Scheduled Style Injection: Expanding the Style-Content Pareto Frontier in Training-Free Diffusion-based Style Transfer
Pith reviewed 2026-06-29 18:44 UTC · model grok-4.3
The pith
Scheduling style injection strength across layers and timesteps expands the achievable tradeoffs between style fidelity and content preservation in training-free diffusion models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
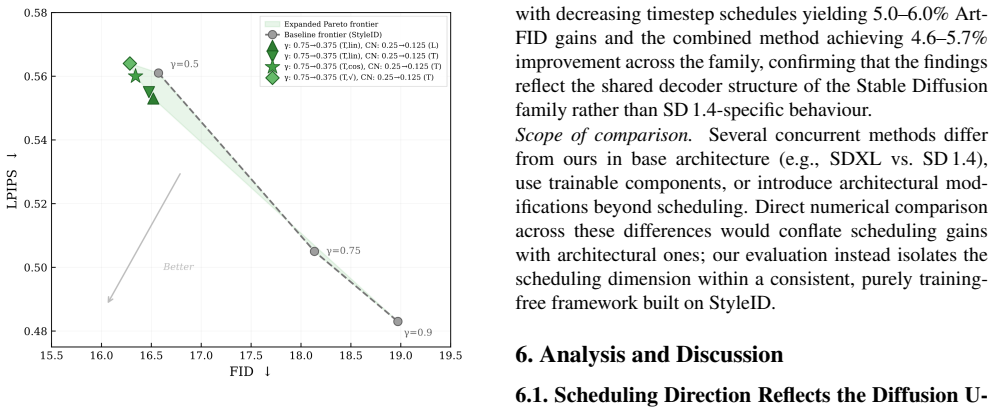
The central claim is that style injection in pre-trained diffusion models need not use one fixed strength value everywhere. Instead, independent schedules can be applied to injection strength along the layer axis and the timestep axis. Decreasing schedules outperform the reverse direction, cosine and square-root shapes outperform linear ones, and the gamma schedule remains nearly independent of ControlNet conditioning. The resulting configurations produce superior style-content tradeoffs, with the best balanced point reaching an ArtFID of 27.036 compared with the baseline value of 28.801, and the gains hold across the frontier. The improvements appear consistently across 35 tested configurat
What carries the argument
Scheduled style injection, which replaces a single global gamma with time- and layer-dependent values for style feature injection while also scheduling ControlNet geometric conditioning.
If this is right
- Users can select operating points with simultaneously higher style fidelity and higher content preservation than any fixed-gamma setting allowed.
- Only a few lines of code are needed to change the injection schedule, with no model retraining required.
- The same rank ordering of schedules holds across different Stable Diffusion backbones.
- Cosine and square-root schedule shapes give better results than linear ones along the timestep axis.
Where Pith is reading between the lines
- The same scheduling idea could be tested on other forms of conditioning or guidance in diffusion models beyond style transfer.
- Automated search over schedule shapes might further improve the frontier without manual trial of 35 configurations.
- The observed independence between gamma and ControlNet schedules suggests that additional independent control dimensions could be added without interference.
Load-bearing premise
That the advantage of decreasing schedules and the near-independence of the two scheduling dimensions are properties of the diffusion process itself rather than limited to the tested configurations and metrics.
What would settle it
Generating the same set of style-content pairs with both decreasing and increasing schedules on a previously untested diffusion backbone and finding that the ArtFID and other metric rankings no longer favor decreasing schedules.
Figures

read the original abstract
Style transfer with pre-trained diffusion models has advanced rapidly, but a core question remains underexplored: where in the model should style injection be strongest? StyleID, the leading training-free method, uses a single global parameter (gamma) uniformly across all layers and timesteps, which forces a fixed tradeoff between style quality and content preservation. We show this tradeoff is unnecessarily rigid. We systematically explore four dimensions of control: varying style injection strength across decoder layers, across denoising timesteps, and scheduling ControlNet geometric conditioning along both axes. The pattern is consistent everywhere: decreasing schedules, with stronger structural signal injection in shallower layers and earlier timesteps, reliably outperform the reverse. Beyond direction, schedule shape matters: cosine and square-root timestep schedules outperform linear. Most importantly, we find that gamma scheduling and ControlNet conditioning are nearly independent. The resulting combined configurations expand the Pareto frontier, offering superior tradeoffs between style fidelity and content preservation compared to any single baseline setting. Our best balanced configuration achieves ArtFID of 27.036 versus StyleID's 28.801 - a 6.1% relative improvement, with consistent gains across the full style-content tradeoff frontier. Results are validated across 35 configurations totaling over 28,000 stylized images using four complementary metrics. These findings generalize across SD backbones with identical rank ordering. All modifications are training-free, parameter-free, and require only a few lines of scheduling code; code is available at https://github.com/ameyskulkarni/scheduled_style_injection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Scheduled Style Injection for training-free diffusion-based style transfer. It systematically varies style injection strength (gamma) and ControlNet geometric conditioning across decoder layers and denoising timesteps in four scheduling dimensions. The central empirical claim is that decreasing schedules (stronger injection in shallower layers and earlier timesteps) outperform alternatives, cosine and square-root timestep schedules outperform linear, gamma scheduling and ControlNet conditioning are nearly independent, and the resulting combined configurations expand the style-content Pareto frontier. This is supported by evaluation across 35 configurations, >28,000 images, four metrics, and multiple SD backbones, with the best balanced configuration reporting ArtFID of 27.036 versus StyleID's 28.801 (6.1% relative improvement) and consistent gains across the tradeoff frontier. All changes are training-free and the code is released.
Significance. If the reported patterns hold beyond the tested configurations, the work provides a lightweight, parameter-free improvement to leading training-free methods such as StyleID by expanding the achievable style-content tradeoff without retraining. The scale of the evaluation (>28k images, cross-backbone validation, four complementary metrics) and public code release are notable strengths that support practical adoption. The finding that schedule direction and shape matter consistently, and that the two control axes are nearly independent, could inform future injection strategies in diffusion models.
major comments (2)
- [Abstract] Abstract and results: The claim that gamma scheduling and ControlNet conditioning are 'nearly independent' and that combined configurations expand the Pareto frontier rests on 35 sampled points across four dimensions. No full factorial design, interaction-term analysis, or sampling justification is described; this leaves open whether the near-independence and consistent outperformance are robust properties or artifacts of the sparse sampling strategy.
- [Abstract] Abstract: The 6.1% ArtFID improvement (27.036 vs. 28.801) is reported for the single 'best balanced configuration.' To establish a genuine frontier shift rather than post-hoc selection among the 35 points, the manuscript should report whether every combined schedule outperforms the StyleID baseline or provide the complete set of frontier points with variance across the four metrics.
minor comments (2)
- The four scheduling dimensions and their parameterization (layer-wise vs. timestep-wise gamma and ControlNet) would benefit from an explicit summary table or diagram early in the methods to improve readability.
- Clarify whether the reported rank ordering across SD backbones was obtained with identical random seeds and prompt sets or whether additional controls were applied.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications and proposed revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract and results: The claim that gamma scheduling and ControlNet conditioning are 'nearly independent' and that combined configurations expand the Pareto frontier rests on 35 sampled points across four dimensions. No full factorial design, interaction-term analysis, or sampling justification is described; this leaves open whether the near-independence and consistent outperformance are robust properties or artifacts of the sparse sampling strategy.
Authors: We acknowledge that the evaluation relies on 35 sampled configurations rather than a complete factorial design. The sampling strategy was selected to systematically vary schedule direction, shape, and axis combinations while remaining computationally feasible given the scale (>28k images). The near-independence and outperformance patterns hold consistently across all sampled points and backbones. We will add explicit justification for the sampling approach and an interaction analysis using the existing data in a revised results section. revision: partial
-
Referee: [Abstract] Abstract: The 6.1% ArtFID improvement (27.036 vs. 28.801) is reported for the single 'best balanced configuration.' To establish a genuine frontier shift rather than post-hoc selection among the 35 points, the manuscript should report whether every combined schedule outperforms the StyleID baseline or provide the complete set of frontier points with variance across the four metrics.
Authors: The abstract highlights the best configuration while noting consistent frontier gains. To address the concern directly, we will revise the abstract and main results to include summary statistics across all 35 configurations (e.g., fraction outperforming baseline, mean/variance per metric) and reference the full per-configuration table already present in the supplement. This will demonstrate the frontier expansion without relying on a single selected point. revision: yes
Circularity Check
No circularity: empirical comparison of scheduling variants
full rationale
The paper conducts an empirical sweep over 35 configurations across four scheduling dimensions (layer-wise and timestep-wise gamma and ControlNet), evaluating on four metrics against the StyleID baseline. Claims such as the superiority of decreasing schedules, near-independence of gamma and ControlNet, and the 6.1% ArtFID improvement are direct experimental outcomes with no equations, fitted parameters renamed as predictions, or self-citation chains that reduce the reported results to inputs by construction. The work is self-contained against external benchmarks (StyleID and multiple metrics) with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-trained diffusion models support style injection at controllable layers and timesteps via attention or feature modulation.
Reference graph
Works this paper leans on
-
[1]
ArtFlow: Unbiased image style transfer via re- versible neural flows
Jie An, Siyu Huang, Yibing Song, Dejing Dou, Wei Liu, and Jiebo Luo. ArtFlow: Unbiased image style transfer via re- versible neural flows. InProc. IEEE/CVF Conf. Comput. Vis. Pattern Recog. (CVPR), pages 862–871, 2021. 2, 6
2021
-
[2]
Cross-domain object detection using un- supervised image translation.Expert Systems with Applica- tions, 186:115786, 2022
Vinicius F Arruda, Tiago M Paix ˜ao, Rodrigo F Berriel, Al- berto F de Souza, Claudine Badue, Nicu Sebe, and Thiago Oliveira-Santos. Cross-domain object detection using un- supervised image translation.Expert Systems with Applica- tions, 186:115786, 2022. 3
2022
-
[3]
Real-time monocular depth estimation using synthetic data with do- main adaptation via image style transfer
Amir Atapour-Abarghouei and Toby P Breckon. Real-time monocular depth estimation using synthetic data with do- main adaptation via image style transfer. InProc. IEEE/CVF Conf. Comput. Vis. Pattern Recog. (CVPR), pages 2800– 2810, 2018. 3
2018
-
[4]
Style transfer with diffusion models for synthetic-to-real domain adaptation.Computer Vision and Image Understanding, 252:104445, 2025
Estelle Chigot et al. Style transfer with diffusion models for synthetic-to-real domain adaptation.Computer Vision and Image Understanding, 252:104445, 2025. 3
2025
-
[5]
Style injec- tion in diffusion: A training-free approach for adapting large- scale diffusion models for style transfer
Jiwoo Chung, Sangeek Hyun, and Jae-Pil Heo. Style injec- tion in diffusion: A training-free approach for adapting large- scale diffusion models for style transfer. InProc. IEEE/CVF Conf. Comput. Vis. Pattern Recog. (CVPR), pages 8795– 8805, 2024. 1, 2, 3, 4, 6, 8
2024
-
[6]
Arbitrary style transfer via multi-adaptation network
Yingying Deng, Fan Tang, Weiming Dong, Wen Sun, Feiyue Huang, and Changsheng Xu. Arbitrary style transfer via multi-adaptation network. InProc. ACM Int. Conf. Multi- media (ACM MM), pages 2719–2727, 2020. 6
2020
-
[7]
StyTR2: Image style transfer with transformers
Yingying Deng, Fan Tang, Weiming Dong, Chongyang Ma, Xingjia Pan, Lei Wang, and Changsheng Xu. StyTR2: Image style transfer with transformers. InProc. IEEE/CVF Conf. Comput. Vis. Pattern Recog. (CVPR), pages 11326–11336,
-
[8]
Gatys, Alexander S
Leon A. Gatys, Alexander S. Ecker, and Matthias Bethge. Image style transfer using convolutional neural networks. In Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recog. (CVPR), pages 2414–2423, 2016. 1, 2
2016
-
[9]
Gatys, Alexander S
Leon A. Gatys, Alexander S. Ecker, and Matthias Bethge. Texture and art with deep neural networks.Current Opinion in Neurobiology, 46:178–186, 2017. 2
2017
-
[10]
Wichmann, and Wieland Brendel
Robert Geirhos, Patricia Rubisch, Claudio Michaelis, Matthias Bethge, Felix A. Wichmann, and Wieland Brendel. Imagenet-trained CNNs are biased towards texture; increas- ing shape bias improves accuracy and robustness. InProc. Int. Conf. Learn. Represent. (ICLR), 2019. 2, 5
2019
-
[11]
Haofan He et al. InstantStyle-Plus: Style transfer with content-preserving in text-to-image generation.arXiv preprint arXiv:2407.00788, 2024. 1, 2, 3
-
[12]
Prompt-to-prompt im- age editing with cross-attention control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt im- age editing with cross-attention control. InProc. Int. Conf. Learn. Represent. (ICLR), 2023. 1, 2, 5
2023
-
[13]
An edit friendly DDPM noise space: Inversion and manipulations
Amir Hertz, Kfir Aberman, and Daniel Cohen-Or. An edit friendly DDPM noise space: Inversion and manipulations. In Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recog. (CVPR), pages 12469–12479, 2024. 1, 4, 8
2024
-
[14]
Style aligned image generation via shared atten- tion
Amir Hertz, Andrey V oynov, Shlomi Fruchter, and Daniel Cohen-Or. Style aligned image generation via shared atten- tion. InProc. IEEE/CVF Conf. Comput. Vis. Pattern Recog. (CVPR), 2024. 3
2024
-
[15]
GANs trained by a two time-scale update rule converge to a local nash equilib- rium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. GANs trained by a two time-scale update rule converge to a local nash equilib- rium. InProc. Adv. Neural Inform. Process. Syst. (NeurIPS), pages 6626–6637, 2017. 3, 4
2017
-
[16]
Denoising dif- fusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models. InProc. Adv. Neural Inform. Process. Syst. (NeurIPS), pages 6840–6851, 2020. 1
2020
-
[17]
AesPA-Net: Aesthetic pattern-aware style transfer networks
Kibeom Hong, Seogkyu Jeon, Junsoo Lee, Namhyuk Ahn, Kunhee Kim, Pilhyeon Lee, Daesik Kim, Youngjung Uh, and Hyeran Byun. AesPA-Net: Aesthetic pattern-aware style transfer networks. InProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), pages 22758–22767, 2023. 6
2023
-
[18]
DiffuseST: Unleash- ing the capability of the diffusion model for style transfer
Ying Hu, Chenyi Zhuang, and Pan Gao. DiffuseST: Unleash- ing the capability of the diffusion model for style transfer. In Proc. ACM Int. Conf. Multimedia Asia (MMAsia), 2024. 2
2024
-
[19]
Bo Huang, Wenlun Xu, Qizhuo Han, Haodong Jing, and Ying Li. AttenST: A training-free attention-driven style transfer framework with pre-trained diffusion models.arXiv preprint arXiv:2503.07307, 2025. 1, 2, 6
-
[20]
Arbitrary style transfer in real-time with adaptive instance normalization
Xun Huang and Serge Belongie. Arbitrary style transfer in real-time with adaptive instance normalization. InProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), pages 1501– 1510, 2017. 1, 2, 3, 6
2017
-
[21]
Structure preserving cycle- GAN for unsupervised medical image domain adaptation
Paolo Iacono and Naimul Khan. Structure preserving cycle- GAN for unsupervised medical image domain adaptation. arXiv preprint arXiv:2304.09164, 2023. 3
-
[22]
Diffusion-based image translation using disentangled style and content representa- tion
Gihyun Kwon and Jong Chul Ye. Diffusion-based image translation using disentangled style and content representa- tion. InProc. AAAI Conf. Artif. Intell. (AAAI), pages 1214– 1222, 2023. 2, 6
2023
-
[23]
De- mystifying neural style transfer
Yanghao Li, Naiyan Wang, Jiaying Liu, and Xiaodi Hou. De- mystifying neural style transfer. InProc. Int. Joint Conf. Ar- tif. Intell. (IJCAI), pages 2230–2236, 2017. 1, 2
2017
-
[24]
Lawrence Zitnick
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C. Lawrence Zitnick. Microsoft COCO: Common objects in context. In Proc. Eur. Conf. Comput. Vis. (ECCV), pages 740–755, 2014. 4
2014
-
[25]
AdaAttN: Revisit attention mechanism in arbitrary neural style transfer
Songhua Liu, Tianwei Lin, Dongliang He, Fu Li, Meiling Wang, Xin Li, Zhengxing Sun, Qian Li, and Errui Ding. AdaAttN: Revisit attention mechanism in arbitrary neural style transfer. InProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), pages 6649–6658, 2021. 2, 6
2021
-
[26]
T2I-Adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models
Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, and Ying Shan. T2I-Adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. InProc. AAAI Conf. Artif. Intell. (AAAI), pages 4296–4304, 2024. 3
2024
-
[27]
Arbitrary style trans- fer with style-attentional networks
Dae Young Park and Kwang Hee Lee. Arbitrary style trans- fer with style-attentional networks. InProc. IEEE/CVF Conf. Comput. Vis. Pattern Recog. (CVPR), pages 5880– 5888, 2019. 1, 2
2019
-
[28]
SDXL: Improving latent diffusion mod- els for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and 9 Robin Rombach. SDXL: Improving latent diffusion mod- els for high-resolution image synthesis. InProc. Int. Conf. Learn. Represent. (ICLR), 2024. 2, 8
2024
-
[29]
Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer.IEEE Transactions on Pattern Analysis and Ma- chine Intelligence, 44(3), 2022
Ren ´e Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer.IEEE Transactions on Pattern Analysis and Ma- chine Intelligence, 44(3), 2022. 3, 4
2022
-
[30]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InProc. IEEE/CVF Conf. Comput. Vis. Pattern Recog. (CVPR), pages 10684–10695,
-
[31]
Very deep convo- lutional networks for large-scale image recognition
Karen Simonyan and Andrew Zisserman. Very deep convo- lutional networks for large-scale image recognition. InProc. Int. Conf. Learn. Represent. (ICLR), 2015. 2
2015
-
[32]
Denois- ing diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denois- ing diffusion implicit models. InProc. Int. Conf. Learn. Rep- resent. (ICLR), 2021. 2, 3, 4
2021
-
[33]
WikiArt: Encyclopedia of visual art, 2016.https://www.wikiart.org/
Wei Ren Tan and Carlos Ortiz. WikiArt: Encyclopedia of visual art, 2016.https://www.wikiart.org/. 4
2016
-
[34]
ControlNet for Stable Diffusion 2.1.https:// huggingface
Thibaud. ControlNet for Stable Diffusion 2.1.https:// huggingface . co / thibaud / controlnet - sd21,
-
[35]
Hugging Face model repository. 7
-
[36]
Plug-and-play diffusion features for text-driven image-to-image translation
Narek Tumanyan, Michal Geyer, Shai Bagon, and Tali Dekel. Plug-and-play diffusion features for text-driven image-to-image translation. InProc. IEEE/CVF Conf. Com- put. Vis. Pattern Recog. (CVPR), pages 1921–1930, 2023. 1, 2, 4, 5, 8
1921
-
[37]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InProc. Adv. Neural Inform. Process. Syst. (NeurIPS), pages 5998–6008, 2017. 1, 3
2017
-
[38]
arXiv preprint arXiv:2404.02733 (2024)
Haofan Wang, Qixun Wang, et al. InstantStyle: Free lunch towards style-preserving in text-to-image generation.arXiv preprint arXiv:2404.02733, 2024. 2
-
[39]
ArtFID: Quantitative evaluation of neural style transfer
Matthias Wright and Bj ¨orn Ommer. ArtFID: Quantitative evaluation of neural style transfer. InDAGM German Con- ference on Pattern Recognition, pages 560–575, 2022. 2, 4
2022
-
[40]
StyleSSP: Sampling StartPoint enhancement for training-free diffusion-based method for style transfer
Ruojun Xu, Weijie Xi, Xiaodi Wang, Yongbo Mao, and Zach Cheng. StyleSSP: Sampling StartPoint enhancement for training-free diffusion-based method for style transfer. In Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recog. (CVPR), pages 18260–18269, 2025. 1, 2, 3
2025
-
[41]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. IP- Adapter: Text compatible image prompt adapter for text-to- image diffusion models.arXiv preprint arXiv:2308.06721,
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), pages 3836–3847, 2023. 1, 2, 3, 4, 7, 8
2023
-
[43]
Efros, Eli Shecht- man, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProc. IEEE/CVF Conf. Comput. Vis. Pattern Recog. (CVPR), pages 586–595,
-
[44]
Exact feature distribution matching for arbitrary style transfer and domain generalization
Yabin Zhang, Minghan Li, Ruihuang Li, Kui Jia, and Lei Zhang. Exact feature distribution matching for arbitrary style transfer and domain generalization. InProc. IEEE/CVF Conf. Comput. Vis. Pattern Recog. (CVPR), pages 8035– 8045, 2022. 6
2022
-
[45]
Do- main enhanced arbitrary image style transfer via contrastive learning
Yuxin Zhang, Fan Tang, Weiming Dong, Haibin Huang, Chongyang Ma, Tong-Yee Lee, and Changsheng Xu. Do- main enhanced arbitrary image style transfer via contrastive learning. InProc. ACM SIGGRAPH, 2022. 6
2022
-
[46]
Inversion-based style transfer with diffusion models
Yuxin Zhang, Nisha Huang, Fan Tang, Haibin Huang, Chongyang Ma, Weiming Dong, and Changsheng Xu. Inversion-based style transfer with diffusion models. In Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recog. (CVPR), pages 10146–10156, 2023. 2, 6
2023
-
[47]
Unpaired image-to-image translation using cycle- consistent adversarial networks
Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycle- consistent adversarial networks. InProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), pages 2223–2232, 2017. 3 10 Supplementary Material: Scheduled Style Injection: Expanding the Style-Content Pareto Frontier in Training-Free Diffusion-based Style Tr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.