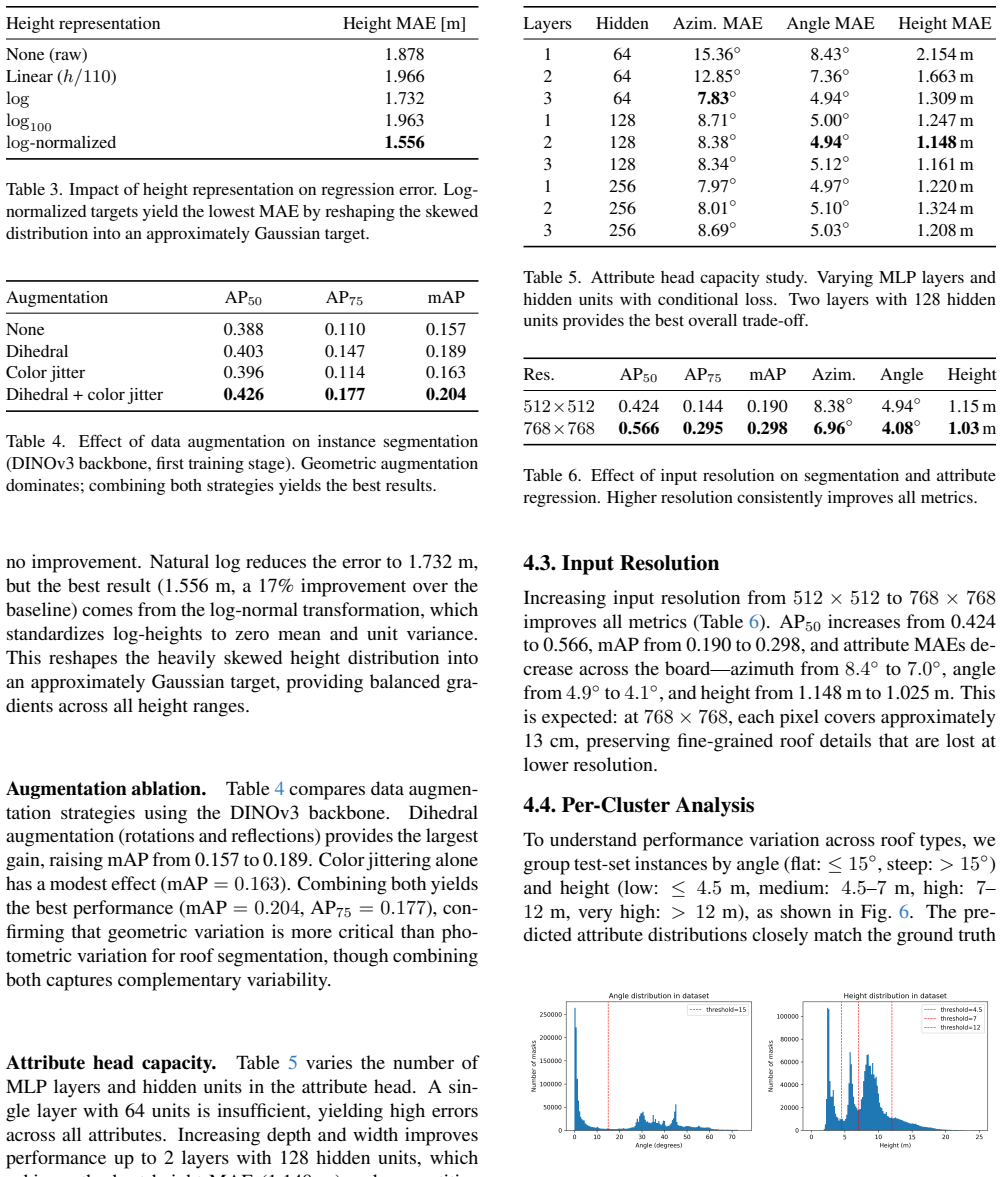
An attribute regression branch attached to Mask R-CNN together with a conditional azimuth loss that skips flat-roof segments and a log-normalized height representation.
If this is right
- Simplified 3D building models can be produced from a single aerial orthophoto at inference time.
- Only the training stage requires the expensive 3D reference data.
- Reported errors are approximately 4 degrees for roof slope, 7 degrees for azimuth and 1 meter for height.
- Instance segmentation reaches AP50 of 0.566 using a DINOv3 ConvNeXt-Base backbone.
Where Pith is reading between the lines
- The same joint mask-plus-attribute output could be applied to other man-made objects whose 3D form can be approximated from overhead imagery.
- Large-scale city modeling pipelines could shift from repeated 3D acquisition to periodic 2D imagery plus a trained regressor.
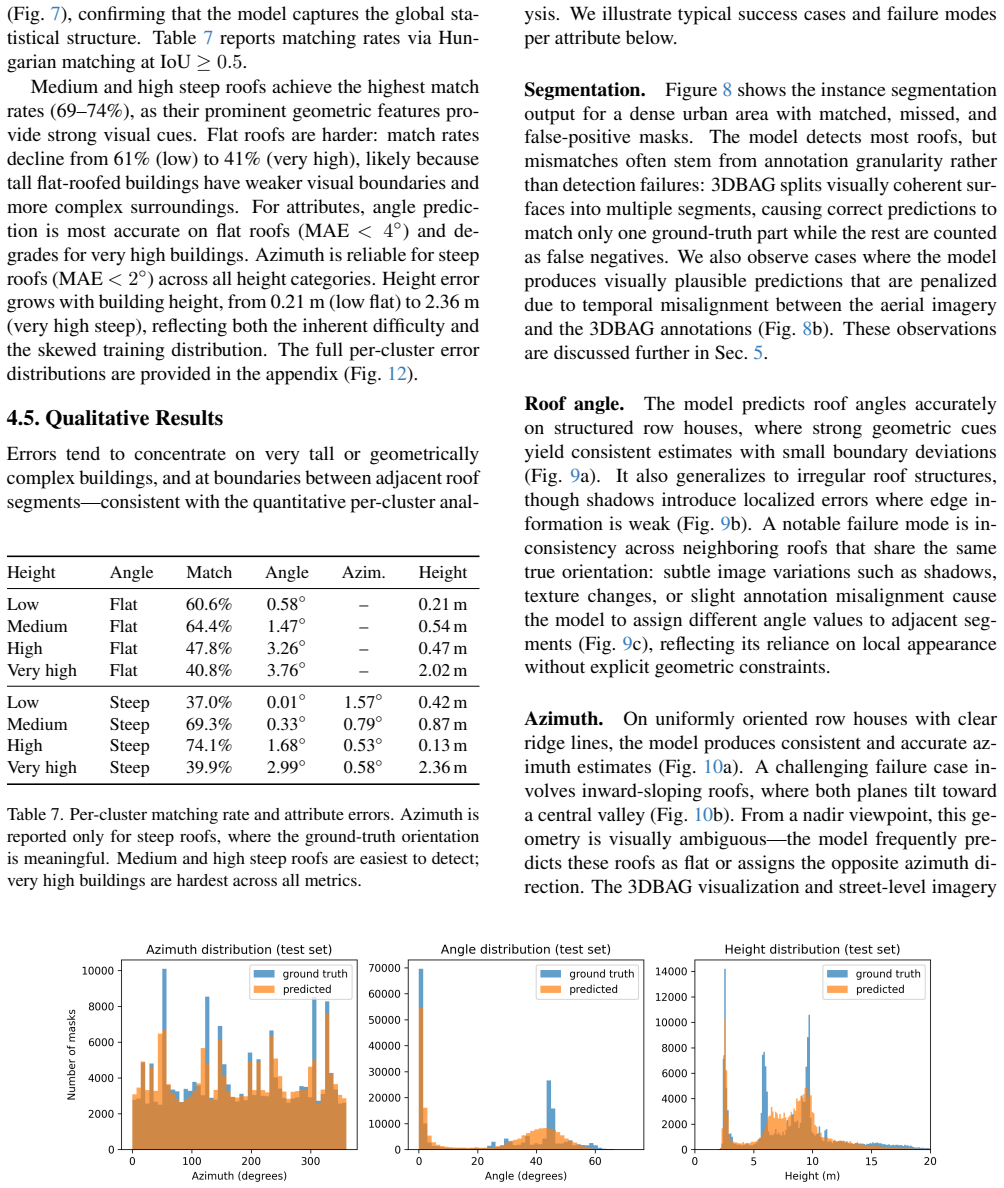
- Performance on imagery from different countries or sensors would test how much the learned mapping depends on Dutch building stock and acquisition conditions.
Load-bearing premise
The automatically derived ground truth labels from the 3DBAG nationwide LiDAR-based dataset are accurate and consistent enough to serve as reliable supervision for the continuous attribute regression tasks.
What would settle it
Reconstruct LoD2 models from the network outputs on a held-out set of buildings and compare the resulting geometry directly against independent high-accuracy LiDAR or manual survey measurements of the same structures.
Figures






read the original abstract
We present a method for jointly predicting instance-level roof segment masks together with three continuous geometric attributes -- building height, roof slope, and roof azimuth -- from a single aerial orthophoto. Our approach extends Mask R-CNN with a dedicated attribute regression branch and introduces two key innovations: a conditional azimuth loss that suppresses supervision for flat roof segments where azimuth labels are inherently noisy, and a log-normalized height representation that addresses the heavily skewed distribution of building heights. We train and evaluate on a large-scale dataset of Dutch aerial images paired with automatically derived ground truth from 3DBAG, a nationwide LiDAR-based 3D building dataset. Using a DINOv3 ConvNeXt-Base backbone, our method achieves a mean absolute error of approximately 4 degrees for roof slope, 7 degrees for azimuth, and 1 meter for building height, with an instance segmentation AP$_{50}$ of 0.566. The predicted per-segment masks and attributes are sufficient to reconstruct simplified 3D building models (LoD2) from a single overhead image, requiring expensive 3D reference data only for training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a multi-task extension of Mask R-CNN for joint roof instance segmentation and regression of three geometric attributes (building height, roof slope, roof azimuth) from single aerial orthophotos. It introduces a conditional azimuth loss to handle noisy flat-roof labels and a log-normalized height representation for skewed distributions. The model is trained on a large Dutch dataset with automatically derived ground truth from the 3DBAG LiDAR-based 3D building collection, reporting instance AP50 of 0.566 together with MAEs of approximately 1 m (height), 4° (slope), and 7° (azimuth) using a DINOv3 ConvNeXt-Base backbone. The authors state that the per-segment masks and attributes suffice to reconstruct simplified LoD2 3D building models from a single overhead image.
Significance. If the reconstruction sufficiency claim is substantiated, the work would enable scalable LoD2 building model generation from widely available 2D aerial imagery, with expensive 3D reference data required only during training. The use of a nationwide real-world dataset and the domain-specific loss modifications for attribute regression represent practical contributions to remote-sensing computer vision. The absence of direct end-to-end reconstruction metrics, however, limits the assessed significance of the central claim.
major comments (2)
- [Abstract] Abstract: The central claim that 'the predicted per-segment masks and attributes are sufficient to reconstruct simplified 3D building models (LoD2)' is unsupported by any quantitative end-to-end evaluation. No metric is reported that compares reconstructed LoD2 geometry (surface error, volume difference, or visual fidelity) derived from the model's outputs against 3DBAG reference models; only separate segmentation AP50 and per-attribute MAEs are provided, rendering the sufficiency statement an untested extrapolation.
- The manuscript provides no validation or error analysis of the automatically derived continuous attribute labels from the 3DBAG LiDAR dataset. Because these labels serve as the sole supervision for the regression tasks, the lack of reported label accuracy or consistency checks for height, slope, and azimuth directly affects the reliability of the reported MAEs.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'the predicted per-segment masks and attributes are sufficient to reconstruct simplified 3D building models (LoD2)' is unsupported by any quantitative end-to-end evaluation. No metric is reported that compares reconstructed LoD2 geometry (surface error, volume difference, or visual fidelity) derived from the model's outputs against 3DBAG reference models; only separate segmentation AP50 and per-attribute MAEs are provided, rendering the sufficiency statement an untested extrapolation.
Authors: We agree that a direct quantitative evaluation of the end-to-end LoD2 reconstruction would provide stronger evidence for the claim. The manuscript focuses on the prediction task, and the statement is intended to highlight the practical utility of the outputs for LoD2 modeling, as these are the defining parameters. However, to address this, we will revise the abstract to qualify the claim as 'enable the reconstruction of simplified LoD2 models' and include a short discussion on how the predicted attributes can be used for reconstruction, along with the expected impact of the reported errors. This will make the claim more precise without overstatement. revision: yes
-
Referee: [—] The manuscript provides no validation or error analysis of the automatically derived continuous attribute labels from the 3DBAG LiDAR dataset. Because these labels serve as the sole supervision for the regression tasks, the lack of reported label accuracy or consistency checks for height, slope, and azimuth directly affects the reliability of the reported MAEs.
Authors: This is a valid point. The ground truth attributes are automatically derived from 3DBAG, and while 3DBAG is a high-quality nationwide dataset, we did not include an analysis of the derivation accuracy or potential label noise beyond the conditional loss for azimuth. We will add a dedicated paragraph or subsection describing the label extraction process from 3DBAG and discuss known limitations, such as potential inaccuracies in slope and azimuth for certain roof types. This will help contextualize the reported MAEs. revision: yes
Circularity Check
No circularity detected; derivation is standard supervised learning on external data
full rationale
The paper describes a Mask R-CNN extension with an added regression branch, trained end-to-end on aerial images paired with independent LiDAR-derived ground truth from the external 3DBAG dataset. Reported results consist of direct test-set metrics (instance AP50 and per-attribute MAEs) with no equations or claims showing that any output reduces to a fitted input by construction. The two listed innovations (conditional azimuth loss and log-normalized height) are explicit modeling choices, not self-referential definitions. The LoD2 sufficiency statement is an unmeasured extrapolation but does not create a circular derivation chain. No self-citations, uniqueness theorems, or ansatzes from prior author work are invoked as load-bearing steps.
Axiom & Free-Parameter Ledger
free parameters (2)
- multi-task loss weighting
- log-normalization scale parameters
axioms (2)
- domain assumption Automatically derived 3DBAG labels provide sufficiently accurate supervision for height, slope, and azimuth.
- domain assumption A single orthophoto contains enough visual cues to regress continuous 3D roof attributes at the reported accuracy.
Reference graph
Works this paper leans on
-
[1]
Biternion nets: Continuous head pose regression from dis- crete training labels
Lucas Beyer, Alexander Hermans, and Bastian Leibe. Biternion nets: Continuous head pose regression from dis- crete training labels. InGerman Conference on Pattern Recognition (GCPR), 2015. 4
2015
-
[2]
Schwing, Alexan- der Kirillov, and Rohit Girdhar
Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexan- der Kirillov, and Rohit Girdhar. Masked-attention mask transformer for universal image segmentation. InCVPR,
-
[3]
Mahmoud El Hussieni, Bahadir K. G ¨unt¨urk, Hasan F. Ates ¸, and O ˘guz Hano ˘glu. Mask-to-height: A YOLOv11-based architecture for joint building instance segmentation and height classification from satellite imagery.arXiv preprint arXiv:2510.27224, 2025. 2
-
[4]
Energy performance of buildings directive, 2024.https : / / energy
European Commission. Energy performance of buildings directive, 2024.https : / / energy . ec . europa . eu / topics / energy - efficiency / energy - efficient-buildings_en. 1
2024
-
[5]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InCVPR,
-
[6]
Mask R-CNN
Kaiming He, Georgia Gkioxari, Piotr Doll ´ar, and Ross Gir- shick. Mask R-CNN. InICCV, 2017. 2, 3
2017
-
[7]
H. W. Kuhn. The Hungarian method for the assignment problem.Naval Research Logistics Quarterly, 2(1-2):83–97,
-
[8]
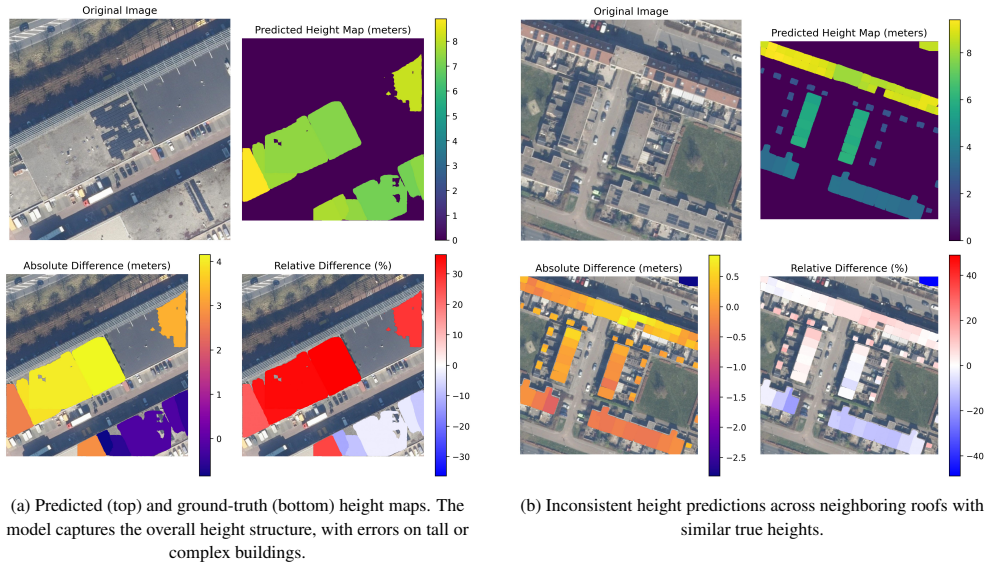
The model captures the overall height structure, with errors on tall or complex buildings
Qingyu Li, Lichao Mou, Yuansheng Hua, Yilei Shi, Sining 10 (a) Predicted (top) and ground-truth (bottom) height maps. The model captures the overall height structure, with errors on tall or complex buildings. (b) Inconsistent height predictions across neighboring roofs with similar true heights. Figure 11. Height prediction examples. (a) The model correct...
2023
-
[9]
Lawrence Zitnick
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C. Lawrence Zitnick. Microsoft COCO: Common objects in context.Eu- ropean Conference on Computer Vision (ECCV), pages 740– 755, 2014. 5
2014
-
[10]
Feature pyramid networks for object detection
Tsung-Yi Lin, Piotr Doll ´ar, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. InCVPR, 2017. 3
2017
-
[11]
Alexandros Mouzakitis et al. SolarNet: A convolutional neu- ral network-based framework for rooftop solar potential esti- mation from aerial imagery.International Journal of Applied Earth Observation and Geoinformation, 2022. 2
2022
-
[12]
Leveraging large-scale aerial data for accurate urban rooftop solar potential estimation via multitask learning.Solar Energy, 2025
Alexandros Mouzakitis et al. Leveraging large-scale aerial data for accurate urban rooftop solar potential estimation via multitask learning.Solar Energy, 2025. 2
2025
-
[13]
Olson and Shoshanna Saxe
Alexander W. Olson and Shoshanna Saxe. Single-image building height estimation using EfficientNet: A simplified, scalable approach.Findings, 2024. 2
2024
-
[14]
DINOv3: Convnext-base with knowl- edge distillation from self-supervised transformers.arXiv preprint, 2024
Maxime Oquab et al. DINOv3: Convnext-base with knowl- edge distillation from self-supervised transformers.arXiv preprint, 2024. 4, 5
2024
-
[15]
3d bag: Automated reconstruction of 3d city models from open data.ISPRS Journal of Photogram- metry and Remote Sensing, 2022
Ravi Peters, Bal ´azs Dukai, Stelios Vitalis, Jordi van Liempt, and Jantien Stoter. 3d bag: Automated reconstruction of 3d city models from open data.ISPRS Journal of Photogram- metry and Remote Sensing, 2022. 1, 2, 3
2022
-
[16]
PDOK lucht- foto RGB open, 2024.https : / / www
Samenwerkingsverband Beeldmateriaal. PDOK lucht- foto RGB open, 2024.https : / / www . pdok . nl / introductie/ - /article / pdok - luchtfoto - rgb-open-. 3
2024
- [17]
- [18]
-
[19]
VGGT: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. VGGT: Visual geometry grounded transformer. InCVPR, pages 5294–5306, 2025. 2
2025
-
[20]
Mask2Former with improved query for se- mantic segmentation in remote-sensing images.Mathemat- ics, 12(5), 2024
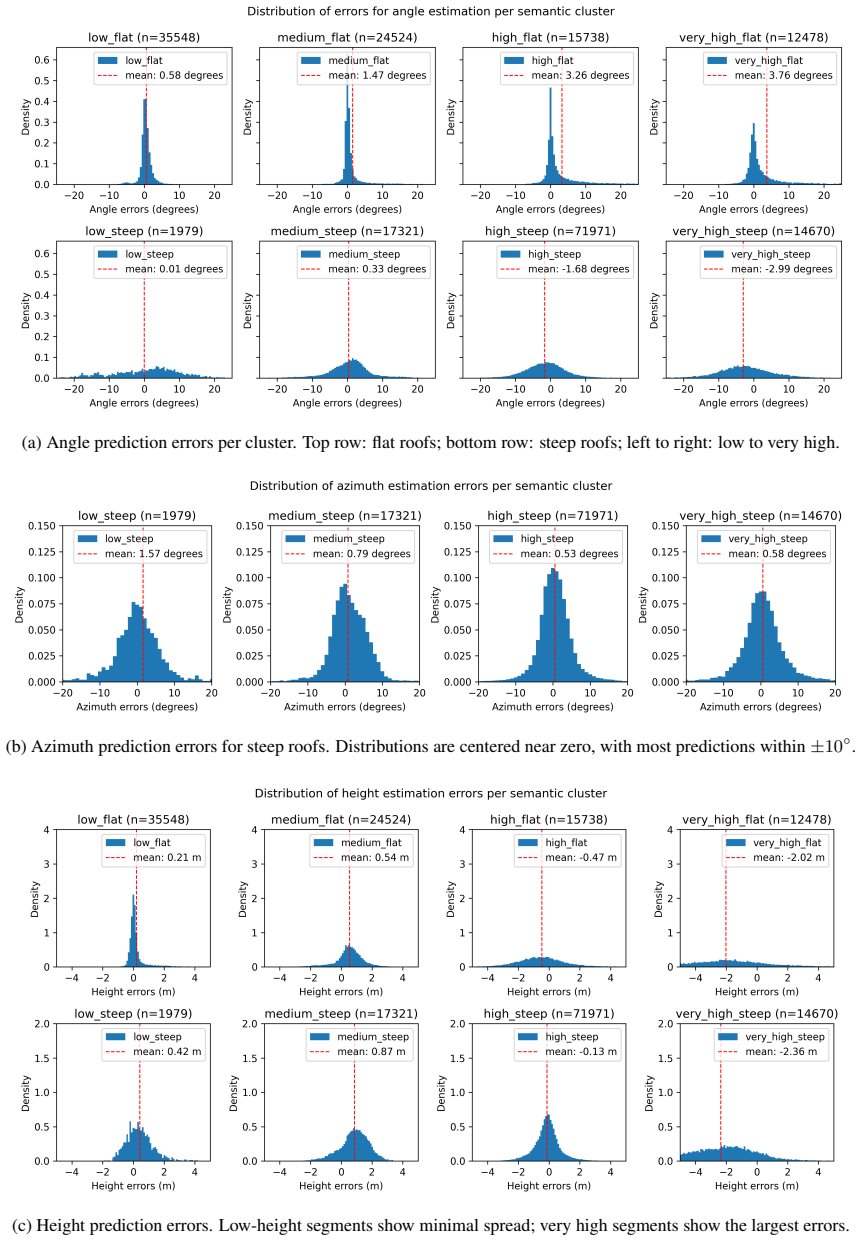
Hao Zhang et al. Mask2Former with improved query for se- mantic segmentation in remote-sensing images.Mathemat- ics, 12(5), 2024. 2 11 (a) Angle prediction errors per cluster. Top row: flat roofs; bottom row: steep roofs; left to right: low to very high. (b) Azimuth prediction errors for steep roofs. Distributions are centered near zero, with most predict...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.