Localizing Input Uncertainty Quantification for Large Language Models via Shapley Values
Pith reviewed 2026-06-29 12:39 UTC · model grok-4.3
The pith
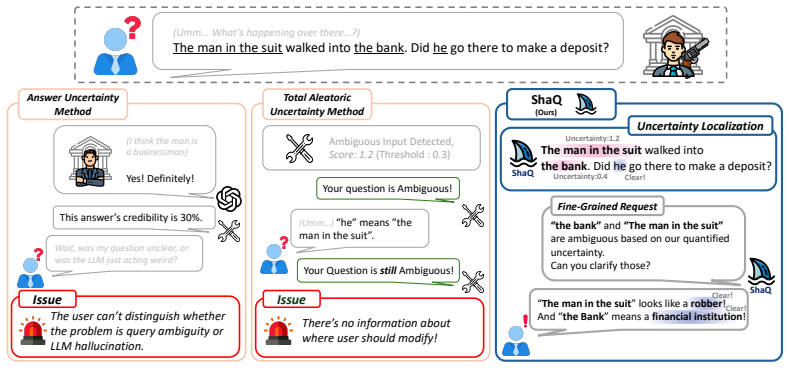
ShaQ attributes uncertainty in LLM outputs to specific ambiguous input spans using Shapley values from conditional entropy reductions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
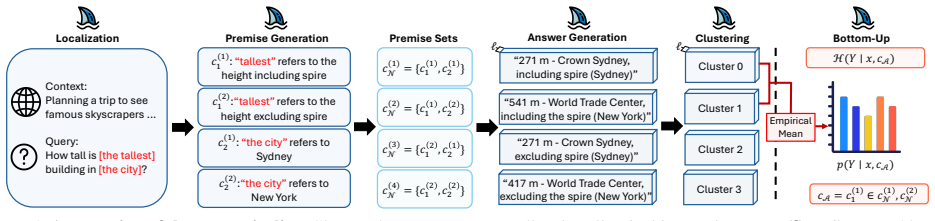
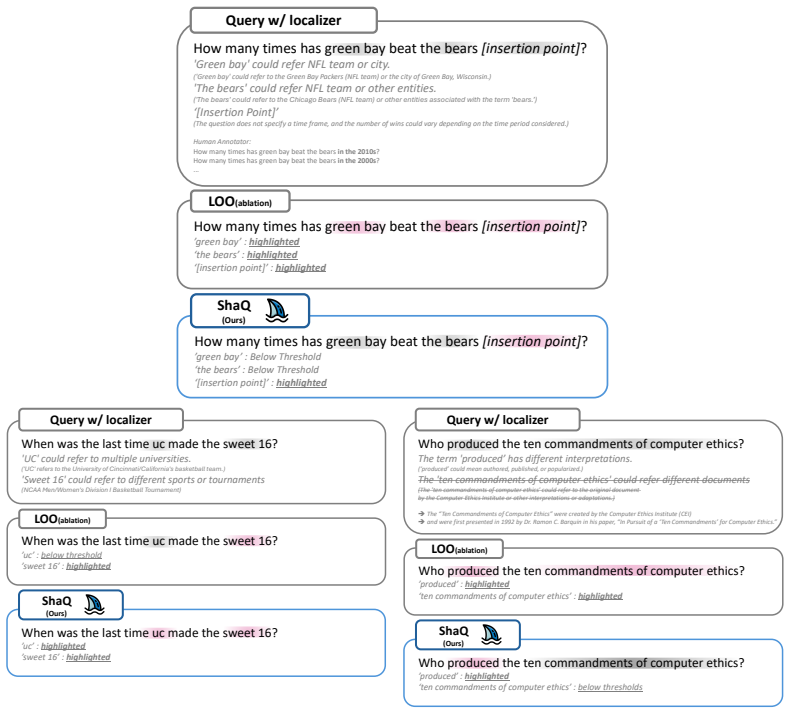
ShaQ models ambiguous spans in the input as players in a cooperative game and quantifies their contributions using Shapley values, defined via the weighted average of marginal reductions in conditional entropy obtained by clarifying each span coalition, providing a principled decomposition in which individual attributions sum exactly to the total input-induced uncertainty.
What carries the argument
Shapley values defined via the weighted average of marginal reductions in conditional entropy obtained by clarifying span coalitions
If this is right
- Individual span attributions sum exactly to the total input-induced uncertainty.
- The formulation captures complex interactions among spans.
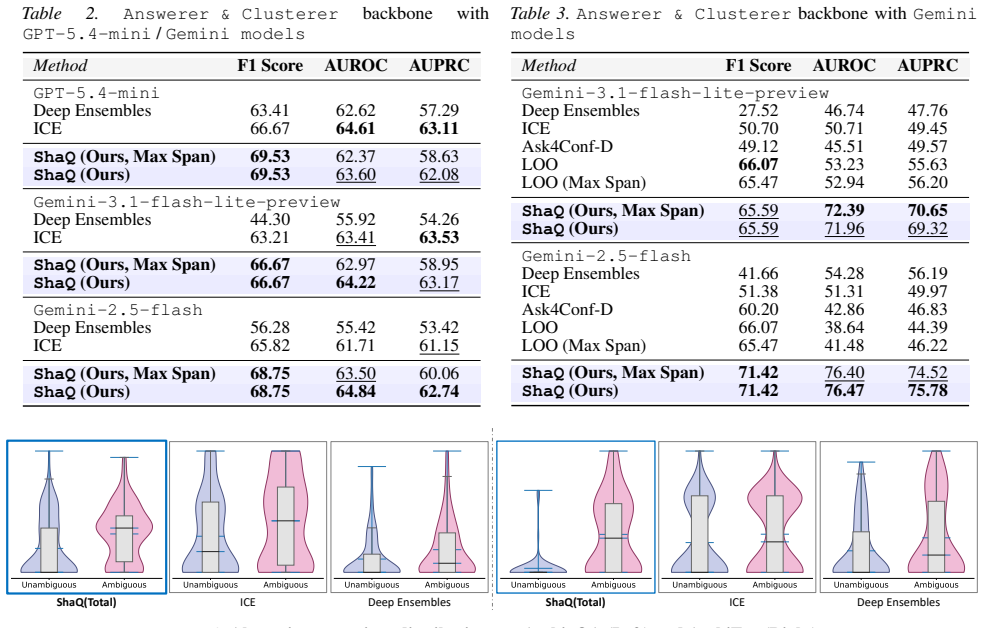
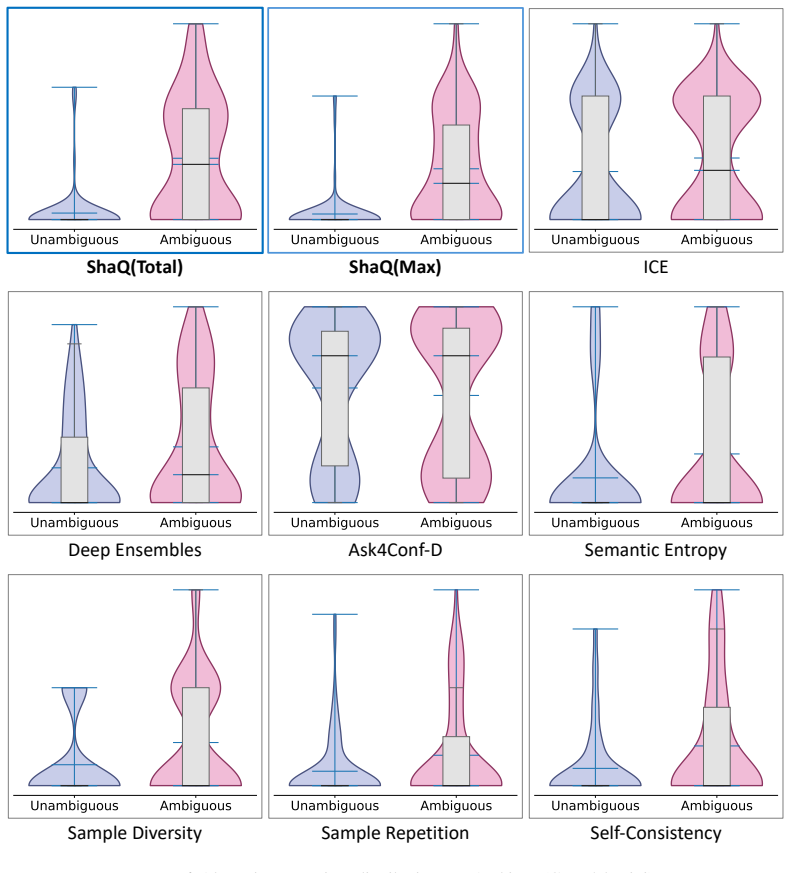
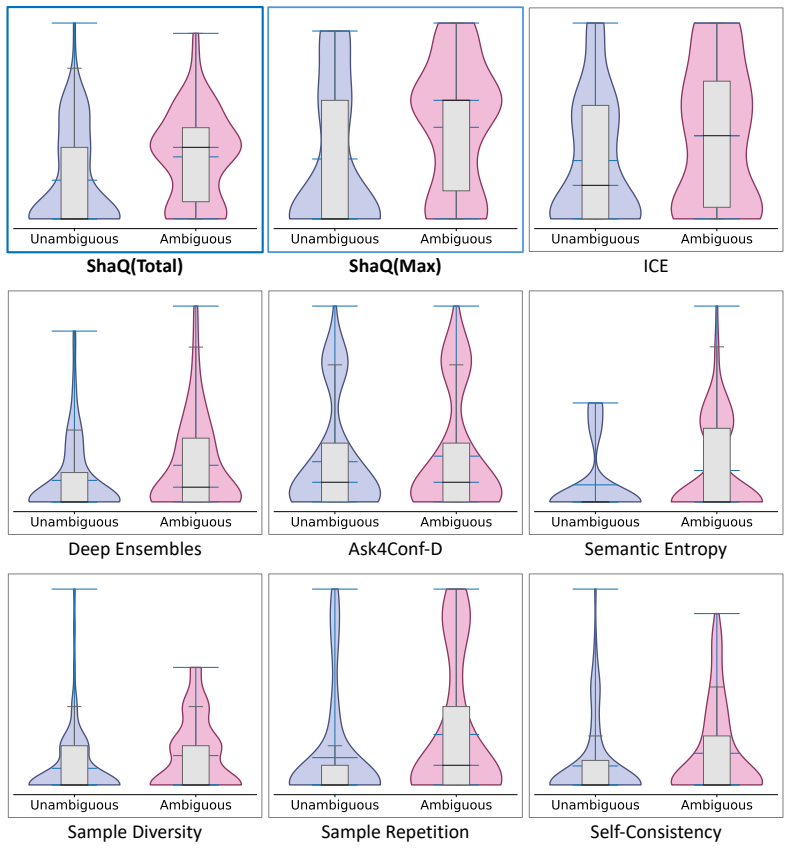
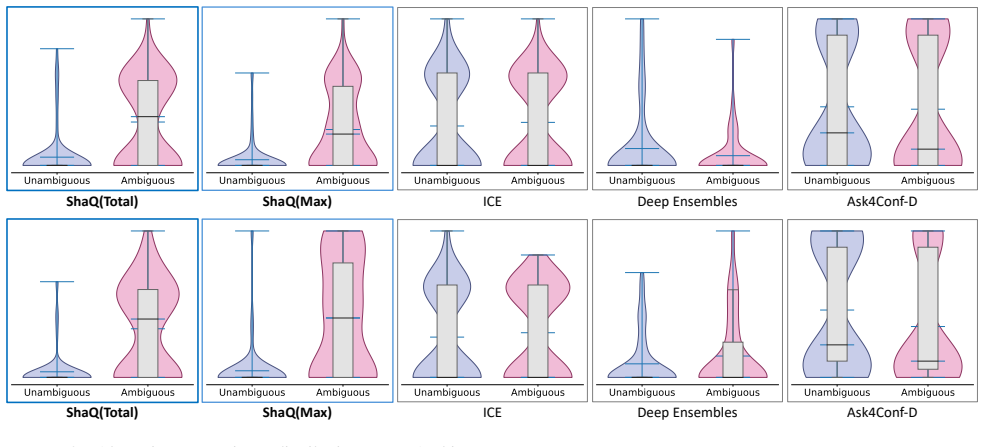
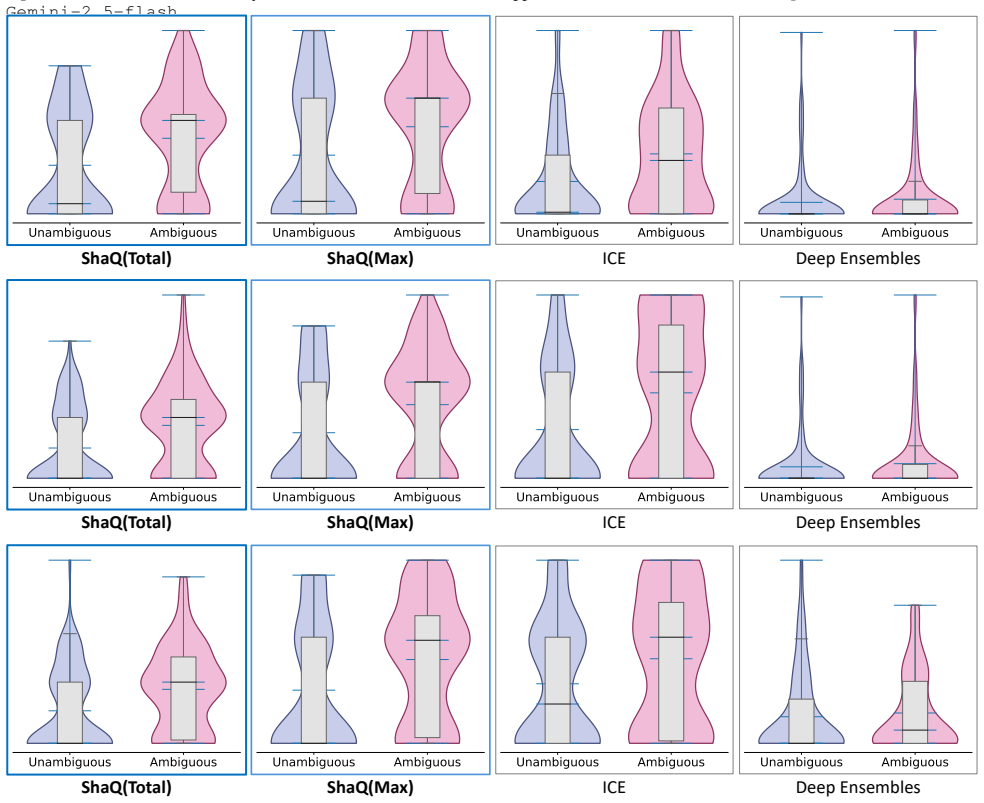
- ShaQ achieves state-of-the-art performance in ambiguity detection on the AmbigQA and AmbiEnt benchmarks.
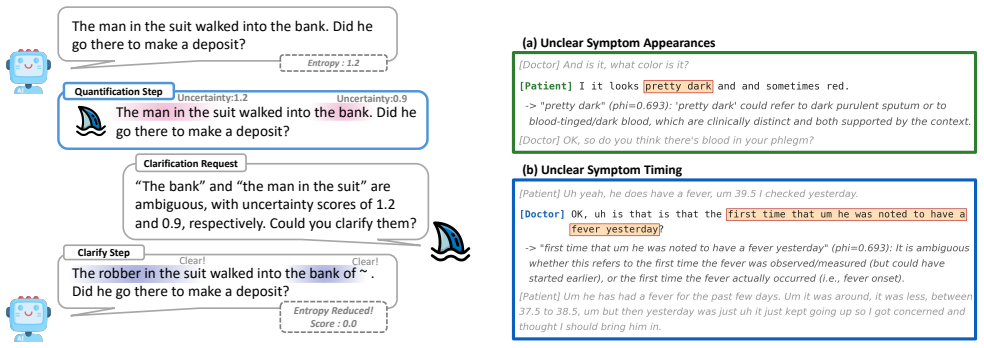
- ShaQ localizes under-specified clinical utterances on MediTOD and supports targeted clarification in human-AI collaboration.
Where Pith is reading between the lines
- Interactive systems could use high-attribution spans to prompt users for clarification in real time.
- The same game setup could be adapted to isolate uncertainty arising from model knowledge gaps rather than input ambiguity.
- Integrating ShaQ into model training loops might encourage LLMs to request clarification on ambiguous spans automatically.
- Running ShaQ across many different LLM architectures would test whether the entropy-based attributions remain stable.
Load-bearing premise
Marginal reductions in conditional entropy when clarifying coalitions of spans can be used to define Shapley values that additively decompose input-induced uncertainty while capturing interactions without model-specific biases.
What would settle it
A direct check that the sum of all span attributions equals the total conditional entropy of the input, or an experiment showing whether clarifying the highest-attribution spans reduces uncertainty more than clarifying lower-attribution ones.
Figures












read the original abstract
As large language models (LLMs) are increasingly integrated into high-stakes decision-making, the ability to reliably quantify uncertainty has become a critical requirement for safety and trust. However, current uncertainty quantification methods primarily operate at the output level, often failing to distinguish whether uncertainty arises from the model's lack of knowledge or from ambiguity in the user's input. While input-centric uncertainty quantification has recently emerged as a promising direction, it remains relatively underexplored and typically relies on coarse, input-level information. Consequently, users are provided with scalar uncertainty scores that offer little actionable guidance on which parts of the input should be clarified to improve reliability. To address this limitation, we propose Shapley-based input uncertainty Quantification (ShaQ), a framework for span-level attribution of input-induced uncertainty. Our approach models ambiguous spans in the input as players in a cooperative game and quantifies their contributions using Shapley values, defined via the weighted average of marginal reductions in conditional entropy obtained by clarifying each span coalition. Unlike existing input-level approaches, our formulation captures complex interactions among spans and provides a principled decomposition in which individual attributions sum exactly to the total input-induced uncertainty. We evaluate ShaQ on the AmbigQA and AmbiEnt benchmarks, where it achieves state-of-the-art performance in ambiguity detection. We further demonstrate its utility on MediTOD, showing that ShaQ can localize under-specified clinical utterances and facilitate human-AI collaboration in high-stakes settings. Overall, ShaQ improves uncertainty estimation and provides actionable insights for targeted input clarification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ShaQ, a framework that models ambiguous spans in LLM inputs as players in a cooperative game and attributes input-induced uncertainty via Shapley values computed from marginal reductions in conditional entropy when coalitions of spans are clarified. It claims this yields an exact additive decomposition of total input uncertainty, captures span interactions, outperforms prior methods on AmbigQA and AmbiEnt for ambiguity detection, and aids human-AI collaboration on MediTOD by localizing under-specified clinical utterances.
Significance. If the value function is shown to isolate input ambiguity without model-specific biases, ShaQ supplies a principled, interaction-aware localization tool that moves beyond scalar input uncertainty scores. The reliance on the standard Shapley construction (additivity holds by definition for any valid v) is a methodological strength, and the application to high-stakes domains like clinical dialogue is a practical contribution.
major comments (2)
- [§3] §3 (method): the value function v(S) is defined via marginal entropy reduction upon span clarification, but the manuscript must explicitly address how clarification is realized in the LLM (e.g., prompt rewriting, token masking, or conditioning) to ensure the marginal contributions remain faithful to input-induced uncertainty rather than conflating it with output-generation stochasticity.
- [§4] §4 (experiments): the SOTA claim on AmbigQA/AmbiEnt requires reporting of exact metrics, baseline implementations, and statistical significance; without these, it is unclear whether gains stem from the Shapley decomposition itself or from auxiliary modeling choices.
minor comments (3)
- [§3] Notation for conditional entropy and the characteristic function v should be introduced with a single consistent equation early in §3 to avoid reader confusion when later referencing coalitions.
- The computational complexity of exact Shapley values is exponential; the paper should state whether Monte-Carlo sampling or other approximations are used and report variance or convergence diagnostics.
- Figure captions and table headers should explicitly label the uncertainty metric (e.g., “input-induced entropy”) rather than generic “uncertainty score.”
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive recommendation for minor revision. We address each major comment below and will update the manuscript accordingly to improve clarity on the value function and experimental details.
read point-by-point responses
-
Referee: [§3] §3 (method): the value function v(S) is defined via marginal entropy reduction upon span clarification, but the manuscript must explicitly address how clarification is realized in the LLM (e.g., prompt rewriting, token masking, or conditioning) to ensure the marginal contributions remain faithful to input-induced uncertainty rather than conflating it with output-generation stochasticity.
Authors: We agree that the current description in §3 would benefit from greater explicitness on the clarification procedure. Clarification is performed via prompt rewriting: each coalition S is clarified by substituting the spans in S with their ground-truth disambiguations (from benchmark annotations) while leaving all other tokens unchanged; the LLM is then conditioned on this rewritten prompt to compute the conditional entropy of the output distribution. This isolates input-induced uncertainty because the only change is the input content, not the sampling procedure or model parameters. We will add a new paragraph and pseudocode in §3 detailing this exact mechanism, including how we ensure the entropy computation uses the same generation settings across coalitions. revision: yes
-
Referee: [§4] §4 (experiments): the SOTA claim on AmbigQA/AmbiEnt requires reporting of exact metrics, baseline implementations, and statistical significance; without these, it is unclear whether gains stem from the Shapley decomposition itself or from auxiliary modeling choices.
Authors: We acknowledge that the experimental section would be strengthened by additional reporting. The manuscript already contains comparative tables, but we will expand §4 with: (i) the precise numerical values for all metrics (accuracy, F1, AUC) rather than only relative rankings, (ii) full implementation details and hyperparameter settings for each baseline, and (iii) statistical significance results (paired t-tests over 5 random seeds) comparing ShaQ against the strongest baselines. These additions will make it possible to attribute performance differences more clearly to the Shapley formulation. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines ShaQ by applying the standard Shapley value formula (weighted average of marginal contributions) to a value function v based on reductions in conditional entropy when clarifying input span coalitions. The claimed additive decomposition (attributions sum exactly to total input-induced uncertainty) follows directly from the definition of Shapley values for any v, which is the standard mathematical property rather than a derived or fitted result internal to the paper. No self-citations, uniqueness theorems, ansatzes smuggled via prior work, or fitted parameters renamed as predictions appear in the abstract or description. The central construction is an application of cooperative game theory to the entropy-based value function and remains independent of its own outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
the flash
Entity overlap — the same name refers to two or more well-known entities that yield different answers. (e.g., “the flash” → 1990 TV series vs 2014 TV series)
1990
-
[2]
current”, “recent
Role/title holders — role-based questions where MORE THAN ONE person is commonly associated, especially with words like “current”, “recent”, or no time qualifier. (e.g., “Who is the administrator of the SBA?” — changed multiple times)
-
[3]
Who won the world cup?
Missing specifier — a key dimension (sport, year, country, gender, edition) is absent and there are multiple well-known correct answers across that dimension. (e.g., “Who won the world cup?” — no sport, no year)
-
[4]
more famous
Temporal — the answer has changed over time AND the question does NOT fix a specific time period. Err toward marking temporal ambiguity when the role or record holder has changed within the past∼20 years, even if one answer is “more famous”. Do NOT mark as ambiguous: • Questions with a single universally dominant answer that virtually everyone would give....
-
[6]
Each premise must be strongly supported by the wording, not merely theoretically possible
-
[7]
All premises must point to real, well-known facts, media, people, or events
DO NOT invent fictional or unverifiable entities. All premises must point to real, well-known facts, media, people, or events
-
[9]
Verify: would a knowledgeable person give a DIFFERENT answer under each premise? If not, do not include both
-
[10]
Keep each premise concise, one short sentence
-
[11]
If the span text is [insertion point] , generate assumptions that supply the missing context, e.g., a specific year, country, sport, or edition
-
[12]
Prefer the MOST COMMON or WELL-KNOWN interpretations first
-
[13]
Do not use obscure variants, foreign editions, regional releases, minor adaptations, or historical edge cases unless the question wording directly makes that dimension salient
-
[14]
Do not split by spelling, alias, paraphrase, or answer granularity if experts would still converge on the same factual answer
-
[15]
premises
When in doubt, be conservative: return fewer premises rather than low-plausibility ones. ## Examples {Examples} ## Task Question:{clean_sentence} Span id:{span_id} Span text:{span_text} Ambiguity reason:{reason} The"premises"array must contain between 1 and{m}items. Add another item only if it is a strong, common, answer-changing interpretation. Figure 14...
-
[16]
Output ONLY the answer entity
Your answer MUST be≤5 words. Output ONLY the answer entity
-
[17]
If the assumption specifies a particular year, TV series, edition, or context, answer for THAT specific version — not the most well-known one
STRICTLY follow the assumption. If the assumption specifies a particular year, TV series, edition, or context, answer for THAT specific version — not the most well-known one
-
[18]
According to
DO NOT explain, hedge, or add qualifiers. No “According to...” or “I think...”
-
[19]
DO NOT fall back to the most famous answer
If the assumption points to an obscure but real entity, output that entity. DO NOT fall back to the most famous answer
-
[20]
## Examples {Examples} Question:{clean_sentence} Assumptions: {premises} Answer: Figure 15.Prompt used for the Answerer
If Assumptions say “None.”, answer the question with its most common interpretation. ## Examples {Examples} Question:{clean_sentence} Assumptions: {premises} Answer: Figure 15.Prompt used for the Answerer. 34 Prompt: Clusterer You are a semantic clustering assistant. Your task is to group a list of short answers to a question into clusters based on whethe...
-
[21]
Paris" and
SAME cluster — surface variations of the same entity: • "Paris" and "paris, france"→same cluster • "1992" and "nineteen ninety-two"→same cluster • "George Washington" and "Washington"→same cluster • "The 2014 CW series" and "2014 Flash"→same cluster • "22 episodes" and "22"→same cluster • "Amy Adams" and "Amy Lou Adams"→same cluster
1992
-
[22]
Paris" and
DIFFERENT clusters — genuinely distinct entities or facts: • "Paris" and "London"→different clusters • "1990" and "2014"→different clusters • "22" and "23"→different clusters • "France" and "Argentina"→different clusters
1990
-
[23]
Unknown",
Refusals: "Unknown", "I don’t know", "N/A", or any refusal to answer form their own single cluster, separate from all factual answers
-
[24]
New York Yankees
Partial overlap: If two answers share some words but refer to different entities, they go in DIFFERENT clusters. - "New York Yankees" and "New York Mets"→different clusters
-
[26]
## Examples {Examples} ## Task Question: {question} Answers: {answers_numbered_list} Figure 16.Prompt used for the Clusterer
Every answer index must be assigned to exactly one cluster. ## Examples {Examples} ## Task Question: {question} Answers: {answers_numbered_list} Figure 16.Prompt used for the Clusterer. 35 Prompt: Ask4Conf-D Read the following question: Question:{sentence} Provide the probability that this question is ambiguous due to factors such as ambiguous entities, a...
-
[32]
Figure 18.Prompt used for the Uncertainty-guided Clarification
If the original question is already clear, keep it nearly unchanged. Figure 18.Prompt used for the Uncertainty-guided Clarification. 36 Uncertainty-guided Question Clarification Prompt for ShaQ You rewrite ambiguous QA questions so that answer uncertainty is reduced while the original broad intent is preserved. You are given only an original question, num...
-
[33]
Return exactly one rewritten direct wh-question
-
[34]
Preserve the original topic and answer type
-
[35]
Prefer edits around spans with larger span uncertainty scores
-
[36]
Do not answer the question
-
[37]
Do not include a candidate answer in the question unless that text already appeared in the original question
-
[38]
Do not ask a yes/no question and do not ask the model to list multiple alternatives
-
[39]
min": {min} ,
If the original question is already clear, keep it nearly unchanged. Figure 19.Prompt used for the Uncertainty-guided Clarification withShaQ. Uncertainty context Numeric uncertainty scores: query_ambiguity: {query_ambiguity} , query_ambiguity_stats: "min": {min} , "max": {max} , "mean": {mean} , "median": {median} , "variance": {variance} , "threshold": {...
-
[40]
The span has at least two DISTINCT, mutually incompatible interpretations
-
[41]
Both interpretations are COMMON and strongly supported by the wording plus context
-
[42]
Choosing between them would materially change the clinical understanding, factual assumption, likely answer, or follow-up question
-
[43]
If a span is merely imprecise, approximate, broad, or missing detail, that alone is NOT enough
No single interpretation is clearly dominant to a knowledgeable doctor or patient. If a span is merely imprecise, approximate, broad, or missing detail, that alone is NOT enough. MARK as ambiguous only when:
-
[44]
Ambiguous referents — a pronoun or vague noun could realistically refer to two different symptoms, body parts, time points, or events already active in context
-
[45]
more detail is needed
Competing medical readings — the wording naturally supports two different concrete clinical meanings, not just “more detail is needed.”
-
[46]
Missing anchor with competing outcomes — omitted timing, target, or state creates two different plausible medical situations that knowledgeable readers would genuinely disagree between
-
[47]
cough”, “headache
Clinically meaningful missing degree or duration — severity, frequency, amount, or duration is expressed so loosely that two different COMMON clinical readings remain live, and the context does not make one reading clearly dominant. Do NOT mark as ambiguous: • Clear statements with one dominant clinical interpretation, even if somewhat informal or approxi...
-
[48]
Each premise describes a specific, real-world interpretation of the span
-
[49]
Each premise must be strongly supported by the context, not merely theoretically possible
-
[50]
The premises must be MUTUALLY EXCLUSIVE — they cannot be simultaneously true
-
[51]
Verify: would a knowledgeable person derive a DIFFERENT medical or semantic meaning under each premise? If not, do not include both
-
[52]
Keep each premise concise (one short sentence)
-
[53]
Prefer the MOST COMMON or CLINICALLY RELEV ANT interpretations first
-
[54]
Do not use obscure variants, highly unlikely edge cases, or unrelated diagnoses unless the context directly makes that dimension salient
-
[55]
When did the pain start getting worse?
When in doubt, be conservative: return fewer premises rather than low-plausibility ones. ## Example Context:Doctor: “When did the pain start getting worse?” Current Utterance:“It hurt a little every time I exercised.” Span text:“exercised” Ambiguity reason:“The type and intensity of the exercise is unspecified and could change the clinical understanding.”...
-
[56]
Keep it short and factual
Your answer MUST be≤20 words. Keep it short and factual
-
[57]
Rewrite the utterance to embed the specific meaning of the assumption into it
STRICTLY follow the assumption. Rewrite the utterance to embed the specific meaning of the assumption into it
-
[58]
Under the assumption
DO NOT explain, hedge, or add qualifiers (e.g., skip “Under the assumption...”, “This means...”). ONLY output the rewritten meaning
-
[59]
None.”, answer with the most straightforward interpretation. ## Examples Context:Doctor: “When did the pain start getting worse?
If Assumptions say “None.”, answer with the most straightforward interpretation. ## Examples Context:Doctor: “When did the pain start getting worse?” Current Utterance:“It hurt a little every time I exercised.” Assumptions:“exercised” refers to strenuous weightlifting. Answer:It hurt a little every time I did heavy weightlifting. Context:Doctor: “When did...
-
[60]
Assign cluster ids as consecutive integers starting from 0
-
[61]
Every answer index must be assigned to exactly one cluster
-
[62]
Unknown”, “N/A
Refusals (“Unknown”, “N/A”) go into their own independent cluster. ## TaskMedical Dialogue Context:{context} Current Utterance:{question} Answers:{answers_numbered_list} Respond strictly in the following JSON format. Do not include any explanation or extra text. { "clusters": { "0": <cluster_id>, "1": <cluster_id> } } Figure 25.Prompt for the Clusterer: g...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.