Striding Across Reynolds Numbers: Representation Geometry in Neural PDE Generalisation
Pith reviewed 2026-06-29 08:50 UTC · model grok-4.3
The pith
Matching states in a source-trained autoencoder latent space enables cross-Reynolds generalisation in PDE solvers using only source data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
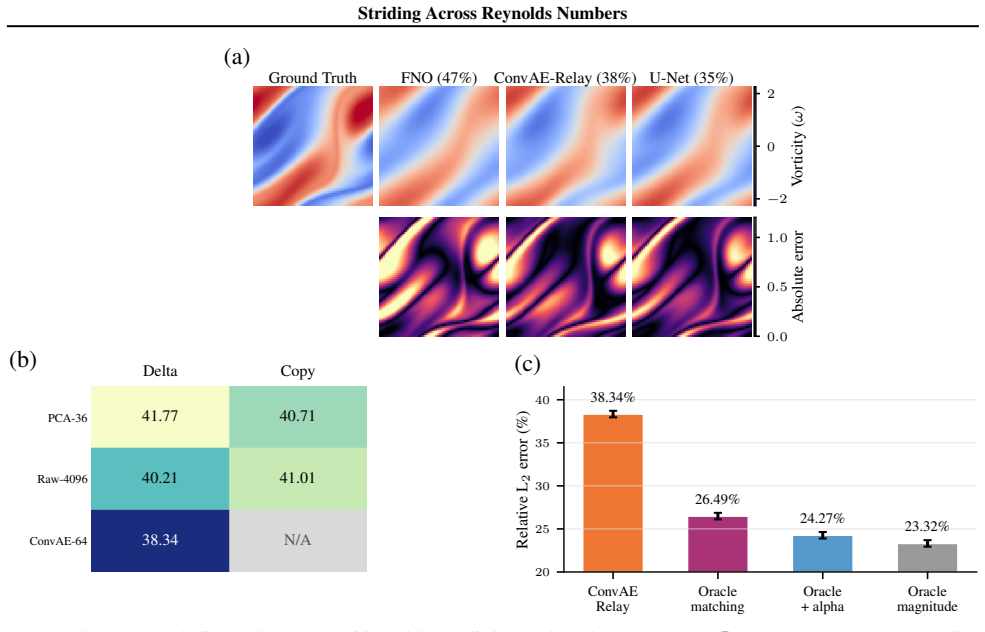
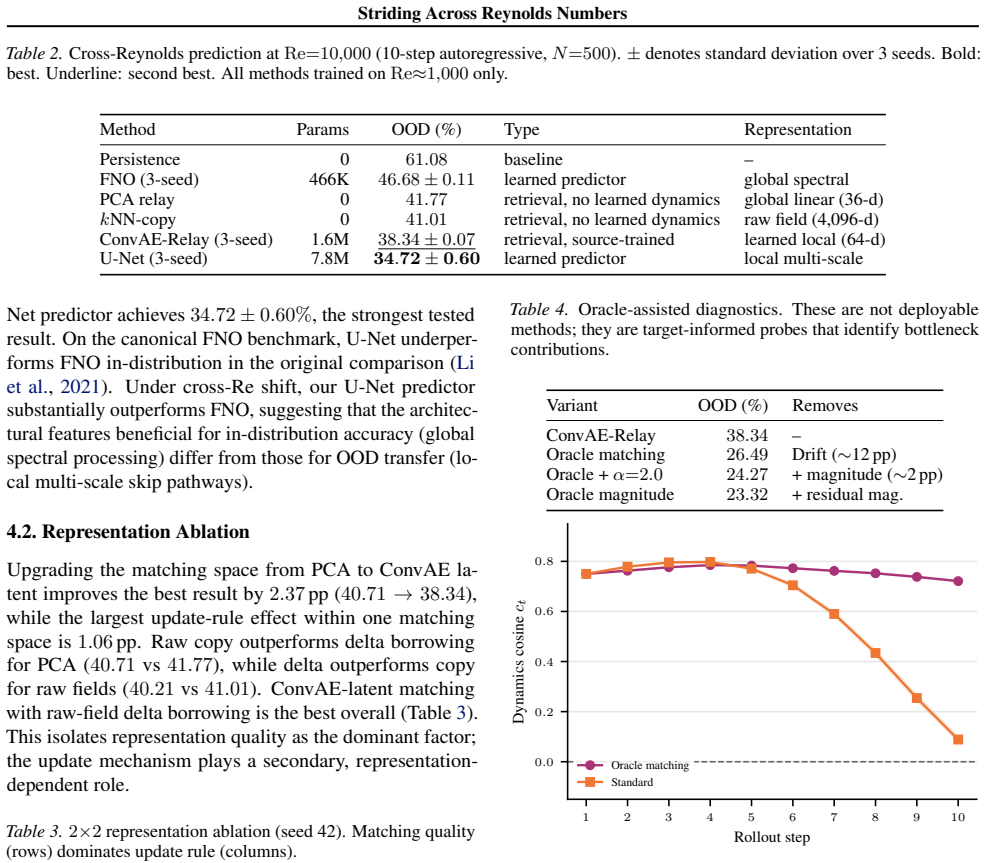
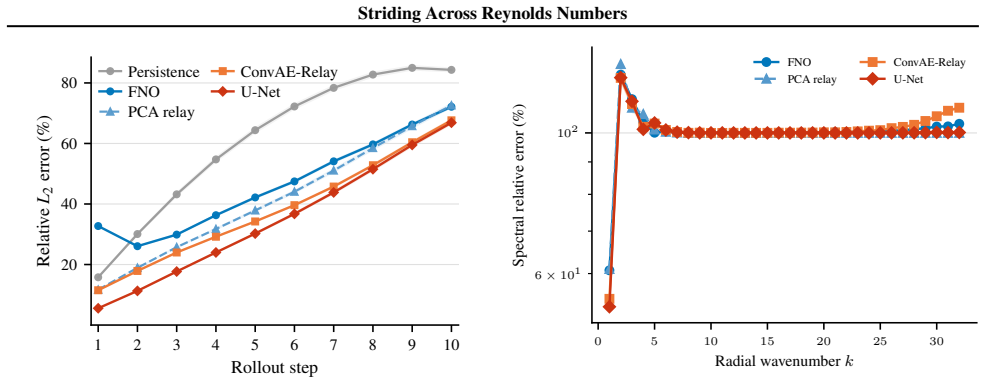
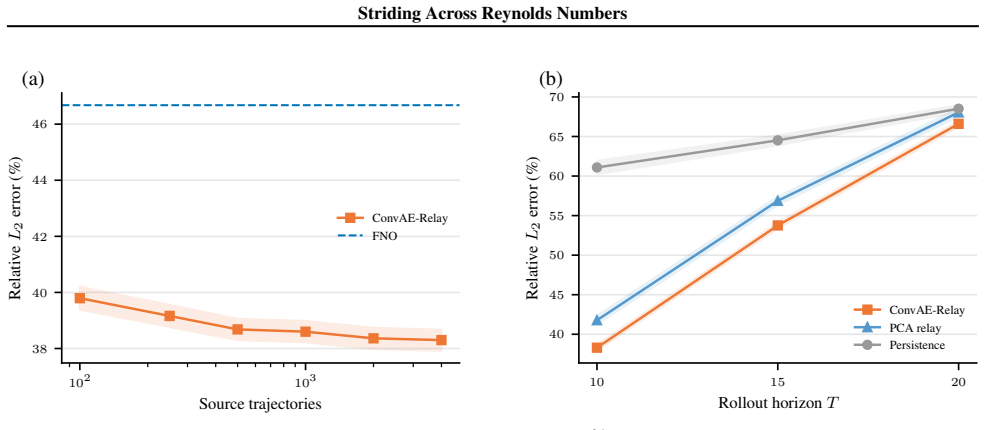
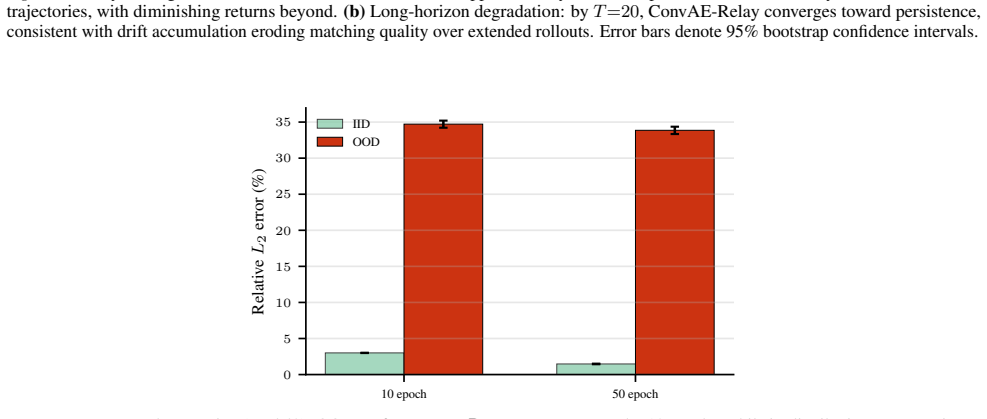
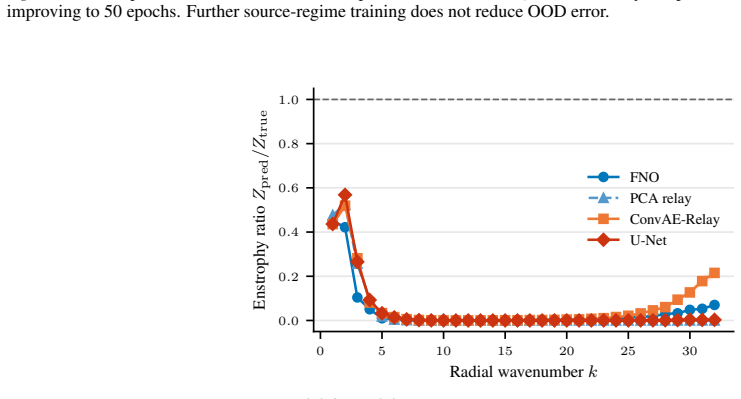
ConvAE-Relay matches states in a source-trained convolutional autoencoder latent space and borrows dynamics from a source-regime database, achieving 38.34+/-0.07 percent relative L2 error on target-regime queries. This uses only the source-regime database with no target-regime fitting, labels, or entries. Oracle experiments show source dynamics directions remain transferable with cosine similarity around 0.84 when matches stay on-manifold, while autoregressive drift accounts for about 12 percentage points of error. A U-Net with multi-scale skip connections reaches 34.72+/-0.60 percent, supporting that local multi-scale representations organise the transfer.
What carries the argument
ConvAE-Relay: matching query states to source states inside the latent space of a convolutional autoencoder trained on the source regime, then retrieving and applying the associated source dynamics.
If this is right
- Matching quality in the latent space dominates the choice of update rule for cross-regime performance.
- Source-regime dynamics directions transfer with cosine similarity near 0.84 provided matches stay on-manifold.
- Autoregressive rollout drift forms the primary remaining error source, contributing roughly 12 percentage points.
- Multi-scale local representations, as used in U-Nets with skip connections, support improved cross-Reynolds transfer.
Where Pith is reading between the lines
- The same latent-space retrieval could be tested on other parameter shifts if the on-manifold condition holds for those shifts.
- Pre-training the autoencoder on the most accessible regime might allow zero-shot application to less accessible regimes without retraining.
- Increasing the density of the source database could reduce the impact of autoregressive drift while still avoiding any target data.
Load-bearing premise
Target regime states remain close enough to the source manifold that nearest-neighbor matches in the autoencoder latent space select dynamics that remain useful after the tenfold Reynolds shift.
What would settle it
Target states under the 10x Reynolds shift fall sufficiently far off the source manifold that nearest matches in latent space produce dynamics whose error exceeds the 41-42 percent retrieval baseline.
Figures

read the original abstract
Cross-Reynolds generalisation in neural PDE solvers remains poorly characterised. On the canonical forced 2D Navier-Stokes benchmark, a trained Fourier Neural Operator reaches 46.68% relative L2 error under a 10x Reynolds-number shift, yet zero-forward-model retrieval baselines already improve to 41-42%. This suggests representation geometry as a major organising variable among the tested methods. We test this hypothesis through ConvAE-Relay, which matches states in a source-trained convolutional autoencoder latent space and borrows dynamics from a source-regime database, achieving 38.34+/-0.07% using only a source-regime database and no target-regime fitting, labels, or database entries. A 2x2 ablation isolates matching quality as dominant over the update rule. Oracle experiments confirm that source-regime dynamics directions remain transferable (cosine similarity ~0.84) when matching stays on-manifold; autoregressive drift is the primary bottleneck (~12 percentage points). From the learned-prediction side, a U-Net with multi-scale skip connections achieves 34.72+/-0.60%, consistent with the retrieval-side finding that local, multi-scale representations organise cross-Reynolds transfer among tested methods. All claims are scoped to this benchmark.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines cross-Reynolds generalization for neural PDE solvers on the forced 2D Navier-Stokes benchmark. A Fourier Neural Operator reaches 46.68% relative L2 error under a 10x Re shift, while retrieval baselines improve to 41-42%. ConvAE-Relay matches states in a source-trained ConvAE latent space and borrows source dynamics, achieving 38.34+/-0.07% with no target fitting, labels, or data. A 2x2 ablation isolates matching quality as dominant; oracle cosine similarity is ~0.84 when on-manifold. Autoregressive drift costs ~12 points. A U-Net with multi-scale skips reaches 34.72+/-0.60%. All claims are scoped to this benchmark.
Significance. If the results hold, the work shows that representation geometry (local, multi-scale) organizes cross-Re transfer among tested methods and supplies a concrete no-target-data baseline (ConvAE-Relay) that beats the FNO while using only source data. The numerical claims are supported by reported means with standard deviations, a 2x2 ablation, and oracle measurements; these elements strengthen the empirical grounding.
major comments (1)
- [Abstract] Abstract: the reported 38.34% performance of ConvAE-Relay and its advantage over the 41-42% retrieval baselines rest on target-regime states remaining sufficiently on the source manifold in the ConvAE latent space under the 10x Re shift. No direct verification (reconstruction error, latent-space density, or distance statistics for target queries) is supplied; the oracle cosine-similarity result (~0.84) is explicitly conditional on on-manifold matching. This assumption is load-bearing for the central performance claim.
Simulated Author's Rebuttal
We thank the referee for the careful review and for highlighting the importance of verifying the manifold assumption underlying the ConvAE-Relay results. We address the single major comment below and will strengthen the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported 38.34% performance of ConvAE-Relay and its advantage over the 41-42% retrieval baselines rest on target-regime states remaining sufficiently on the source manifold in the ConvAE latent space under the 10x Re shift. No direct verification (reconstruction error, latent-space density, or distance statistics for target queries) is supplied; the oracle cosine-similarity result (~0.84) is explicitly conditional on on-manifold matching. This assumption is load-bearing for the central performance claim.
Authors: We agree that direct verification of how well target-regime states align with the source manifold would strengthen the central claim. The reported oracle cosine similarity (~0.84) is indeed conditional on on-manifold matches, and while the performance gap versus retrieval baselines provides indirect support, it does not substitute for explicit checks. In the revised manuscript we will add: (i) reconstruction error statistics for target queries passed through the source-trained ConvAE, (ii) latent-space distance histograms comparing target queries to the source database, and (iii) a brief density comparison (e.g., nearest-neighbor distances) between source and target latent points. These additions will be placed in the methods/results section and referenced from the abstract. revision: yes
Circularity Check
No circularity: all performance claims are direct empirical measurements on held-out target data
full rationale
The paper reports empirical error rates (e.g., ConvAE-Relay at 38.34+/-0.07%, U-Net at 34.72+/-0.60%) obtained by training on source-regime data and evaluating on held-out target-regime trajectories under a 10x Reynolds shift. No equations, fitted parameters, or self-citations are used to derive these numbers; the results are measured quantities. The on-manifold assumption is stated as a scope condition for the oracle cosine-similarity check but is not used to algebraically reduce any reported performance figure. No self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The forced 2D Navier-Stokes equations define the benchmark dynamics under varying Reynolds number.
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Atencia, A. and Zawadzki, I. A comparison of two techniques for generating nowcasting ensembles. part II : Analogs selection and comparison of techniques. Monthly Weather Review, 143 0 (7): 0 2890--2908, 2015. doi:10.1175/MWR-D-14-00342.1. URL https://doi.org/10.1175/MWR-D-14-00342.1
-
[3]
Bengio, Y., Courville, A., and Vincent, P. Representation learning: A review and new perspectives. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35 0 (8): 0 1798--1828, 2013. doi:10.1109/TPAMI.2013.50. URL https://doi.org/10.1109/TPAMI.2013.50
-
[4]
E., and Welling, M
Brandstetter, J., Worrall, D. E., and Welling, M. Message passing neural PDE solvers. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=vSix3HPYKSU
2022
-
[5]
Brunton, S. L., Noack, B. R., and Koumoutsakos, P. Machine learning for fluid mechanics. Annual Review of Fluid Mechanics, 52: 0 477--508, 2020. doi:10.1146/annurev-fluid-010719-060214. URL https://doi.org/10.1146/annurev-fluid-010719-060214
-
[6]
Choose a transformer: Fourier or Galerkin
Cao, S. Choose a transformer: Fourier or Galerkin . In Advances in Neural Information Processing Systems, volume 34, 2021. URL https://proceedings.neurips.cc/paper/2021/hash/d0921d442ee91b896ad95059d13df618-Abstract.html
2021
-
[7]
Turbulence modeling in the age of data
Duraisamy, K., Iaccarino, G., and Xiao, H. Turbulence modeling in the age of data. Annual Review of Fluid Mechanics, 51: 0 357--377, 2019. doi:10.1146/annurev-fluid-010518-040547. URL https://doi.org/10.1146/annurev-fluid-010518-040547
-
[8]
Multiwavelet-based operator learning for differential equations
Gupta, G., Xiao, X., and Bogdan, P. Multiwavelet-based operator learning for differential equations. In Advances in Neural Information Processing Systems, volume 34, 2021. URL https://proceedings.neurips.cc/paper/2021/hash/c9e5c2b59d98488fe1070e744041ea0e-Abstract.html
2021
-
[9]
GNOT : A general neural operator transformer for operator learning
Hao, Z., Wang, Z., Su, H., Ying, C., Dong, Y., Liu, S., Cheng, Z., Song, J., and Zhu, J. GNOT : A general neural operator transformer for operator learning. In Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pp.\ 12556--12569. PMLR, 2023. URL https://proceedings.mlr.press/v202/h...
2023
-
[10]
Physics-informed machine learning,
Karniadakis, G. E., Kevrekidis, I. G., Lu, L., Perdikaris, P., Wang, S., and Yang, L. Physics-informed machine learning. Nature Reviews Physics, 3: 0 422--440, 2021. doi:10.1038/s42254-021-00314-5. URL https://doi.org/10.1038/s42254-021-00314-5
-
[11]
Generalization through memorization: Nearest neighbor language models
Khandelwal, U., Levy, O., Jurafsky, D., Zettlemoyer, L., and Lewis, M. Generalization through memorization: Nearest neighbor language models. In International Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=HklBjCEKvH
2020
-
[12]
Kingma, D. P. and Ba, J. Adam: A method for stochastic optimization. In International Conference on Learning Representations, 2015. URL https://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[13]
B., Li, Z., Liu, B., Azizzadenesheli, K., Bhattacharya, K., Stuart, A
Kovachki, N. B., Li, Z., Liu, B., Azizzadenesheli, K., Bhattacharya, K., Stuart, A. M., and Anandkumar, A. Neural operator: Learning maps between function spaces with applications to PDEs . Journal of Machine Learning Research, 24 0 (89): 0 1--97, 2023. URL https://jmlr.org/papers/v24/21-1524.html
2023
-
[14]
Kraichnan, R. H. Inertial ranges in two-dimensional turbulence. Physics of Fluids, 10 0 (7): 0 1417--1423, 1967. doi:10.1063/1.1762301. URL https://doi.org/10.1063/1.1762301
-
[15]
Learning skillful medium-range global weather forecasting
Lam, R., Sanchez-Gonzalez, A., Willson, M., Wirnsberger, P., Fortunato, M., Alet, F., Ravuri, S., Ewalds, T., Eaton-Rosen, Z., Hu, W., Merose, A., Hoyer, S., Holland, G., Vinyals, O., Stott, J., Pritzel, A., Mohamed, S., and Battaglia, P. Learning skillful medium-range global weather forecasting. Science, 382 0 (6677): 0 1416--1421, 2023. doi:10.1126/scie...
-
[16]
B., Azizzadenesheli, K., Liu, B., Bhattacharya, K., Stuart, A
Li, Z., Kovachki, N. B., Azizzadenesheli, K., Liu, B., Bhattacharya, K., Stuart, A. M., and Anandkumar, A. Fourier neural operator for parametric partial differential equations. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=c8P9NQVtmnO
2021
-
[17]
Z., Liu, B., and Anandkumar, A
Li, Z., Huang, D. Z., Liu, B., and Anandkumar, A. Fourier neural operator with learned deformations for PDEs on general geometries. Journal of Machine Learning Research, 24 0 (388): 0 1--26, 2023. URL https://jmlr.org/papers/v24/23-0064.html
2023
-
[18]
Scale-consistent learning with neural operators
Li, Z., Lanthaler, S., Deng, C., Wang, Y., Azizzadenesheli, K., and Anandkumar, A. Scale-consistent learning with neural operators. In NeurIPS 2024 Workshop on Foundation Models for Science: Progress, Opportunities, and Challenges, 2024. URL https://neurips.cc/virtual/2024/105933
2024
-
[19]
E., and Brandstetter, J
Lippe, P., Veeling, B., Perdikaris, P., Turner, R. E., and Brandstetter, J. PDE -refiner: Achieving accurate long rollouts with neural PDE solvers. In Advances in Neural Information Processing Systems, volume 36, 2023. URL https://papers.nips.cc/paper_files/paper/2023/hash/d529b943af3dba734f8a7d49efcb6d09-Abstract-Conference.html
2023
-
[20]
Lorenz, E. N. Atmospheric predictability as revealed by naturally occurring analogues. Journal of the Atmospheric Sciences, 26 0 (4): 0 636--646, 1969. URL https://journals.ametsoc.org/view/journals/atsc/26/4/1520-0469_1969_26_636_aparbn_2_0_co_2.xml
1969
-
[21]
Lu, L., Jin, P., Pang, G., Zhang, Z., and Karniadakis, G. E. Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators. Nature Machine Intelligence, 3: 0 218--229, 2021. doi:10.1038/s42256-021-00302-5. URL https://doi.org/10.1038/s42256-021-00302-5
-
[22]
Pathak, J., Subramanian, S., Harrington, P., Raja, S., Chattopadhyay, A., Mardani, M., Kurth, T., Hall, D., Li, Z., Azizzadenesheli, K., Hassanzadeh, P., Kashinath, K., and Anandkumar, A. FourCastNet : A global data-driven high-resolution weather model using adaptive Fourier neural operators. arXiv preprint arXiv:2202.11214, 2022. URL https://arxiv.org/ab...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Pfaff, T., Fortunato, M., Sanchez-Gonzalez, A., and Battaglia, P. W. Learning mesh-based simulation with graph networks. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=roNqYL0_XP
2021
-
[24]
Pope, S. B. Turbulent Flows. Cambridge University Press, 2000. URL https://www.cambridge.org/core/books/turbulent-flows/B6051EBC741C237DCAF9C517ED3E0539
2000
-
[25]
A., Ross, Z
Rahman, M. A., Ross, Z. E., and Azizzadenesheli, K. U-NO : U -shaped neural operators. Transactions on Machine Learning Research, 2023. URL https://openreview.net/forum?id=j3oQF9coJd
2023
-
[26]
Raissi, M., Perdikaris, P., and Karniadakis, G. E. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational Physics, 378: 0 686--707, 2019. doi:10.1016/j.jcp.2018.10.045. URL https://doi.org/10.1016/j.jcp.2018.10.045
-
[27]
U-Net: Convolutional networks for biomedical image segmentation
Ronneberger, O., Fischer, P., and Brox, T. U-Net : Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention, volume 9351 of Lecture Notes in Computer Science, pp.\ 234--241. Springer, 2015. doi: https://doi.org/10.1007/978-3-319-24574-4_28
-
[28]
Sanchez-Gonzalez, A., Godwin, J., Pfaff, T., Ying, R., Leskovec, J., and Battaglia, P. W. Learning to simulate complex physics with graph networks. In Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pp.\ 8459--8468. PMLR, 2020. URL https://proceedings.mlr.press/v119/sanchez-gonz...
2020
-
[29]
W., and Gholami, A
Subramanian, S., Harrington, P., Keutzer, K., Bhimji, W., Morozov, D., Mahoney, M. W., and Gholami, A. Towards foundation models for scientific machine learning: Characterizing scaling and transfer behavior. In Advances in Neural Information Processing Systems, volume 36, 2023. URL https://papers.nips.cc/paper_files/paper/2023/hash/e15790966a4a9d85d688635...
2023
-
[30]
Tran, A., Mathews, A., Xie, L., and Ong, C. S. Factorized Fourier neural operators. In International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=tmIiMPl4IPa
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.