Convergence of empirical subgradients for optimal transport-based objectives
Pith reviewed 2026-06-29 11:16 UTC · model grok-4.3
The pith
Sampled optimal transport objectives have subdifferentials that converge graphically to the population subdifferential.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We study parameterized objectives defined by sampled transport costs and prove graphical convergence of their subdifferentials to the subdifferential of the population objective. In particular, this ensures that standard subgradient methods consistently approach stationary points of the population-level problem. The analysis is illustrated in risk-averse optimization, fairness-constrained learning, and sliced Wasserstein problems, with smooth parameterizations providing a stable interface between sampling and optimization.
What carries the argument
Graphical convergence of subdifferentials between empirical and population optimal transport-based objectives
If this is right
- Subgradient methods applied to the sampled problem approach stationary points of the population objective.
- Smooth parameterizations ensure stable derivatives in the large-sample limit.
- The convergence result applies directly to risk-averse optimization, fairness-constrained learning, and sliced Wasserstein problems.
- Nonsmooth costs and models can produce unstable derivatives as sample size increases.
Where Pith is reading between the lines
- Empirical optimal transport losses can be treated as reliable proxies for population-level optimization when parameters remain smooth.
- The same graphical-convergence approach might apply to other sampling-based losses if analogous technical conditions hold.
- Training pipelines using transport costs may benefit from enforcing smoothness on the model class to avoid limit instability.
Load-bearing premise
Smooth parameterizations are needed to translate statistical consistency into stable optimization behavior without unstable derivatives in the large-sample limit.
What would settle it
An explicit example of a smooth parameterization and transport cost where the empirical subdifferential fails to converge graphically to the population subdifferential, or where subgradient iterates on growing samples diverge from the population stationary points.
Figures

read the original abstract
Optimal transport is widely used to learn distributions, enforce distributional constraints, and model uncertainty. In applications, transport losses are often computed from samples through tractable representations, such as one-dimensional sorting formulas or sliced Wasserstein costs, making them practical components in training pipelines. We study parameterized objectives defined by sampled transport costs and prove graphical convergence of their subdifferentials to the subdifferential of the population objective. In particular, this ensures that standard subgradient methods consistently approach stationary points of the population-level problem. We illustrate the results in several settings, including risk-averse optimization, fairness-constrained learning, and sliced Wasserstein problems. Our analysis highlights that smooth parameterizations provide a favorable interface between statistical consistency and optimization. By contrast, transport objectives with nonsmooth costs and models may exhibit unstable derivatives in the large-sample limit.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proves graphical convergence of the subdifferentials of empirical optimal transport (OT) objectives—defined via sampled transport costs such as one-dimensional sorting or sliced Wasserstein—to the subdifferential of the corresponding population objective. This convergence is shown to ensure that standard subgradient methods applied to the empirical problems consistently approach stationary points of the population problem. The results are illustrated in risk-averse optimization, fairness-constrained learning, and sliced Wasserstein settings, with emphasis on the favorable role of smooth parameterizations versus potential instability in nonsmooth cases.
Significance. If the graphical convergence result holds under the stated conditions, the work supplies a useful theoretical bridge between statistical consistency of empirical OT losses and the reliability of first-order optimization methods. This is relevant for machine learning pipelines that incorporate transport-based objectives, and the explicit contrast between smooth and nonsmooth regimes offers practical guidance on when subgradient consistency can be expected.
major comments (2)
- [Main theorem / assumptions paragraph] The central graphical convergence claim (abstract and main theorem) relies on technical conditions on the transport cost and parameterization class that are invoked but whose precise statement and necessity are not fully detailed in the provided abstract; the main result section should explicitly list all assumptions (e.g., on smoothness, compactness, or measurability) and verify they are minimal for the conclusion.
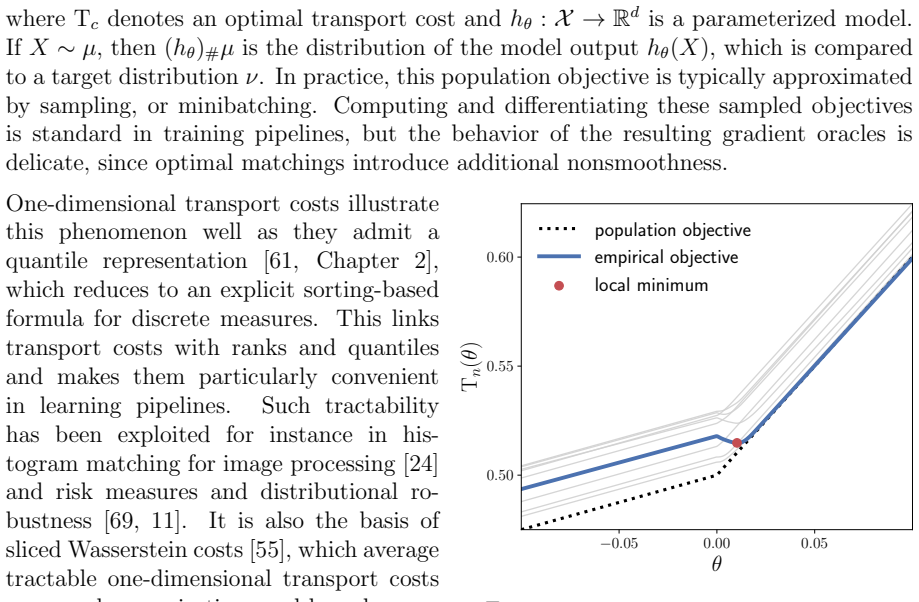
- [Section on illustrations] The illustrations (risk-averse optimization, fairness, sliced Wasserstein) are presented as supporting examples, but without quantitative verification that the empirical subdifferentials indeed converge in the reported regimes, it is unclear whether the examples confirm the rate or only the qualitative behavior; a numerical check or explicit error bound would strengthen the claim.
minor comments (2)
- Notation for the empirical versus population subdifferentials should be introduced once and used consistently; occasional shifts between ∂ and ∂_emp notation reduce readability.
- [Abstract / conclusion] The abstract states that nonsmooth costs 'may exhibit unstable derivatives in the large-sample limit,' but this is not accompanied by a counter-example or reference; adding a brief remark or citation would clarify the contrast.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address each major comment below and will incorporate the suggested clarifications in a revised version of the manuscript.
read point-by-point responses
-
Referee: [Main theorem / assumptions paragraph] The central graphical convergence claim (abstract and main theorem) relies on technical conditions on the transport cost and parameterization class that are invoked but whose precise statement and necessity are not fully detailed in the provided abstract; the main result section should explicitly list all assumptions (e.g., on smoothness, compactness, or measurability) and verify they are minimal for the conclusion.
Authors: We agree that the assumptions should be stated more explicitly for clarity. In the revised manuscript we will insert a dedicated 'Assumptions' paragraph immediately preceding the statement of the main graphical convergence theorem. This paragraph will enumerate all conditions on the transport cost (continuity, growth, and measurability requirements) and on the parameterization class (compactness of the parameter domain and appropriate measurability of the maps). We will also add a short remark discussing the role of each assumption in the proof and note which ones are standard versus those that are tailored to the OT setting. revision: yes
-
Referee: [Section on illustrations] The illustrations (risk-averse optimization, fairness, sliced Wasserstein) are presented as supporting examples, but without quantitative verification that the empirical subdifferentials indeed converge in the reported regimes, it is unclear whether the examples confirm the rate or only the qualitative behavior; a numerical check or explicit error bound would strengthen the claim.
Authors: The illustrations are designed to highlight qualitative distinctions between smooth and nonsmooth regimes that follow from the theory, rather than to provide rate information. We acknowledge that a quantitative check would make the examples more convincing. In the revision we will add, in the sliced Wasserstein subsection, a small numerical study that tracks the distance between empirical and population subdifferentials (or a proxy such as the norm of the difference in subgradient evaluations) across increasing sample sizes, thereby supplying concrete evidence of the convergence behavior in at least one setting. revision: partial
Circularity Check
No significant circularity
full rationale
The paper presents a mathematical proof of graphical convergence of subdifferentials for empirical OT-based objectives to the population subdifferential. The derivation relies on standard variational analysis tools and assumptions on smooth parameterizations, without reducing any central claim to a fitted parameter, self-referential definition, or load-bearing self-citation chain. The result is framed as an independent convergence theorem that applies to the stated regimes (risk-averse optimization, fairness, sliced Wasserstein) and explicitly contrasts with nonsmooth cases, remaining self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard properties of subdifferentials and graphical convergence from variational analysis
Reference graph
Works this paper leans on
-
[1]
Aliprantis and K
C. Aliprantis and K. Border , Infinite Dimensional Analysis , Springer Berlin, Heidelberg, 2006. 32
2006
-
[2]
Ambrosio, N
L. Ambrosio, N. Gigli, and G. Savar ´e, Gradient flows: in metric spaces and in the space of probability measures , Springer, 2005
2005
-
[3]
Arjovsky, S
M. Arjovsky, S. Chintala, and L. Bottou, Wasserstein generative adversarial networks, in International conference on machine learning, Pmlr, 2017, pp. 214–223
2017
-
[4]
Artstein and R
Z. Artstein and R. A. Vitale, A strong law of large numbers for random compact sets, The Annals of Probability, (1975), pp. 879–882
1975
-
[5]
Attouch, Convergence de fonctionnelles convexes , in Journ´ ees d’Analyse Non Lin´ eaire: Proceedings, Besan¸ con, France, June 1977, Springer, 2006, pp
H. Attouch, Convergence de fonctionnelles convexes , in Journ´ ees d’Analyse Non Lin´ eaire: Proceedings, Besan¸ con, France, June 1977, Springer, 2006, pp. 1–40
1977
-
[6]
Aubin, Graphical convergence of set-valued maps, (1987)
J.-P. Aubin, Graphical convergence of set-valued maps, (1987)
1987
-
[7]
Bena¨ım, J
M. Bena¨ım, J. Hofbauer, and S. Sorin , Perturbations of set-valued dynami- cal systems, with applications to game theory , Dynamic Games and Applications, 2 (2012), pp. 195–205
2012
-
[8]
E. Beyler and F. Bach , Convergence of deterministic and stochastic diffusion- model samplers: A simple analysis in wasserstein distance , arXiv preprint arXiv:2508.03210, (2025)
-
[9]
Billingsley, Convergence of probability measures, John Wiley & Sons, 2013
P. Billingsley, Convergence of probability measures, John Wiley & Sons, 2013
2013
-
[10]
Bolte and E
J. Bolte and E. Pauwels , Conservative set valued fields, automatic differenti- ation, stochastic gradient methods and deep learning , Mathematical Programming, 188 (2021), pp. 19–51
2021
-
[11]
R. Bonalli, B. Bonnet-Weill, and L. Pfeiffer , A characterization of law- invariant and coherent risk measures through optimal transport , arXiv preprint arXiv:2512.19157, (2025)
- [12]
-
[13]
Carlier, V
G. Carlier, V. Duval, G. Peyr´e, and B. Schmitzer, Convergence of entropic schemes for optimal transport and gradient flows , SIAM Journal on Mathematical Analysis, 49 (2017), pp. 1385–1418
2017
-
[14]
Chapel, R
L. Chapel, R. Tavenard, and S. Vaiter , Differentiable generalized sliced wasserstein plans , Advances in Neural Information Processing Systems, 38 (2026), pp. 162905–162929
2026
-
[15]
Clarke, Optimization and Nonsmooth Analysis , Classics in Applied Mathemat- ics, Society for Industrial and Applied Mathematics, 1990
F. Clarke, Optimization and Nonsmooth Analysis , Classics in Applied Mathemat- ics, Society for Industrial and Applied Mathematics, 1990
1990
-
[16]
F. H. Clarke, Generalized gradients and applications, Transactions of the American Mathematical Society, 205 (1975), pp. 247–262. 33
1975
-
[17]
Cuturi and A
M. Cuturi and A. Doucet , Fast computation of wasserstein barycenters , in In- ternational conference on machine learning, PMLR, 2014, pp. 685–693
2014
- [18]
-
[19]
Cuturi, O
M. Cuturi, O. Teboul, and J.-P. Vert, Differentiable ranking and sorting using optimal transport, in Advances in Neural Information Processing Systems, H. Wal- lach, H. Larochelle, A. Beygelzimer, F. d 'Alch´ e-Buc, E. Fox, and R. Garnett, eds., vol. 32, Curran Associates, Inc., 2019
2019
-
[20]
C ´edric, Optimal transport : old and new / C´ edric Villani , Grundlehren der mathematischen Wissenschaften, Springer, Berlin, 2009
V. C ´edric, Optimal transport : old and new / C´ edric Villani , Grundlehren der mathematischen Wissenschaften, Springer, Berlin, 2009
2009
-
[21]
J. M. Danskin , The theory of max-min and its application to weapons allocation problems, Springer Science & Business Media, 2012
2012
-
[22]
Davis, D
D. Davis, D. Drusvyatskiy, S. Kakade, and J. D. Lee, Stochastic subgradient method converges on tame functions , Foundations of Computational Mathematics, 20 (2020), pp. 119–154
2020
-
[23]
Dellacherie and P.-A
C. Dellacherie and P.-A. Meyer, Probabilities and potential, c: potential theory for discrete and continuous semigroups , vol. 151, Elsevier, 2011
2011
-
[24]
Delon, Midway image equalization, Journal of Mathematical Imaging and Vision, 21 (2004), pp
J. Delon, Midway image equalization, Journal of Mathematical Imaging and Vision, 21 (2004), pp. 119–134
2004
-
[25]
Deshpande, Z
I. Deshpande, Z. Zhang, and A. G. Schwing , Generative modeling using the sliced wasserstein distance, in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 3483–3491
2018
-
[26]
Dumont, T
T. Dumont, T. Lacombe, and F.-X. Vialard, On the existence of monge maps for the gromov–wasserstein problem, Foundations of Computational Mathematics, 25 (2025), pp. 463–510
2025
-
[27]
Durrett , Probability: Theory and Examples , Cambridge Series in Statistical and Probabilistic Mathematics, Cambridge University Press, 2010
R. Durrett , Probability: Theory and Examples , Cambridge Series in Statistical and Probabilistic Mathematics, Cambridge University Press, 2010
2010
-
[28]
Dwork, M
C. Dwork, M. Hardt, T. Pitassi, O. Reingold, and R. Zemel , Fairness through awareness, in Proceedings of the 3rd innovations in theoretical computer science conference, 2012, pp. 214–226
2012
-
[29]
Minibatch optimal transport distances; analysis and applications.arXiv preprint arXiv:2101.01792,
K. Fatras, Y. Zine, S. Majewski, R. Flamary, R. Gribonval, and N. Courty, Minibatch optimal transport distances; analysis and applications, arXiv preprint arXiv:2101.01792, (2021)
-
[30]
Feldman, S
M. Feldman, S. A. Friedler, J. Moeller, C. Scheidegger, and S. Venkatasubramanian, Certifying and removing disparate impact , in proceed- ings of the 21th ACM SIGKDD international conference on knowledge discovery and data mining, 2015, pp. 259–268. 34
2015
-
[31]
Flamary, N
R. Flamary, N. Courty, A. Gramfort, M. Z. Alaya, A. Boisbunon, S. Chambon, L. Chapel, A. Corenflos, K. Fatras, N. Fournier, L. Gau- theron, N. T. Gayraud, H. Janati, A. Rakotomamonjy, I. Redko, A. Ro- let, A. Schutz, V. Seguy, D. J. Sutherland, R. Tavenard, A. Tong, and T. Vayer, Pot: Python optimal transport , Journal of Machine Learning Research, 22 (20...
2021
-
[32]
F¨ollmer and A
H. F¨ollmer and A. Schied , Stochastic finance: an introduction in discrete time , Walter de Gruyter, 2011
2011
-
[33]
Fournier and A
N. Fournier and A. Guillin , On the rate of convergence in wasserstein distance of the empirical measure , Probability theory and related fields, 162 (2015), pp. 707– 738
2015
-
[34]
Gao and A
R. Gao and A. Kleywegt , Distributionally robust stochastic optimization with wasserstein distance, Math. Oper. Res., 48 (2023), pp. 603–655
2023
-
[35]
Ghossoub and D
M. Ghossoub and D. Saunders, On the continuity of the feasible set mapping in optimal transport, Economic Theory Bulletin, 9 (2021), pp. 113–117
2021
-
[36]
Gulrajani, F
I. Gulrajani, F. Ahmed, M. Arjovsky, V. Dumoulin, and A. C. Courville, Improved training of wasserstein gans , Advances in neural information processing systems, 30 (2017)
2017
-
[37]
Houdard, A
A. Houdard, A. Leclaire, N. Papadakis, and J. Rabin, On the gradient for- mula for learning generative models with regularized optimal transport costs , Trans- actions on Machine Learning Research, (2023)
2023
-
[38]
D. Kuhn, P. M. Esfahani, V. A. Nguyen, and S. Shafieezadeh-Abadeh , Wasserstein distributionally robust optimization: Theory and applications in ma- chine learning, in Operations research & management science in the age of analytics, Informs, 2019, pp. 130–166
2019
-
[39]
Laguel, J
Y. Laguel, J. Malick, and Z. Harchaoui, Superquantile-based learning: a direct approach using gradient-based optimization, Journal of Signal Processing Systems, 94 (2022), pp. 161–177
2022
-
[40]
and Mérigot, Q.Gluing methods for quantitative stability of optimal trans- port maps
C. Letrouit and Q. M´erigot, Gluing methods for quantitative stability of optimal transport maps, arXiv preprint arXiv:2411.04908, (2024)
-
[41]
A. B. Levy, R. Poliquin, and L. Thibault , Partial extensions of attouch’s theorem with applications to proto-derivatives of subgradient mappings , Transactions of the American Mathematical Society, 347 (1995), pp. 1269–1294
1995
-
[42]
L´evy, Sur certains processus stochastiques homog` enes, Compositio mathematica, 7 (1940), pp
P. L´evy, Sur certains processus stochastiques homog` enes, Compositio mathematica, 7 (1940), pp. 283–339
1940
-
[43]
Lobashev, M
A. Lobashev, M. Larchenko, and D. Guskov , Color conditional generation with sliced wasserstein guidance, Advances in Neural Information Processing Systems, 38 (2026), pp. 164572–164601. 35
2026
-
[44]
Mehta, V
R. Mehta, V. Roulet, K. Pillutla, L. Liu, and Z. Harchaoui , Stochas- tic optimization for spectral risk measures , in International Conference on Artificial Intelligence and Statistics, PMLR, 2023, pp. 10112–10159
2023
-
[45]
M´erigot, A
Q. M´erigot, A. Delalande, and F. Chazal , Quantitative stability of optimal transport maps and linearization of the 2-wasserstein space , in International Confer- ence on Artificial Intelligence and Statistics, PMLR, 2020, pp. 3186–3196
2020
-
[46]
Nadjahi, Sliced-Wasserstein distance for large-scale machine learning: theory, methodology and extensions, PhD thesis, Institut polytechnique de Paris, 2021
K. Nadjahi, Sliced-Wasserstein distance for large-scale machine learning: theory, methodology and extensions, PhD thesis, Institut polytechnique de Paris, 2021
2021
-
[47]
Nadjahi, A
K. Nadjahi, A. Durmus, L. Chizat, S. Kolouri, S. Shahrampour, and U. Simsekli, Statistical and topological properties of sliced probability divergences , Advances in Neural Information Processing Systems, 33 (2020), pp. 20802–20812
2020
-
[48]
Nguyen, S
K. Nguyen, S. Zhang, T. Le, and N. Ho , Sliced wasserstein with random-path projecting directions, in Proceedings of the 41st International Conference on Machine Learning, ICML’24, JMLR.org, 2024
2024
-
[49]
Norkin, Generalized-differentiable functions, Cybernetics and Systems Analysis, 16 (1980), pp
V. Norkin, Generalized-differentiable functions, Cybernetics and Systems Analysis, 16 (1980), pp. 10–12
1980
-
[50]
V. I. Norkin et al., On a strong graphical law of large numbers for random semi- continuous mappings, Vestnik of Saint Petersburg University. Applied Mathematics. Computer Science. Control Processes, (2013), pp. 102–111
2013
-
[51]
V. I. Norkin and R. J.-B. Wets , On a strong graphical law of large numbers for random semicontinuous mappings , Vestnik S.-Petersburg University. Series 10. Applied Mathematics, Computer Science, Control Processes, (2013), pp. 102–111
2013
-
[52]
Pauwels and S
E. Pauwels and S. Vaiter , The derivatives of sinkhorn–knopp converge , SIAM Journal on Optimization, 33 (2023), pp. 1494–1517
2023
-
[53]
Peyr´e and M
G. Peyr´e and M. Cuturi , Computational optimal transport: With applications to data science , Found. Trends Mach. Learn., 11 (2019), p. 355–607
2019
-
[54]
Pillutla, Y
K. Pillutla, Y. Laguel, J. Malick, and Z. Harchaoui , Federated learning with superquantile aggregation for heterogeneous data, Machine Learning, 113 (2024), pp. 2955–3022
2024
-
[55]
Rabin, G
J. Rabin, G. Peyr ´e, J. Delon, and M. Bernot , Wasserstein barycenter and its application to texture mixing , in International conference on scale space and vari- ational methods in computer vision, Springer, 2011, pp. 435–446
2011
-
[56]
Risser, A
L. Risser, A. G. Sanz, Q. Vincenot, and J.-M. Loubes , Tackling algorith- mic bias in neural-network classifiers using wasserstein-2 regularization , Journal of Mathematical Imaging and Vision, 64 (2022), pp. 672–689
2022
-
[57]
R. T. Rockafellar and R. J. B. Wets , Variational Analysis, Springer Berlin Heidelberg, 1998. 36
1998
-
[58]
D. Rodr´ıguez-V´ıtores, C. Lalanne, and J.-M. Loubes , Learning with dif- ferentially private (sliced) wasserstein gradients , arXiv preprint arXiv:2502.01701, (2025)
-
[59]
Y. Rychener, B. Taskesen, and D. Kuhn , Metrizing fairness , arXiv preprint arXiv:2205.15049, (2022)
-
[60]
Salim, A strong law of large numbers for random monotone operators, Set-Valued and Variational Analysis, 31 (2023), p
A. Salim, A strong law of large numbers for random monotone operators, Set-Valued and Variational Analysis, 31 (2023), p. 38
2023
-
[61]
Santambrogio , Optimal Transport for Applied Mathematicians , Progress in Nonlinear Differential Equations and Their Applications, Birkh¨ auser Cham, 1 ed., 2015
F. Santambrogio , Optimal Transport for Applied Mathematicians , Progress in Nonlinear Differential Equations and Their Applications, Birkh¨ auser Cham, 1 ed., 2015
2015
-
[62]
Schechtman , The gradient’s limit of a definable family of functions admits a variational stratification, SIAM Journal on Optimization, (2026)
S. Schechtman , The gradient’s limit of a definable family of functions admits a variational stratification, SIAM Journal on Optimization, (2026)
2026
-
[63]
Sebbouh, M
O. Sebbouh, M. Cuturi, and G. Peyr´e, Randomized stochastic gradient descent ascent, in International Conference on Artificial Intelligence and Statistics, PMLR, 2022, pp. 2941–2969
2022
-
[64]
Shapiro and H
A. Shapiro and H. Xu , Uniform laws of large numbers for set-valued mappings and subdifferentials of random functions , Journal of Mathematical Analysis and Ap- plications, 325 (2007), pp. 1390–1399
2007
-
[65]
E. Tanguy, L. Chapel, and J. Delon , Sliced optimal transport plans , arXiv preprint arXiv:2508.01243, (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
Tanguy, R
E. Tanguy, R. Flamary, and J. Delon, Properties of discrete sliced wasserstein losses, Mathematics of Computation, 94 (2025), pp. 1411–1465
2025
-
[67]
C. Vauthier, A. Korba, and Q. M ´erigot, Towards understanding gradient dynamics of the sliced-wasserstein distance via critical point analysis , arXiv preprint arXiv:2502.06525, (2025)
-
[68]
J. Wang, R. Gao, and Y. Xie , Sinkhorn distributionally robust optimization , 2023
2023
-
[69]
R. Xiao, Y. Ge, R. Jiang, and Y. Yan , A unified framework for rank-based loss minimization , Advances in Neural Information Processing Systems, 36 (2023), pp. 51302–51326
2023
-
[70]
Zolezzi , Convergence of generalized gradients , Set-Valued Analysis, 2 (1994), pp
T. Zolezzi , Convergence of generalized gradients , Set-Valued Analysis, 2 (1994), pp. 381–393. 37
1994
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.