Quantifying and Optimizing Simplicity via Polynomial Representations
Pith reviewed 2026-06-29 07:07 UTC · model grok-4.3
The pith
Neural network predictions along data paths can be approximated by low-degree orthogonal polynomials, and the effective degree of this approximation measures simplicity and predicts generalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
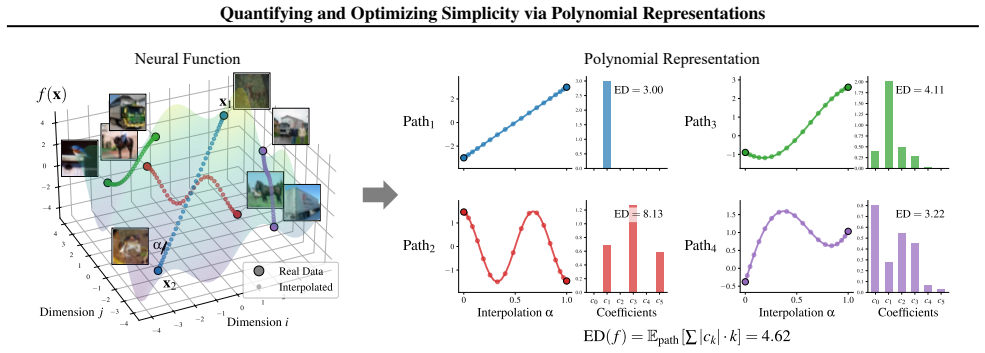
We introduce polynomial representations as a distribution-aware, low-dimensional surrogate for neural functions: we approximate a network's predictive behavior along data-dependent interpolation paths using orthogonal polynomial bases, yielding a compact functional representation. We show that the effective degree of this representation serves as a practical simplicity metric that is predictive of generalization across tasks and architectures, and consistently outperforms existing generalization proxies such as sharpness. Polynomial representations naturally yield a differentiable simplicity regularizer, which consistently improves generalization in image and text classification, fine-tuning
What carries the argument
Polynomial representations: compact surrogates formed by fitting orthogonal polynomial bases to a network's outputs along data-dependent interpolation paths between points.
If this is right
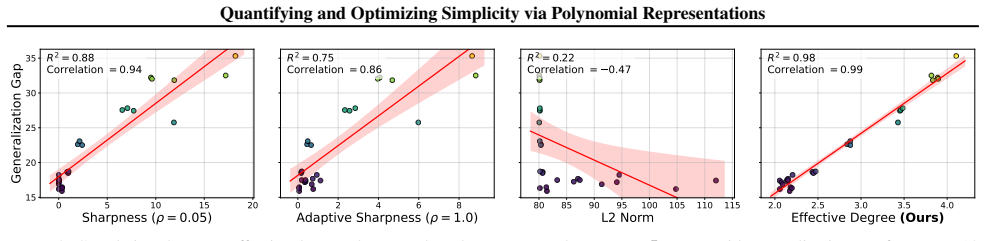
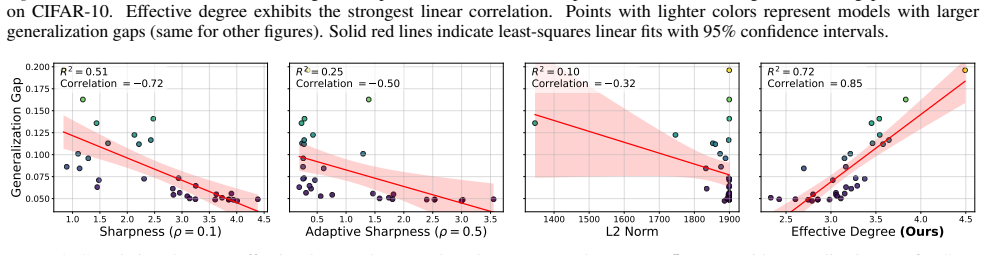
- The effective degree outperforms sharpness as a predictor of generalization on image and text tasks.
- Adding the polynomial-based regularizer during training raises test accuracy in classification, vision-language fine-tuning, and reinforcement learning.
- The same representation works across different network architectures without task-specific tuning.
- The metric remains predictive even when networks are trained with different optimizers or initializations.
Where Pith is reading between the lines
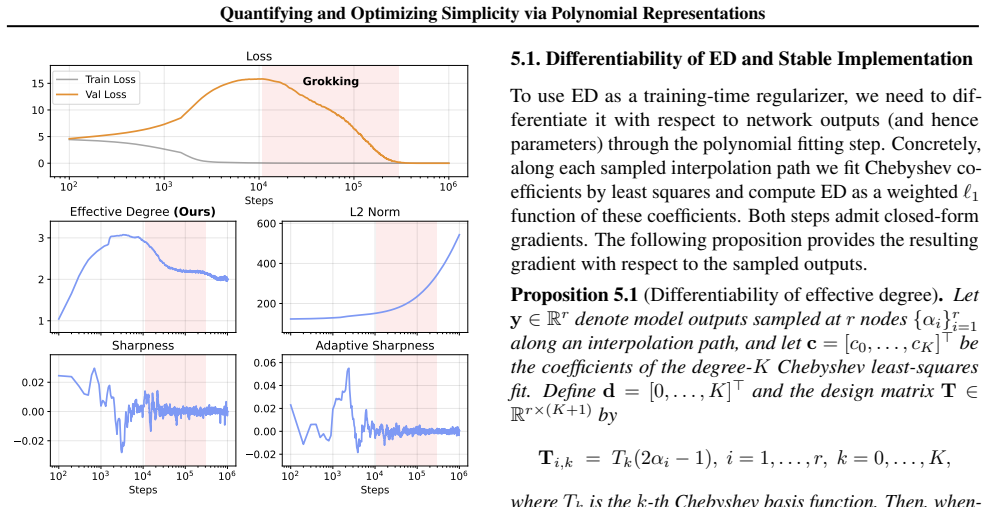
- One could monitor the degree during training to decide when to stop or change the learning rate.
- Architectures whose inductive biases naturally produce lower-degree solutions on the same data might generalize better by construction.
- The approach might be extended to measure simplicity in non-classification settings such as generative models by fitting polynomials to their output distributions.
Load-bearing premise
The polynomial fit along those specific interpolation paths captures the parts of the network's behavior that actually control generalization.
What would settle it
Compute the effective polynomial degree for many trained networks on a fresh task and check whether networks with lower degrees reliably show lower test error; a clear absence of correlation would falsify the metric's usefulness.
Figures
read the original abstract
Deep networks often exhibit a preference for "simple" solutions, and such a simplicity bias is widely believed to play a key role in generalization. Yet a broadly applicable, quantitative measure of simplicity remains elusive. We introduce polynomial representations as a distribution-aware, low-dimensional surrogate for neural functions: we approximate a network's predictive behavior along data-dependent interpolation paths using orthogonal polynomial bases, yielding a compact functional representation. We show that the effective degree of this representation serves as a practical simplicity metric that is predictive of generalization across tasks and architectures, and consistently outperforms existing generalization proxies such as sharpness. Finally, polynomial representations naturally yield a differentiable simplicity regularizer, which consistently improves generalization in image and text classification, fine-tuning contrastive vision-language models, and reinforcement learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces polynomial representations as a distribution-aware, low-dimensional surrogate for neural functions by approximating a network's predictive behavior along data-dependent interpolation paths using orthogonal polynomial bases. It claims that the effective degree of this representation serves as a practical simplicity metric predictive of generalization across tasks and architectures, consistently outperforming existing proxies such as sharpness. It further shows that these representations yield a differentiable simplicity regularizer that improves generalization in image and text classification, fine-tuning of contrastive vision-language models, and reinforcement learning.
Significance. If the results hold, the work supplies a concrete, differentiable tool for quantifying and optimizing the simplicity bias thought to underlie generalization in deep networks. The orthogonal-polynomial construction and its use as a regularizer constitute a practical advance over purely descriptive proxies.
major comments (2)
- [Methods / Experiments] The central claim that effective degree along the chosen paths quantifies simplicity in a manner predictive of generalization is load-bearing on the assumption that 1D interpolation paths capture the operative aspects of network behavior. The manuscript should therefore supply, in the methods or experimental sections, either a theoretical argument or an ablation demonstrating that higher-dimensional couplings do not drive the reported correlations (or that the metric remains predictive when such couplings are controlled for).
- [Experiments] The abstract asserts consistent outperformance over sharpness and generalization gains from the regularizer, yet the support for these claims cannot be evaluated without explicit reporting of datasets, statistical tests, ablation controls, and baseline implementations. These details are required to establish that the observed advantages are not artifacts of path selection or experimental design.
minor comments (2)
- Define 'effective degree' with an explicit formula or algorithm reference at first use to avoid ambiguity in later sections.
- Clarify how the orthogonal bases are constructed and normalized along each interpolation path (e.g., via an equation in the methods).
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and will revise the manuscript to incorporate additional analyses and reporting as needed.
read point-by-point responses
-
Referee: [Methods / Experiments] The central claim that effective degree along the chosen paths quantifies simplicity in a manner predictive of generalization is load-bearing on the assumption that 1D interpolation paths capture the operative aspects of network behavior. The manuscript should therefore supply, in the methods or experimental sections, either a theoretical argument or an ablation demonstrating that higher-dimensional couplings do not drive the reported correlations (or that the metric remains predictive when such couplings are controlled for).
Authors: We agree that the reliance on 1D paths is a central modeling choice and that explicit validation against higher-dimensional effects would strengthen the work. While the paper motivates 1D paths via their distribution-aware construction and empirical predictive power, we do not currently provide a dedicated ablation isolating higher-order couplings. We will add such an ablation (e.g., via controlled multi-dimensional perturbations) to the experimental section of the revised manuscript. revision: yes
-
Referee: [Experiments] The abstract asserts consistent outperformance over sharpness and generalization gains from the regularizer, yet the support for these claims cannot be evaluated without explicit reporting of datasets, statistical tests, ablation controls, and baseline implementations. These details are required to establish that the observed advantages are not artifacts of path selection or experimental design.
Authors: The full manuscript already specifies the datasets, tasks, and architectures used (image/text classification, VLM fine-tuning, RL), along with comparisons to sharpness. However, we acknowledge that statistical significance tests, complete ablation tables, and precise baseline re-implementation details are not presented in a single consolidated location. We will add a dedicated experimental-details subsection and expanded tables reporting these elements to ensure full evaluability. revision: yes
Circularity Check
No significant circularity; metric defined from independent polynomial fit and validated empirically.
full rationale
The paper constructs the polynomial representation and effective degree directly from orthogonal basis fits along data-dependent paths as a surrogate for network behavior. This definition does not incorporate generalization performance or sharpness by construction. The claim that the degree predicts generalization is presented as an empirical result across tasks, not a statistical necessity from the fitting procedure itself. No self-citations are invoked as load-bearing for the core uniqueness or derivation, and the full chain remains self-contained against external benchmarks like sharpness without reducing to renamed inputs or fitted predictions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Stronger generalization bounds for deep nets via a compression approach
Arora, S., Ge, R., Neyshabur, B., and Zhang, Y . Stronger generalization bounds for deep nets via a compression approach.arXiv preprint arXiv:1802.05296,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Barron, A. R. and Klusowski, J. M. Approximation and estimation for high-dimensional deep learning networks. arXiv preprint arXiv:1809.03090,
work page internal anchor Pith review Pith/arXiv arXiv
- [3]
-
[4]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. BERT: Pre-training of deep bidirectional transformers for lan- guage understanding.arXiv preprint arXiv:1810.04805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Augmenting Data with Mixup for Sentence Classification: An Empirical Study
Gunasekar, S., Lee, J., Soudry, D., and Srebro, N. Charac- terizing implicit bias in terms of optimization geometry. InInternational Conference on Machine Learning, pp. 1827–1836, 2018a. Gunasekar, S., Lee, J. D., Soudry, D., and Srebro, N. Im- plicit bias of gradient descent on linear convolutional 10 Quantifying and Optimizing Simplicity via Polynomial ...
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[6]
Hoffman, J., Roberts, D. A., and Yaida, S. Robust learning with Jacobian regularization.arXiv preprint arXiv:1908.02729,
-
[7]
Fantastic generalization measures and where to find them.arXiv preprint arXiv:1912.02178,
Jiang, Y ., Neyshabur, B., Mobahi, H., Krishnan, D., and Bengio, S. Fantastic generalization measures and where to find them.arXiv preprint arXiv:1912.02178,
- [8]
-
[9]
Large-Margin Softmax Loss for Convolutional Neural Networks
Liu, W., Wen, Y ., Yu, Z., and Yang, M. Large-margin softmax loss for convolutional neural networks.arXiv preprint arXiv:1612.02295,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
The Zero Set of a Real Analytic Function
Mityagin, B. The zero set of a real analytic function.arXiv preprint arXiv:1512.07276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
In Search of the Real Inductive Bias: On the Role of Implicit Regularization in Deep Learning
Neyshabur, B., Tomioka, R., and Srebro, N. In search of the real inductive bias: On the role of implicit regularization in deep learning.arXiv preprint arXiv:1412.6614,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Power, A., Burda, Y ., Edwards, H., Babuschkin, I., and Misra, V . Grokking: Generalization beyond overfit- ting on small algorithmic datasets.arXiv preprint arXiv:2201.02177,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
GLUE: A multi-task benchmark and analy- sis platform for natural language understanding
Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., and Bowman, S. GLUE: A multi-task benchmark and analy- sis platform for natural language understanding. InPro- ceedings of the 2018 EMNLP Workshop BlackboxNLP: 12 Quantifying and Optimizing Simplicity via Polynomial Representations Analyzing and Interpreting Neural Networks for NLP, pp. 353–355,
2018
-
[15]
Differentiating both sides with respect toyyields the Jacobian matrix: ∂c ∂y = (T ⊤T)−1T⊤
WhenT ⊤Tis invertible, the normal-equation solution is c= (T ⊤T)−1T⊤y. Differentiating both sides with respect toyyields the Jacobian matrix: ∂c ∂y = (T ⊤T)−1T⊤. Finally, applying the chain rule yields the gradient presented in Proposition 5.1: ∂ED ∂y = ∂c ∂y ⊤ ∂ED ∂c =T(T ⊤T)−1 (sign(c)⊙d). Gradient for the stable implementation (damped least squares).In...
1900
-
[16]
D.1. Generalization Prediction on CIFAR-10 and ImageNet We describe the generation of the model pool and the specific protocols for estimating effective degree in the correlation experiments. Model pool generation.To evaluate the correlation between complexity and generalization, we trained a diverse set of models on CIFAR-10 by sweeping over key hyperpar...
2025
-
[17]
Baseline configurations.For sharpness-based baselines, we report the best correlation achieved across a range of neighborhood sizes ρ
with cosine learning rate decay, sweeping batch sizes{256,512,1024}, learning rates{0.005,0.001,0.0005}, and weight decays{10 −3,10 −4,10 −5}. Baseline configurations.For sharpness-based baselines, we report the best correlation achieved across a range of neighborhood sizes ρ. For standard sharpness, we sweep ρ∈ {0.01,0.05,0.1} . For adaptive sharpness, w...
2025
-
[18]
normalized ED)
We report the best correlation achieved over metric variants (raw vs. normalized ED). Specifically, for the raw variant, we fit the polynomial to the model’s output after Softmax (as it provides inherent normalization), whereas for the normalized variant, we fit the logits directly, with normalization explicitly handled within the ED calculation. For Imag...
2022
-
[19]
Consequently, this serves as a standard setting where resolution parameters are fixed, reducing the hyperparameter search space to onlyλ
while significantly reducing training time. Consequently, this serves as a standard setting where resolution parameters are fixed, reducing the hyperparameter search space to onlyλ. 21 Quantifying and Optimizing Simplicity via Polynomial Representations F.2. Settings for ImageNet For the ImageNet experiments, we employ the ViT-S/16 architecture and evalua...
2021
-
[20]
• Strong recipe:We adopt the improved training recipe and hyperparameter settings proposed by Beyer et al
All other hyperparameters remain unchanged. • Strong recipe:We adopt the improved training recipe and hyperparameter settings proposed by Beyer et al. (2022) without mixup augmentation, which serves as a stronger baseline. ED regularization.We apply the same ED regularization configuration across both training settings. The regularization setup shares sim...
2022
-
[21]
1/3 of the training duration) to allow the model to learn adequate representations before enforcing stronger complexity control
Similar to the CIFAR-10 settings, we apply a sinusoidal ramp-up schedule for λ during the first 30 epochs (approx. 1/3 of the training duration) to allow the model to learn adequate representations before enforcing stronger complexity control. F.3. Settings for CLIP Fine-Tuning on ImageNet We adhere to the end-to-end fine-tuning protocol outlined in Worts...
2019
-
[22]
This intermediate manifold is then propagated through the transformer layers to compute the effective degree of the decision trace
+ (1−α)E(x 2). This intermediate manifold is then propagated through the transformer layers to compute the effective degree of the decision trace. Method-specific configurations.For mixup, we employ an embedding interpolation strategy λ∼Beta(α, α) with α= 1.0 . For ED regularization, we adopt the label-anchored ED strategy with randomized cosine sampling....
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.