Megakernel vs Wavefront GPU Path Tracing
Pith reviewed 2026-06-29 14:24 UTC · model grok-4.3
The pith
Wavefront path tracing runs about 16 percent faster than megakernel path tracing on GPUs by improving cache locality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
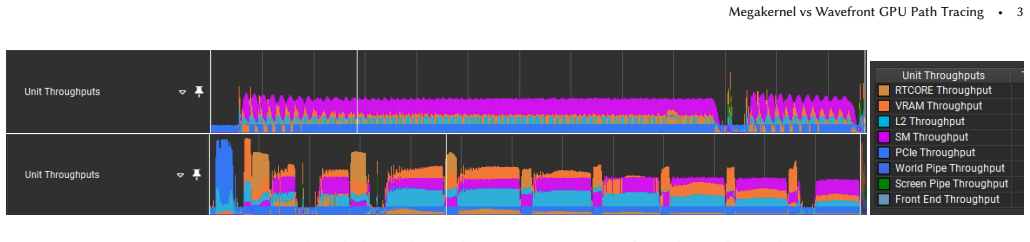
In our implementation, wavefront path tracing provides approximately a 16% performance improvement over forward path tracing. This speedup is attributed to enhanced cache locality, as revealed by analysis with NVIDIA Nsight Graphics. The implementations do not reach maximum throughput on any GPU units, indicating that communication, memory latency, and synchronization are the primary limiting factors.
What carries the argument
The side-by-side execution of megakernel path tracing (single-thread full paths) versus wavefront path tracing (staged kernels with intermediate state buffers), measured for runtime and cache behavior via hardware traces.
If this is right
- Wavefront path tracing delivers a 16% speedup over megakernel path tracing.
- The performance difference is caused by improved cache locality under the wavefront organization.
- Neither approach saturates GPU compute units; memory latency, communication, and synchronization remain the binding constraints.
- Future real-time path tracing work should target reductions in data movement and synchronization overhead.
Where Pith is reading between the lines
- Organizing ray work into wavefront stages may reduce cache pressure for other ray-tracing workloads that share similar memory access patterns.
- Hardware generations with larger or smarter caches could change the magnitude of the observed difference.
- The same staging technique might be applied to non-path-tracing ray algorithms such as photon mapping or volume rendering.
Load-bearing premise
The observed 16 percent gap and its attribution to cache locality are not specific to the chosen scenes, shader complexity, or hardware generation, and that the tracing tool isolates cache effects without confounding pipeline stages.
What would settle it
Re-running the same comparison on a different GPU generation or with scenes of markedly different geometric and shading complexity and checking whether a speedup near 16 percent still appears and is still traceable to cache locality in the traces.
Figures

read the original abstract
Over the last decade, advances in GPU hardware have been driven in large part by the demands of real-time graphics, culminating in dedicated hardware ray tracing cores (RT cores). These units accelerate ray scene intersection queries directly in hardware, making physically based ray tracing algorithms increasingly practical for interactive applications. This paper compares and analyzes the performance of two ray-based rendering algorithms: forward path tracing (PT) and wavefront path tracing (WPT). GPU-based PT computes the color of each pixel by having each thread trace a single path to completion, naturally leading to a megakernel approach - while WPT maintains state buffers between specialized kernel invocations to trace path stages simultaneously. We find that WPT affords a ~16% speedup over PT in our implementation. By analyzing traces from NVIDIA Nsight Graphics, we attributed this speedup to WPT's improved cache locality compared to PT. We also find that our implementation does not achieve maximum GPU throughput across any of its units, suggesting that communication and memory latency, as well as synchronization, are the limiting factors. Finally, we address potential algorithmic improvements and future work for real-time path tracing implementation for practical applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript compares megakernel-based forward path tracing (PT) and wavefront path tracing (WPT) on GPUs equipped with RT cores. It reports that WPT yields an approximately 16% speedup over PT in the authors' implementation, with the performance difference attributed to improved cache locality as diagnosed from NVIDIA Nsight Graphics traces. The paper further observes that neither implementation saturates any GPU execution unit and identifies communication, memory latency, and synchronization as the dominant bottlenecks, while outlining directions for future real-time path-tracing work.
Significance. Should the reported speedup and its cache-locality attribution prove robust under controlled conditions, the work would supply practical guidance on scheduling choices for GPU ray tracing. The explicit use of hardware performance counters to identify bottlenecks is a constructive element that grounds the discussion in measurable data.
major comments (2)
- [Abstract] Abstract: The claim of a ~16% WPT-over-PT speedup is presented without accompanying scene descriptions, hardware specifications, run counts, error bars, or statistical tests, preventing assessment of whether the gap is reproducible or sensitive to the particular test conditions.
- [Abstract] Abstract: The attribution of the speedup to improved cache locality rests on Nsight traces, yet the manuscript simultaneously states that communication, memory latency, and synchronization—not compute or cache—are the limiting factors. No ablation that holds shader complexity, path-length distribution, and kernel-launch overhead fixed while varying only the megakernel versus wavefront organization is described, leaving the causal link unisolated.
minor comments (2)
- The abstract refers to 'our implementation' without cross-references to later sections that would detail the concrete differences in state management, kernel launch patterns, or buffer layouts between PT and WPT.
- Consider adding a compact table that reports per-unit utilization (e.g., RT-core, SM, L1/L2 cache hit rates) for both PT and WPT across the tested scenes; this would make the Nsight-based analysis more transparent.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of a ~16% WPT-over-PT speedup is presented without accompanying scene descriptions, hardware specifications, run counts, error bars, or statistical tests, preventing assessment of whether the gap is reproducible or sensitive to the particular test conditions.
Authors: The experimental setup, including scene descriptions and hardware platform, is detailed in Section 4 of the manuscript. We will revise the abstract to summarize the GPU model, the scenes evaluated, and the number of frames rendered per measurement. The reported 16% figure is the observed average difference; we will add an explicit statement that per-scene variation was small and no formal statistical tests were applied. revision: yes
-
Referee: [Abstract] Abstract: The attribution of the speedup to improved cache locality rests on Nsight traces, yet the manuscript simultaneously states that communication, memory latency, and synchronization—not compute or cache—are the limiting factors. No ablation that holds shader complexity, path-length distribution, and kernel-launch overhead fixed while varying only the megakernel versus wavefront organization is described, leaving the causal link unisolated.
Authors: We will clarify the distinction in the revised text: both implementations are memory-latency and synchronization bound (as confirmed by unsaturated execution units), yet the Nsight traces indicate that the wavefront organization yields measurably higher cache hit rates, reducing effective memory stalls. The two implementations use identical shaders and path-length distributions; the primary difference is the single-kernel versus multi-kernel scheduling. We acknowledge that a narrower ablation isolating only the organization was not performed and will note this limitation. revision: partial
Circularity Check
No circularity: purely empirical timing and profiling results
full rationale
The paper reports measured wall-clock speedups (~16%) and Nsight Graphics counter data between two concrete GPU implementations (megakernel PT vs. wavefront WPT). No equations, fitted parameters, predictions, or first-principles derivations appear; the central claims are direct observations from execution traces and timing. Attribution to cache locality is an interpretive claim about the measured counters, not a reduction of one quantity to another by definition or self-citation. No load-bearing self-citations or ansatzes are present. This is the expected non-finding for an empirical systems paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Dedicated RT cores accelerate ray-scene intersection queries directly in hardware.
Reference graph
Works this paper leans on
-
[1]
M.RenderMan XPU: A Hybrid CPU+GPU Renderer for Interactive and Final-frame Rendering.Computer Graphics Forum(2025)
Christensen, P., Fong, J., Nettleship, T., Seshadri, M., Salituro, S., Kilpatrick, C., Gonzalez, F., Ravichandran, S., Shah, A., Jaszewski, E., Friedman, S., Burgess, J., and Roy, T. M.RenderMan XPU: A Hybrid CPU+GPU Renderer for Interactive and Final-frame Rendering.Computer Graphics Forum(2025)
2025
-
[2]
T.The rendering equation.SIGGRAPH Comput
Kajiya, J. T.The rendering equation.SIGGRAPH Comput. Graph. 20, 4 (Aug. 1986), 143–150
1986
-
[3]
InProceedings of the 5th High-Performance Graphics Confer- ence(New York, NY, USA, 2013), HPG ’13, Association for Computing Machinery, p
Laine, S., Karras, T., and Aila, T.Megakernels considered harmful: wavefront path tracing on gpus. InProceedings of the 5th High-Performance Graphics Confer- ence(New York, NY, USA, 2013), HPG ’13, Association for Computing Machinery, p. 137–143
2013
-
[4]
MIT Press, 2023
Pharr, M., Jakob, W., and Humphreys, G.Physically Based Rendering, Fourth Edition: From Theory to Implementation. MIT Press, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.