Diagnosing Harmful Continuation in Answer-Correct Long-CoT Training Traces
Pith reviewed 2026-06-29 07:24 UTC · model grok-4.3
The pith
Removing post-conclusion continuation from answer-correct long-CoT traces improves SFT outcomes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
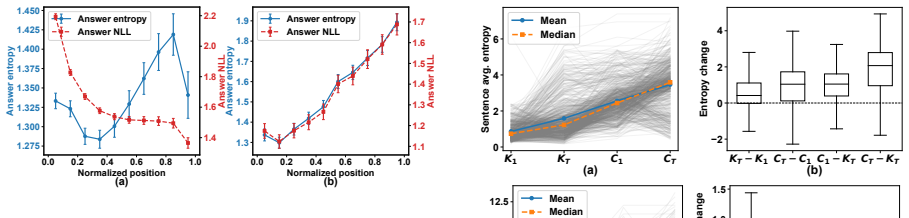
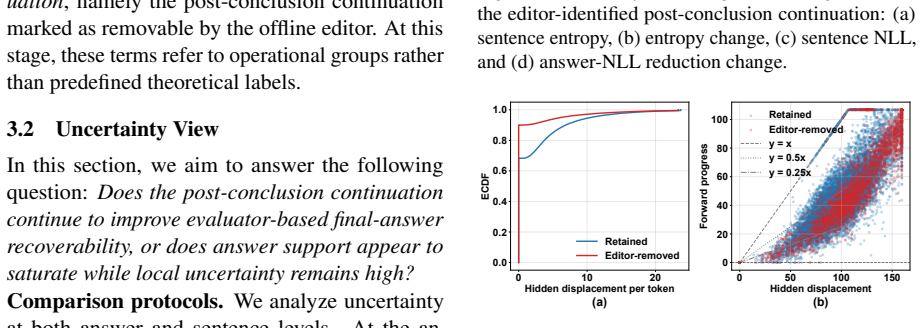
The paper establishes that post-conclusion continuation in answer-correct long-CoT traces is harmful to SFT training. Removing these continuations via answer-preserving suffix deletion produces improved fine-tuning outcomes. The removed segments show persistent local uncertainty together with weakened terminal-directional progress, forming an uncertainty-geometry mismatch. A lightweight boundary proxy called Harmful Continuation Cut approximates the editor-identified boundary.
What carries the argument
A delete-only editor that constructs answer-preserving suffix removal to isolate and test the effect of post-conclusion continuation.
If this is right
- SFT on traces without post-conclusion continuation yields improved reasoning performance.
- Data curation pipelines for CoT supervision should detect and remove such continuations.
- The uncertainty-geometry mismatch offers a diagnostic for identifying low-value segments in reasoning traces.
- Harmful Continuation Cut provides a scalable proxy for boundary detection without full editor intervention.
Where Pith is reading between the lines
- Automatic detection tools built on the HCC proxy could enable large-scale cleaning of existing CoT datasets.
- The same continuation pattern may degrade performance in other training methods that rely on full trace supervision.
- Similar uncertainty-progress mismatches could serve as a general signal for data quality issues across model training.
Load-bearing premise
The delete-only editor removes only the post-conclusion continuation and does not introduce other systematic changes that explain the SFT improvement.
What would settle it
Training models on the original versus edited traces and observing no consistent gain in downstream reasoning accuracy after removal would falsify the claim that the continuation is harmful.
Figures





read the original abstract
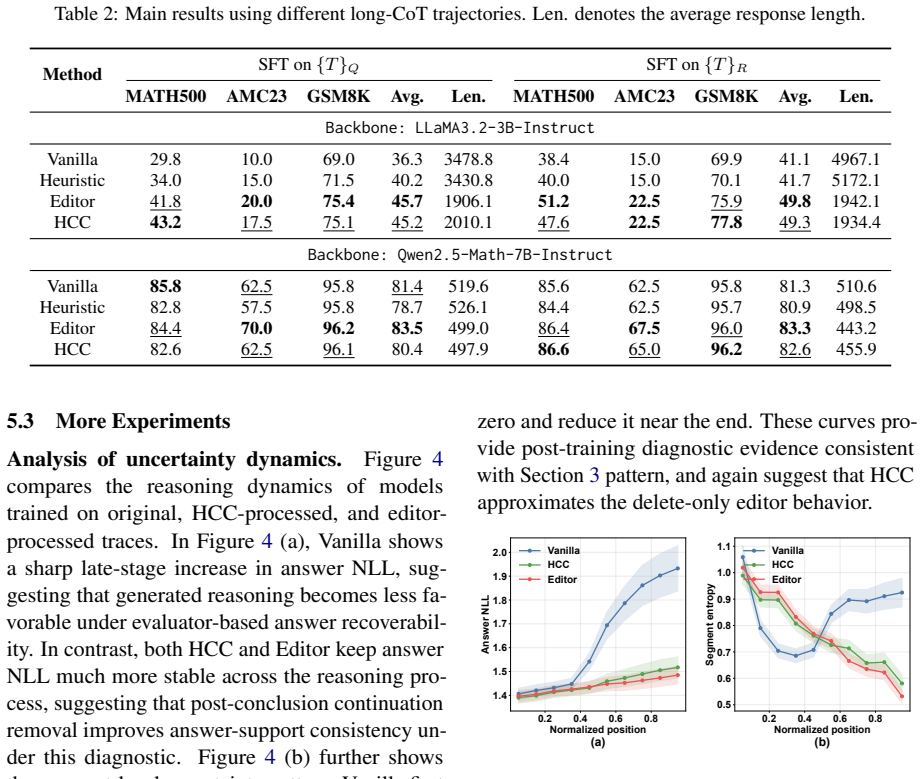
Long chain-of-thought (CoT) traces are widely used as supervision for reasoning-oriented LLM SFT, yet answer-correct traces can still lead to markedly different fine-tuning outcomes. We study post-conclusion continuation in answer-correct long-CoT data: a continuation where the answer appears sufficiently supported, but the trace continues with additional reasoning that remains in the supervised target. To test its training effect, we use a delete-only editor to construct answer-preserving suffix removal and compare CoT-based SFT on the original and processed traces. We observe improved SFT outcomes after removing the editor-identified post-conclusion continuation, suggesting that this continuation is harmful to training in our setting. We therefore refer to this empirically supported phenomenon as harmful continuation. Beyond this intervention, we further characterize the removed post-conclusion continuation through uncertainty and hidden-state progress. We observe persistent local uncertainty together with weakened terminal-directional progress, forming an uncertainty--geometry mismatch. Finally, we instantiate Harmful Continuation Cut (HCC), a lightweight boundary proxy that approximates the editor-identified post-conclusion continuation boundary.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that answer-correct long-CoT traces contain post-conclusion continuation that harms downstream SFT performance. It constructs processed traces via a delete-only, answer-preserving editor that excises this suffix, reports improved SFT outcomes relative to the original traces, characterizes the excised segments via persistent local uncertainty combined with weakened terminal-directional hidden-state progress (an uncertainty-geometry mismatch), and introduces Harmful Continuation Cut (HCC) as a lightweight boundary proxy.
Significance. If the central empirical result holds after proper controls and reporting, the work would be significant for reasoning-oriented LLM training pipelines: it isolates a specific, removable defect in otherwise correct CoT supervision that measurably degrades fine-tuning, supplies a practical editor and a cheap proxy (HCC), and links the defect to measurable uncertainty and geometry signals. These elements could directly inform data-cleaning practices without architectural changes.
major comments (2)
- [Abstract] Abstract: the central claim of 'improved SFT outcomes' after editor intervention is stated without any quantitative results (accuracy deltas, dataset sizes, number of traces, baselines, error bars, or statistical tests), so the magnitude, reliability, and reproducibility of the effect cannot be evaluated.
- [Abstract] Abstract (description of delete-only editor and 'answer-preserving suffix removal'): no verification is supplied that the only systematic difference between original and processed traces is excision of the post-conclusion continuation. Absent token-level diff statistics, length-distribution comparisons, EOS-placement checks, or control removals of matched-length non-terminal segments, incidental artifacts (shorter targets, changed tokenization boundaries) could explain any SFT delta independently of the claimed harmful continuation.
minor comments (1)
- The phrase 'uncertainty--geometry mismatch' is used to characterize the removed segments but is not given an explicit operational definition or formula in the abstract; a precise quantification (e.g., how terminal-directional progress is measured in hidden states) would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and rigor where the points identify gaps.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'improved SFT outcomes' after editor intervention is stated without any quantitative results (accuracy deltas, dataset sizes, number of traces, baselines, error bars, or statistical tests), so the magnitude, reliability, and reproducibility of the effect cannot be evaluated.
Authors: We agree that the abstract would benefit from quantitative indicators to allow immediate evaluation of the effect. While the body of the paper reports accuracy deltas on reasoning benchmarks, dataset sizes (number of traces), baselines, and error bars with statistical tests, the abstract omits them for brevity. In revision we will incorporate key quantitative results (e.g., accuracy improvements, trace counts, and significance) directly into the abstract. revision: yes
-
Referee: [Abstract] Abstract (description of delete-only editor and 'answer-preserving suffix removal'): no verification is supplied that the only systematic difference between original and processed traces is excision of the post-conclusion continuation. Absent token-level diff statistics, length-distribution comparisons, EOS-placement checks, or control removals of matched-length non-terminal segments, incidental artifacts (shorter targets, changed tokenization boundaries) could explain any SFT delta independently of the claimed harmful continuation.
Authors: This concern is valid and highlights a need for stronger controls. The current description in the abstract does not include explicit verification. We will add, in a revised methods or appendix section, token-level diff statistics, length-distribution comparisons, EOS-placement checks, and a control experiment that removes matched-length non-terminal segments. These additions will demonstrate that performance differences arise specifically from post-conclusion removal rather than length or boundary artifacts. revision: yes
Circularity Check
No significant circularity; empirical intervention is self-contained
full rationale
The paper's core claim rests on constructing answer-preserving suffix removals via a delete-only editor and measuring downstream SFT deltas between original and edited traces. This is an external intervention whose effect is evaluated against held-out training outcomes rather than being defined into existence or recovered from fitted parameters. No equations appear, no self-citation chain supplies a uniqueness theorem or ansatz, and the subsequent uncertainty/geometry characterization plus HCC proxy are presented as observational descriptions, not derivations that loop back to the editor output by construction. The derivation chain therefore remains independent of its inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
First 3 hours at 60 mph: - Distance covered: \(60 \, \text{mph} \times 3 \, \text{hours} = 180 \, \text{miles}\)- He is 180 miles away from home
-
[2]
Stuck in traffic for 2 hours: - No movement, so he remains 180 miles away from home
-
[3]
Driving at 30 mph for 0.5 hours: - Distance covered: \(30 \, \text{mph} \times 0.5 \, \text{hours} = 15 \, \text{miles}\)- New distance from home: \(180 \, \text{miles} - 15 \, \text{miles} = 165 \, \text{miles}\)
-
[4]
Therefore, the total distance from home is 195 + 120 = 315 miles.Wait, but hold on
Driving at 80 mph for the remaining 1.5 hours: - Distance covered: \(80 \, \text{mph} \times 1.5 \, \text{hours} = 120 \, \text{miles}\)- Final distance from home: \(165 \, \text{miles} - 120 \, \text{miles} = 45 \, \text{miles}\) <think>...So, the distance he covers in 1.5 hours is 80 * 1.5 = 120 miles. Therefore, the total distance from home is 195 + 12...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.