Visualizing Latent Phase Structures in Locomotion Policies: A Multi-Environment Study with Temporal Feature Extension
Pith reviewed 2026-06-29 11:55 UTC · model grok-4.3
The pith
Augmenting state features with actions and next states uncovers clearer latent motion phases in locomotion policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
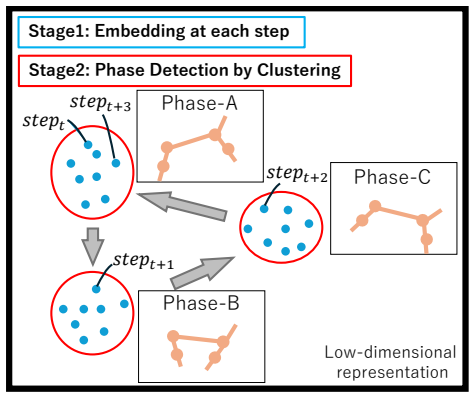
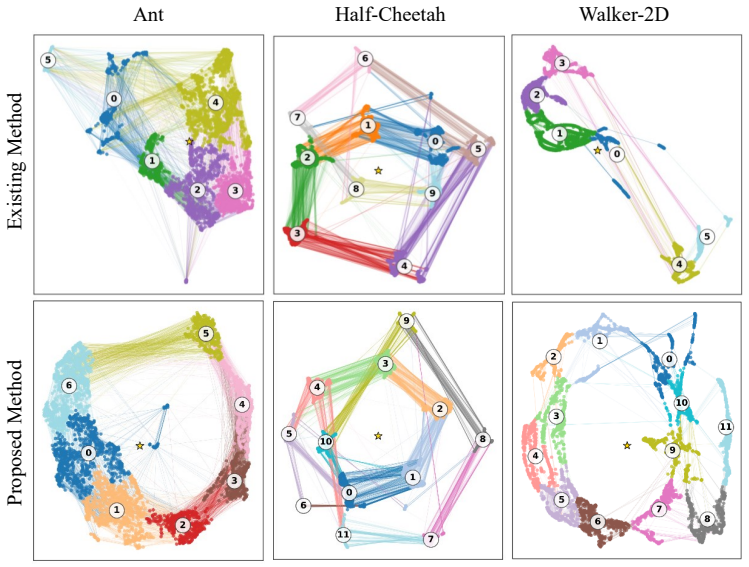
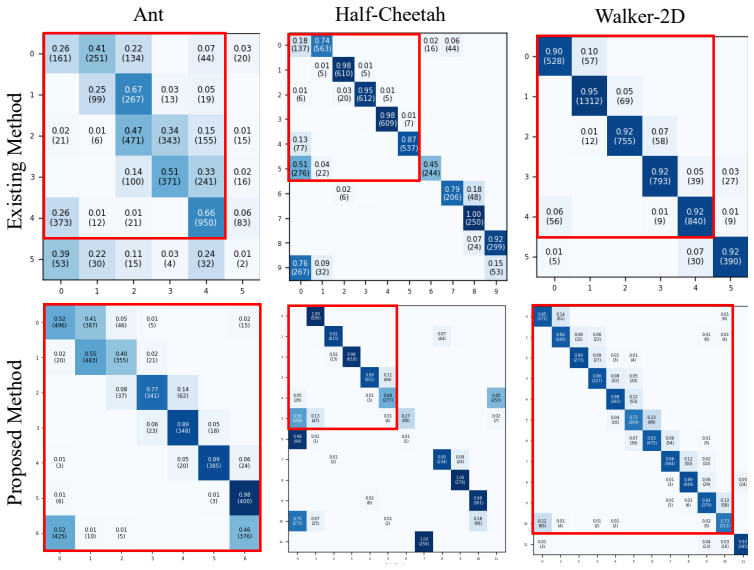
The proposed method extends clustering features from state observations alone to augmented features including actions, next states, and next actions, and introduces a method for determining the number of clusters that suppresses self-transitions. Applying this to three MuJoCo environments successfully identified phase structures with clearer and more regular transition rules than those obtained by the existing method.
What carries the argument
Temporal feature extension for clustering, which augments state observations with actions, next states, and next actions together with a self-transition suppression rule for choosing cluster count.
If this is right
- Locomotion policies in these environments implicitly organize behavior into repeatable phases with consistent transition patterns.
- Phase visualization becomes feasible without hand-crafted phase labels or explicit biomechanical models.
- The same augmentation and suppression approach can be applied to other continuous-control environments to expose internal structure.
- Policy analysis gains a quantitative measure of phase regularity that distinguishes better-organized policies from less organized ones.
Where Pith is reading between the lines
- The method might be combined with phase-specific reward shaping to improve sample efficiency in new locomotion tasks.
- Similar temporal extensions could be tested on non-locomotion control problems where sequential structure is expected but not labeled.
- If the phases prove stable across policy initializations, they could serve as a diagnostic for whether a policy has converged to a biologically plausible gait.
Load-bearing premise
That the augmented features plus self-transition suppression actually produce clusters corresponding to genuine latent motion phases instead of artifacts of the feature choice or the heuristic.
What would settle it
If manual inspection of trajectories shows that the discovered clusters do not align with observable biomechanical events such as foot contact or leg swing, or if transition regularity is no higher than with random feature choices.
Figures

read the original abstract
Deep reinforcement learning (DRL) has been shown to achieve high performance on locomotion control tasks in MuJoCo benchmarks such as HalfCheetah, Ant, and Walker2D. However, visualizing the motion structures internally obtained by a trained policy function implemented as a deep neural network remains challenging. It is known from biomechanics and related fields that locomotion control is realized through the repetition of motion phases such as the stance phase and swing phase. In this study, we propose a framework for uncovering latent motion phase structures from trajectories generated by locomotion control policies through interaction with the environment. The proposed method extends the clustering features from state observations alone to augmented features including actions, next states, and next actions, and introduces a method for determining the number of clusters that suppresses self-transitions. Applying the proposed method to three environments -- Ant-v5, HalfCheetah-v5, and Walker2D-v5 -- we successfully identified phase structures with clearer and more regular transition rules than those obtained by the existing method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes extending clustering features for visualizing latent phases in DRL locomotion policies from states alone to include actions, next-states, and next-actions, combined with a self-transition suppression heuristic for selecting the number of clusters k. Applied to Ant-v5, HalfCheetah-v5, and Walker2D-v5, it claims this yields phase structures with clearer and more regular transition rules than an existing baseline method.
Significance. If the clusters reliably recover genuine biomechanical phases rather than feature-induced artifacts, the framework could aid interpretability of black-box locomotion policies across MuJoCo environments. The multi-environment application is a positive aspect, but the lack of quantitative validation or ground-truth alignment reduces the strength of the contribution to the field.
major comments (2)
- [Abstract] Abstract: the central claim that the method produces 'clearer and more regular transition rules' than the existing method is asserted without any quantitative metrics (e.g., transition matrix entropy, regularity scores, or alignment with simulator contact/kinematic ground truth), making the improvement impossible to assess objectively.
- [Method] Method description (inferred from abstract and reader's summary): the self-transition suppression rule for choosing k and the feature augmentation are presented at a high level with no ablation isolating their individual contributions, no comparison to standard cluster selection criteria, and no validation that the resulting clusters correspond to biomechanically meaningful phases rather than artifacts of the heuristic.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify that the current manuscript relies on qualitative visual comparisons rather than quantitative metrics or ablations. We address each point below and commit to revisions that strengthen the evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the method produces 'clearer and more regular transition rules' than the existing method is asserted without any quantitative metrics (e.g., transition matrix entropy, regularity scores, or alignment with simulator contact/kinematic ground truth), making the improvement impossible to assess objectively.
Authors: We agree that the abstract and results section present the improvement through visual inspection of transition diagrams across the three environments. No quantitative metrics are currently reported. In the revision we will add objective measures, including transition-matrix entropy and a self-transition regularity score, computed on the same trajectories to allow direct comparison with the baseline. revision: yes
-
Referee: [Method] Method description (inferred from abstract and reader's summary): the self-transition suppression rule for choosing k and the feature augmentation are presented at a high level with no ablation isolating their individual contributions, no comparison to standard cluster selection criteria, and no validation that the resulting clusters correspond to biomechanically meaningful phases rather than artifacts of the heuristic.
Authors: Section 3 describes the augmented feature set (state, action, next-state, next-action) and the self-transition suppression heuristic for k selection. We acknowledge the absence of ablations and comparisons to criteria such as silhouette score or the elbow method. The revision will include these ablations. Regarding biomechanical validation, the manuscript treats transition regularity as a proxy for meaningful phases; we will add discussion of alignment with known locomotion phases and, where simulator data permit, contact-force statistics as supplementary evidence. revision: yes
Circularity Check
No circularity: empirical clustering on augmented trajectories with heuristic k-selection
full rationale
The paper presents an empirical method that augments clustering features with actions/next-states/next-actions and applies a self-transition suppression rule to choose cluster count, then reports the resulting phase structures on three MuJoCo environments. No equations, derivations, or first-principles claims are given that reduce the reported structures to quantities defined by the augmentation or suppression rule itself. No self-citations are invoked as load-bearing uniqueness theorems. The central claim is simply the outcome of running the described procedure, which is self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of clusters
axioms (1)
- domain assumption Locomotion control is realized through the repetition of motion phases such as the stance phase and swing phase.
Reference graph
Works this paper leans on
-
[1]
Efficient bipedal robots based on passive-dynamic walkers.Science, 307(5712):1082–1085, 2005
Steven Collins, Andy Ruina, Russ Tedrake, and Martijn Wisse. Efficient bipedal robots based on passive-dynamic walkers.Science, 307(5712):1082–1085, 2005
2005
-
[2]
Addressing function approximation error in actor-critic methods
Scott Fujimoto, Herke van Hoof, and David Meger. Addressing function approximation error in actor-critic methods. InInternational Conference on Machine Learning (ICML), 2018
2018
-
[3]
Hybrid dynamics of bipedal walking.Autonomous Robots, 17(2):105–125, 2004
Yildirim Hurmuzlu, Cagatay Basdogan, and Dan Stoianovici. Hybrid dynamics of bipedal walking.Autonomous Robots, 17(2):105–125, 2004
2004
-
[4]
Continuous control with deep reinforcement learning
Timothy P. Lillicrap, Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforcement learning.arXiv preprint arXiv:1509.02971, 2019
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[5]
Umap: Uniform manifold approximation and projection
Leland McInnes, John Healy, and James Melville. Umap: Uniform manifold approximation and projection. Journal of Open Source Software, 3(29):861, 2018
2018
-
[6]
Rousseeuw
Peter J. Rousseeuw. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis.Journal of Computational and Applied Mathematics, 20:53–65, 1987
1987
-
[7]
Deterministic policy gradient algorithms
David Silver, Guy Lever, Nicolas Heess, Thomas Degris, Daan Wierstra, and Martin Riedmüller. Deterministic policy gradient algorithms. InProceedings of the 31st International Conference on Machine Learning (ICML), 2014
2014
-
[8]
Sutton and Andrew G
Richard S. Sutton and Andrew G. Barto.Reinforcement Learning: An Introduction. MIT Press, Cambridge, MA, 2018
2018
-
[9]
Mujoco: A physics engine for model-based control.IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2012
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control.IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2012
2012
-
[10]
Deep reinforcement learning with double q-learning
Hado van Hasselt, Arthur Guez, and David Silver. Deep reinforcement learning with double q-learning. InAAAI, 2016
2016
-
[11]
Daisuke Yasui, Toshitaka Matsuki, and Hiroshi Sato. Uncovering latent phase structures and branching logic in locomotion policies: A case study on halfcheetah.arXiv preprint arXiv:2603.18084, 2026
-
[12]
Graying the black box: Understanding dqns
Tom Zahavy, Nir Ben-Zrihem, and Shie Mannor. Graying the black box: Understanding dqns. InInternational Conference on Machine Learning (ICML), 2016. 9
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.