AnomalyAgent: Training-Free Agentic Models for Zero-/Few-Shot Anomaly Detection
Pith reviewed 2026-06-29 08:07 UTC · model grok-4.3
The pith
AnomalyAgent equips multimodal LLMs with anomaly-specific tools and memory for effective training-free anomaly detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AnomalyAgent is a training-free agentic framework that leverages multimodal large language models through a comprehensive anomaly-centric toolset for adaptive zero-shot reasoning and a customized memory module that grounds reasoning with few-shot in-context examples, yielding substantially better performance than training-free VLM-based anomaly detection and generic agentic methods on both simple and complex anomalies.
What carries the argument
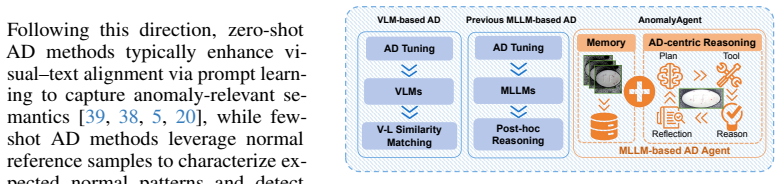
Anomaly-centric toolset enabling MLLM-driven agentic anomaly reasoning together with a memory module for few-shot reference grounding.
If this is right
- Detection extends beyond surface defects to logical and contextual anomalies in logistics and manufacturing.
- No auxiliary training data or model fine-tuning is required for competitive zero-shot and few-shot results.
- The same framework improves generalization across both zero-shot and few-shot regimes compared with similarity-only baselines.
Where Pith is reading between the lines
- The same tool-and-memory pattern might transfer to other vision tasks that need contextual judgment rather than pure visual matching.
- Lower dependence on large labeled sets could open anomaly detection to settings where collecting training data is costly or restricted.
- Further tests on additional real-world anomaly types would show whether the hand-designed tools remain effective outside the evaluated domains.
Load-bearing premise
Existing multimodal large language models already hold enough reasoning power to perform in-depth contextual anomaly detection when steered by a hand-designed toolset and memory module without any training.
What would settle it
If AnomalyAgent shows no clear performance gain over generic agentic methods on a new set of logical or contextual anomalies, the claim of superior generalization would not hold.
Figures








read the original abstract
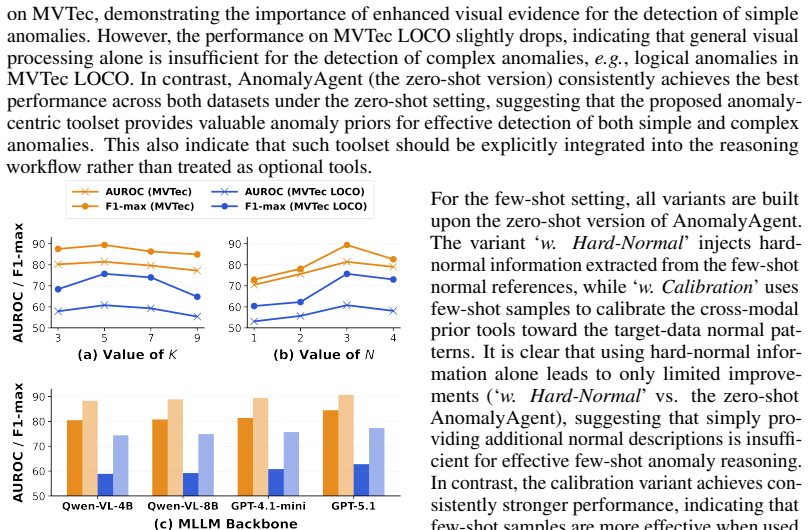
Benefiting from generalizability of vision-language models (VLMs) such as CLIP, many zero-/few-shot anomaly detection (AD) approaches have achieved impressive detection performance across various datasets. Nevertheless, they require substantial training on large auxiliary datasets to adapt VLMs to anomaly detection, and their inference largely relies on visual-text embedding similarity-based anomaly scores, lacking reasoning abilities to detect complex anomalies that require in-depth contextual understanding. To address this limitation, we propose \textbf{AnomalyAgent}, a novel training-free, agentic framework that leverages the advanced reasoning and generalization capabilities of multimodal large language models (MLLMs) for anomaly detection. The key ingredients include \textbf{1)} a comprehensive anomaly-centric toolset that enables adaptive MLLM-driven, agentic anomaly reasoning in zero-shot settings, and \textbf{2)} a customized memory module that grounds anomaly reasoning with few-shot, in-context reference examples. We extend evaluation beyond the detection of simple anomalies (e.g., surface defects like cracks and dents and clear lesions) in widely used benchmarks to more diverse types of anomalies such as logical/contextual anomalies in logistics and manufacturing settings. Extensive experiment results demonstrate that our AnomalyAgent achieves substantially better performance compared to training-free VLM-based AD and generic agentic methods, highlighting its superior generalization capability in both zero-shot and few-shot anomaly detection settings. The code implementation can be find at this address.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AnomalyAgent, a training-free agentic framework for zero- and few-shot anomaly detection that leverages multimodal large language models (MLLMs). It introduces an anomaly-centric toolset enabling adaptive MLLM-driven reasoning and a customized memory module for grounding with few-shot in-context examples. The work extends evaluation to logical/contextual anomalies beyond simple surface defects and claims substantially superior performance and generalization over training-free VLM-based AD methods and generic agentic approaches.
Significance. If the performance claims are substantiated through quantitative results and component ablations, the work would provide evidence that hand-designed agentic structures can effectively harness existing MLLM reasoning for complex contextual anomalies without any training or fine-tuning. The training-free design and stated code availability are explicit strengths supporting reproducibility.
major comments (3)
- [Abstract] Abstract: The central claim that AnomalyAgent 'achieves substantially better performance compared to training-free VLM-based AD and generic agentic methods' supplies no quantitative metrics, dataset names, baseline comparisons, ablation results, or error analysis, rendering the primary empirical contribution unevaluable.
- [Method] Method (key ingredients 1 and 2): The framework is described as a wrapper around pre-existing MLLMs. No ablation studies are referenced that isolate the contribution of the anomaly-centric toolset and memory module from the base MLLM's inherent capabilities; without such controls, gains cannot be attributed to the proposed agentic elements rather than MLLM scale or alignment.
- [Experiments] Experiments: The extension of evaluation to 'more diverse types of anomalies such as logical/contextual anomalies in logistics and manufacturing settings' is asserted, but no tables, figures, or specific quantitative results on these anomaly types versus baselines are referenced to support the generalization claim.
minor comments (2)
- [Abstract] Abstract: Typo in final sentence: 'can be find' should be 'can be found'.
- [Abstract] Abstract: The code address is referenced but not supplied; a concrete repository URL or identifier should be included for accessibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly to improve clarity and substantiation of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that AnomalyAgent 'achieves substantially better performance compared to training-free VLM-based AD and generic agentic methods' supplies no quantitative metrics, dataset names, baseline comparisons, ablation results, or error analysis, rendering the primary empirical contribution unevaluable.
Authors: We agree that the abstract would be strengthened by including key quantitative metrics. In the revised version we will expand the abstract to report specific AUROC improvements, dataset names (MVTec, VisA, and the new contextual anomaly sets), and main baseline comparisons while remaining within length limits. revision: yes
-
Referee: [Method] Method (key ingredients 1 and 2): The framework is described as a wrapper around pre-existing MLLMs. No ablation studies are referenced that isolate the contribution of the anomaly-centric toolset and memory module from the base MLLM's inherent capabilities; without such controls, gains cannot be attributed to the proposed agentic elements rather than MLLM scale or alignment.
Authors: The full manuscript contains an ablation study that compares the complete framework against ablated versions (toolset removed, memory module removed) while holding the base MLLM fixed. We will revise the method section to explicitly cite these ablation results so that the contribution of each component is clearly isolated and attributed. revision: yes
-
Referee: [Experiments] Experiments: The extension of evaluation to 'more diverse types of anomalies such as logical/contextual anomalies in logistics and manufacturing settings' is asserted, but no tables, figures, or specific quantitative results on these anomaly types versus baselines are referenced to support the generalization claim.
Authors: The experiments section already presents tables and figures with quantitative results on both standard surface-defect benchmarks and the additional logical/contextual anomaly datasets, including direct comparisons to the training-free VLM and generic agentic baselines. We will add explicit cross-references from the text discussing generalization to the relevant tables and figures. revision: yes
Circularity Check
No circularity: framework applies pre-existing MLLM capabilities without derivations or self-referential fits
full rationale
The paper describes a training-free agentic wrapper around existing multimodal LLMs, using a hand-designed anomaly-centric toolset and memory module for zero-/few-shot AD. No equations, parameter fitting, or mathematical derivations appear in the provided text. Performance claims rest on empirical comparisons to baselines rather than any reduction of outputs to inputs by construction. No self-citation chains or uniqueness theorems are invoked as load-bearing premises. The central claim is an engineering application of off-the-shelf MLLM reasoning, which is self-contained and externally falsifiable via standard benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal large language models possess advanced reasoning and generalization capabilities that can be directly applied to anomaly detection without training
invented entities (2)
-
anomaly-centric toolset
no independent evidence
-
customized memory module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Beyond dents and scratches: Logical constraints in unsupervised anomaly detection and localization.International Journal of Computer Vision, 130(4):947–969, 2022
Paul Bergmann, Kilian Batzner, Michael Fauser, David Sattlegger, and Carsten Steger. Beyond dents and scratches: Logical constraints in unsupervised anomaly detection and localization.International Journal of Computer Vision, 130(4):947–969, 2022. 1, 2, 6
2022
-
[3]
Mvtec ad–a comprehensive real-world dataset for unsupervised anomaly detection
Paul Bergmann, Michael Fauser, David Sattlegger, and Carsten Steger. Mvtec ad–a comprehensive real-world dataset for unsupervised anomaly detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9592–9600, 2019. 1, 6
2019
-
[4]
Yunkang Cao, Xiaohao Xu, Jiangning Zhang, Yuqi Cheng, Xiaonan Huang, Guansong Pang, and Weim- ing Shen. A survey on visual anomaly detection: Challenge, approach, and prospect.arXiv preprint arXiv:2401.16402, 2024. 1
-
[5]
Adaclip: Adapting clip with hybrid learnable prompts for zero-shot anomaly detection
Yunkang Cao, Jiangning Zhang, Luca Frittoli, Yuqi Cheng, Weiming Shen, and Giacomo Boracchi. Adaclip: Adapting clip with hybrid learnable prompts for zero-shot anomaly detection. InEuropean Conference on Computer Vision, pages 55–72, 2024. 1, 2, 3, 7
2024
-
[6]
Yuhao Chao, Jie Liu, Jie Tang, and Gangshan Wu. Anomalyr1: A grpo-based end-to-end mllm for industrial anomaly detection.arXiv preprint arXiv:2504.11914, 2025. 2, 3
- [7]
-
[8]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025. 3, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Af-clip: Zero-shot anomaly detection via anomaly-focused clip adaptation
Qingqing Fang, Wenxi Lv, and Qinliang Su. Af-clip: Zero-shot anomaly detection via anomaly-focused clip adaptation. InProceedings of the 33rd ACM International Conference on Multimedia, pages 4846–4855,
-
[10]
AnomalyVFM -- Transforming Vision Foundation Models into Zero-Shot Anomaly Detectors
Matic Fuˇcka, Vitjan Zavrtanik, and Danijel Skoˇcaj. Anomalyvfm–transforming vision foundation models into zero-shot anomaly detectors.arXiv preprint arXiv:2601.20524, 2026. 7
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Filo: Zero-shot anomaly detection by fine-grained description and high-quality localization
Zhaopeng Gu, Bingke Zhu, Guibo Zhu, Yingying Chen, Hao Li, Ming Tang, and Jinqiao Wang. Filo: Zero-shot anomaly detection by fine-grained description and high-quality localization. InProceedings of the 32nd ACM International Conference on Multimedia, pages 2041–2049, 2024. 3
2041
-
[12]
Anomalygpt: Detecting industrial anomalies using large vision-language models.Proceedings of the AAAI Conference on Artificial Intelligence, 2024
Zhaopeng Gu, Bingke Zhu, Guibo Zhu, Yingying Chen, Ming Tang, and Jinqiao Wang. Anomalygpt: Detecting industrial anomalies using large vision-language models.Proceedings of the AAAI Conference on Artificial Intelligence, 2024. 2, 3
2024
-
[13]
Kaputt: A large-scale dataset for visual defect detection
Sebastian Höfer, Dorian F Henning, Artemij Amiranashvili, Douglas Morrison, Mariliza Tzes, Ingmar Posner, Marc Matvienko, Alessandro Rennola, and Anton Milan. Kaputt: A large-scale dataset for visual defect detection. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 24224–24233, 2025. 1, 2, 6
2025
-
[14]
Winclip: Zero-/few-shot anomaly classification and segmentation
Jongheon Jeong, Yang Zou, Taewan Kim, Dongqing Zhang, Avinash Ravichandran, and Onkar Dabeer. Winclip: Zero-/few-shot anomaly classification and segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19606–19616, 2023. 1, 3, 4, 7
2023
-
[15]
Mmad: A comprehensive benchmark for multimodal large language models in industrial anomaly detection
Xi Jiang, Jian Li, Hanqiu Deng, Yong Liu, Bin-Bin Gao, Yifeng Zhou, Jialin Li, Chengjie Wang, and Feng Zheng. Mmad: A comprehensive benchmark for multimodal large language models in industrial anomaly detection. InProceedings of The International Conference on Learning Representations, 2025. 2, 3
2025
-
[16]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Attention based glaucoma detection: A large-scale database and cnn model
Liu Li, Mai Xu, Xiaofei Wang, Lai Jiang, and Hanruo Liu. Attention based glaucoma detection: A large-scale database and cnn model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10571–10580, 2019. 6
2019
-
[18]
Promptad: Learning prompts with only normal samples for few-shot anomaly detection.Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024
Xiaofan Li, Zhizhong Zhang, Xin Tan, Chengwei Chen, Yanyun Qu, Yuan Xie, and Lizhuang Ma. Promptad: Learning prompts with only normal samples for few-shot anomaly detection.Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024. 3 10
2024
-
[19]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Aa-clip: Enhancing zero-shot anomaly detection via anomaly-aware clip
Wenxin Ma, Xu Zhang, Qingsong Yao, Fenghe Tang, Chenxu Wu, Yingtai Li, Rui Yan, Zihang Jiang, and S Kevin Zhou. Aa-clip: Enhancing zero-shot anomaly detection via anomaly-aware clip. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 4744–4754, 2025. 1, 2
2025
-
[21]
Gpt-4.1 mini.https://platform.openai.com/docs/models, 2025
OpenAI. Gpt-4.1 mini.https://platform.openai.com/docs/models, 2025. 7
2025
-
[22]
Gpt-5.1.https://platform.openai.com/docs/models, 2025
OpenAI. Gpt-5.1.https://platform.openai.com/docs/models, 2025. 7
2025
-
[23]
Deep learning for anomaly detection: A review.ACM Computing Surveys, 54(2):1–38, 2021
Guansong Pang, Chunhua Shen, Longbing Cao, and Anton Van Den Hengel. Deep learning for anomaly detection: A review.ACM Computing Surveys, 54(2):1–38, 2021. 1
2021
-
[24]
Dictas: A framework for class-generalizable few-shot anomaly segmentation via dictionary lookup
Zhen Qu, Xian Tao, Xinyi Gong, ShiChen Qu, Xiaopei Zhang, Xingang Wang, Fei Shen, Zhengtao Zhang, Mukesh Prasad, and Guiguang Ding. Dictas: A framework for class-generalizable few-shot anomaly segmentation via dictionary lookup. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20519–20528, 2025. 1, 2
2025
-
[25]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763, 2021. 3, 7, 13
2021
-
[26]
Towards total recall in industrial anomaly detection
Karsten Roth, Latha Pemula, Joaquin Zepeda, Bernhard Schölkopf, Thomas Brox, and Peter Gehler. Towards total recall in industrial anomaly detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14318–14328, 2022. 2, 7
2022
-
[27]
Multiresolution knowledge distillation for anomaly detection
Mohammadreza Salehi, Niousha Sadjadi, Soroosh Baselizadeh, Mohammad H Rohban, and Hamid R Rabiee. Multiresolution knowledge distillation for anomaly detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14902–14912, 2021. 1, 6
2021
-
[28]
Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023. 3
2023
-
[29]
Real-esrgan: Training real-world blind super- resolution with pure synthetic data
Xintao Wang, Liangbin Xie, Chao Dong, and Ying Shan. Real-esrgan: Training real-world blind super- resolution with pure synthetic data. InProceedings of the IEEE/CVF international conference on computer vision, pages 1905–1914, 2021. 13
1905
-
[30]
Deep learning for video anomaly detection: A review.IEEE Transactions on Neural Networks and Learning Systems, 2026
Peng Wu, Chengyu Pan, Yuting Yan, Guansong Pang, Qingsen Yan, Peng Wang, and Yanning Zhang. Deep learning for video anomaly detection: A review.IEEE Transactions on Neural Networks and Learning Systems, 2026. 1
2026
-
[31]
Mrad: Zero-shot anomaly detection with memory-driven retrieval
Chaoran Xu, Chengkan Lv, Qiyu Chen, Feng Zhang, and Zhengtao Zhang. Mrad: Zero-shot anomaly detection with memory-driven retrieval. InProceedings of The International Conference on Learning Representations, 2026. 1, 2, 7
2026
-
[32]
Towards zero-shot anomaly detection and reasoning with multimodal large language models
Jiacong Xu, Shao-Yuan Lo, Bardia Safaei, Vishal M Patel, and Isht Dwivedi. Towards zero-shot anomaly detection and reasoning with multimodal large language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 20370–20382, 2025. 2, 3
2025
-
[33]
Qwen3 technical report.arXiv preprint arXiv:2505.xxxxx, 2025
An Yang et al. Qwen3 technical report.arXiv preprint arXiv:2505.xxxxx, 2025. 7
2025
-
[34]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InProceedings of The International Conference on Learning Representations, 2023. 3, 7
2023
-
[35]
Resad: A simple framework for class generalizable anomaly detection
Xincheng Yao, Zixin Chen, Gao Chao, Guangtao Zhai, and Chongyang Zhang. Resad: A simple framework for class generalizable anomaly detection. 2024. 3
2024
-
[36]
Towards training-free anomaly detection with vision and language foundation models
Jinjin Zhang, Guodong Wang, Yizhou Jin, and Di Huang. Towards training-free anomaly detection with vision and language foundation models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15204–15213, 2025. 1, 2, 3, 7
2025
-
[37]
Generative and contrastive self-supervised learning for graph anomaly detection.IEEE Transactions on Knowledge and Data Engineering, 35(12):12220–12233, 2021
Yu Zheng, Ming Jin, Yixin Liu, Lianhua Chi, Khoa T Phan, and Yi-Ping Phoebe Chen. Generative and contrastive self-supervised learning for graph anomaly detection.IEEE Transactions on Knowledge and Data Engineering, 35(12):12220–12233, 2021. 1 11
2021
-
[38]
Anomalyclip: Object-agnostic prompt learning for zero-shot anomaly detection
Qihang Zhou, Guansong Pang, Yu Tian, Shibo He, and Jiming Chen. Anomalyclip: Object-agnostic prompt learning for zero-shot anomaly detection. InProceedings of The International Conference on Learning Representations, 2024. 1, 2, 3, 7
2024
-
[39]
Fine-grained abnormality prompt learning for zero-shot anomaly detection
Jiawen Zhu, Yew-Soon Ong, Chunhua Shen, and Guansong Pang. Fine-grained abnormality prompt learning for zero-shot anomaly detection. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22241–22251, 2025. 1, 2, 3, 7
2025
-
[40]
Toward generalist anomaly detection via in-context residual learning with few-shot sample prompts
Jiawen Zhu and Guansong Pang. Toward generalist anomaly detection via in-context residual learning with few-shot sample prompts. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17826–17836, 2024. 2, 3, 7 12 A More Implmentation Details A.1 Details of Visual Tool Use AnomalyAgent equips the MLLM agent with a set o...
2024
-
[41]
Examine the image for potential anomalies (color, texture, shape, patterns, structure)
-
[42]
Decide whether additional image processing is needed
-
[43]
decision
Either: - Call exactly ONE image-processing tool using the tool calling mechanism, OR - Skip tool calling if you have already identified obvious anomalies. IMPORTANT (CRITICAL PROTOCOL — MUST FOLLOW EXACTLY): You MUST ALWAYS provide a JSON object in the assistant message content with the following structure: { "decision": "call_tool" or "skip_tool", "pote...
-
[44]
Decide whether new information is needed
-
[45]
Either: - Call exactly ONE image-processing tool (prefer a tool NOT used previously; if all tools were used, you may reuse one with a different focus), OR - Skip tool calling if the existing evidence is sufficient
-
[46]
decision
Provide refined potential anomalies and a refined heuristic prompt. IMPORTANT (CRITICAL PROTOCOL — MUST FOLLOW EXACTLY): You MUST ALWAYS provide a JSON object in the assistant message content with the following structure: { "decision": "call_tool" or "skip_tool", "image_target": "raw" or "augmented", "potential_anomalies": "Refined description of suspecte...
-
[47]
anomaly_candidates: 10-12 short phrases or sentences describing anomalies such as: - Surface issues (scratches, cracks, dents, stains) - Deformations (bent, warped, misshapen) - Missing parts (broken, incomplete) - Contamination (dirty, discolored, foreign objects) - Label issues (misaligned, damaged labels)
-
[48]
anomaly_candidates
normal_candidates: The same quantity as anomaly_candidates, describing the object in complete and intact state. Guidelines: - Each candidate MUST be a short phrase or sentence (1-10 words). - Candidates should be specific and concrete. - Do NOT repeat similar descriptions. - anomaly_candidates should focus on defect/anomaly characteristics. - normal_candi...
-
[49]
Decide whether the image caption likely misled the reasoner into calling this normal sample anomalous
-
[50]
If the caption was misleading, write one concise hard-negative description: a visual cue that sounds suspicious in the caption but is actually normal for this class/sample
-
[51]
caption_misled_reasoner
If the caption was not the cause of the mistake, do not invent a hard-negative description. Return JSON only: {{ "caption_misled_reasoner": true or false, "hard_negative_description": "Concise description, or empty string if not applicable.", "misleading_caption_evidence": "What phrase or visual framing was misleading, or empty string.", "why_normal_for_t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.