TC-MIS: Maximal Independent Set on Tensor-cores
Pith reviewed 2026-06-29 05:47 UTC · model grok-4.3
The pith
Reformulating maximal independent set computation as sparse matrix-vector multiplications allows tensor cores to accelerate the process on GPUs while preserving solution quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
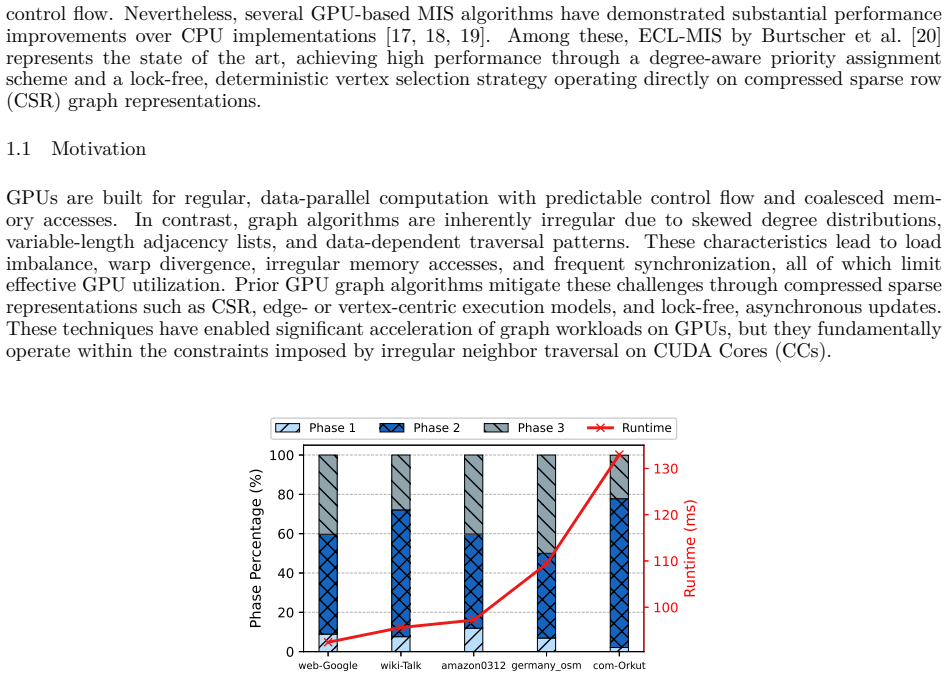
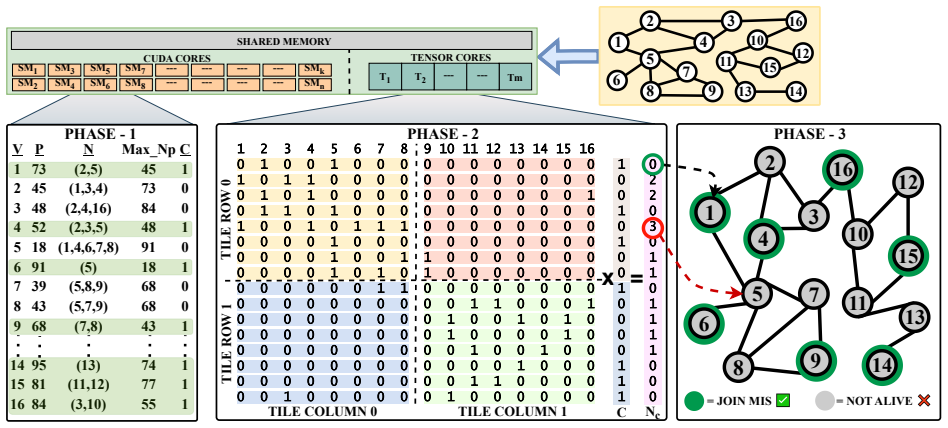
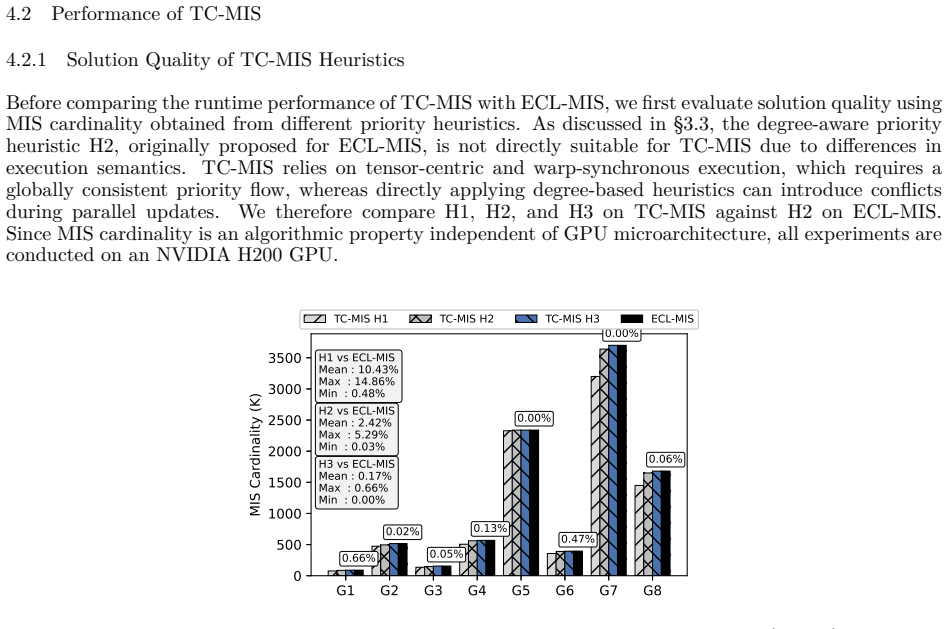
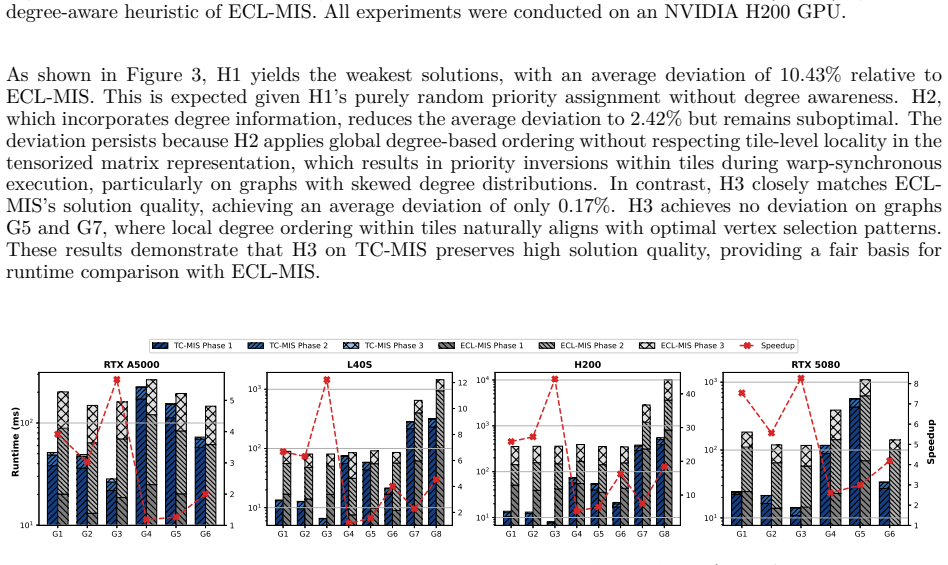
TC-MIS reformulates key MIS phases as SpMV operations executed via WMMA on tensor cores. The adjacency matrix is tiled so that the irregular traversal of the graph becomes regular, massively parallel matrix arithmetic. This yields measured average speedups of 2.84x on RTX A5000, 4.84x on L40S, 18.80x on H200, and 5.20x on RTX 5080, with a peak of 44.38x on H200, while the independent sets match the quality of near-maximum heuristics.
What carries the argument
The WMMA-driven SpMV reformulation of MIS phases that tiles the adjacency matrix and executes irregular graph steps as regular tensor-core matrix operations.
If this is right
- Million-vertex graphs become processable in milliseconds on tensor-core GPUs for scheduling and allocation tasks.
- Tensor cores previously reserved for machine learning become usable for graph algorithms without loss of solution quality.
- The same tiling and WMMA approach can be applied across Ampere through Blackwell microarchitectures with consistent speedups.
- Established MIS heuristics can be replaced by the faster tensor-core version in performance-critical pipelines.
Where Pith is reading between the lines
- Other graph problems whose traversals can be cast as sparse matrix operations may also benefit from tensor-core execution.
- Hardware designs that increase tensor-core throughput relative to CUDA cores would amplify gains for this class of algorithms.
- The method invites hybrid implementations that fall back to CUDA cores only when tensor cores are unavailable.
Load-bearing premise
The reformulation of MIS phases as SpMV via WMMA on tensor cores produces sets that remain independent and maximal without any selection bias or later corrections.
What would settle it
Execute TC-MIS on a small, well-known graph whose maximal independent sets are enumerated exhaustively; if the output set contains adjacent vertices or is not maximal, the correctness claim fails.
Figures
read the original abstract
Maximal Independent Set (MIS) in a graph is a fundamental problem with applications in resource allocation, scheduling, and network optimization. Although graphs are inherently un-structured and challenging for GPU parallelism due to irregular memory access and workload imbalance, specialized GPU algorithms have achieved good performance, processing million-vertex graphs in milliseconds. Modern GPUs are equipped with Tensor Cores (TCs), specialized units for matrix operations with 8-16x higher throughput than CUDA Cores (CCs), which are extensively used for ML, DL, and inference tasks but remain largely unexplored for graph algorithms. In this paper, we present TC-MIS, a TC-accelerated algorithm that reformulates key phases of MIS computation as sparse matrix-vector multiplication (SpMV). TC-MIS tiles the graph adjacency matrix and employs Warp Matrix Multiply-Accumulate (WMMA) operations to transform irregular graph traversal into regular, massively parallel computation. Our evaluation across TC-enabled microarchitectures (Ampere, Ada Lovelace, Hopper, Blackwell) demonstrates that TC-MIS achieves an average speedup of 2.84x on RTX A5000, 4.84x on L40S, 18.80x on H200 GPUs, and 5.20x on RTX 5080 with a maximum speedup of 44.38x on H200 GPU over state-of-the-art methods, while maintaining solution quality comparable to that obtained by established heuristics that produce near-maximum independent sets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TC-MIS, which reformulates phases of Maximal Independent Set computation (neighbor marking, degree computation, vertex selection) as sparse matrix-vector multiplications executed via WMMA on GPU Tensor Cores. It reports average speedups of 2.84x (RTX A5000), 4.84x (L40S), 18.80x (H200), and 5.20x (RTX 5080) with a maximum of 44.38x on H200 over state-of-the-art methods, while asserting that solution quality remains comparable to established heuristics producing near-maximum independent sets.
Significance. If the precision and verification concerns are resolved, the work would be significant for demonstrating tensor-core acceleration of irregular graph algorithms beyond ML workloads. The multi-generation evaluation (Ampere through Blackwell) is a concrete strength that supports claims of broad applicability.
major comments (3)
- [Abstract] Abstract: the claim that 'solution quality [is] comparable to that obtained by established heuristics' provides no quantitative metrics (e.g., independent-set cardinality relative to known maxima or to the baselines), no named heuristics, and no verification that the output satisfies independence and maximality; this is load-bearing for the central empirical claim.
- [Abstract] Abstract: the reported speedups lack any description of the concrete state-of-the-art baselines, graph datasets, or timing methodology (including whether SpMV mapping overhead or post-processing is included), rendering the 18.80x average on H200 and 44.38x maximum impossible to assess.
- [Abstract] Abstract (reformulation description): the mapping of MIS phases to SpMV via WMMA does not address or empirically test whether FP16/TF32 reduced-precision accumulation on 0/1 adjacency data can alter selection decisions relative to exact integer arithmetic, which directly risks violating the independence or maximality invariants.
minor comments (1)
- [Abstract] The abstract would be clearer if the per-architecture speedup figures were presented in a small table rather than a single sentence.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the abstract accordingly to provide the requested details while preserving the manuscript's core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'solution quality [is] comparable to that obtained by established heuristics' provides no quantitative metrics (e.g., independent-set cardinality relative to known maxima or to the baselines), no named heuristics, and no verification that the output satisfies independence and maximality; this is load-bearing for the central empirical claim.
Authors: We agree the abstract should be more explicit. The full manuscript already reports quantitative comparisons (cardinality ratios to baselines and known optima on standard graphs) and verifies independence/maximality via post-processing. In revision we will add a concise summary of these metrics and name the heuristics (e.g., the GPU baselines from prior work) directly in the abstract. revision: yes
-
Referee: [Abstract] Abstract: the reported speedups lack any description of the concrete state-of-the-art baselines, graph datasets, or timing methodology (including whether SpMV mapping overhead or post-processing is included), rendering the 18.80x average on H200 and 44.38x maximum impossible to assess.
Authors: We acknowledge the abstract is insufficiently detailed on methodology. The experimental section specifies the baselines, the full set of graphs (SNAP/SuiteSparse collections), and that all timings include SpMV overhead plus post-processing. We will incorporate a brief description of these elements into the revised abstract. revision: yes
-
Referee: [Abstract] Abstract (reformulation description): the mapping of MIS phases to SpMV via WMMA does not address or empirically test whether FP16/TF32 reduced-precision accumulation on 0/1 adjacency data can alter selection decisions relative to exact integer arithmetic, which directly risks violating the independence or maximality invariants.
Authors: This concern is valid. While the manuscript's end-to-end results showed no violations of the invariants across tested graphs, we did not include a dedicated precision-sensitivity experiment. In the revision we will add a short discussion plus a targeted comparison (TC-MIS vs. FP32 fallback on a representative subset) confirming that reduced-precision accumulation does not change selection decisions for 0/1 adjacency data. revision: yes
Circularity Check
No circularity: empirical algorithm with direct measurements
full rationale
The paper describes an algorithmic reformulation of MIS phases into SpMV operations executed via WMMA on tensor cores, followed by empirical timing and quality measurements across GPU architectures. No equations or claims reduce a result to its own inputs by construction. No parameters are fitted on a subset and then presented as predictions. No load-bearing self-citations or uniqueness theorems imported from prior author work are present in the abstract or description. The speedups and quality comparisons are reported as direct experimental outcomes on specific hardware, which are externally falsifiable. This matches the default expectation of a non-circular empirical systems paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Graphs can be represented as adjacency matrices suitable for SpMV operations without altering independent-set properties.
Reference graph
Works this paper leans on
-
[1]
Garey and David S
Michael R. Garey and David S. Johnson. Computers and Intractability; A Guide to the Theory of NP-Completeness. W. H. Freeman & Co., USA, 1990
1990
-
[2]
A simple parallel algorithm for the maximal independent set problem
Michael Luby. A simple parallel algorithm for the maximal independent set problem. SIAM Journal on Computing, 15(4):1036–1053, 1986
1986
-
[3]
Minimal resources for fixed and variable job schedules
Ilya Gertsbakh and Helman I Stern. Minimal resources for fixed and variable job schedules. Operations Research, 26(1):68–85, 1978. 9
1978
-
[4]
Selection of representative protein data sets
Uwe Hobohm, Michael Scharf, Reinhard Schneider, and Chris Sander. Selection of representative protein data sets. Protein Science, 1(3):409–417, 1992
1992
-
[5]
Karp and A vi Wigderson
Richard M. Karp and A vi Wigderson. A fast parallel algorithm for the maximal independent set problem. J. ACM, 32(4):762–773, oct 1985
1985
-
[6]
Finding a maximum independent set
Robert Endre Tarjan and Anthony E Trojanowski. Finding a maximum independent set. SIAM Journal on Computing, 6(3):537–546, 1977
1977
-
[7]
An improved distributed algorithm for maximal independent set
Mohsen Ghaffari. An improved distributed algorithm for maximal independent set. Proceedings of the twenty-seventh annual ACM-SIAM symposium on Discrete algorithms, pages 270–277, 2016
2016
-
[8]
Im- proved massively parallel computation algorithms for mis, matching, and vertex cover
Mohsen Ghaffari, Themis Gouleakis, Christian Konrad, Slobodan Mitrovic, and Ronitt Rubinfeld. Im- proved massively parallel computation algorithms for mis, matching, and vertex cover. In Proceedings of the 37th ACM SIGMOD-SIGACT-SIGAI Symposium on Principles of Database Systems, pages 129– 139, 2018
2018
-
[9]
A new algorithm for generating all the maximal independent sets
Shuji Tsukiyama, Mikio Ide, Hiromu Ariyoshi, and Isao Shirakawa. A new algorithm for generating all the maximal independent sets. SIAM Journal on Computing, 6(3):505–517, 1977
1977
-
[10]
Community structure in social and biological networks
Michelle Girvan and Mark EJ Newman. Community structure in social and biological networks. Pro- ceedings of the National Academy of Sciences, 99(12):7821–7826, 2002
2002
-
[11]
Emergence of scaling in random networks
Albert-László Barabási and Réka Albert. Emergence of scaling in random networks. Science, 286(5439):509–512, 1999
1999
-
[12]
Graph neural networks for wireless commu- nications: From theory to practice
Yifei Shen, Jun Zhang, SH Song, and Khaled B Letaief. Graph neural networks for wireless commu- nications: From theory to practice. IEEE Transactions on Wireless Communications, 22(5):3554–3569, 2022
2022
-
[13]
The structure and function of complex networks
Mark EJ Newman. The structure and function of complex networks. SIAM Review, 45(2):167–256, 2003
2003
-
[14]
A simple parallel algorithm for the maximal independent set problem
Michael Luby. A simple parallel algorithm for the maximal independent set problem. In Proceedings of the 17th Annual ACM Symposium on Theory of Computing (STOC’85), pages 1–10, New York, NY,
-
[15]
Recent advances in fully dynamic graph algorithms – a quick reference guide
Kathrin Hanauer, Monika Henzinger, and Christian Schulz. Recent advances in fully dynamic graph algorithms – a quick reference guide. ACM J. Exp. Algorithmics, 27, dec 2022
2022
-
[16]
Graph stream algorithms: a survey
Andrew McGregor. Graph stream algorithms: a survey. ACM SIGMOD Record, 43(1):9–20, 2014
2014
-
[17]
Cusp: Generic parallel algorithms for sparse matrix and graph computations
Nathan Bell and Michael Garland. Cusp: Generic parallel algorithms for sparse matrix and graph computations. http://cusplibrary.github.io/, 2009. Accessed: August 28, 2015
2009
-
[18]
Pannotia: Understanding irregular gpgpu graph applications
Shuai Che, Bradford M Beckmann, Steven K Reinhardt, and Kevin Skadron. Pannotia: Understanding irregular gpgpu graph applications. In 2013 IEEE International Symposium on Workload Characteri- zation (IISWC), pages 185–195. IEEE, 2013
2013
-
[19]
A compiler for throughput optimization of graph algorithms on gpus
Sreepathi Pai and Keshav Pingali. A compiler for throughput optimization of graph algorithms on gpus. In Proceedings of the 2016 ACM SIGPLAN International Conference on Object-Oriented Programming, Systems, Languages, and Applications, pages 1–19, 2016
2016
-
[20]
A high-quality and fast maximal independent set implementation for GPUs
Martin Burtscher, Sindhu Devale, Sahar Azimi, Jayadharini Jaiganesh, and Evan Powers. A high-quality and fast maximal independent set implementation for GPUs. ACM Transactions on Parallel Computing (TOPC), 5(2):1–27, 2018
2018
-
[21]
A fast and simple randomized parallel algorithm for the maximal independent set problem
Noga Alon, László Babai, and Alon Itai. A fast and simple randomized parallel algorithm for the maximal independent set problem. Journal of algorithms, 7(4):567–583, 1986
1986
-
[22]
MIS on trees
Christoph Lenzen and Roger Wattenhofer. MIS on trees. In Proceedings of the 30th ACM SIGACT- SIGOPS Symposium on Principles of Distributed Computing, pages 41–48, 2011
2011
-
[23]
The combinatorial blas: Design, implementation, and applications
Aydın Buluç and John R Gilbert. The combinatorial blas: Design, implementation, and applications. The International Journal of High Performance Computing Applications, 25(4):496–509, 2011
2011
-
[24]
Combinatorial blas 2.0: Scaling combinatorial algorithms on distributed-memory systems
Ariful Azad, Oguz Selvitopi, Md Taufique Hussain, John R Gilbert, and Aydın Buluç. Combinatorial blas 2.0: Scaling combinatorial algorithms on distributed-memory systems. IEEE Transactions on Parallel and Distributed Systems, 33(4):989–1001, 2021
2021
-
[25]
Mathematical foundations of the graphblas
Jeremy Kepner, Peter Aaltonen, David Bader, Aydin Buluç, Franz Franchetti, John Gilbert, Dylan Hutchison, Manoj Kumar, Andrew Lumsdaine, Henning Meyerhenke, et al. Mathematical foundations of the graphblas. In 2016 IEEE High Performance Extreme Computing Conference (HPEC), pages 1–9. IEEE, 2016. 10
2016
-
[26]
Graphblas c api: Ideas for future versions of the specification
Timothy G Mattson, Carl Yang, Scott McMillan, Aydin Buluç, and José E Moreira. Graphblas c api: Ideas for future versions of the specification. In 2017 IEEE High Performance Extreme Computing Conference (HPEC), pages 1–6. IEEE, 2017
2017
-
[27]
Compression and load balancing for efficient sparse matrix-vector product on multicore processors and graphics processing units
José I Aliaga, Hartwig Anzt, Thomas Grützmacher, Enrique S Quintana-Ortí, and Andrés E Tomás. Compression and load balancing for efficient sparse matrix-vector product on multicore processors and graphics processing units. Concurrency and Computation: Practice and Experience, 34(14):e6515, 2022
2022
-
[28]
Load-balancing sparse matrix vector product kernels on gpus
Hartwig Anzt, Terry Cojean, Chen Yen-Chen, Jack Dongarra, Goran Flegar, Pratik Nayak, Stanimire Tomov, Yuhsiang M Tsai, and Weichung Wang. Load-balancing sparse matrix vector product kernels on gpus. ACM Transactions on Parallel Computing (TOPC), 7(1):1–26, 2020
2020
-
[29]
fgspmspv: A fine- grained parallel spmspv framework on hpc platforms
Yuedan Chen, Guoqing Xiao, Kenli Li, Francesco Piccialli, and Albert Y Zomaya. fgspmspv: A fine- grained parallel spmspv framework on hpc platforms. ACM Transactions on Parallel Computing, 9(2):1– 29, 2022
2022
-
[30]
HASpMV: Heterogeneity- aware sparse matrix-vector multiplication on modern asymmetric multicore processors
Wenxuan Li, Helin Cheng, Zhengyang Lu, Yuechen Lu, and Weifeng Liu. HASpMV: Heterogeneity- aware sparse matrix-vector multiplication on modern asymmetric multicore processors. In 2023 IEEE International Conference on Cluster Computing (CLUSTER), pages 209–220. IEEE, 2023
2023
-
[31]
TileSpMV: A tiled algorithm for sparse matrix-vector multiplication on gpus
Yuyao Niu, Zhengyang Lu, Meichen Dong, Zhou Jin, Weifeng Liu, and Guangming Tan. TileSpMV: A tiled algorithm for sparse matrix-vector multiplication on gpus. In 2021 IEEE International Parallel and Distributed Processing Symposium (IPDPS), pages 68–78. IEEE, 2021
2021
-
[32]
Nvidia a100 tensor core GPU: Performance and innovation
Jack Choquette, Wishwesh Gandhi, Olivier Giroux, Nick Stam, and Ronny Krashinsky. Nvidia a100 tensor core GPU: Performance and innovation. IEEE Micro, 41(2):29–35, 2021
2021
-
[33]
Convstencil: Transform stencil computation to matrix multiplication on tensor cores
Yuetao Chen, Kun Li, Yuhao Wang, Donglin Bai, Lei Wang, Lingxiao Ma, Liang Yuan, Yunquan Zhang, Ting Cao, and Mao Yang. Convstencil: Transform stencil computation to matrix multiplication on tensor cores. In Proceedings of the 29th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming, pages 333–347, 2024
2024
-
[34]
tcFFT: A fast half-precision FFT library for NVIDIA tensor cores
Binrui Li, Shenggan Cheng, and James Lin. tcFFT: A fast half-precision FFT library for NVIDIA tensor cores. In 2021 IEEE International Conference on Cluster Computing (CLUSTER), pages 1–11. IEEE, 2021
2021
-
[35]
Harnessing gpu tensor cores for fast fp16 arithmetic to speed up mixed-precision iterative refinement solvers
Azzam Haidar, Stanimire Tomov, Jack Dongarra, and Nicholas J Higham. Harnessing gpu tensor cores for fast fp16 arithmetic to speed up mixed-precision iterative refinement solvers. In SC18: International Conference for High Performance Computing, Networking, Storage and Analysis, pages 603–613. IEEE, 2018
2018
-
[36]
Berrybees: Breadth first search by bit-tensor-cores
Yuyao Niu and Marc Casas. Berrybees: Breadth first search by bit-tensor-cores. In Proceedings of the 30th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming, pages 339–354, 2025
2025
-
[37]
Tot: Triangle counting on tensor cores
YuAng Chen and Jeffrey Xu Yu. Tot: Triangle counting on tensor cores. IEEE Transactions on Parallel and Distributed Systems, 2025
2025
-
[38]
On the feasibility of using reduced-precision tensor core operations for graph analytics
Jesun Sahariar Firoz, Ang Li, Jiajia Li, and Kevin Barker. On the feasibility of using reduced-precision tensor core operations for graph analytics. In 2020 IEEE High Performance Extreme Computing Con- ference (HPEC), pages 1–7. IEEE, 2020
2020
-
[39]
Davis and Yifan Hu
Timothy A. Davis and Yifan Hu. The university of florida sparse matrix collection. ACM Trans. Math. Softw., 38(1), dec 2011. 11
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.