SQARL: A Size-Agnostic Reinforcement Learning approach for Circuit Allocation in Distributed Quantum Architectures
Pith reviewed 2026-06-29 19:07 UTC · model grok-4.3
The pith
Transformer-based RL learns qubit allocation policies that generalize to any circuit and hardware size without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors show that their size-agnostic transformer RL model learns an allocation policy capable of minimizing inter-core communication for quantum circuits on distributed hardware, generalizing to arbitrary sizes and topologies after one training run, and delivering allocation costs 25% lower on average than previous methods for random circuits.
What carries the argument
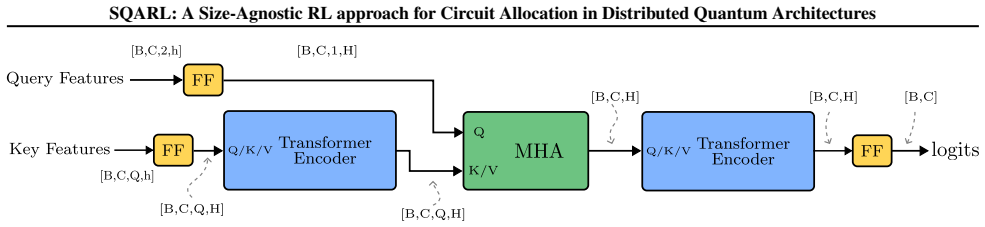
A transformer-based policy network that encodes sets of qubits and cores of arbitrary cardinality to select allocation mappings in a reinforcement learning setup for the qubit allocation problem.
If this is right
- The same policy applies directly to new hardware configurations without additional training.
- Learning methods can achieve allocation quality close to that of specialized heuristics like HQA.
- Reduced communication costs from better allocation improve the feasibility of large-scale distributed quantum computations.
Where Pith is reading between the lines
- This flexibility suggests that RL could become the default for dynamic quantum hardware environments where topologies change over time.
- Future work might test whether the model can handle noisy intermediate-scale quantum constraints beyond just communication cost.
Load-bearing premise
The model trained on a fixed set of circuit and topology examples will perform well on unseen sizes and topologies.
What would settle it
Evaluating the policy on a circuit with a number of qubits outside the training range or on a hardware graph with different connectivity and measuring if the cost exceeds the HQA baseline.
Figures


read the original abstract
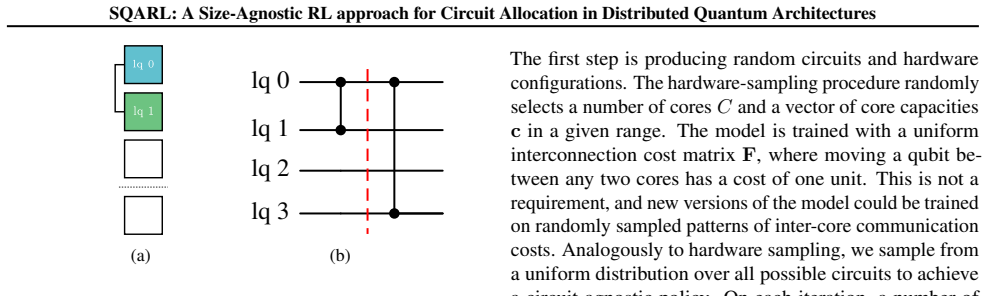
The scaling of quantum processors is currently limited by technical challenges such as decoherence and cross-talk. As the number of qubits grows, interference increases the computational noise. Distributed quantum computing addresses these limitations by interconnecting smaller, easier-to-handle quantum processors (cores), but it introduces the challenge of minimizing slow, error-prone inter-core communication. The task of distributing quantum circuits across cores while minimizing communication costs is known as the Qubit Allocation problem. This work focuses on developing a deep learning approach to this problem, emphasizing flexibility to quantum hardware topology and improving state-of-the-art performance. Heuristic and non-learning algorithms, such as the Hungarian Qubit Allocation (HQA), currently represent the state of the art. Reinforcement Learning (RL) approaches leverage learned allocation policies but often lack flexibility, requiring retraining when hardware configurations change, and they fall short of the solution quality achieved by non-learning methods. However, learning mechanisms could outperform human-crafted heuristics. To overcome these limitations, this work proposes a flexible, transformer-based architecture that can handle arbitrary numbers of qubits and cores without retraining. Results show that the trained policy consistently outperforms the previous RL state of the art and narrows the gap between RL and HQA for the most common circuits. It achieves a 33% reduction in allocation cost relative to the HQA for the Cuccaro Adder and 25% on average for random circuits. These findings show that learning-based approaches can effectively match the performance of hand-crafted heuristics, a crucial step towards their application in real-world scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SQARL, a transformer-based reinforcement learning architecture for the qubit allocation problem in distributed quantum computing. It claims the method is size-agnostic (handling arbitrary qubit/core counts and topologies without retraining), outperforms prior RL baselines, and narrows the gap to the Hungarian Qubit Allocation (HQA) heuristic, with reported gains of 33% cost reduction versus HQA on the Cuccaro Adder and 25% average on random circuits.
Significance. If the size-agnostic generalization claim holds with verifiable zero-shot transfer, the result would be significant for practical RL deployment in quantum hardware, as it removes the retraining requirement that currently limits learned policies relative to topology-independent heuristics. The empirical narrowing of the RL-HQA gap, if robustly demonstrated, would credit the transformer encoder for enabling competitive learned allocation policies.
major comments (2)
- [Abstract] Abstract: The central claim that the architecture 'can handle arbitrary numbers of qubits and cores without retraining' is load-bearing for the reported performance gains, yet the provided text contains no experimental section, table, or figure demonstrating zero-shot transfer to topologies or sizes materially outside the training distribution (e.g., 2-D to 3-D grids or 4-core to 16-core configurations). Without such evidence, the 33% and 25% improvements cannot be attributed to the claimed flexibility.
- [Abstract] Abstract (performance claims): The headline results (33% reduction vs. HQA on Cuccaro Adder; 25% average on random circuits; outperforming prior RL) are presented without reference to training/test topology distributions, statistical tests, or ablations isolating the transformer attention mechanism, which is required to confirm that gains stem from size-agnostic properties rather than in-distribution fitting.
minor comments (1)
- [Abstract] Abstract: The description of the RL algorithm (e.g., policy gradient variant or value function) and state representation details are omitted, which would aid clarity even in a high-level summary.
Simulated Author's Rebuttal
Thank you for the detailed review and valuable feedback on our manuscript. We appreciate the emphasis on the importance of demonstrating the size-agnostic properties and the need for clearer experimental context in the abstract. Below, we provide point-by-point responses to the major comments and outline the revisions we will make to address them.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the architecture 'can handle arbitrary numbers of qubits and cores without retraining' is load-bearing for the reported performance gains, yet the provided text contains no experimental section, table, or figure demonstrating zero-shot transfer to topologies or sizes materially outside the training distribution (e.g., 2-D to 3-D grids or 4-core to 16-core configurations). Without such evidence, the 33% and 25% improvements cannot be attributed to the claimed flexibility.
Authors: We agree that the abstract, being a concise summary, does not include direct references or citations to the supporting experiments. The manuscript body includes experimental results that evaluate the trained policy on varying numbers of qubits and cores, as well as different topologies, without retraining, including instances outside the training distribution. We will revise the abstract to explicitly reference this experimental validation of zero-shot generalization, for example by adding a phrase such as 'supported by zero-shot evaluations on unseen sizes and topologies.' This will strengthen the link between the flexibility claim and the reported performance gains. revision: yes
-
Referee: [Abstract] Abstract (performance claims): The headline results (33% reduction vs. HQA on Cuccaro Adder; 25% average on random circuits; outperforming prior RL) are presented without reference to training/test topology distributions, statistical tests, or ablations isolating the transformer attention mechanism, which is required to confirm that gains stem from size-agnostic properties rather than in-distribution fitting.
Authors: We acknowledge that the abstract would benefit from additional context on the experimental conditions to better support attribution of the gains. The manuscript details the training and evaluation distributions, reports aggregated results with variability measures, and presents ablations on architectural components including the transformer. We will revise the abstract to briefly indicate the relevant setup, such as noting evaluation across diverse circuit sizes and topologies. This will help clarify that the improvements relate to the size-agnostic design. revision: yes
Circularity Check
No significant circularity; empirical results rest on external baselines.
full rationale
The paper reports trained RL policy performance on allocation cost for specific circuits (Cuccaro Adder, random circuits) against prior RL methods and the external HQA heuristic. No equations, self-citations, or fitted parameters are presented as load-bearing derivations that reduce to the method's own inputs by construction. The size-agnostic claim is an architectural assertion evaluated empirically rather than a self-referential definition or renamed known result. This is the common case of a self-contained empirical ML paper with independent external comparisons.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jnane, H., Undseth, B., Cai, Z., Benjamin, S
IBM Quantum blog, accessed 2026-02-12. Jnane, H., Undseth, B., Cai, Z., Benjamin, S. C., and Koczor, B. Multicore quantum comput- ing.Phys. Rev. Appl., 18:044064, October 2022. https://doi.org/10.1103/PhysRevApplied.18.044064. Kool, W., van Hoof, H., and Welling, M. Attention, learn to solve routing problems! InProceedings of the 7th International Confere...
-
[2]
Luo, F., Lin, X., Liu, F., Zhang, Q., and Wang, Z
https://openreview.net/forum?id= ByxBFsRqYm. Luo, F., Lin, X., Liu, F., Zhang, Q., and Wang, Z. Neural combinatorial optimization with heavy decoder: Toward large scale generalization. InProceedings of the 37th International Conference on Neural Information Process- ing Systems, Red Hook, NY , USA, 2023. Curran As- sociates Inc. https://openreview.net/for...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.