Helicase: Uncertainty-Guided Supply Chain Knowledge Graph Construction with Autonomous Multi-Agent LLMs
Pith reviewed 2026-06-29 17:18 UTC · model grok-4.3
The pith
Helicase decomposes supply chain queries into multi-agent plans to build uncertainty-annotated knowledge graphs from fragmented web sources.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
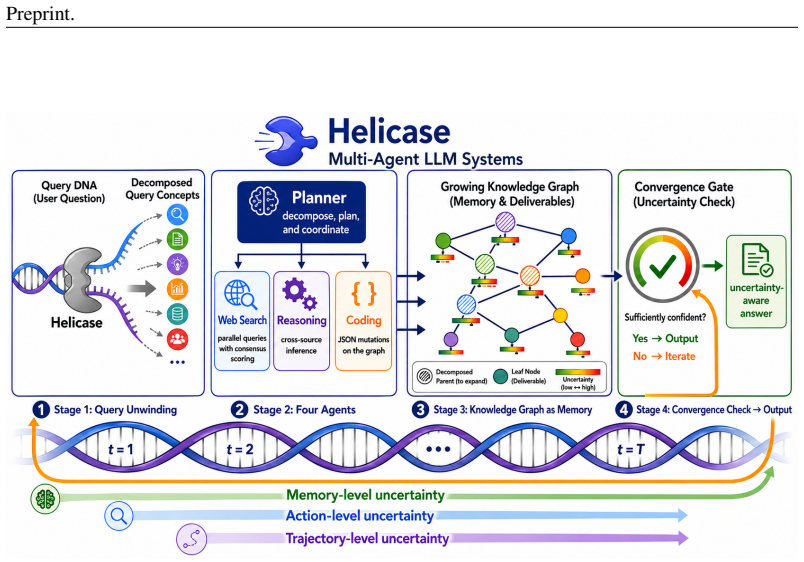
Helicase decomposes high-level supply-chain queries into executable investigation plans, coordinates specialized web-search, reasoning, and coding agents through iterative verification loops, and incrementally constructs query-specific supply chain knowledge graphs with per-fact uncertainty annotations. Its three-layer uncertainty framework tracks uncertainty at the action, trajectory, and memory layers, enabling both structural inference and calibrated confidence assessment.
What carries the argument
Three-layer uncertainty framework that tracks confidence at action, trajectory, and memory levels to guide agent coordination and annotate facts during incremental knowledge graph construction.
If this is right
- Complex supply chain questions can be resolved by synthesizing information into dynamic, query-specific graphs instead of relying on existing documents.
- Each inferred fact carries a confidence score linked to source quality and reasoning consistency for better decision support.
- Iterative verification loops allow agents to refine the knowledge graph until sufficient confidence is reached.
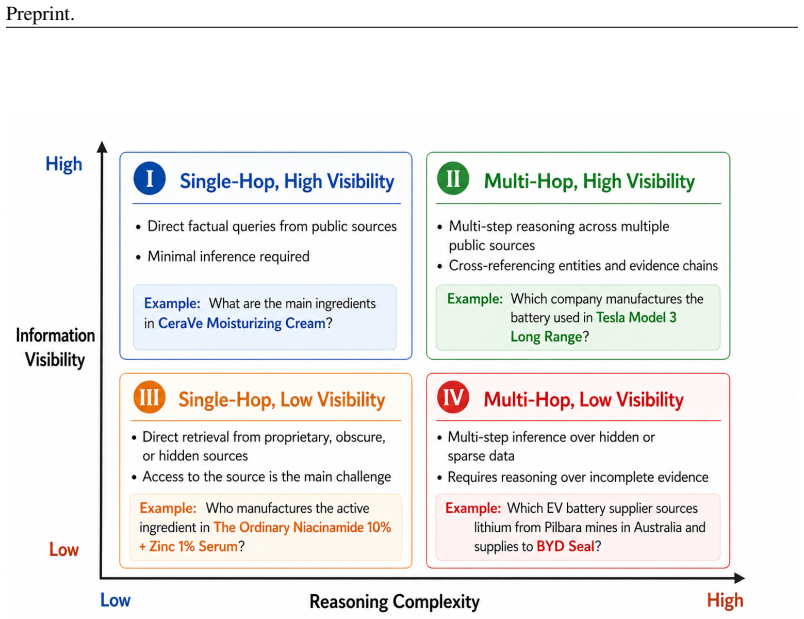
- The SCQA benchmark enables systematic testing of autonomous reasoning across single-hop and multi-hop scenarios with high and low data visibility.
Where Pith is reading between the lines
- Similar multi-agent approaches with uncertainty layers could be adapted for knowledge synthesis in other fields with dispersed information, such as academic research or regulatory compliance.
- The inclusion of coding agents opens the possibility for automated data validation and simulation within the investigation process.
- Calibrated uncertainty might support risk-aware planning by focusing agent efforts on low-confidence areas first.
Load-bearing premise
The three-layer uncertainty framework produces calibrated confidence traceable to source quality and reasoning consistency sufficient for reliable structural inference across fragmented web resources.
What would settle it
A mismatch between the system's reported uncertainty levels and actual accuracy on verified multi-hop queries from the SCQA benchmark would indicate the framework does not provide reliable calibration.
Figures

read the original abstract
LLM-based multi-agent systems have been widely adopted for knowledge retrieval and report generation, synthesizing known information through web search and textual reasoning. However, many critical information tasks in supply chains are not simple one-shot queries: they are structural inference problems requiring multi-hop reasoning across complex, fragmented web resources. Questions such as \textit{``Which Tesla components use lithium from Australian mines?''} have no answer in any single document; answers must be computationally synthesized through the autonomous construction and analysis of dynamic knowledge graphs assembled from fragmented, heterogeneous sources. Moreover, such discovery processes must be uncertainty-aware: decisions depend not only on answers but on calibrated confidence in their reliability, traceable to source quality and reasoning consistency. To address this capability gap, we propose \textit{Helicase}, an autonomous multi-agent LLM system for uncertainty-guided supply chain knowledge graph construction. \textit{Helicase} decomposes high-level supply-chain queries into executable investigation plans, coordinates specialized web-search, reasoning, and coding agents through iterative verification loops, and incrementally constructs query-specific supply chain knowledge graphs with per-fact uncertainty annotations. Its three-layer uncertainty framework tracks uncertainty at the action, trajectory, and memory layers, enabling both structural inference and calibrated confidence assessment. To evaluate autonomous reasoning across the full complexity spectrum, we introduce SCQA (Supply Chain Query Assessment), a benchmark of 80 supply chain queries organized into four quadrants spanning single-hop to multi-hop inference under both high and low data visibility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Helicase, an autonomous multi-agent LLM system for uncertainty-guided supply chain knowledge graph construction. It decomposes high-level queries into investigation plans, coordinates web-search, reasoning, and coding agents via iterative verification loops, incrementally builds query-specific KGs with per-fact uncertainty annotations from a three-layer (action/trajectory/memory) framework, and introduces the SCQA benchmark of 80 queries spanning single- to multi-hop inference under varying data visibility.
Significance. If the three-layer uncertainty framework produces calibrated per-fact confidences traceable to source quality and reasoning consistency, the approach could enable reliable structural inference for complex supply-chain queries that require synthesizing fragmented web sources, addressing a gap beyond one-shot retrieval. The SCQA benchmark provides a structured testbed for full-complexity autonomous reasoning. Without demonstrated calibration, however, the practical significance for trustworthy KG construction remains unestablished.
major comments (1)
- [Evaluation / SCQA benchmark section] Evaluation / SCQA results: the central claim that the three-layer uncertainty framework enables 'calibrated confidence assessment' sufficient for reliable multi-hop KG construction is load-bearing, yet the manuscript reports no quantitative calibration metrics (expected calibration error, Brier score, or reliability diagrams) comparing reported uncertainties to empirical accuracy across the 80 SCQA queries. This leaves the framework's key property as an untested modeling assumption rather than a demonstrated result.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for emphasizing the need to empirically validate the calibration of the three-layer uncertainty framework. We address the major comment below and commit to strengthening the evaluation section accordingly.
read point-by-point responses
-
Referee: [Evaluation / SCQA benchmark section] Evaluation / SCQA results: the central claim that the three-layer uncertainty framework enables 'calibrated confidence assessment' sufficient for reliable multi-hop KG construction is load-bearing, yet the manuscript reports no quantitative calibration metrics (expected calibration error, Brier score, or reliability diagrams) comparing reported uncertainties to empirical accuracy across the 80 SCQA queries. This leaves the framework's key property as an untested modeling assumption rather than a demonstrated result.
Authors: We agree that the absence of quantitative calibration metrics leaves the central claim under-supported. The current manuscript describes the three-layer (action/trajectory/memory) uncertainty tracking mechanism and its use in constructing per-fact annotations on the SCQA benchmark but does not report empirical calibration statistics. In the revised manuscript we will add Expected Calibration Error (ECE), Brier scores, and reliability diagrams computed across all 80 SCQA queries. These metrics will be presented both in aggregate and broken down by the four benchmark quadrants (single-hop vs. multi-hop, high vs. low visibility) to demonstrate whether the reported uncertainties are well-calibrated with respect to empirical accuracy. This addition will convert the calibration property from an untested modeling assumption into a demonstrated result. revision: yes
Circularity Check
No circularity: system architecture and benchmark proposal are self-contained
full rationale
The paper introduces Helicase as a multi-agent LLM architecture for query-driven supply-chain KG construction together with a three-layer uncertainty tracking design and the SCQA benchmark. No equations, fitted parameters, or derivation steps appear in the provided text. The uncertainty framework is presented as an explicit design choice (action/trajectory/memory layers) rather than a quantity derived from or fitted to the system's own outputs. The SCQA benchmark is introduced as an independent evaluation set of 80 queries, not as a fitted input. No self-citations are used to justify uniqueness theorems or ansatzes, and no renaming of known results occurs. The central claims remain architectural proposals whose validity is left to empirical evaluation rather than reducing to self-definition by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ajmal Aziz, Edward Elson Kosasih, Ryan-Rhys Griffiths, and Alexandra Brintrup. Data considera- tions in graph representation learning for supply chain networks.arXiv preprint arXiv:2107.10609,
-
[2]
Brintrup, P
A. Brintrup, P. Wichmann, P. Woodall, D. McFarlane, E. Nicks, and W. Krechel. Predicting hidden links in supply networks.Complexity, 2018(1):9104387,
2018
-
[3]
Alexandra Brintrup, Edward Kosasih, Philipp Schaffer, Ge Zheng, Guven Demirel, and Bart L MacCarthy
doi: 10.1155/2018/9104387. Alexandra Brintrup, Edward Kosasih, Philipp Schaffer, Ge Zheng, Guven Demirel, and Bart L MacCarthy. Digital supply chain surveillance using artificial intelligence: definitions, opportunities and risks.International Journal of Production Research, 62(13):4674–4695,
-
[4]
Sparks of Artificial General Intelligence: Early experiments with GPT-4
Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, et al. Sparks of artificial general intelligence: Early experiments with GPT-4.arXiv preprint arXiv:2303.12712,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Visibility into ai agents
Alan Chan, Carson Ezell, Max Kaufmann, Kevin Wei, Lewis Hammond, Herbie Bradley, Emma Bluemke, Nitarshan Rajkumar, David Krueger, Noam Kolt, et al. Visibility into ai agents. In Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, pp. 958–973,
2024
-
[6]
Understanding Dataset Design Choices for Multi-hop Reasoning
Jifan Chen and Greg Durrett. Understanding dataset design choices for multi-hop reasoning.arXiv preprint arXiv:1904.12106,
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[7]
DeepSeek-AI. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
SafeSearch: Automated Red-Teaming of LLM-Based Search Agents
Jianshuo Dong, Sheng Guo, Hao Wang, Xun Chen, Zhuotao Liu, Tianwei Zhang, Ke Xu, Minlie Huang, and Han Qiu. Safesearch: Automated red-teaming for the safety of llm-based search agents. arXiv preprint arXiv:2509.23694,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Towards uncertainty-aware language agent.arXiv preprint arXiv:2401.14016,
Jiuzhou Han, Wray Buntine, and Ehsan Shareghi. Towards uncertainty-aware language agent.arXiv preprint arXiv:2401.14016,
-
[10]
Deep research agents: A systematic examination and roadmap.arXiv preprint arXiv:2506.18096,
Yuxuan Huang, Yihang Chen, Haozheng Zhang, Kang Li, Huichi Zhou, Meng Fang, Linyi Yang, Xiaoguang Li, Lifeng Shang, Songcen Xu, et al. Deep research agents: A systematic examination and roadmap.arXiv preprint arXiv:2506.18096,
-
[11]
Position: Uncertainty quantification needs reassessment for large-language model agents, 2025
Michael Kirchhof, Gjergji Kasneci, and Enkelejda Kasneci. Position: Uncertainty quantification needs reassessment for large-language model agents.arXiv preprint arXiv:2505.22655,
-
[12]
Mahjabin Nahar, Eun-Ju Lee, Jin Won Park, and Dongwon Lee. Catch me if you search: When con- textual web search results affect the detection of hallucinations.arXiv preprint arXiv:2504.01153,
-
[13]
Yinzhu Quan and Zefang Liu. Invagent: A large language model based multi-agent system for inventory management in supply chains.arXiv preprint arXiv:2407.11384,
-
[14]
20 Preprint. Qwen Team. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. In Advances in Neural Information Processing Systems, 2023a. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoni...
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Deep research: A survey of autonomous research agents.arXiv preprint arXiv:2508.12752,
Wenlin Zhang, Xiaopeng Li, Yingyi Zhang, Pengyue Jia, Yichao Wang, Huifeng Guo, Yong Liu, and Xiangyu Zhao. Deep research: A survey of autonomous research agents.arXiv preprint arXiv:2508.12752,
-
[17]
Saup: Situation awareness uncertainty propagation on llm agent, 2024
Qiwei Zhao, Xujiang Zhao, Yanchi Liu, Wei Cheng, Yiyou Sun, Mika Oishi, Takao Osaki, Katsushi Matsuda, Huaxiu Yao, and Haifeng Chen. Saup: Situation awareness uncertainty propagation on llm agent.arXiv preprint arXiv:2412.01033,
-
[18]
Efficient multi-agent collabo- ration with tool use for online planning in complex table question answering
Wei Zhou, Mohsen Mesgar, Annemarie Friedrich, and Heike Adel. Efficient multi-agent collabo- ration with tool use for online planning in complex table question answering. InFindings of the Association for Computational Linguistics: NAACL 2025, pp. 945–968,
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.