I Hear, Therefore I Trust: A Socio-Technical Investigation of Humans as Synthetic Speech Detectors
Pith reviewed 2026-06-29 10:14 UTC · model grok-4.3
The pith
Humans detected fully synthetic speech below chance levels while quality ratings revealed implicit discrimination by utterance type.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
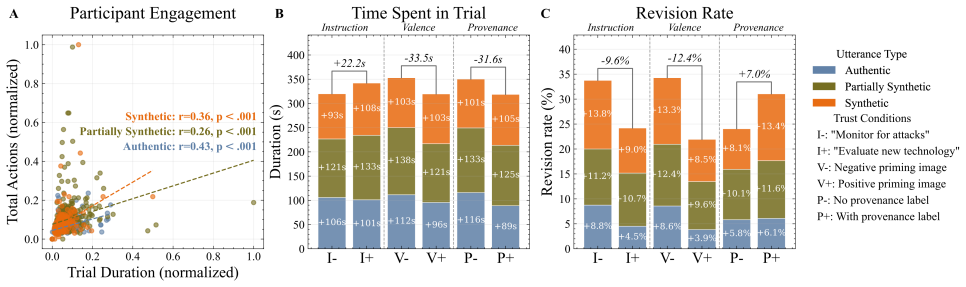
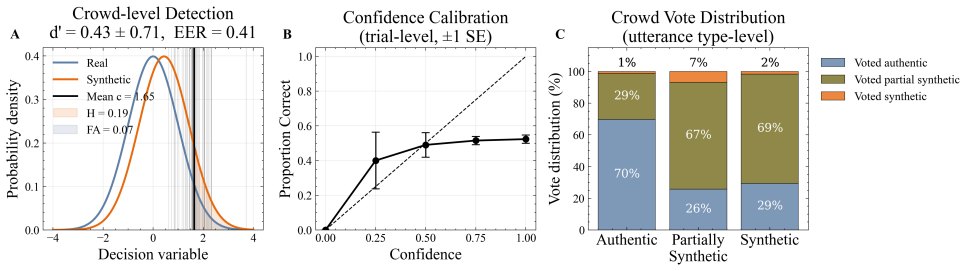
In a localization task with 47 participants, utterance class determined both detection accuracy and perceptual quality ratings; manipulated trust cues affected motivation but produced no main effects on performance. Fully synthetic speech was identified at below-chance levels, while quality ratings for mechanicalness, expressiveness, and related dimensions tracked the authentic, fully synthetic, and partially synthetic categories, indicating implicit discrimination where explicit detection failed.
What carries the argument
The localization task in which participants mark suspected synthetic segments under three manipulated trust cues (instructional framing, affective priming, and provenance labeling).
If this is right
- Human oversight cannot be relied upon to catch fully synthetic speech at usable rates.
- Perceptual quality ratings may serve as indirect signals of synthetic content even when listeners cannot name the source.
- Trust cues influence willingness to report suspicion but not the accuracy of that suspicion.
- Design of detection systems should incorporate implicit perceptual measures rather than depending solely on explicit judgments.
- Partially synthetic utterances may be easier to flag than fully synthetic ones under the same conditions.
Where Pith is reading between the lines
- Training listeners on quality-rating dimensions could improve downstream detection performance without changing overt task instructions.
- Systems that combine human quality ratings with automatic classifiers might achieve better coverage than either alone.
- Real-world deployment of voice interfaces may need provenance indicators that go beyond simple labels if trust cues show no effect in controlled settings.
- The gap between implicit and explicit detection points to a need for experiments that measure reaction times or eye movements during listening.
Load-bearing premise
The controlled localization task with its specific manipulations accurately represents how humans encounter synthetic speech outside the experiment.
What would settle it
A field study in which participants encounter synthetic speech in ordinary conversations or media and show detection rates at or above chance.
Figures


read the original abstract
Automatic deepfake detection has received considerable research attention, yet the socio-technical environment in which humans actually encounter synthetic speech remains poorly understood. We investigate voice deepfake detection as a perceptual and contextual process, presenting a localization task in which 47 participants marked suspected synthetic segments across authentic, fully synthetic, and partially synthetic utterances under three manipulated trust cues: instructional framing, affective priming, and provenance labeling. Participants provided quality ratings on mechanicalness, expressiveness, intelligibility, clarity, calmness, and confidence of evaluation. Utterance class was the primary determinant of detection accuracy and perceptual quality; trust cues produced no main effects but motivated detection behavior. Fully synthetic speech was detected at below-chance levels. Quality ratings tracked utterance type, indicating implicit discrimination where overt detection failed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports an empirical user study with 47 participants performing a localization task to identify suspected synthetic segments in authentic, fully synthetic, and partially synthetic utterances. Three trust cues (instructional framing, affective priming, provenance labeling) were manipulated. Participants also provided perceptual quality ratings on mechanicalness, expressiveness, intelligibility, clarity, calmness, and evaluation confidence. The central claims are that utterance class is the primary driver of both overt detection accuracy and quality ratings, trust cues produce no main effects on detection but do motivate behavior, fully synthetic speech is detected at below-chance levels, and quality ratings reveal implicit discrimination even when overt localization fails.
Significance. If the empirical results hold after proper statistical reporting and controls, the work contributes to socio-technical research on deepfake speech by documenting human limitations in explicit detection alongside evidence of implicit sensitivity via quality judgments. This could inform the design of warning systems, provenance interfaces, and training for human detectors, highlighting that contextual cues may matter more for behavior than for accuracy.
major comments (2)
- [Abstract / Methods] Abstract and Methods: The claims of main effects, below-chance detection of fully synthetic speech, and implicit discrimination via quality ratings are presented without any statistical tests, exact definition of the chance baseline, per-condition hit/false-alarm rates, participant demographics, or exclusion criteria. These omissions are load-bearing because they prevent evaluation of whether the data actually support the reported effects and the below-chance result.
- [Methods] Methods: The controlled localization task with manipulated instructional framing, affective priming, and provenance labeling is presented as modeling the socio-technical environment, yet no validation or discussion of ecological validity is supplied to justify that the artificial task and cue manipulations generalize to naturalistic encounters with synthetic speech.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly stated the scoring rule used for 'chance' performance and the primary statistical approach.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address the major comments below, agreeing to incorporate additional statistical details and a discussion of ecological validity in the revised version.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods: The claims of main effects, below-chance detection of fully synthetic speech, and implicit discrimination via quality ratings are presented without any statistical tests, exact definition of the chance baseline, per-condition hit/false-alarm rates, participant demographics, or exclusion criteria. These omissions are load-bearing because they prevent evaluation of whether the data actually support the reported effects and the below-chance result.
Authors: We agree with the referee that the abstract and methods sections would be strengthened by including the requested statistical information. In the revision, we will add the results of the appropriate statistical tests supporting the main effects and the below-chance detection, provide an exact definition of the chance baseline for the localization task, report per-condition hit and false-alarm rates, include participant demographics, and specify exclusion criteria. These additions will clarify how the data support the claims regarding utterance class as the primary driver and implicit discrimination via quality ratings. revision: yes
-
Referee: [Methods] Methods: The controlled localization task with manipulated instructional framing, affective priming, and provenance labeling is presented as modeling the socio-technical environment, yet no validation or discussion of ecological validity is supplied to justify that the artificial task and cue manipulations generalize to naturalistic encounters with synthetic speech.
Authors: Regarding ecological validity, we recognize that the manuscript would benefit from explicit discussion of this issue. Although the task is designed as a controlled experiment to examine the effects of trust cues in a socio-technical context, we will add a dedicated paragraph in the Discussion section addressing the limitations of the laboratory setting and the extent to which the findings may generalize to naturalistic encounters with synthetic speech. We will also elaborate on how the cue manipulations are intended to model real-world trust signals. revision: yes
Circularity Check
Empirical user study with no derivation chain present
full rationale
The paper reports results from a controlled localization task with 47 human participants, including detection rates, quality ratings across utterance types, and effects of manipulated trust cues. No equations, parameters, derivations, or predictive models are described in the abstract or referenced full text. All claims reduce directly to observed experimental outcomes rather than any self-referential construction, fitted input, or self-citation chain. This matches the default case of a self-contained empirical report with no load-bearing mathematical steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Participant responses in a localization task can be aggregated to measure detection accuracy and quality perception under controlled cue manipulations.
Reference graph
Works this paper leans on
-
[1]
I Hear, Therefore I Trust: A Socio-Technical Investigation of Humans as Synthetic Speech Detectors
Introduction Generative artificial intelligence (genAI), particularly conver- sational agents, extends a socio-cultural transition of epistemic authority and information sourcing, from traditional news out- lets, to social media platforms and now to personalized chat- bots [1, 2]. Within this shifting landscape, trust becomes a currency of the attention e...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Over time, its def- inition has expanded to encompass generative techniques across audio, text, images, videos, and multimodal media
Socio-technical background The term ”deepfake” was coined in the mid-2010s to describe non-consensual impersonating pornographic synthetic media produced with deep learning techniques [24]. Over time, its def- inition has expanded to encompass generative techniques across audio, text, images, videos, and multimodal media. Benefi- cial applications such as...
2024
-
[3]
Dataset The LlamaPartialSpoof [38] is a recent dataset that contains both fully synthetic and partially spoofed speech
Methods 3.1. Dataset The LlamaPartialSpoof [38] is a recent dataset that contains both fully synthetic and partially spoofed speech. It contains English utterances from 40 LibriTTS [39] speakers, with syn- thetic counterparts generated using five open-source models (LJ JETS8, YourTTS9, XTTS V2 10, GPT-SoVITS11, CosyV oice12) plus one commercial service (E...
2025
-
[4]
Results Each utterance was processed by aligning participant marker placements to ground-truth synthetic regions via sliding win- dow scoring (see Figure 1), producing window-level metrics from which an overall verdict per utterance was derived and inter-participant agreement calculated. The results reveal a crit- ical tension in the socio-technical trust...
-
[5]
Discussion Utterance type emerged as the dominant determinant of detec- tion, suggesting that the environmental dimension of trust may fall to a secondary role in real-time detection tasks. This pattern may reflect a mismatch in listener expectations: participants en- tered the task expecting robotic or background artifacts [6, 18], yet encountered realis...
-
[6]
Limitations and future directions Exploring context-driven human decision-making factors is a multidimensional problem. If automated detection studies test the strength of countermeasures [7, 16, 17, 22, 29], with human listener studies exploring themes of detection [6, 7, 18, 46], our study tackled the environment dimension by integrating vari- ables tha...
-
[7]
Conclusion This study challenges the ”one solution fits all” approach to synthetic speech detection by investigating (partial) voice deep- fake detection as asocio-technical process shaped by trust. Al- though participants expressed confidence in their judgments, they were generally unable to detect synthetic speech, with detection performance improving o...
-
[8]
349605, project ”SPEECH- FAKES”)
Acknowledgments This work was carried out as part of the V oCS (V oice in Com- munication Sciences) doctoral network, funded by the Euro- pean Union’s Horizon Europe Framework programme under Grant Agreement No 101168998 and partially supported by the Academy of Finland (Decision No. 349605, project ”SPEECH- FAKES”). This study was submitted to and receiv...
-
[9]
Public intellectuals on new platforms: con- structing critical authority in a digital media culture,
M. B. Johansen, “Public intellectuals on new platforms: con- structing critical authority in a digital media culture,” inRethink- ing cultural criticism: New voices in the digital age. Springer, 2020, pp. 17–42
2020
-
[10]
Large language models are echo chambers,
J. Nehring, A. Gabryszak, P. J ¨urgens, A. Burchardt, S. Schaffer, M. Spielkamp, and B. Stark, “Large language models are echo chambers,” inProceedings of the 2024 joint international confer- ence on computational linguistics, language resources and evalu- ation (lrec-coling 2024), 2024, pp. 10 117–10 123
2024
-
[11]
Attention economy theory,
J. Myers, “Attention economy theory,” inMedia Ecology for the 21st Century: Theories of Culture, Communications, and Con- sciousness. Springer, 2025, pp. 101–109
2025
-
[12]
Synthetic media detection, the wheel, and the bur- den of proof,
K. R. Harris, “Synthetic media detection, the wheel, and the bur- den of proof,”Philosophy & Technology, vol. 37, no. 4, p. 131, 2024
2024
-
[13]
Deepfakes and trust in technology,
O. Laas, “Deepfakes and trust in technology,”Synthese, vol. 202, no. 5, p. 132, 2023
2023
-
[14]
” better be computer or i’m dumb
K. Warren, T. Tucker, A. Crowder, D. Olszewski, A. Lu, C. Fedele, M. Pasternak, S. Layton, K. Butler, C. Gateset al., “” better be computer or i’m dumb”: A large-scale evaluation of humans as audio deepfake detectors,” inProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, 2024, pp. 2696–2710
2024
-
[15]
Partial fake speech attacks in the real world using deepfake audio,
A. Alali and G. Theodorakopoulos, “Partial fake speech attacks in the real world using deepfake audio,”Journal of Cybersecurity and Privacy, vol. 5, no. 1, p. 6, 2025
2025
-
[16]
Can you tell it’s ai? human perception of synthetic voices in vishing scenarios,
Z. H. Bhatti, B. Ahtisham, S. Tausif, N. George, M. Javedet al., “Can you tell it’s ai? human perception of synthetic voices in vishing scenarios,”arXiv preprint arXiv:2602.20061, 2026
-
[17]
When machines speak with feeling: Investi- gating emotional prosody, authenticity, and trust in ai vs. human voices,
G. Fan and D. Liu, “When machines speak with feeling: Investi- gating emotional prosody, authenticity, and trust in ai vs. human voices,” inProceedings of the Annual Meeting of the Cognitive Science Society, vol. 47, 2025
2025
-
[18]
Spoofing and countermeasures for speaker verification: A sur- vey,
Z. Wu, N. Evans, T. Kinnunen, J. Yamagishi, F. Alegre, and H. Li, “Spoofing and countermeasures for speaker verification: A sur- vey,”speech communication, vol. 66, pp. 130–153, 2015
2015
-
[19]
Why do people spread false information online? the effects of message and viewer characteristics on self-reported likelihood of sharing social media disinformation,
T. Buchanan, “Why do people spread false information online? the effects of message and viewer characteristics on self-reported likelihood of sharing social media disinformation,”Plos one, vol. 15, no. 10, p. e0239666, 2020
2020
-
[20]
Ai or your lying eyes: Some shortcomings of arti- ficially intelligent deepfake detectors,
K. R. Harris, “Ai or your lying eyes: Some shortcomings of arti- ficially intelligent deepfake detectors,”Philosophy & Technology, vol. 37, no. 1, p. 7, 2024
2024
-
[21]
How we trust, perceive, and learn from virtual humans: The influence of voice quality,
E. K. Chiou, N. L. Schroeder, and S. D. Craig, “How we trust, perceive, and learn from virtual humans: The influence of voice quality,”Computers & Education, vol. 146, p. 103756, 2020
2020
-
[22]
” human, all too human
K. M. Scott, S. Ashby, and J. Hanna, “” human, all too human”: Noaa weather radio and the emotional impact of synthetic voices,” inProceedings of the 2020 CHI conference on human factors in computing systems, 2020, pp. 1–9
2020
-
[23]
Yourtts: Towards zero-shot multi-speaker tts and zero-shot voice conversion for everyone,
E. Casanova, J. Weber, C. D. Shulby, A. C. Junior, E. G ¨olge, and M. A. Ponti, “Yourtts: Towards zero-shot multi-speaker tts and zero-shot voice conversion for everyone,” inInternational confer- ence on machine learning. PMLR, 2022, pp. 2709–2720
2022
-
[24]
Asvspoof 2021: Towards spoofed and deepfake speech detection in the wild,
X. Liu, X. Wang, M. Sahidullah, J. Patino, H. Delgado, T. Kin- nunen, M. Todisco, J. Yamagishi, N. Evans, A. Nautschet al., “Asvspoof 2021: Towards spoofed and deepfake speech detection in the wild,”IEEE/ACM Transactions on Audio, Speech, and Lan- guage Processing, vol. 31, pp. 2507–2522, 2023
2021
-
[25]
X. Wang, H. Delgado, H. Tak, J.-w. Jung, H.-j. Shim, M. Todisco, I. Kukanov, X. Liu, M. Sahidullah, T. Kinnunenet al., “Asvspoof 5: Crowdsourced speech data, deepfakes, and adversarial attacks at scale,”arXiv preprint arXiv:2408.08739, 2024
-
[26]
Detect- ing the undetectable: Human judgments and the challenge of syn- thetic voices,
S. Amirkhani, G. Stevens, M. Shajalal, and A. Boden, “Detect- ing the undetectable: Human judgments and the challenge of syn- thetic voices,” inProceedings of the 12th International Confer- ence on Communities & Technologies (C&T 2025). European Society for Socially Embedded Technologies (EUSSET), 2025
2025
-
[27]
Human trust in artificial intelli- gence: Review of empirical research,
E. Glikson and A. W. Woolley, “Human trust in artificial intelli- gence: Review of empirical research,”Academy of management annals, vol. 14, no. 2, pp. 627–660, 2020
2020
-
[28]
A review of trust in artificial intelligence: Challenges, vulnerabilities and future directions,
S. Lockey, N. Gillespie, D. Holm, and I. A. Someh, “A review of trust in artificial intelligence: Challenges, vulnerabilities and future directions,” 2021
2021
-
[29]
Deepfakes: Deceptions, mitigations, and opportuni- ties,
M. Mustak, J. Salminen, M. M ¨antym¨aki, A. Rahman, and Y . K. Dwivedi, “Deepfakes: Deceptions, mitigations, and opportuni- ties,”Journal of Business Research, vol. 154, p. 113368, 2023
2023
-
[30]
Where are we in audio deep- fake detection? a systematic analysis over generative and detec- tion models,
X. Li, P.-Y . Chen, and W. Wei, “Where are we in audio deep- fake detection? a systematic analysis over generative and detec- tion models,”ACM Transactions on Internet Technology, 2025
2025
-
[31]
Human performance in deepfake detection: a systematic review,
K. Somoray, D. J. Miller, and M. Holmes, “Human performance in deepfake detection: a systematic review,”Human Behavior and Emerging Technologies, vol. 2025, no. 1, p. 1833228, 2025
2025
-
[32]
Ctrl-alt-del: Gamergate as a precursor to the rise of the alt-right,
K. M. Bezio, “Ctrl-alt-del: Gamergate as a precursor to the rise of the alt-right,”Leadership, vol. 14, no. 5, pp. 556–566, 2018
2018
-
[33]
Key challenges in using automatic dubbing to trans- late educational youtube videos,
R. Ba ˜nos, “Key challenges in using automatic dubbing to trans- late educational youtube videos,”Linguistica Antverpiensia, New Series–Themes in Translation Studies, vol. 22, 2023
2023
-
[34]
Grooming an ideal chatbot by training the algorithm: Exploring the exploitation of replika users’ immaterial labor,
S. Pan, L. Fortunati, and A. Edwards, “Grooming an ideal chatbot by training the algorithm: Exploring the exploitation of replika users’ immaterial labor,”New Media & Society, vol. 27, no. 10, pp. 5489–5507, 2025
2025
-
[35]
Sycophantic ai decreases prosocial intentions and promotes de- pendence,
M. Cheng, C. Lee, P. Khadpe, S. Yu, D. Han, and D. Jurafsky, “Sycophantic ai decreases prosocial intentions and promotes de- pendence,”arXiv preprint arXiv:2510.01395, 2025
-
[36]
Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 laying down harmonised rules on artificial intelligence (Artificial Intelligence Act),
“Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 laying down harmonised rules on artificial intelligence (Artificial Intelligence Act),” 2024. [Online]. Available: https://eur-lex.europa.eu/eli/reg/2024/1689/oj/eng
2024
-
[37]
Battling voice spoofing: a review, comparative analysis, and generalizability evaluation of state-of-the-art voice spoofing counter measures,
A. Khan, K. M. Malik, J. Ryan, and M. Saravanan, “Battling voice spoofing: a review, comparative analysis, and generalizability evaluation of state-of-the-art voice spoofing counter measures,” Artificial Intelligence Review, vol. 56, no. Suppl 1, pp. 513–566, 2023
2023
-
[38]
It’s not just “press record
L. Krikheli, S. El-Wahsh, and R. Cave, “It’s not just “press record”: a viewpoint for providing ethical voice banking,” Evidence-Based Communication Assessment and Intervention, pp. 1–10, 2026
2026
-
[39]
Can emotion fool anti-spoofing?
A. Mahapatra, I. R. Ulgen, A. R. Naini, C. Busso, and B. Sisman, “Can emotion fool anti-spoofing?”arXiv preprint arXiv:2505.23962, 2025
-
[40]
Every breath you don’t take: Deep- fake speech detection using breath,
S. Layton, T. De Andrade, D. Olszewski, K. Warren, C. Gates, K. Butler, and P. Traynor, “Every breath you don’t take: Deep- fake speech detection using breath,”Digital Threats: Research and Practice, vol. 6, no. 3, pp. 1–18, 2025
2025
-
[41]
What is a digital persona?
D. De Kerckhove and C. M. De Almeida, “What is a digital persona?”Technoetic Arts: A Journal of Speculative Research, vol. 11, no. 3, pp. 277–287, 2013
2013
-
[42]
Rating naturalness in speech synthesis: The effect of style and expectation,
R. Dall, J. Yamagishi, and S. King, “Rating naturalness in speech synthesis: The effect of style and expectation,” inSpeech Prosody 2014, 2014
2014
-
[43]
The role of affect in decision making,
G. Loewenstein, J. S. Lerneret al., “The role of affect in decision making,”Handbook of affective science, vol. 619, no. 642, p. 3, 2003
2003
-
[44]
Emotions don’t lie: An audio-visual deepfake detection method using affective cues,
T. Mittal, U. Bhattacharya, R. Chandra, A. Bera, and D. Manocha, “Emotions don’t lie: An audio-visual deepfake detection method using affective cues,” inProceedings of the 28th ACM interna- tional conference on multimedia, 2020, pp. 2823–2832
2020
-
[45]
La- beling synthetic content: User perceptions of label designs for ai-generated content on social media,
D. Gamage, D. Sewwandi, M. Zhang, and A. K. Bandara, “La- beling synthetic content: User perceptions of label designs for ai-generated content on social media,” inProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, 2025, pp. 1–29
2025
-
[46]
Llama- partialspoof: An llm-driven fake speech dataset simulating dis- information generation,
H.-T. Luong, H. Li, L. Zhang, K. A. Lee, and E. S. Chng, “Llama- partialspoof: An llm-driven fake speech dataset simulating dis- information generation,” inICASSP 2025-2025 IEEE Interna- tional Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[47]
LibriTTS: A Corpus Derived from LibriSpeech for Text-to-Speech
H. Zen, V . Dang, R. Clark, Y . Zhang, R. J. Weiss, Y . Jia, Z. Chen, and Y . Wu, “Libritts: A corpus derived from librispeech for text- to-speech,”arXiv preprint arXiv:1904.02882, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[48]
Understanding fatigue and its im- pact in crowdsourcing,
Y . Zhang, X. Ding, and N. Gu, “Understanding fatigue and its im- pact in crowdsourcing,” in2018 IEEE 22nd International Con- ference on Computer Supported Cooperative Work in Design ((CSCWD)). IEEE, 2018, pp. 57–62
2018
-
[49]
A. Mitchell, T. Oberman, F. Aletta, M. Erfanian, M. Kach- licka, M. Lionello, and J. Kang, “The international soundscape database: An integrated multimedia database of urban soundscape surveys–questionnaires with acoustical and contextual informa- tion,”Online. URL: https://www. zenodo. org/record/5914715#. YnwwoGDP00Q, 2021
-
[50]
Pre- senting and processing information in background noise: A com- bined speaker–listener perspective,
A. Bockstael, L. Samyn, P. Corthals, and D. Botteldooren, “Pre- senting and processing information in background noise: A com- bined speaker–listener perspective,”The Journal of the Acoustical Society of America, vol. 143, no. 1, pp. 210–218, 2018
2018
-
[51]
Introducing the open af- fective standardized image set (oasis),
B. Kurdi, S. Lozano, and M. R. Banaji, “Introducing the open af- fective standardized image set (oasis),”Behavior research meth- ods, vol. 49, no. 2, pp. 457–470, 2017
2017
-
[52]
Decisional carry- over effects in interval timing: Evidence of a generalized response bias,
J. J. Wehrman, J. Wearden, and P. Sowman, “Decisional carry- over effects in interval timing: Evidence of a generalized response bias,”Attention, Perception, & Psychophysics, vol. 82, no. 4, pp. 2147–2164, 2020
2020
-
[53]
Good Practices for Evaluation of Synthesized Speech,
E. Cooper, S. L. Maguer, E. Klabbers, and J. Yamagishi, “Good practices for evaluation of synthesized speech,”arXiv preprint arXiv:2503.03250, 2025
-
[54]
Human perception of audio deepfakes: the role of language and speaking style,
E. San Segundo, A. L ´opez-Jare˜no, X. Wang, and J. Yamagishi, “Human perception of audio deepfakes: the role of language and speaking style,”Available at SSRN 5954496, 2025
2025
-
[55]
The intelligibility benefits of modern computer-synthesized speech for normal-hearing and hearing- impaired listeners in non-ideal listening conditions,
Y . Ma and Y . Tang, “The intelligibility benefits of modern computer-synthesized speech for normal-hearing and hearing- impaired listeners in non-ideal listening conditions,”Journal of Otorhinolaryngology, Hearing and Balance Medicine, vol. 5, no. 1, p. 5, 2024
2024
-
[56]
Automatic speaker verification on compressed au- dio,
O. Sokol, H. Naumenko, V . Derkach, V . Kuznetsov, D. Progonov, and V . Husiev, “Automatic speaker verification on compressed au- dio,” in2022 12th International Conference on Dependable Sys- tems, Services and Technologies (DESSERT). IEEE, 2022, pp. 1–7
2022
-
[57]
Trust in artifi- cial voices: A
I. Torre, J. Goslin, L. White, and D. Zanatto, “Trust in artifi- cial voices: A ”congruency effect” of first impressions and be- havioural experience,” 04 2018
2018
-
[58]
”human, all too human
K. Scott, S. Ashby, and J. Hanna, “”human, all too human”: Noaa weather radio and the emotional impact of synthetic voices,” 04 2020, pp. 1–9
2020
-
[59]
Unmasking illusions: Understanding human perception of au- diovisual deepfakes,
A. Hashmi, S. A. Shahzad, C.-W. Lin, Y . Tsao, and H.-M. Wang, “Unmasking illusions: Understanding human perception of au- diovisual deepfakes,”arXiv preprint arXiv:2405.04097, 2024
-
[60]
The perils of automatic- ity,
J. Toner, B. G. Montero, and A. Moran, “The perils of automatic- ity,”Review of General Psychology, vol. 19, no. 4, pp. 431–442, 2015
2015
-
[61]
The effects of task difficulty and multitasking on performance,
R. F. Adler and R. Benbunan-Fich, “The effects of task difficulty and multitasking on performance,”Interacting with Computers, vol. 27, no. 4, pp. 430–439, 2015
2015
-
[62]
Quality control in crowd- sourcing systems: Issues and directions,
M. Allahbakhsh, B. Benatallah, A. Ignjatovic, H. R. Motahari- Nezhad, E. Bertino, and S. Dustdar, “Quality control in crowd- sourcing systems: Issues and directions,”IEEE Internet Comput- ing, vol. 17, no. 2, pp. 76–81, 2013
2013
-
[63]
Something ai should tell you–the case for labelling synthetic content,
S. A. Fisher, “Something ai should tell you–the case for labelling synthetic content,”Journal of Applied Philosophy, vol. 42, no. 1, pp. 272–286, 2025
2025
-
[64]
Statsmodels: econometric and sta- tistical modeling with python
S. Seabold, J. Perktoldet al., “Statsmodels: econometric and sta- tistical modeling with python.”scipy, vol. 7, no. 1, pp. 92–96, 2010
2010
-
[65]
Trust in artifi- cial voices: A
I. Torre, J. Goslin, L. White, and D. Zanatto, “Trust in artifi- cial voices: A” congruency effect” of first impressions and be- havioural experience,” inProceedings of the technology, mind, and society, 2018, pp. 1–6
2018
-
[66]
How do voice acoustics affect the perceived trustworthiness of a speaker? a systematic review,
C. Maltezou-Papastylianou, R. Scherer, and S. Paulmann, “How do voice acoustics affect the perceived trustworthiness of a speaker? a systematic review,”Frontiers in Psychology, vol. 16, p. 1495456, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.