Robust Cross-Domain Generalization Using Unlabeled Target Data with Source-Domain Supervision
Pith reviewed 2026-06-29 12:43 UTC · model grok-4.3
The pith
Unlabeled target ultrasound images enable self-supervised pretraining that lifts cross-device segmentation Dice by over 6% when paired with labeled source data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
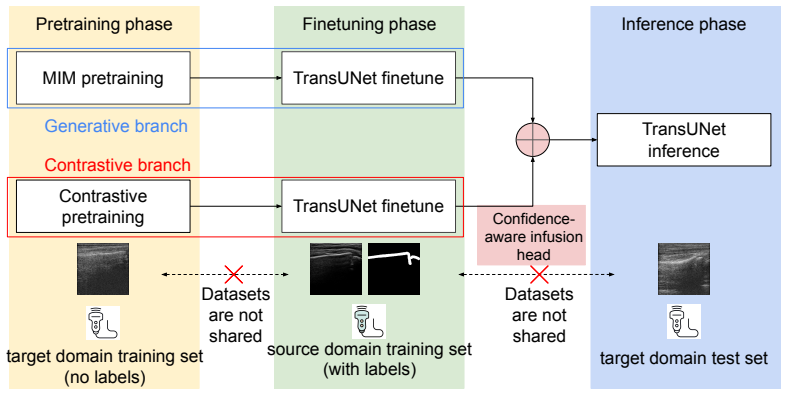
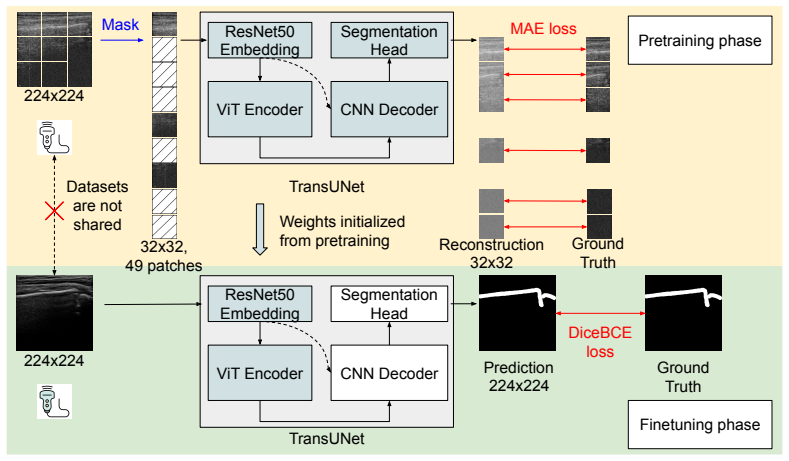
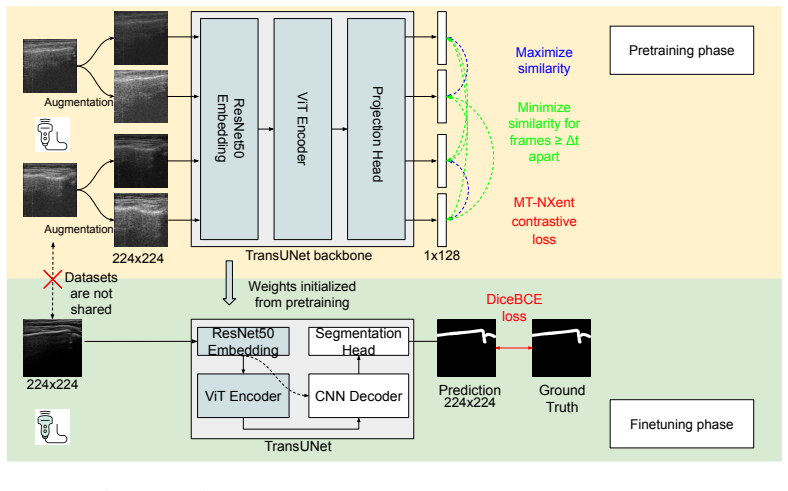
The method learns target-domain structural representations through masked image modeling and contrastive learning on unlabeled images, trains a segmentation model under source-domain supervision, and uses a confidence-aware infusion head to adaptively combine predictions, yielding more than 6% Dice improvement on the target domain relative to a supervised baseline while keeping the source and target datasets strictly separate.
What carries the argument
Target-informed self-supervised pretraining with masked image modeling and contrastive learning, together with a confidence-aware infusion head that adaptively integrates source-trained and target-adapted predictions.
If this is right
- A model trained with dense labels on one probe can be adapted to another probe without requiring any new dense annotations on the target device.
- Source and target datasets remain strictly separate throughout training, supporting privacy constraints in clinical data sharing.
- The same pretraining-plus-infusion strategy supplies a concrete framework that extends directly to multi-center studies or federated learning setups.
Where Pith is reading between the lines
- The same unlabeled-target pretraining step could be tested on other ultrasound tasks such as nerve or vessel segmentation where device shifts are also common.
- If the learned representations capture bone geometry reliably, the method might be applied to fracture detection rather than segmentation alone.
- Extending the approach to additional probe types beyond the two examined here would test whether the reported gain generalizes across a wider range of hardware.
Load-bearing premise
Self-supervised pretraining on the unlabeled target images produces structural representations that transfer usefully to the downstream bone segmentation task when combined with source supervision.
What would settle it
Re-running the supervised baseline and the proposed method on the identical set of 318 target images and observing no Dice gain or a reversal of the reported improvement.
Figures

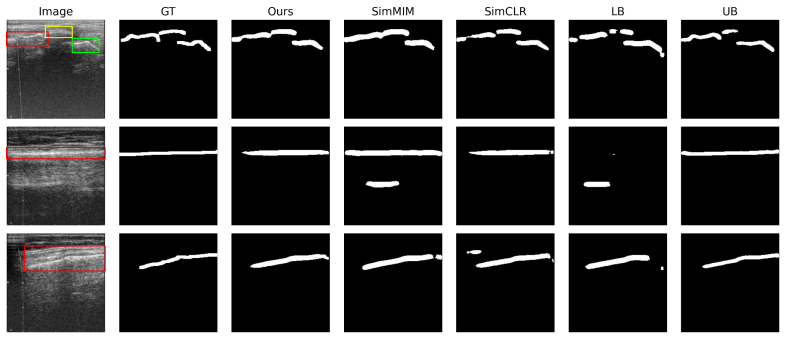
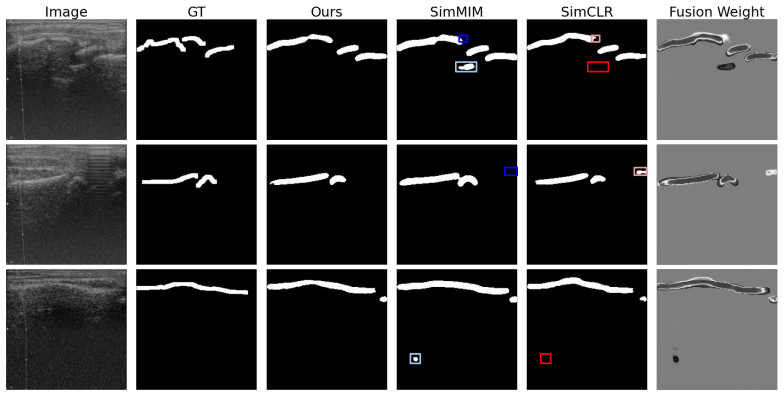
read the original abstract
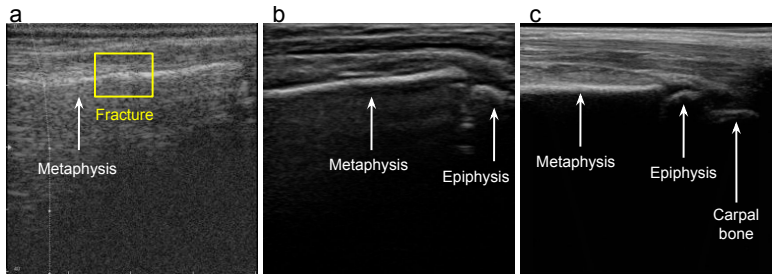
It is often desirable to generalize medical imaging AI models trained with dense annotations to data acquired from different ultrasound scanners or clinical sites; however, retraining these models with new annotations is often difficult and costly. We examine this challenge in pediatric wrist fracture assessment using point-of-care ultrasound (POCUS), where fractures are common and can be effectively triaged via ultrasound. AI has shown radiologist-level performance for fracture detection, often aided by high-quality bony structure segmentation. However, due to significant domain shifts, models perform poorly on data from other centers or probes, and obtaining segmentation labels across devices is impractical due to manual annotation effort and data privacy concerns. To address this, we propose a target-informed self-supervised pretraining and model-ensemble strategy. Specifically, our approach combines masked image modeling (MIM) and contrastive learning to learn target-domain structural representations without labels, and introduces a confidence-aware infusion head to adaptively integrate predictions. The source dataset, collected with a Philips Lumify probe, contained dense labels, while the target dataset, acquired with a TeleMED portable probe, was unlabeled. The datasets were kept strictly separate throughout the entire process. Our method used labeled source data for supervised training and leveraged target-domain pretraining to improve generalization. On 318 images from 62 pediatric POCUS videos, this approach significantly improved cross-device performance, achieving over 6% Dice improvement on the target domain versus the baseline. These results demonstrate a label-efficient and privacy-preserving approach for cross-device-robust ultrasound AI, offering a framework that can be extended to multi-center studies or federated learning setups.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that combining masked image modeling and contrastive self-supervised pretraining on unlabeled target-domain POCUS images (TeleMED probe) with source-supervised training (Philips Lumify probe) and a confidence-aware infusion head plus model ensemble yields >6% Dice improvement on a held-out target set of 318 images from 62 pediatric wrist videos, enabling label-efficient cross-device generalization without target annotations.
Significance. If the empirical result is shown to be driven by the target pretraining rather than the infusion mechanism and is supported by proper controls, the approach would offer a practical privacy-preserving route to domain-robust medical segmentation models. The explicit separation of source and target data and the focus on bony-structure features in ultrasound are strengths that align with real clinical constraints.
major comments (2)
- [Results] Results section: no ablation is reported that removes only the MIM+contrastive pretraining step on the unlabeled target data while retaining the confidence-aware infusion head and ensemble; without this isolation the >6% Dice gain on the 318-image target set cannot be attributed to the learned structural representations as claimed.
- [Results] Results section: the abstract and experimental description supply no information on the baseline model architecture, statistical testing (p-values, confidence intervals, or number of runs), data splits, or whether the 318 images constitute a true held-out test set, leaving the central performance claim weakly supported.
minor comments (1)
- The term 'confidence-aware infusion head' is introduced without an accompanying equation or architectural diagram reference, which reduces clarity for readers attempting to reproduce the adaptive integration step.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on strengthening the attribution of results and experimental details. We address each major comment below.
read point-by-point responses
-
Referee: [Results] Results section: no ablation is reported that removes only the MIM+contrastive pretraining step on the unlabeled target data while retaining the confidence-aware infusion head and ensemble; without this isolation the >6% Dice gain on the 318-image target set cannot be attributed to the learned structural representations as claimed.
Authors: We agree that a dedicated ablation isolating the MIM+contrastive pretraining (while retaining the confidence-aware infusion head and ensemble) would strengthen the claim that the gain is driven by target-domain structural representations. The current manuscript compares the full proposed method against a supervised baseline without any target pretraining, but does not report the exact requested ablation. We will add this ablation study, reporting Dice scores on the 318-image target set, in the revised version. revision: yes
-
Referee: [Results] Results section: the abstract and experimental description supply no information on the baseline model architecture, statistical testing (p-values, confidence intervals, or number of runs), data splits, or whether the 318 images constitute a true held-out test set, leaving the central performance claim weakly supported.
Authors: We acknowledge that these details are insufficiently specified. The baseline is a standard U-Net trained only on labeled source data. The 318 images come from 62 videos that form a strictly held-out target test set (no overlap with source data or any target pretraining). We will revise the experimental section to explicitly state the architecture, confirm the held-out nature of the split, and add statistical testing including p-values, confidence intervals, and results over multiple runs with different random seeds. revision: yes
Circularity Check
No significant circularity; empirical result on held-out data
full rationale
The paper reports a measured >6% Dice improvement on 318 held-out target-domain images from a strictly separate TeleMED dataset. The method description (MIM + contrastive pretraining on unlabeled target data, source-supervised training, confidence-aware infusion head, and ensemble) produces predictions that are evaluated externally rather than being equivalent to inputs by definition, fitted parameters renamed as predictions, or load-bearing self-citations. No equations or steps reduce the reported cross-device performance to a self-referential construction; the outcome remains falsifiable against the external target images.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Unlabeled target-domain ultrasound images contain structural information that masked image modeling and contrastive learning can extract without segmentation labels
invented entities (1)
-
confidence-aware infusion head
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Ghosh, B
S. Ghosh, B. Felfeliyan, Y. Zhou, J. Knight, N. Akhlaq, J. Küpper, A. R. Hareendranathan, J. L. Jaremko, Ultrasound for automated classifica- tion of full-thickness rotator cuff tendon tears using deep learning, in: 2024 46th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), IEEE, 2024, pp. 1–4
2024
-
[2]
Ghosh, B
S. Ghosh, B. Felfeliyan, Y. Zhou, S. Liu, J. Knight, N. Akhlaq, J. Küpper, A. R. Hareendranathan, J. Jaremko, Automated detection of shoulder rotator cuff tendon tears from ultrasound images by cnn- autoencoder, in: 2024 IEEE International Symposium on Biomedical Imaging (ISBI), IEEE, 2024, pp. 1–4
2024
-
[3]
Y. Zhou, A. Rakkunedeth, C. Keen, J. Knight, J. L. Jaremko, Wrist ultrasound segmentation by deep learning, in: International Conference on Artificial Intelligence in Medicine, Springer, 2022, pp. 230–237
2022
-
[4]
S. J. Pan, Q. Yang, A survey on transfer learning, IEEE Transactions on knowledge and data engineering 22 (10) (2009) 1345–1359
2009
-
[5]
Torralba, A
A. Torralba, A. A. Efros, Unbiased look at dataset bias, in: CVPR 2011, IEEE, 2011, pp. 1521–1528
2011
-
[6]
S. B. David, T. Lu, T. Luu, D. Pál, Impossibility theorems for domain adaptation, in: Proceedings of the Thirteenth International Conference onArtificialIntelligenceandStatistics, JMLRWorkshopandConference Proceedings, 2010, pp. 129–136
2010
-
[7]
H. Guan, M. Liu, Domain adaptation for medical image analysis: a sur- vey, IEEE Transactions on Biomedical Engineering 69 (3) (2021) 1173– 1185
2021
-
[8]
Huang, J
L. Huang, J. Zhou, J. Jiao, S. Zhou, C. Chang, Y. Wang, Y. Guo, Stan- dardization of ultrasound images across various centers: M2o-diffgan 31 bridging the gaps among unpaired multi-domain ultrasound images, Medical Image Analysis 95 (2024) 103187
2024
-
[9]
D. Wu, D. Smith, B. VanBerlo, A. Roshankar, H. Lee, B. Li, F. Ali, M. Rahman, J. Basmaji, J. Tschirhart, et al., Improving the general- izability and performance of an ultrasound deep learning model using limited multicenter data for lung sliding artifact identification, Diagnos- tics 14 (11) (2024) 1081
2024
-
[10]
Brudvik, L
C. Brudvik, L. M. Hove, Childhood fractures in bergen, norway: identi- fying high-risk groups and activities, Journal of pediatric orthopaedics 23 (5) (2003) 629–634
2003
-
[11]
E. M. Hedström, O. Svensson, U. Bergström, P. Michno, Epidemiol- ogy of fractures in children and adolescents: Increased incidence over the past decade: a population-based study from northern sweden, Acta orthopaedica 81 (1) (2010) 148–153
2010
-
[12]
C. Zhu, X. Wang, M. Liu, X. Liu, J. Chen, G. Liu, G. Ji, Non-surgical vs. surgical treatment of distal radius fractures: a meta-analysis of ran- domized controlled trials, BMC surgery 24 (1) (2024) 205
2024
-
[13]
H. C. Bäcker, C. H. Wu, R. J. Strauch, Systematic review of diagnosis of clinically suspected scaphoid fractures, Journal of wrist surgery 9 (01) (2020) 081–089
2020
-
[14]
URLhttps://www.cihi.ca/en/nacrs-emergency-department-visits-and-lengths-of-stay
Canadian Institute for Health Information, Nacrs emergency depart- ment visits and lengths of stay, accessed: February 3, 2026 (2024). URLhttps://www.cihi.ca/en/nacrs-emergency-department-visits-and-lengths-of-stay
2026
-
[15]
Slaar, M
A. Slaar, M. M. Walenkamp, A. Bentohami, M. Maas, R. R. van Rijn, E. W. Steyerberg, L. C. Jager, N. L. Sosef, R. van Velde, J. M. Ultee, et al., A clinical decision rule for the use of plain radiography in children after acute wrist injury: development and external validation of the amsterdam pediatric wrist rules, Pediatric radiology 46 (1) (2016) 50– 60
2016
-
[16]
Knight, Y
J. Knight, Y. Zhou, C. Keen, A. R. Hareendranathan, F. Alves-Pereira, S. Ghasseminia, S. Wichuk, A. Brilz, D. Kirschner, J. Jaremko, 2d/3d ultrasound diagnosis of pediatric distal radius fractures by human read- ers vs artificial intelligence, Scientific Reports 13 (1) (2023) 14535. 32
2023
-
[17]
Y. Zhou, J. Knight, F. Alves-Pereira, C. Keen, A. R. Hareendranathan, J. L. Jaremko, Wrist and elbow fracture detection and segmentation by artificial intelligence using point-of-care ultrasound, Journal of Ultra- sound (2025) 1–9
2025
-
[18]
L. B. Chartier, L. Bosco, L. Lapointe-Shaw, J. Chenkin, Use of point-of- care ultrasound in long bone fractures: a systematic review and meta- analysis, Canadian Journal of Emergency Medicine 19 (2) (2017) 131– 142
2017
-
[19]
Pinto-Coelho, How artificial intelligence is shaping medical imaging technology: a survey of innovations and applications, Bioengineering 10 (12) (2023) 1435
L. Pinto-Coelho, How artificial intelligence is shaping medical imaging technology: a survey of innovations and applications, Bioengineering 10 (12) (2023) 1435
2023
-
[20]
Di Cosmo, M
M. Di Cosmo, M. C. Fiorentino, F. P. Villani, E. Frontoni, G. Smerilli, E. Filippucci, S. Moccia, A deep learning approach to median nerve eval- uation in ultrasound images of carpal tunnel inlet, Medical & Biological Engineering & Computing 60 (11) (2022) 3255–3264
2022
-
[21]
Smerilli, E
G. Smerilli, E. Cipolletta, G. Sartini, E. Moscioni, M. Di Cosmo, M. C. Fiorentino, S. Moccia, E. Frontoni, W. Grassi, E. Filippucci, Develop- ment of a convolutional neural network for the identification and the measurement of the median nerve on ultrasound images acquired at carpal tunnel level, Arthritis Research & Therapy 24 (1) (2022) 38
2022
-
[22]
Du Toit, N
C. Du Toit, N. Orlando, S. Papernick, R. Dima, I. Gyacskov, A. Fenster, Automatic femoral articular cartilage segmentation using deep learning in three-dimensional ultrasound images of the knee, Osteoarthritis and Cartilage Open 4 (3) (2022) 100290
2022
-
[23]
Marzola, N
F. Marzola, N. Van Alfen, J. Doorduin, K. M. Meiburger, Deep learning segmentation of transverse musculoskeletal ultrasound images for neu- romuscular disease assessment, Computers in biology and medicine 135 (2021) 104623
2021
-
[24]
Lee, H.-U
S.-W. Lee, H.-U. Ye, K.-J. Lee, W.-Y. Jang, J.-H. Lee, S.-M. Hwang, Y.- R. Heo, Accuracy of new deep learning model-based segmentation and key-point multi-detection method for ultrasonographic developmental dysplasia of the hip (ddh) screening, Diagnostics 11 (7) (2021) 1174. 33
2021
-
[25]
Hemalatha, V
R. Hemalatha, V. Vijaybaskar, T. Thamizhvani, Automatic localiza- tion of anatomical regions in medical ultrasound images of rheumatoid arthritis using deep learning, Proceedings of the Institution of Mechani- cal Engineers, Part H: Journal of Engineering in Medicine 233 (6) (2019) 657–667
2019
-
[26]
J. Lyu, X. Bi, S. Banerjee, Z. Huang, F. H. Leung, T. T.-Y. Lee, D.-D. Yang, Y.-P. Zheng, S. H. Ling, Dual-task ultrasound spine transverse vertebrae segmentation network with contour regularization, Comput- erized Medical Imaging and Graphics 89 (2021) 101896
2021
-
[27]
A. Z. Alsinan, V. M. Patel, I. Hacihaliloglu, Automatic segmentation of bone surfaces from ultrasound using a filter-layer-guided cnn, Interna- tional journal of computer assisted radiology and surgery 14 (5) (2019) 775–783
2019
-
[28]
K. Luan, Z. Li, J. Li, An efficient end-to-end cnn for segmentation of bone surfaces from ultrasound, Computerized Medical Imaging and Graphics 84 (2020) 101766
2020
-
[29]
P. Wang, M. Vives, V. M. Patel, I. Hacihaliloglu, Robust real-time bone surfaces segmentation from ultrasound using a local phase tensor-guided cnn, International Journal of Computer Assisted Radiology and Surgery 15 (7) (2020) 1127–1135
2020
-
[30]
Zoetmulder, E
R. Zoetmulder, E. Gavves, M. Caan, H. Marquering, Domain-and task- specific transfer learning for medical segmentation tasks, Computer Methods and Programs in Biomedicine 214 (2022) 106539
2022
-
[31]
Ghafoorian, A
M. Ghafoorian, A. Mehrtash, T. Kapur, N. Karssemeijer, E. Mar- chiori, M. Pesteie, C. R. Guttmann, F.-E. De Leeuw, C. M. Tempany, B. Van Ginneken, et al., Transfer learning for domain adaptation in mri: Application in brain lesion segmentation, in: International conference on medical image computing and computer-assisted intervention, Springer, 2017, pp. 516–524
2017
-
[32]
Zhang, J
P. Zhang, J. Li, Y. Wang, J. Pan, Domain adaptation for medical image segmentation: a meta-learning method, Journal of Imaging 7 (2) (2021) 31. 34
2021
-
[33]
H. Yang, W. Hua, Z. Xu, J. Sun, Domain-generalized discrete diffusion model for cross-domain medical image segmentation, IEEE Transactions on Medical Imaging (2025)
2025
-
[34]
G. Zeng, T. D. Lerch, F. Schmaranzer, G. Zheng, J. Burger, K. Gerber, M. Tannast, K. Siebenrock, N. Gerber, Semantic consistent unsuper- vised domain adaptation for cross-modality medical image segmenta- tion, in: International Conference on Medical Image Computing and Computer-Assisted Intervention, Springer, 2021, pp. 201–210
2021
-
[35]
R. Wang, G. Zheng, Cycmis: Cycle-consistent cross-domain medical im- age segmentation via diverse image augmentation, Medical Image Anal- ysis 76 (2022) 102328
2022
-
[36]
Jiang, T
K. Jiang, T. Gong, L. Quan, A medical unsupervised domain adapta- tion framework based on fourier transform image translation and multi- model ensemble self-training strategy, International Journal of Com- puter Assisted Radiology and Surgery 18 (10) (2023) 1885–1894
2023
-
[37]
Kirillov, E
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo, et al., Segment anything, in: Proceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4015–4026
2023
-
[38]
P. Shi, J. Qiu, S. M. D. Abaxi, H. Wei, F. P.-W. Lo, W. Yuan, Generalist vision foundation models for medical imaging: A case study of segment anything model on zero-shot medical segmentation, Diagnostics 13 (11) (2023) 1947
2023
-
[39]
J. Ma, Y. He, F. Li, L. Han, C. You, B. Wang, Segment anything in medical images, Nature Communications 15 (1) (2024) 654
2024
-
[40]
Noh, B.-D
S. Noh, B.-D. Lee, A narrative review of foundation models for med- ical image segmentation: zero-shot performance evaluation on diverse modalities, Quantitative Imaging in Medicine and Surgery 15 (6) (2025) 5825
2025
-
[41]
H. Ning, Q. He, T. Lei, X. Cao, W. Zhang, Y. Chen, A. K. Nandi, Da 2- net: Integrating sam2 with domain adaption and difference aggregation for remote sensing change detection, IEEE Transactions on Geoscience and Remote Sensing (2025). 35
2025
-
[42]
A cookbook of self-supervised learning,
R. Balestriero, M. Ibrahim, V. Sobal, A. Morcos, S. Shekhar, T. Gold- stein, F. Bordes, A. Bardes, G. Mialon, Y. Tian, et al., A cookbook of self-supervised learning, arXiv preprint arXiv:2304.12210 (2023)
-
[43]
D. Wolf, T. Payer, C. S. Lisson, C. G. Lisson, M. Beer, M. Götz, T. Ropinski, Self-supervised pre-training with contrastive and masked autoencoder methods for dealing with small datasets in deep learning for medical imaging, Scientific Reports 13 (1) (2023) 20260
2023
-
[44]
T. Chen, S. Kornblith, M. Norouzi, G. Hinton, A simple framework for contrastive learning of visual representations, in: International confer- ence on machine learning, PmLR, 2020, pp. 1597–1607
2020
-
[45]
K. He, H. Fan, Y. Wu, S. Xie, R. Girshick, Momentum contrast for unsupervised visual representation learning, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 9729–9738
2020
-
[46]
Grill, F
J.-B. Grill, F. Strub, F. Altché, C. Tallec, P. Richemond, E.Buchatskaya, C.Doersch, B.AvilaPires, Z.Guo, M.GheshlaghiAzar, et al., Bootstrap your own latent-a new approach to self-supervised learning, Advances in neural information processing systems 33 (2020) 21271–21284
2020
-
[47]
X. Chen, K. He, Exploring simple siamese representation learning, in: Proceedings of the IEEE/CVF conference on computer vision and pat- tern recognition, 2021, pp. 15750–15758
2021
-
[48]
G. E. Hinton, R. R. Salakhutdinov, Reducing the dimensionality of data with neural networks, science 313 (5786) (2006) 504–507
2006
-
[49]
Larsson, M
G. Larsson, M. Maire, G. Shakhnarovich, Colorization as a proxy task for visual understanding, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 6874–6883
2017
-
[50]
K. He, X. Chen, S. Xie, Y. Li, P. Dollár, R. Girshick, Masked autoen- coders are scalable vision learners, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 16000– 16009. 36
2022
-
[51]
9653–9663
Z.Xie, Z.Zhang, Y.Cao, Y.Lin, J.Bao, Z.Yao, Q.Dai, H.Hu, Simmim: A simple framework for masked image modeling, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 9653–9663
2022
-
[52]
Zheng, J
H. Zheng, J. Han, H. Wang, L. Yang, Z. Zhao, C. Wang, D. Z. Chen, Hi- erarchical self-supervised learning for medical image segmentation based on multi-domain data aggregation, in: International conference on medi- calimagecomputingandcomputer-assistedintervention, Springer, 2021, pp. 622–632
2021
-
[53]
V. Bundele, K. Sarıtaş, B. Kargi, O. A. Çal, K. Tezören, Z. Ghaderi, H. Lensch, Evaluating self-supervised learning in medical imaging: A benchmark for robustness, generalizability, and multi-domain impact, arXiv preprint arXiv:2412.19124 (2024)
-
[54]
Y. He, A. Carass, L. Zuo, B. E. Dewey, J. L. Prince, Autoencoder based self-supervised test-time adaptation for medical image analysis, Medical image analysis 72 (2021) 102136
2021
-
[55]
S. B. Ali, N. E. Ghannam, H. Mancy, B. G. Elkilany, Multimodal self- supervised learning for early alzheimer’s: Cross-modal mri–pet, longi- tudinal signals, and site invariance, Diagnostics 15 (24) (2025) 3135
2025
-
[56]
Anton, L
J. Anton, L. Castelli, M. F. Chan, M. Outters, W. H. Tang, V. Cheung, P. Shukla, R. Walambe, K. Kotecha, How well do self-supervised models transfer to medical imaging?, Journal of Imaging 8 (12) (2022) 320
2022
-
[57]
J. Chen, Y. Lu, Q. Yu, X. Luo, E. Adeli, Y. Wang, L. Lu, A. L. Yuille, Y. Zhou, Transunet: Transformers make strong encoders for medical image segmentation, arXiv preprint arXiv:2102.04306 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[58]
Y. Zhou, B. Felfeliyan, S. Ghosh, J. Knight, F. Alves-Pereira, C. Keen, J. Küpper, A. R. Hareendranathan, J. L. Jaremko, Simicl: A simple visual in-context learning framework for ultrasound segmentation, in: 2024 46th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), IEEE, 2024, pp. 1–4. 37
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.