Ocean4Rec: Offline LLM-Derived OCEAN Profiles for Request-Time VOD Reranking
Pith reviewed 2026-06-30 15:12 UTC · model grok-4.3
The pith
Ocean4Rec reranks VOD items using precomputed LLM OCEAN profiles and time-decayed user aggregates without any request-time LLM calls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
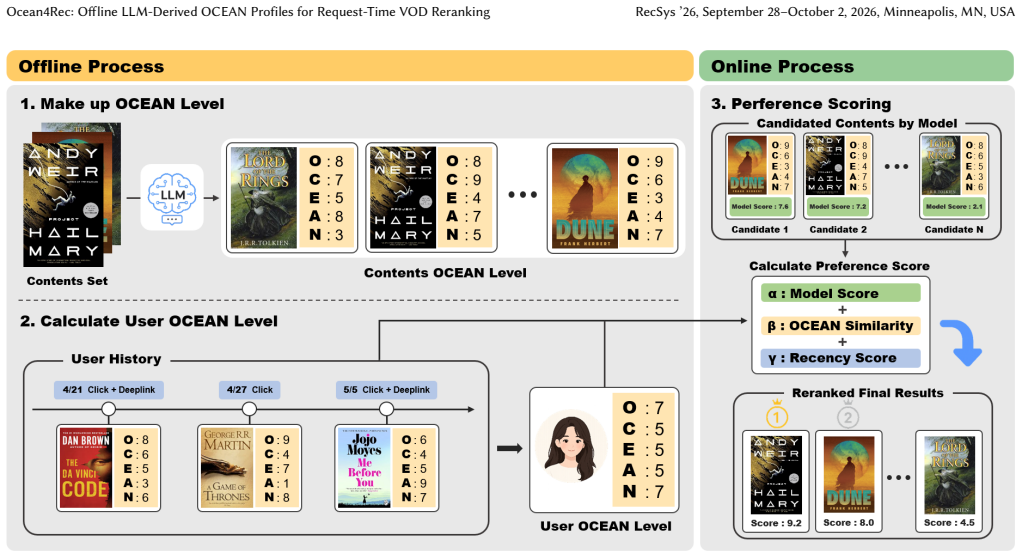
Ocean4Rec maps item metadata to OCEAN scores offline, builds time-decayed user profiles from interaction history in the same five dimensions, and at request time joins these with base recommender scores plus catalog recency to perform purely numeric reranking. On temporal-holdout replay of Top-1000 candidates from real VOD logs this yields NDCG@20 gains of 7.6 percent for an NCF base and 61.5 percent for a LightGCN base while leaving the online path free of LLM invocations.
What carries the argument
The OCEAN profile: a five-dimensional vector of scores for Openness, Conscientiousness, Extraversion, Agreeableness and Neuroticism obtained by offline LLM processing of item metadata and aggregated with exponential time decay for users.
If this is right
- Reranking layers can incorporate personality-derived content signals while remaining fully numeric and latency-predictable at request time.
- Offline materialization of item profiles separates heavy LLM work from the serving path.
- The auxiliary feature remains useful even when the base generator already receives recency signals.
- Gains appear across two different collaborative-filtering generators in the same log replay setting.
Where Pith is reading between the lines
- The same offline profiling pattern could be tried with other fixed trait or embedding spaces derived from metadata.
- Production systems might measure the reduction in LLM inference cost and tail-latency variance once the request-time path is eliminated.
- Live A/B tests would be required to determine whether replay NDCG lifts translate into measurable user engagement changes.
- The approach suggests examining whether simpler non-LLM metadata extractors can produce comparable profile vectors.
Load-bearing premise
LLM-derived OCEAN scores from content metadata capture aspects of user preference that, when aggregated with time decay, add ranking value beyond what base models and recency already provide.
What would settle it
Re-run the identical Top-1000 temporal-holdout evaluation after replacing every OCEAN vector with random numbers drawn from the same distribution and check whether the reported NDCG@20 lifts disappear.
Figures
read the original abstract
Industrial video-on-demand (VOD) recommenders need richer content understanding, but LLM-as-reranker designs repeat prompt construction, token generation, model invocation, output parsing, and fallback handling for each request. In high-volume latency-sensitive services, these request-time operations complicate throughput planning, tail-latency control, capacity isolation, and predictable operation. This paper presents Ocean4Rec, a reranking layer that uses an LLM only offline to materialize item OCEAN profiles from content metadata. Items are mapped into Openness, Conscientiousness, Extraversion, Agreeableness, and Neuroticism scores, while user profiles are built by time-decayed aggregation of recently clicked and deep-linked items in the same five-dimensional space. At request time, Ocean4Rec joins precomputed item profiles, user profiles, base recommender scores, and catalog recency, then performs numeric reranking without an LLM call. On anonymized Samsung Smart TV VOD logs, same-candidate Top1000 temporal-holdout offline evaluations show that Ocean4Rec improves NDCG@20 over a stronger non-OCEAN Base+Recency ordering by 7.6% for an NCF generator and 61.5% for a LightGCN generator. HR@20 is inconclusive for NCF and improves by 67.3% for LightGCN, reflecting sparse exact-item replay labels and the strength of recency as an industrial baseline. The result should be read as offline replay evidence for a bounded auxiliary content-taste feature that preserves the deployability advantage of a request-time-LLM-free serving path.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Ocean4Rec, a VOD reranking layer that materializes item OCEAN (Openness, Conscientiousness, Extraversion, Agreeableness, Neuroticism) profiles offline via LLM from content metadata, builds time-decayed user profiles from interaction history in the same space, and performs numeric reranking at request time by combining precomputed profiles with base recommender scores and recency. On anonymized Samsung Smart TV logs, same-candidate Top-1000 temporal-holdout replay evaluations report NDCG@20 gains of 7.6% (NCF generator) and 61.5% (LightGCN generator) over a non-OCEAN Base+Recency baseline, with HR@20 inconclusive for NCF and +67.3% for LightGCN; the design avoids request-time LLM calls.
Significance. If the reported additive gains hold under the stated conditions, the work demonstrates a practical route to injecting metadata-derived content-taste signals into high-throughput industrial recommenders while preserving the latency and capacity predictability of a fully numeric serving path. The offline materialization, temporal-holdout protocol, and explicit comparison against a recency-augmented baseline are strengths that directly address deployability concerns common in LLM-augmented ranking.
major comments (2)
- [§4] §4 (Experiments): The reported NDCG@20 deltas are given only as relative percentages without absolute baseline values, variance estimates, or statistical significance tests; this limits assessment of whether the 7.6% (NCF) and 61.5% (LightGCN) improvements are practically meaningful or sensitive to the sparse replay labels noted in the abstract.
- [§3.2] §3.2 (Profile Construction): The mapping from content metadata to OCEAN scores via LLM is described at a high level but omits the exact prompt template, model version, decoding parameters, and any post-processing or normalization steps; these details are load-bearing for reproducing the claimed feature quality and for evaluating the weakest assumption that the derived scores capture preference-relevant dimensions.
minor comments (2)
- [Abstract] The abstract and §1 state that HR@20 is inconclusive for NCF; a short parenthetical note on the absolute HR@20 numbers would help readers interpret the NDCG improvement in context of the sparse-label regime.
- [§3.1] Notation for the time-decay aggregation (e.g., the free parameter mentioned in the axiom ledger) should be introduced with an explicit equation in §3.1 to avoid ambiguity when readers compare against the Base+Recency baseline.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation of minor revision. We address each major comment below and will update the manuscript accordingly.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The reported NDCG@20 deltas are given only as relative percentages without absolute baseline values, variance estimates, or statistical significance tests; this limits assessment of whether the 7.6% (NCF) and 61.5% (LightGCN) improvements are practically meaningful or sensitive to the sparse replay labels noted in the abstract.
Authors: We agree that absolute baseline values, variance estimates, and significance tests would improve interpretability. In the revised manuscript we will add the absolute NDCG@20 figures for the Base+Recency baseline and Ocean4Rec under both generators. We will also report standard deviations computed across the temporal splits and include paired significance tests (e.g., Wilcoxon signed-rank) on the per-user NDCG differences. We retain the observation that sparse exact-item replay labels are intrinsic to VOD logs and that the comparison is already against a strong recency-augmented baseline. revision: yes
-
Referee: [§3.2] §3.2 (Profile Construction): The mapping from content metadata to OCEAN scores via LLM is described at a high level but omits the exact prompt template, model version, decoding parameters, and any post-processing or normalization steps; these details are load-bearing for reproducing the claimed feature quality and for evaluating the weakest assumption that the derived scores capture preference-relevant dimensions.
Authors: We concur that these details are necessary for reproducibility. The revised §3.2 will include the complete prompt template, the exact LLM model and version used, decoding hyperparameters (temperature, top-p, max tokens), and the normalization/post-processing steps applied to the five OCEAN dimensions. revision: yes
Circularity Check
No significant circularity; system design with external evaluation
full rationale
The paper describes an offline LLM-based profile generation step followed by time-decayed aggregation and numeric reranking, evaluated via temporal-holdout replay against Base+Recency baselines on real VOD logs. No derivation chain reduces a claimed result to its own inputs by construction; the reported NDCG lifts are measured on held-out data and do not rely on self-citation for uniqueness or on renaming fitted quantities as predictions. The method is a deployable engineering artifact rather than a closed mathematical derivation.
Axiom & Free-Parameter Ledger
free parameters (1)
- time decay factor
axioms (2)
- domain assumption OCEAN personality traits can be meaningfully assigned to video content from metadata by LLM
- domain assumption Aggregated user OCEAN profiles reflect evolving user preferences
Reference graph
Works this paper leans on
-
[1]
Gediminas Adomavicius and Alexander Tuzhilin. 2005. Toward the Next Gener- ation of Recommender Systems: A Survey of the State-of-the-Art and Possible Ocean4Rec: Offline LLM-Derived OCEAN Profiles for Request-Time VOD Reranking RecSys ’26, September 28–October 2, 2026, Minneapolis, MN, USA Extensions. IEEE Transactions on Knowledge and Data Engineering, 1...
2005
-
[2]
https://doi.org/10.1109/TKDE.2005.99
-
[3]
Keqin Bao, Jizhi Zhang, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He
-
[4]
TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation. RecSys 2023. https://arxiv.org/abs/ 2305.00447
-
[5]
Robin Burke. 2002. Hybrid Recommender Systems: Survey and Experiments. User Modeling and User-Adapted Interaction, 12, 331–370. https://doi.org/10.1023/A: 1021240730564
work page doi:10.1023/a: 2002
-
[6]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu
-
[7]
M3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. arXiv:2402.03216. https: //arxiv.org/abs/2402.03216
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, Rohan Anil, Zakaria Haque, Lichan Hong, Vihan Jain, Xiaobing Liu, and Hemal Shah
-
[9]
Wide & Deep Learning for Recommender Systems
Wide & Deep Learning for Recommender Systems. DLRS 2016. https: //arxiv.org/abs/1606.07792
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[10]
Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep Neural Networks for YouTube Recommendations. RecSys 2016. https://research.google.com/pubs/ archive/45530.pdf
2016
-
[11]
Tibshirani
Bradley Efron and Robert J. Tibshirani. 1993.An Introduction to the Bootstrap. Chapman & Hall/CRC, Boca Raton, FL, USA
1993
-
[12]
Lewis R. Goldberg. 1990. An Alternative “Description of Personality”: The Big-Five Factor Structure. Journal of Personality and Social Psychology, 59(6), 1216–1229. https://doi.org/10.1037/0022-3514.59.6.1216
-
[13]
Carlos A. Gomez-Uribe and Neil Hunt. 2015. The Netflix Recommender System: Algorithms, Business Value, and Innovation.ACM Transactions on Management Information Systems6, 4 (2015), 1–19. doi:10.1145/2843948
-
[14]
Google Cloud. 2025. Gemini 2.5 Pro. Vertex AI Generative AI Documen- tation. https://docs.cloud.google.com/vertex-ai/generative-ai/docs/models/ gemini/2-5-pro
2025
- [15]
- [16]
-
[17]
Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu, and Tat-Seng Chua. 2017. Neural Collaborative Filtering. WWW 2017. https://arxiv.org/abs/ 1708.05031
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
Herlocker, Joseph A
Jonathan L. Herlocker, Joseph A. Konstan, Loren G. Terveen, and John T. Riedl
-
[19]
ACM Transac- tions on Information Systems, 22(1), 5–53
Evaluating Collaborative Filtering Recommender Systems. ACM Transac- tions on Information Systems, 22(1), 5–53. https://doi.org/10.1145/963770.963772
-
[20]
Yupeng Hou, Jiacheng Li, Zhankui He, An Yan, Xiusi Chen, and Julian McAuley
-
[21]
Bridging Language and Items for Retrieval and Recommendation: Benchmarking LLMs as Semantic Encoders
Bridging Language and Items for Retrieval and Recommendation. arXiv:2403.03952. https://arxiv.org/abs/2403.03952
work page internal anchor Pith review Pith/arXiv arXiv
- [22]
-
[23]
Rong Hu and Pearl Pu. 2011. Enhancing Collaborative Filtering Systems with Per- sonality Information. InProceedings of the Fifth ACM Conference on Recommender Systems. ACM, New York, NY, USA, 197–204. doi:10.1145/2043932.2043969
-
[24]
Yifan Hu, Yehuda Koren, and Chris Volinsky. 2008. Collaborative Filtering for Implicit Feedback Datasets. ICDM 2008. https://doi.org/10.1109/ICDM.2008.22
-
[25]
Kalervo Järvelin and Jaana Kekäläinen. 2002. Cumulated Gain-Based Evaluation of IR Techniques. ACM Transactions on Information Systems, 20(4), 422–446. https://doi.org/10.1145/582415.582418
-
[26]
Yitong Ji, Aixin Sun, Jie Zhang, and Chenliang Li. 2023. A Critical Study on Data Leakage in Recommender System Offline Evaluation. ACM Transactions on Information Systems, 41(3), Article 75. https://doi.org/10.1145/3569930
-
[27]
John and Sanjay Srivastava
Oliver P. John and Sanjay Srivastava. 1999. The Big Five Trait Taxonomy: History, Measurement, and Theoretical Perspectives. In Handbook of Personality: Theory and Research, 2nd ed. Guilford Press. https://pages.uoregon.edu/sanjay/pubs/ bigfive.pdf
1999
-
[28]
Costa Jr
Paul T. Costa Jr. and Robert R. McCrae. 1992. Revised NEO Personality Inventory (NEO PI-R) and NEO Five-Factor Inventory (NEO-FFI): Professional Manual. Psychological Assessment Resources
1992
- [29]
- [30]
-
[31]
Yehuda Koren. 2009. Collaborative Filtering with Temporal Dynamics. InProceed- ings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, New York, NY, USA, 447–456. doi:10.1145/1557019.1557072
-
[32]
Michal Kosinski, David Stillwell, and Thore Graepel. 2013. Private Traits and Attributes Are Predictable from Digital Records of Human Behavior.Proceedings of the National Academy of Sciences110, 15 (2013), 5802–5805. doi:10.1073/pnas. 1218772110
-
[33]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles. ACM, New York, NY, USA, 611–626. doi:10.1145/3600006.3613165
-
[34]
Jianghao Lin, Xinyi Dai, Yunjia Xi, Weiwen Liu, Bo Chen, Hao Zhang, Yong Liu, Chuhan Wu, Xiangyang Li, Chenxu Zhu, Huifeng Guo, Yong Yu, Ruiming Tang, and Weinan Zhang. 2024. How Can Recommender Systems Benefit from Large Language Models: A Survey. ACM Transactions on Information Systems. https://arxiv.org/abs/2306.05817
-
[35]
Pasquale Lops, Marco de Gemmis, and Giovanni Semeraro. 2011. Content-Based Recommender Systems: State of the Art and Trends. In Recommender Systems Handbook. Springer. https://doi.org/10.1007/978-0-387-85820-3_3
-
[36]
Sichun Luo, Bowei He, Haohan Zhao, Wei Shao, Yanlin Qi, Yinya Huang, Aojun Zhou, Yuxuan Yao, Zongpeng Li, Yuanzhang Xiao, Mingjie Zhan, and Linqi Song
-
[37]
RecRanker: Instruction Tuning Large Language Model as Ranker for Top-k Recommendation. arXiv:2312.16018. https://arxiv.org/abs/2312.16018
- [38]
-
[39]
Matz, Michal Kosinski, Gideon Nave, and David J
Sandra C. Matz, Michal Kosinski, Gideon Nave, and David J. Stillwell. 2017. Psychological Targeting as an Effective Approach to Digital Mass Persuasion. Proceedings of the National Academy of Sciences114, 48 (2017), 12714–12719. doi:10.1073/pnas.1710966114
-
[40]
McAuley Lab. 2023. Amazon Reviews 2023. Public dataset. https://amazon- reviews-2023.github.io/main.html
2023
- [41]
-
[42]
Zhen Qin, Rolf Jagerman, Kai Hui, Honglei Zhuang, Junru Wu, Le Yan, Jiaming Shen, Tianqi Liu, Jialu Liu, Donald Metzler, Xuanhui Wang, and Michael Ben- dersky. 2024. Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting. NAACL 2024. https://arxiv.org/abs/2306.17563
-
[43]
Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme
-
[44]
BPR: Bayesian Personalized Ranking from Implicit Feedback
BPR: Bayesian Personalized Ranking from Implicit Feedback. UAI 2009. https://arxiv.org/abs/1205.2618
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[45]
Paul Resnick, Neophytos Iacovou, Mitesh Suchak, Peter Bergstrom, and John Riedl. 1994. GroupLens: An Open Architecture for Collaborative Filtering of Netnews. CSCW 1994. https://doi.org/10.1145/192844.192905
-
[46]
Guy Shani and Asela Gunawardana. 2011. Evaluating Recommendation Systems. In Recommender Systems Handbook. Springer. https://doi.org/10.1007/978-0- 387-85820-3_8
- [47]
-
[48]
Marko Tkalcic and Li Chen. 2015. Personality and Recommender Systems. In Recommender Systems Handbook, 2nd ed. Springer. https://doi.org/10.1007/978- 1-4899-7637-6_25
- [49]
-
[50]
Yelp. 2026. Yelp Open Dataset. Public dataset. https://business.yelp.com/data/ resources/open-dataset/
2026
-
[51]
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung- Gon Chun. 2022. Orca: A Distributed Serving System for Transformer-Based Generative Models. In16th USENIX Symposium on Operating Systems Design and Implementation. USENIX Association, Berkeley, CA, USA, 521–538. https: //www.usenix.org/conference/osdi22/presentation/yu
2022
-
[52]
Zihuai Zhao, Wenqi Fan, Jiatong Li, Yunqing Liu, Xiaowei Mei, Yiqi Wang, Zhen Wen, Fei Wang, Xiangyu Zhao, Jiliang Tang, and Qing Li. 2024. Recommender Systems in the Era of Large Language Models. IEEE Transactions on Knowledge and Data Engineering. https://arxiv.org/abs/2307.02046
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.