LLM-Evolved Domain-Independent Heuristics for Symbolic AI Planning
Pith reviewed 2026-06-29 07:25 UTC · model grok-4.3
The pith
LLM-driven evolution on training domains produces the first domain-independent heuristics that solve more tasks than the strongest hand-engineered baselines on entirely new domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
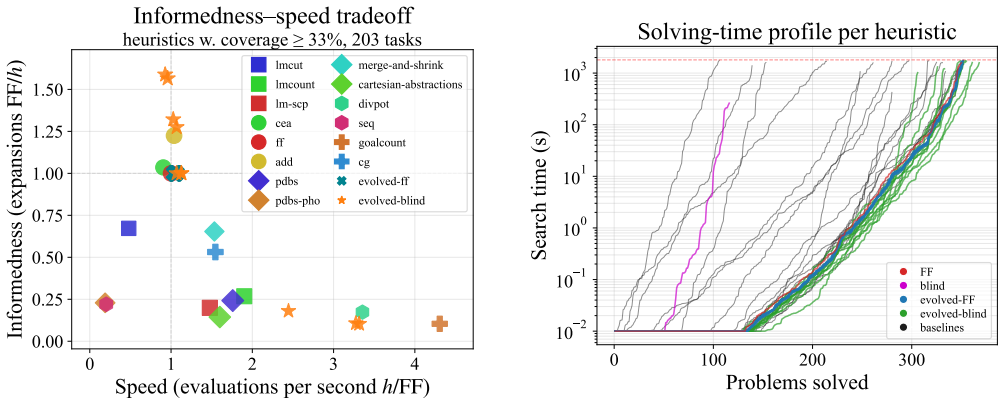
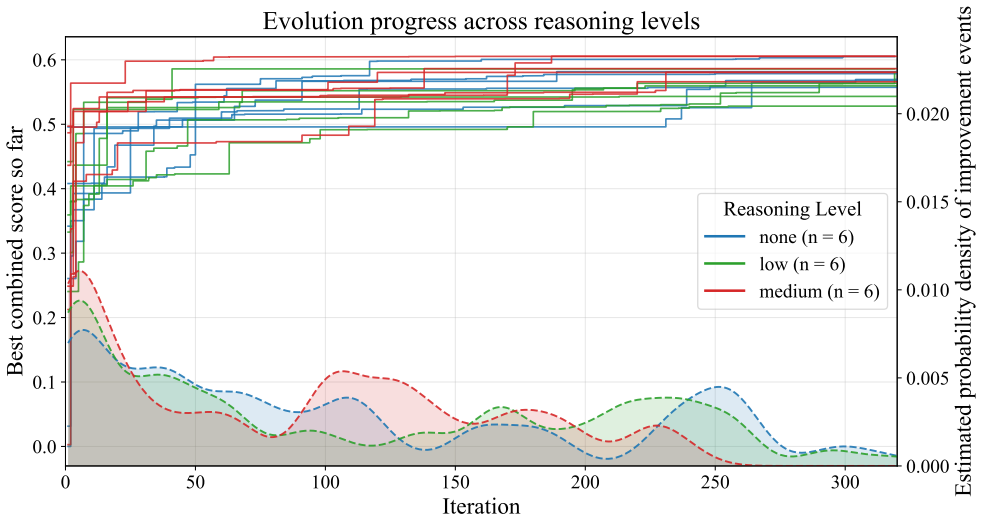
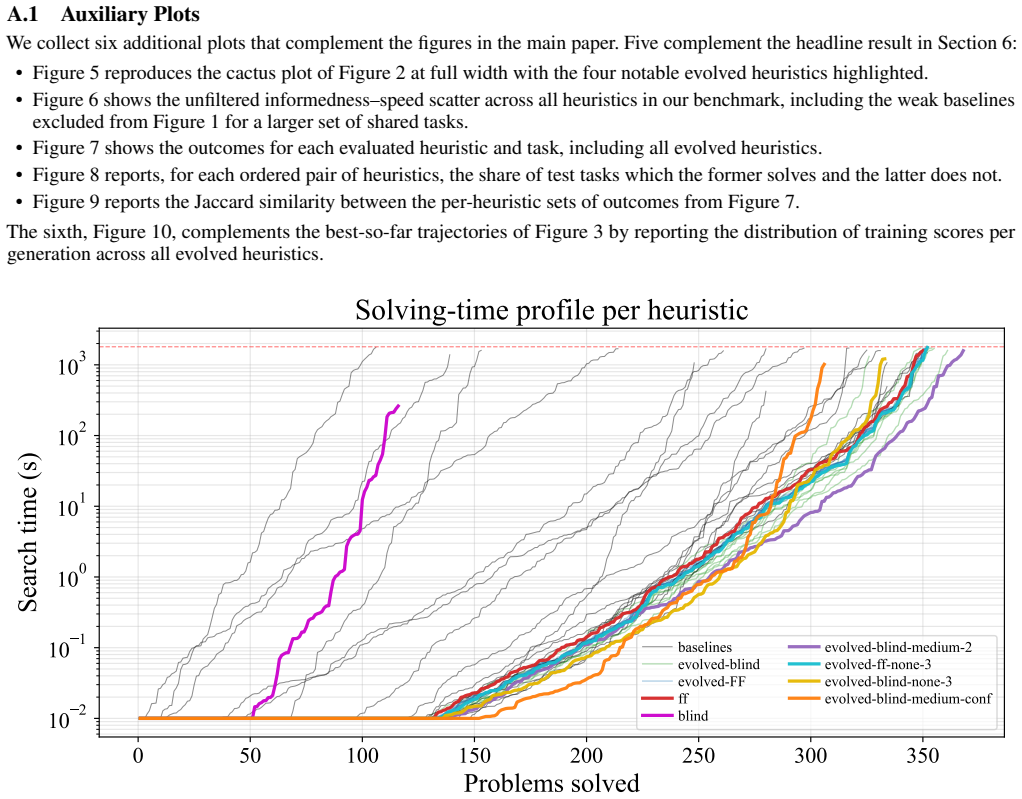
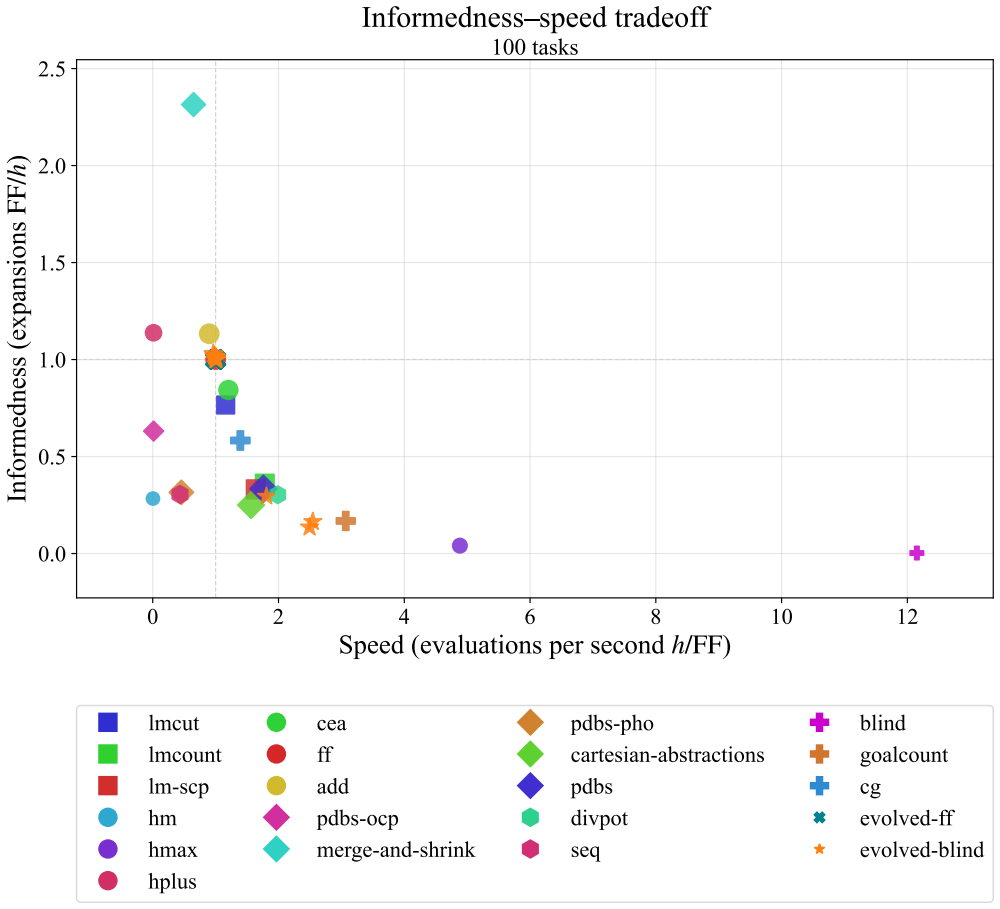
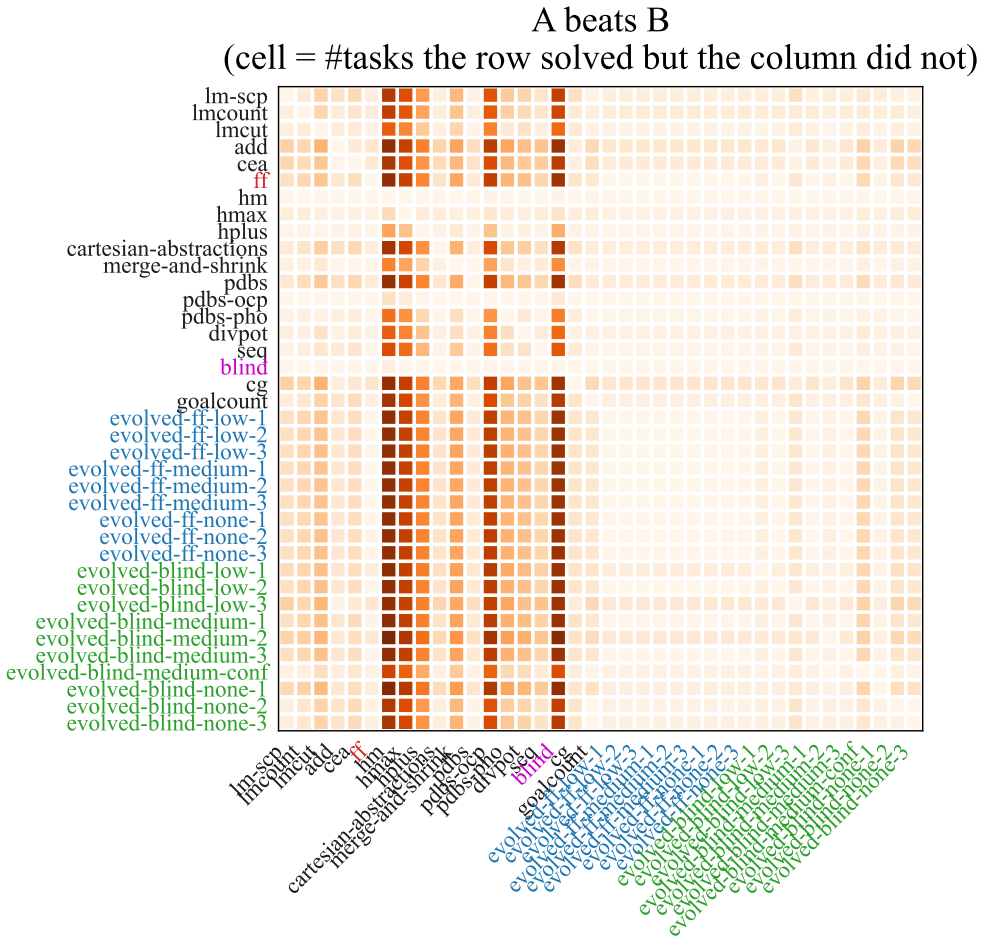
By seeding an evolutionary loop with an LLM that proposes mutations to parent heuristics written in C++, maintaining a MAP-Elites archive indexed by informedness and speed, and assigning fitness from a blend of coverage and runtime on training domains, the method yields heuristics whose best member solves more tasks than the strongest baseline on unseen test domains while the full collection of evolved programs spans the Pareto frontier of the informedness-speed tradeoff.
What carries the argument
MAP-Elites archive keyed on informedness and speed, with LLM mutations generating new C++ heuristic candidates whose fitness is computed from coverage blended with solving time on training domains.
If this is right
- The evolved heuristics slot into existing planners as ordinary C++ functions and inherit soundness and completeness.
- Seeding the evolutionary process from the blind heuristic can produce stronger final programs than seeding from the FF heuristic.
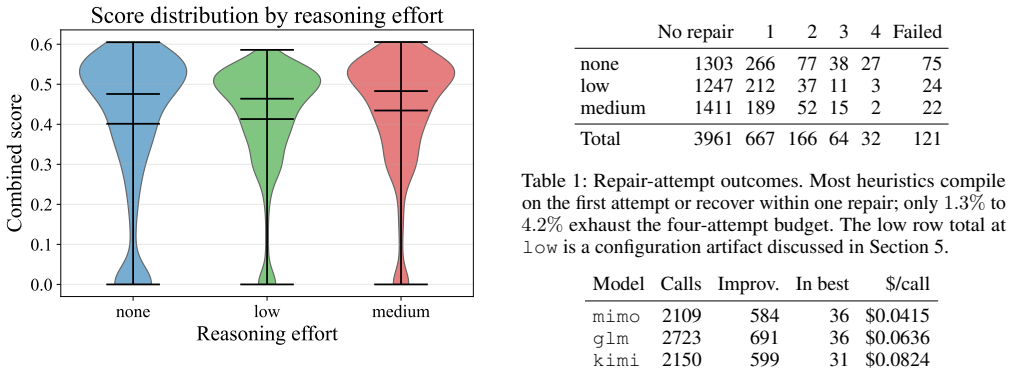
- LLM reasoning effort during mutation affects how often candidates compile far more than the quality of the candidates that do compile.
- A broad benchmark of hand-engineered heuristics on the informedness-speed tradeoff is now available for comparison.
Where Pith is reading between the lines
- The same mutation-plus-archive loop could be applied to other search problems that rely on hand-crafted heuristics, such as game playing or verification.
- Planners could dynamically select among the Pareto-optimal evolved heuristics according to current time or memory limits.
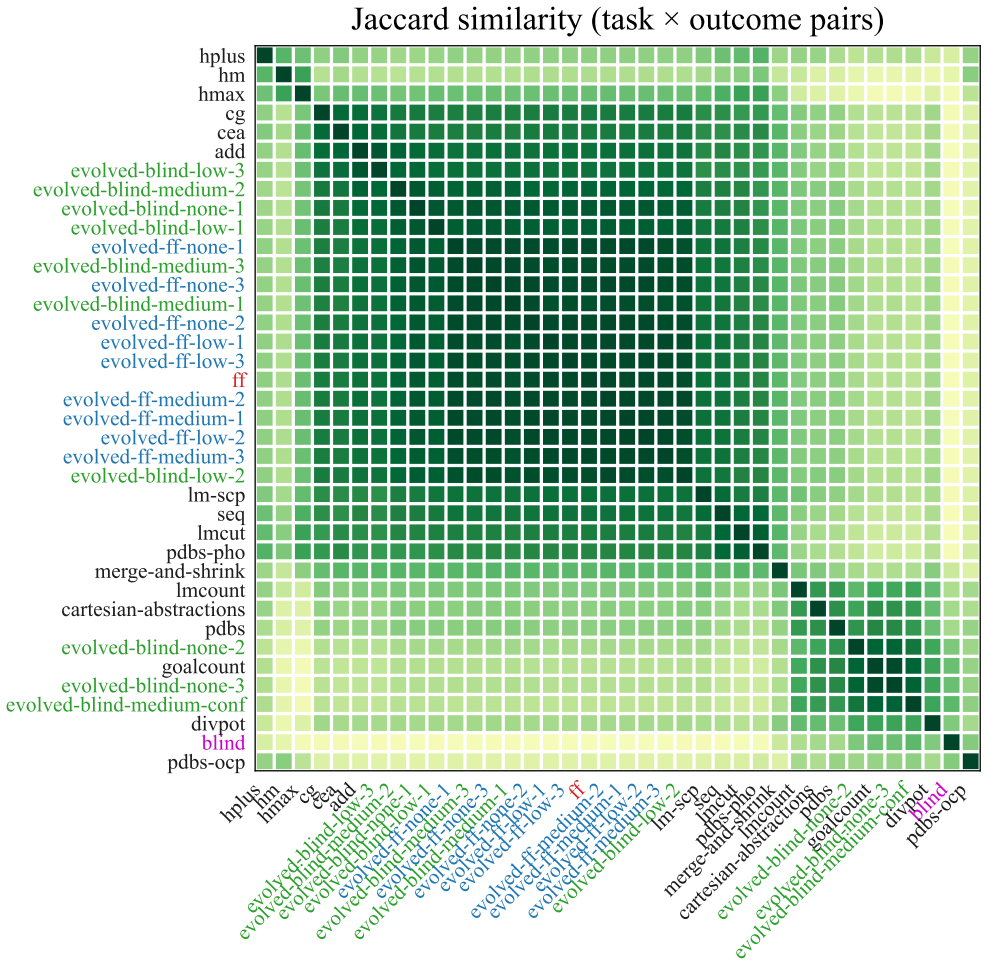
- Varying the diversity or number of training domains would test how robust the generalization is to changes in the training distribution.
- The plain C++ form opens the possibility of further manual or automated refinement after evolution.
Load-bearing premise
Heuristics evolved only on a finite set of training domains will generalize their performance advantage to completely new planning domains without overfitting to the training distribution or the particular coverage-runtime fitness blend.
What would settle it
A collection of new planning domains in which none of the evolved heuristics solves more tasks than the strongest hand-engineered baseline would falsify the generalization result.
Figures
read the original abstract
Heuristic search is the dominant paradigm in symbolic AI planning, and the strongest heuristics are the result of decades of work by planning researchers. Recent work has shown that large language models (LLMs) can design heuristics for individual planning domains, but no LLM-generated heuristic has so far worked on arbitrary planning tasks. In this paper, we use evolutionary search to produce the first LLM-generated domain-independent heuristics that exceed the hand-engineered state of the art. We let an LLM mutate parent heuristics written in C++, store candidates in a MAP-Elites archive keyed on informedness and speed and calculate fitness scores by blending coverage with solving time. To place the evolved programs in context, we additionally benchmark a broad set of hand-engineered heuristics on their informedness-speed tradeoff, which to our knowledge has not been done before. On unseen testing domains, our best evolved heuristic solves more tasks than even the strongest baseline, with our full heuristic suite spanning the Pareto frontier of said tradeoff. We also find that seeding evolution from the trivial blind heuristic outperforms seeding from the strong FF heuristic, even when the resulting program is itself an FF variant, and that LLM reasoning effort affects how often candidates compile much more than the quality of those that do. Because the evolved programs are plain C++, they slot into existing planners as drop-in replacements and inherit the soundness and completeness guarantees of the underlying search.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce the first LLM-generated domain-independent heuristics for symbolic AI planning that outperform hand-engineered state-of-the-art baselines. It uses evolutionary search where an LLM mutates C++ heuristic code, stores candidates in a MAP-Elites archive keyed on informedness and speed, and computes fitness by blending coverage with solving time. On unseen test domains, the best evolved heuristic reportedly solves more tasks than the strongest baseline, with the full suite spanning the informedness-speed Pareto frontier. Additional results include that seeding from the blind heuristic outperforms seeding from FF, and that LLM reasoning effort primarily affects compilation rates rather than quality of successful candidates. The evolved C++ programs are presented as drop-in replacements inheriting planner guarantees.
Significance. If the generalization results hold under rigorous evaluation, this would represent a notable advance by showing that LLM-driven evolution can produce domain-independent planning heuristics exceeding decades of hand-engineered work, with practical integration via C++ code. The broad benchmarking of hand-engineered heuristics on the informedness-speed tradeoff is a useful and previously unreported contribution that provides context for the evolved results.
major comments (3)
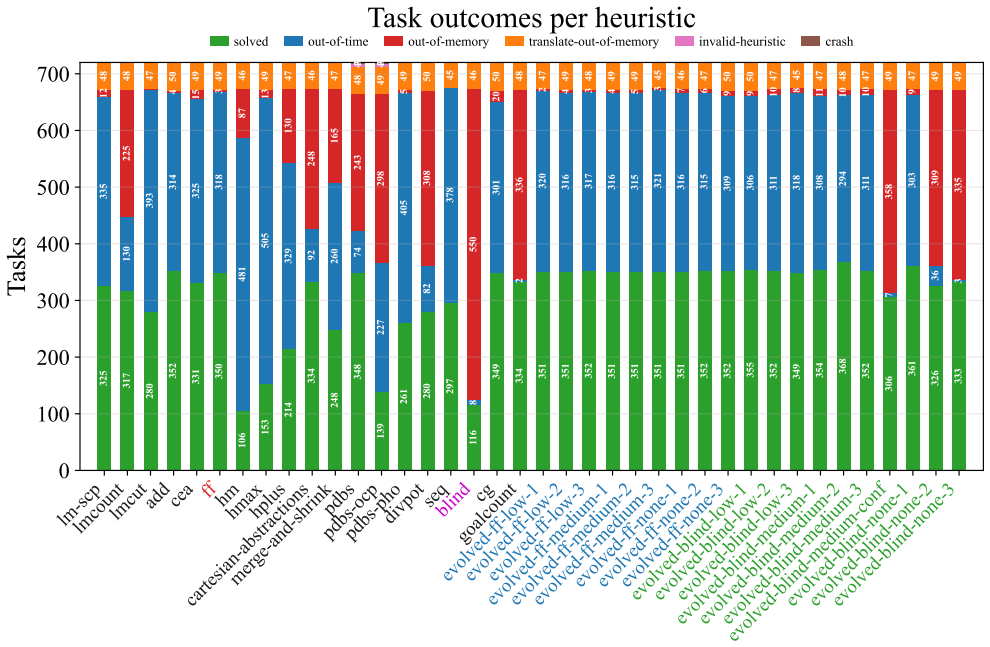
- [Experimental Evaluation] Experimental Evaluation (likely §4 or equivalent): The central claim that the best evolved heuristic outperforms the strongest baseline on unseen testing domains, and that the suite spans the Pareto frontier, is presented without any details on the number of training vs. testing domains, the procedure for creating the train/test split, domain diversity metrics, selection criteria for domains, or any statistical tests (e.g., significance of coverage differences). These omissions directly undermine evaluation of the generalization step highlighted as the weakest assumption.
- [Method / Fitness] Fitness computation description (likely §3): The fitness score is described as a blend of coverage and solving time, but the specific weights, how they were chosen, and any sensitivity analysis are not reported. This is load-bearing because the MAP-Elites archive and Pareto claims depend on this blending, and different weights could alter which candidates are retained or which evolved heuristic is deemed best.
- [Results] Results on seeding and LLM effort (likely §5): Claims that seeding from the blind heuristic outperforms FF seeding (even for FF-variant outputs) and that reasoning effort affects compilation more than quality lack reported run counts, variance across runs, or controls for other factors, making it impossible to assess whether these are robust findings supporting the overall approach.
minor comments (2)
- [Abstract / Introduction] The abstract and introduction could more explicitly reference the specific tables or figures showing the Pareto frontier comparison to allow readers to locate the supporting data immediately.
- [Method] Notation for informedness and speed metrics in the MAP-Elites archive could be defined more formally with equations or pseudocode to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which identify areas where additional clarity and rigor will strengthen the presentation of our results. We respond to each major comment below and will incorporate the suggested improvements in the revised manuscript.
read point-by-point responses
-
Referee: [Experimental Evaluation] Experimental Evaluation (likely §4 or equivalent): The central claim that the best evolved heuristic outperforms the strongest baseline on unseen testing domains, and that the suite spans the Pareto frontier, is presented without any details on the number of training vs. testing domains, the procedure for creating the train/test split, domain diversity metrics, selection criteria for domains, or any statistical tests (e.g., significance of coverage differences). These omissions directly undermine evaluation of the generalization step highlighted as the weakest assumption.
Authors: We agree that the experimental section requires expanded reporting to allow readers to assess the generalization claims. In the revision we will add: the precise counts of training and testing domains, the exact procedure used to form the train/test split (including any stratification or diversity considerations), quantitative domain diversity metrics, the domain selection criteria, and statistical tests (such as Wilcoxon signed-rank tests) with p-values for coverage differences between the best evolved heuristic and the strongest baseline. These details will be placed in a dedicated subsection of the experimental evaluation. revision: yes
-
Referee: [Method / Fitness] Fitness computation description (likely §3): The fitness score is described as a blend of coverage and solving time, but the specific weights, how they were chosen, and any sensitivity analysis are not reported. This is load-bearing because the MAP-Elites archive and Pareto claims depend on this blending, and different weights could alter which candidates are retained or which evolved heuristic is deemed best.
Authors: We acknowledge that the fitness function description is incomplete. The revised manuscript will explicitly state the weights applied to coverage and solving time, explain the rationale and any preliminary experiments used to select them, and include a sensitivity analysis that varies the weights and reports the resulting changes to the retained archive members and the identity of the best heuristic. This information will be added to Section 3. revision: yes
-
Referee: [Results] Results on seeding and LLM effort (likely §5): Claims that seeding from the blind heuristic outperforms FF seeding (even for FF-variant outputs) and that reasoning effort affects compilation more than quality lack reported run counts, variance across runs, or controls for other factors, making it impossible to assess whether these are robust findings supporting the overall approach.
Authors: We agree that the robustness of the seeding and LLM-effort results needs better documentation. The revision will report the number of independent runs performed for each condition, means and standard deviations (or other variance measures) across runs, and any controls applied for confounding factors. These statistics will be added to the relevant results subsection. revision: yes
Circularity Check
No circularity: empirical benchmarking against external baselines
full rationale
The paper reports an experimental protocol that evolves C++ heuristics via LLM mutation on a finite training-domain set, then measures coverage and runtime on a disjoint unseen test set, comparing directly to a broad suite of hand-engineered baselines. No equations, fitted parameters, or self-referential definitions appear; the reported advantage is a measured outcome, not a quantity forced by construction from the training fitness function or archive. Self-citations (if any) are not load-bearing for the central empirical claim, which remains falsifiable by external replication on the same domain split.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Heuristic search algorithms remain sound and complete when supplied with admissible or consistent heuristics.
Reference graph
Works this paper leans on
-
[1]
, " * write output.state after.block = add.period write newline
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint howpublished institution isbn journal key month note number organization pages publisher school series title type volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.a...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Aler, R.; Borrajo, D.; and Isasi, P. 2001. Learning to Solve Planning Problems Efficiently by Means of Genetic Programming. Evolutionary Computation, 9(4): 387--420
2001
-
[4]
a ckstr \
B \"a ckstr \"o m, C.; and Nebel, B. 1995. Complexity Results for SAS ^ + Planning. Computational Intelligence, 11(4): 625--655
1995
-
[5]
Bonet, B. 2013. An Admissible Heuristic for SAS ^ + Planning Obtained from the State Equation. In Rossi, F., ed., Proceedings of the 23rd International Joint Conference on Artificial Intelligence (IJCAI 2013), 2268--2274. AAAI Press
2013
-
[6]
Bonet, B.; and Geffner, H. 2001. Planning as Heuristic Search. Artificial Intelligence, 129(1): 5--33
2001
-
[7]
Bylander, T. 1994. The Computational Complexity of Propositional STRIPS Planning. Artificial Intelligence, 69(1--2): 165--204
1994
-
[8]
Z.; Thi \'e baux, S.; and Trevizan, F
Chen, D. Z.; Thi \'e baux, S.; and Trevizan, F. 2024. Learning Domain-Independent Heuristics for Grounded and Lifted Planning. In Dy, J.; and Natarajan, S., eds., Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence ( AAAI 2024) , 20078--20086. AAAI Press
2024
-
[9]
Z.; Zenn, J.; Cinquin, T.; and McIlraith, S
Chen, D. Z.; Zenn, J.; Cinquin, T.; and McIlraith, S. A. 2025. Language Models for Generalised PDDL Planning: Synthesising Sound and Programmatic Policies. In ICAPS 2025 Workshop on Planning in the Era of LLMs (LM4Plan)
2025
-
[10]
Frontier Large Language Models Rival State-of-the-Art Planners
Corr \^e a, A. B.; Pereira, A. G.; and Seipp, J. 2025. The 2025 Planning Performance of Frontier Large Language Models. arXiv:2511.09378
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
B.; Pereira, A
Corr\^ e a, A. B.; Pereira, A. G.; and Seipp, J. 2025. Classical Planning with LLM -Generated Heuristics: Challenging the State of the Art with Python Code. In Proceedings of the Thirty-Ninth Annual Conference on Neural Information Processing Systems ( NeurIPS 2025)
2025
-
[12]
Edelkamp, S. 2002. Symbolic Pattern Databases in Heuristic Search Planning. In Ghallab, M.; Hertzberg, J.; and Traverso, P., eds., Proceedings of the Sixth International Conference on Artificial Intelligence Planning and Scheduling ( AIPS 2002) , 274--283. AAAI Press
2002
-
[13]
E.; and Smith, J
Eiben, A. E.; and Smith, J. E. 2015. Introduction to Evolutionary Computing. Natural Computing Series. Springer, 2nd edition
2015
-
[14]
Fox, M.; and Long, D. 2003. PDDL2.1 : An Extension to PDDL for Expressing Temporal Planning Domains. Journal of Artificial Intelligence Research, 20: 61--124
2003
-
[15]
Fritzsche, M.; Gestrin, E.; and Seipp, J. 2026. Symmetry-Aware Transformer Training for Automated Planning. In Jenkins, C.; and Taylor, M., eds., Proceedings of the Fortieth AAAI Conference on Artificial Intelligence ( AAAI 2026) . AAAI Press
2026
-
[16]
Fukunaga, A. S. 2008. Automated Discovery of Local Search Heuristics for Satisfiability Testing. Evolutionary Computation, 16(1): 31--61
2008
-
[17]
Gestrin, E.; Kuhlmann, M.; and Seipp, J. 2024. NL2Plan : Robust LLM -Driven Planning from Minimal Text Descriptions. In ICAPS 2024 Workshop on Human-Aware and Explainable Planning (HAXP)
2024
-
[18]
Haslum, P.; Botea, A.; Helmert, M.; Bonet, B.; and Koenig, S. 2007. Domain-Independent Construction of Pattern Database Heuristics for Cost-Optimal Planning. In Proceedings of the Twenty-Second AAAI Conference on Artificial Intelligence ( AAAI 2007) , 1007--1012. AAAI Press
2007
-
[19]
Haslum, P.; and Geffner, H. 2000. Admissible Heuristics for Optimal Planning. In Chien, S.; Kambhampati, S.; and Knoblock, C. A., eds., Proceedings of the Fifth International Conference on Artificial Intelligence Planning and Scheduling ( AIPS 2000) , 140--149. AAAI Press
2000
-
[20]
Helmert, M. 2004. A Planning Heuristic Based on Causal Graph Analysis. In Zilberstein, S.; Koehler, J.; and Koenig, S., eds., Proceedings of the Fourteenth International Conference on Automated Planning and Scheduling ( ICAPS 2004) , 161--170. AAAI Press
2004
-
[21]
Helmert, M. 2006. The Fast Downward Planning System. Journal of Artificial Intelligence Research, 26: 191--246
2006
-
[22]
Helmert, M.; and Domshlak, C. 2009. Landmarks, Critical Paths and Abstractions: What's the Difference Anyway? In Gerevini, A.; Howe, A.; Cesta, A.; and Refanidis, I., eds., Proceedings of the Nineteenth International Conference on Automated Planning and Scheduling (ICAPS 2009), 162--169. AAAI Press
2009
-
[23]
Helmert, M.; and Geffner, H. 2008. Unifying the Causal Graph and Additive Heuristics. In Rintanen, J.; Nebel, B.; Beck, J. C.; and Hansen, E., eds., Proceedings of the Eighteenth International Conference on Automated Planning and Scheduling (ICAPS 2008), 140--147. AAAI Press
2008
-
[24]
Helmert, M.; Haslum, P.; Hoffmann, J.; and Nissim, R. 2014. Merge-and-Shrink Abstraction: A Method for Generating Lower Bounds in Factored State Spaces. Journal of the ACM, 61(3): 16:1--63
2014
-
[25]
Hoffmann, J.; and Nebel, B. 2001. The FF Planning System: Fast Plan Generation Through Heuristic Search. Journal of Artificial Intelligence Research, 14: 253--302
2001
-
[26]
Karpas, E.; and Domshlak, C. 2009. Cost-Optimal Planning with Landmarks. In Boutilier, C., ed., Proceedings of the 21st International Joint Conference on Artificial Intelligence ( IJCAI 2009) , 1728--1733. AAAI Press
2009
-
[27]
Liu, B.; Jiang, Y.; Zhang, X.; Liu, Q.; Zhang, S.; Biswas, J.; and Stone, P. 2023. LLM+P : Empowering Large Language Models with Optimal Planning Proficiency. arXiv preprint arXiv:2304.11477
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Liu, F.; Tong, X.; Yuan, M.; Lin, X.; Luo, F.; Wang, Z.; Lu, Z.; and Zhang, Q. 2024. Evolution of heuristics: towards efficient automatic algorithm design using large language model. In Proceedings of the 41st International Conference on Machine Learning, ICML'24. JMLR.org
2024
-
[29]
McDermott, D.; Ghallab, M.; Howe, A.; Knoblock, C.; Ram, A.; Veloso, M.; Weld, D.; and Wilkins, D. 1998. PDDL -- The Planning Domain Definition Language -- Version 1.2. Technical Report CVC TR-98-003/DCS TR-1165, Yale Center for Computational Vision and Control, Yale University
1998
-
[30]
Mouret, J.-B.; and Clune, J. 2015. Illuminating search spaces by mapping elites. arXiv:1504.04909
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[31]
Murray, A.; Dervovic, D.; Pozanco, A.; and Cashmore, M. 2026. GenePlan : Evolving Better Generalized PDDL Plans using Large Language Models. In Proceedings of the Thirty-Sixth International Conference on Automated Planning and Scheduling (ICAPS 2026)
2026
-
[32]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Novikov, A.; V \ u , N.; Eisenberger, M.; Dupont, E.; Huang, P.-S.; Wagner, A. Z.; Shirobokov, S.; Kozlovskii, B.; Ruiz, F. J. R.; Mehrabian, A.; Kumar, M. P.; See, A.; Chaudhuri, S.; Holland, G.; Davies, A.; Nowozin, S.; Kohli, P.; and Balog, M. 2025. AlphaEvolve : A Coding Agent for Scientific and Algorithmic Discovery. arXiv:2506.13131
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Pommerening, F.; Helmert, M.; R\"oger , G.; and Seipp, J. 2015. From Non-Negative to General Operator Cost Partitioning. In Bonet, B.; and Koenig, S., eds., Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence ( AAAI 2015) , 3335--3341. AAAI Press
2015
-
[34]
Pommerening, F.; R\"oger , G.; and Helmert, M. 2013. Getting the Most Out of Pattern Databases for Classical Planning. In Rossi, F., ed., Proceedings of the 23rd International Joint Conference on Artificial Intelligence (IJCAI 2013), 2357--2364. AAAI Press
2013
-
[35]
Pommerening, F.; R\"oger , G.; Helmert, M.; and Bonet, B. 2014. LP -based Heuristics for Cost-optimal Planning. In Chien, S.; Fern, A.; Ruml, W.; and Do, M., eds., Proceedings of the Twenty-Fourth International Conference on Automated Planning and Scheduling (ICAPS 2014), 226--234. AAAI Press
2014
-
[36]
F.; and Rintanen, J
Rankooh, M. F.; and Rintanen, J. 2022. Efficient Computation and Informative Estimation of h^+ by Integer and Linear Programming. In Thi \'e baux, S.; and Yeoh, W., eds., Proceedings of the Thirty-Second International Conference on Automated Planning and Scheduling (ICAPS 2022), 71--79. AAAI Press
2022
-
[37]
Richter, S.; and Westphal, M. 2010. The LAMA Planner: Guiding Cost-Based Anytime Planning with Landmarks. Journal of Artificial Intelligence Research, 39: 127--177
2010
-
[38]
P.; Dupont, E.; Ruiz, F
Romera-Paredes, B.; Barekatain, M.; Novikov, A.; Balog, M.; Kumar, M. P.; Dupont, E.; Ruiz, F. J. R.; Ellenberg, J. S.; Wang, P.; Fawzi, O.; Kohli, P.; and Fawzi, A. 2024. Mathematical Discoveries from Program Search with Large Language Models. Nature, 625: 468--475
2024
-
[39]
Seipp, J.; and Helmert, M. 2018. Counterexample-Guided Cartesian Abstraction Refinement for Classical Planning. Journal of Artificial Intelligence Research, 62: 535--577
2018
-
[40]
Seipp, J.; Keller, T.; and Helmert, M. 2020. Saturated Cost Partitioning for Optimal Classical Planning. Journal of Artificial Intelligence Research, 67: 129--167
2020
-
[41]
Seipp, J.; Pommerening, F.; and Helmert, M. 2015. New Optimization Functions for Potential Heuristics. In Brafman, R.; Domshlak, C.; Haslum, P.; and Zilberstein, S., eds., Proceedings of the Twenty-Fifth International Conference on Automated Planning and Scheduling (ICAPS 2015), 193--201. AAAI Press
2015
-
[42]
Sharma, A. 2025. OpenEvolve: an open-source evolutionary coding agent
2025
-
[43]
Sievers, S.; and Helmert, M. 2021. Merge-and-Shrink: A Compositional Theory of Transformations of Factored Transition Systems. Journal of Artificial Intelligence Research, 71: 781--883
2021
-
[44]
St hlberg, S.; Bonet, B.; and Geffner, H. 2022. Learning General Optimal Policies with Graph Neural Networks: Expressive Power, Transparency, and Limits. In Thi \'e baux, S.; and Yeoh, W., eds., Proceedings of the Thirty-Second International Conference on Automated Planning and Scheduling (ICAPS 2022), 629--637. AAAI Press
2022
-
[45]
Stein, K.; Hodel, N.; Fi s er, D.; Hoffmann, J.; Katz, M.; and Koller, A. 2026. Improved Generalized Planning with LLMs through Strategy Refinement and Reflection. In Proceedings of the Thirty-Sixth International Conference on Automated Planning and Scheduling (ICAPS 2026)
2026
-
[46]
Taitler, A.; Alford, R.; Espasa, J.; Behnke, G.; Fi s er, D.; Gimelfarb, M.; Pommerening, F.; Sanner, S.; Scala, E.; Schreiber, D.; Segovia-Aguas, J.; and Seipp, J. 2024. The 2023 International Planning Competition . AI Magazine, 45(2): 280--296
2024
-
[47]
Tantakoun, M.; Muise, C.; and Zhu, X. 2025. LLM s as Planning Formalizers: A Survey for Leveraging Large Language Models to Construct Automated Planning Models. In Findings of the Association for Computational Linguistics: ACL 2025, 25167--25188. Vienna, Austria: Association for Computational Linguistics. ISBN 979-8-89176-256-5
2025
-
[48]
Torralba, \'A .; Seipp, J.; and Sievers, S. 2021. Automatic Instance Generation for Classical Planning. In Goldman, R. P.; Biundo, S.; and Katz, M., eds., Proceedings of the Thirty-First International Conference on Automated Planning and Scheduling (ICAPS 2021), 376--384. AAAI Press
2021
- [49]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.