Escaping the Linearity Trap: Manifold Detours for Black-Box Adversarial Attacks on Singing Audio Deepfake Detection
Pith reviewed 2026-06-30 18:56 UTC · model grok-4.3
The pith
MARS uses bi-level optimization to guide adversarial attacks on singing deepfake detectors toward the natural semantic manifold, escaping the linearity trap and improving transfer success rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
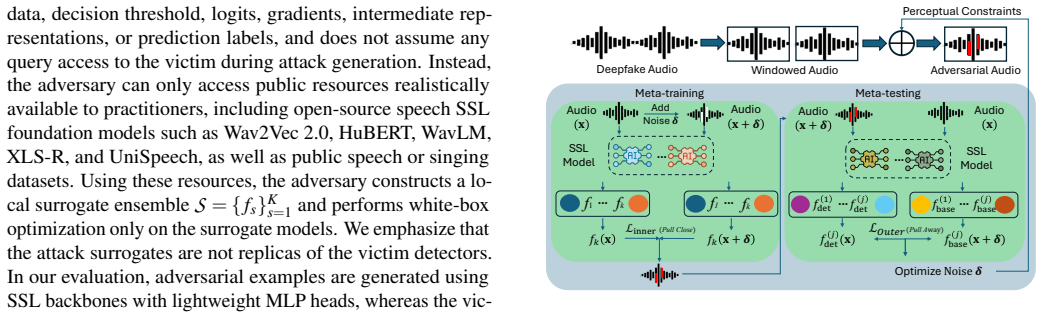
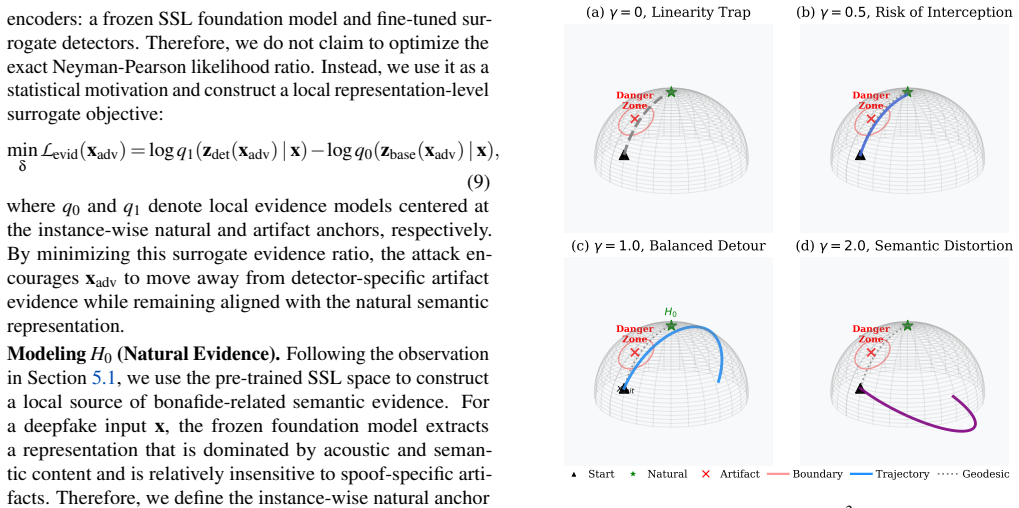
Existing attacks fail because they optimize cross-entropy on local surrogates and follow dominant gradient directions aligned with fine-tuned artifact-sensitive features, a geometric issue called the Linearity Trap. MARS escapes this by shifting to hypothesis-evidence manipulation using a natural semantic anchor from pre-trained SSL space and an artifact anchor from fine-tuned space, with bi-level optimization where the inner stage induces tangential exploration and the outer stage guides toward the natural semantic manifold.
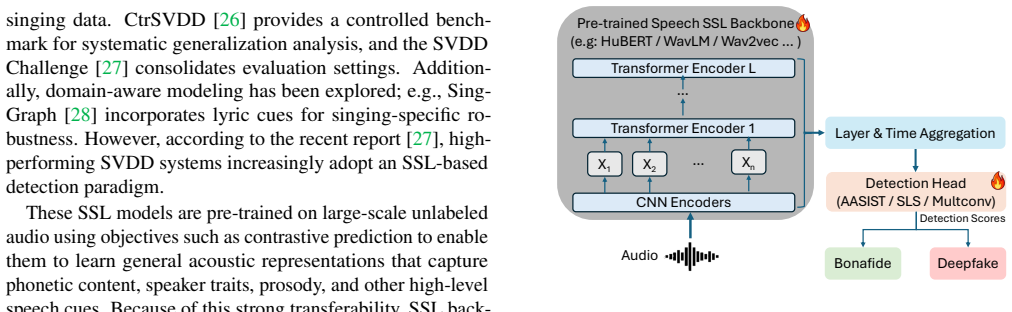
What carries the argument
MARS (Meta-Adversarial Regression of Semantics), a bi-level optimization framework that performs inner tangential exploration and outer guidance to the natural semantic manifold using anchors from pre-trained and fine-tuned SSL spaces.
If this is right
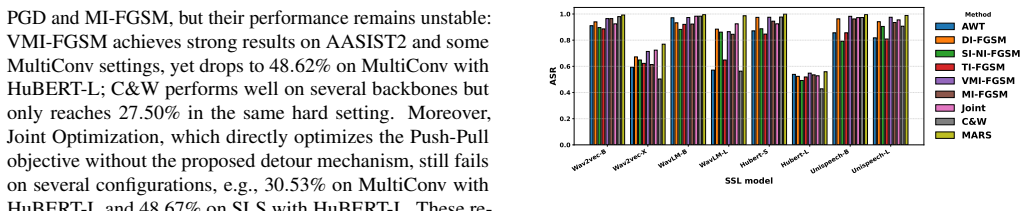
- MARS achieves higher attack success rates in in-distribution transfer by 13% on CtrSVDD.
- Out-of-distribution transfer improves by 10%.
- Cross-task evaluation shows 36% better ASR.
- The approach highlights that SSL-SVDD systems require more robust defenses against manifold-aware attacks.
Where Pith is reading between the lines
- Similar manifold-detour techniques might improve attack transferability in other audio or image deepfake detection tasks.
- If the linearity trap is general, then many fine-tuned SSL models in security applications could be vulnerable to attacks that target pre-trained representations.
- Detectors could be hardened by incorporating manifold regularization during training to resist such detours.
Load-bearing premise
The bi-level optimization will successfully suppress shared spoof evidence by guiding to the natural semantic manifold without being trapped by surrogate-specific directions.
What would settle it
Running standard gradient-based attacks versus MARS on the CtrSVDD benchmark and finding no improvement or lower ASR in transfer settings would falsify the claim.
Figures



read the original abstract
Recent Singing Voice Synthesis (SVS) advances enable highly realistic but potentially malicious AI covers, making singing voice deepfake detection (SVDD) crucial. Self-Supervised Learning (SSL)-based detectors achieve state-of-the-art performance by fine-tuning speech SSL backbones to capture singing-specific spoof artifacts. Existing adversarial attacks often fail against SSL-SVDD, creating a false impression of inherent robustness. We reveal this stems from two challenges. First, at the objective level, attacks optimize cross-entropy on local surrogates, crossing surrogate-specific boundaries rather than suppressing shared spoof evidence. Second, at the method level, attacks follow the surrogate's dominant gradient direction. In SSL-SVDD, this aligns with fine-tuned artifact-sensitive directions, limiting transferability to unseen detectors - a geometric failure we term the Linearity Trap. To properly evaluate robustness, we propose MARS (Meta-Adversarial Regression of Semantics), a transfer-based black-box framework tailored to SSL-SVDD. Structurally, MARS shifts to hypothesis-evidence manipulation by constructing a natural semantic anchor from the pre-trained SSL space and an artifact anchor from the fine-tuned space. Algorithmically, MARS escapes the Linearity Trap via bi-level optimization: the inner stage induces tangential exploration, while the outer stage guides the audio toward the natural semantic manifold. Experiments on the CtrSVDD benchmark show MARS improves Attack Success Rate (ASR) in in-distribution transfer (13%), out-of-distribution transfer (10%), and cross-task evaluation (36%), highlighting the urgent need for robust SVDD systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MARS (Meta-Adversarial Regression of Semantics), a transfer-based black-box attack framework for SSL-based singing voice deepfake detectors. It diagnoses the 'Linearity Trap' as attacks following surrogate-specific gradients aligned with fine-tuned artifact directions rather than suppressing shared spoof evidence. MARS constructs a natural semantic anchor from pre-trained SSL space and an artifact anchor from fine-tuned space, then applies bi-level optimization (inner tangential exploration, outer manifold guidance) to improve transferability, claiming ASR gains of 13% (in-distribution), 10% (out-of-distribution), and 36% (cross-task) on the CtrSVDD benchmark.
Significance. If the central geometric mechanism is validated, the work would be significant for adversarial robustness evaluation in audio deepfake detection, especially for singing voice synthesis threats. It offers a manifold-based alternative to standard surrogate attacks and reports concrete transfer gains that could inform defense design. The explicit use of pre-trained vs. fine-tuned SSL spaces for anchor construction is a potentially reusable idea if supported by diagnostics.
major comments (3)
- [Method (bi-level optimization description)] The core hypothesis that pre-trained SSL provides a 'natural semantic anchor' distinct from artifact-sensitive directions in the fine-tuned space (and that this suppresses shared spoof evidence) lacks any embedding-space diagnostics, distance metrics, or visualization in the experiments. This assumption is load-bearing for the claim that MARS escapes the Linearity Trap rather than simply altering surrogate gradients.
- [Experiments section] The reported ASR improvements (13/10/36%) are presented without error bars, statistical significance tests, or ablation studies that isolate the bi-level components (inner tangential exploration and outer manifold guidance) from confounds such as total query budget or surrogate selection. Without these, attribution to the proposed geometric escape cannot be verified.
- [Algorithmic description of MARS] No convergence analysis, perturbation norm bounds, or content-preservation metrics (e.g., perceptual similarity to original singing audio) are provided for the bi-level optimization, leaving open whether the output lands closer to the natural manifold while remaining a valid adversarial example.
minor comments (1)
- [Abstract and introduction] The term 'hypothesis-evidence manipulation' is introduced in the abstract but not formally defined or connected to the anchor construction in the method section.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major comment point-by-point below, providing clarifications and committing to revisions that strengthen the validation of our claims.
read point-by-point responses
-
Referee: [Method (bi-level optimization description)] The core hypothesis that pre-trained SSL provides a 'natural semantic anchor' distinct from artifact-sensitive directions in the fine-tuned space (and that this suppresses shared spoof evidence) lacks any embedding-space diagnostics, distance metrics, or visualization in the experiments. This assumption is load-bearing for the claim that MARS escapes the Linearity Trap rather than simply altering surrogate gradients.
Authors: We agree that direct embedding-space diagnostics would strengthen the geometric interpretation. The manuscript uses the observed ASR gains in cross-task transfer (36%) as indirect evidence that the anchors are distinct and that the bi-level optimization suppresses surrogate-specific artifact directions rather than merely altering gradients. In revision, we will add t-SNE visualizations of the pre-trained versus fine-tuned SSL spaces and cosine similarity metrics between the semantic and artifact anchors to provide explicit support for the hypothesis. revision: yes
-
Referee: [Experiments section] The reported ASR improvements (13/10/36%) are presented without error bars, statistical significance tests, or ablation studies that isolate the bi-level components (inner tangential exploration and outer manifold guidance) from confounds such as total query budget or surrogate selection. Without these, attribution to the proposed geometric escape cannot be verified.
Authors: The referee correctly notes a gap in experimental rigor. The reported gains are point estimates without measures of variability or component isolation. We will revise the experiments section to include error bars from multiple independent runs, statistical significance tests on the ASR differences, and targeted ablations that vary the inner and outer optimization stages independently while controlling for query budget and surrogate choice. revision: yes
-
Referee: [Algorithmic description of MARS] No convergence analysis, perturbation norm bounds, or content-preservation metrics (e.g., perceptual similarity to original singing audio) are provided for the bi-level optimization, leaving open whether the output lands closer to the natural manifold while remaining a valid adversarial example.
Authors: We acknowledge that the current manuscript omits these analyses for the bi-level optimization procedure. The framework is intended to produce perturbations that remain on or near the natural manifold, but without reported diagnostics this property is not explicitly verified. In the revised version, we will include convergence plots for the inner and outer loops, L2 perturbation norm statistics, and content-preservation metrics such as perceptual similarity scores to confirm that adversarial examples preserve singing audio quality. revision: yes
Circularity Check
No circularity; new framework with external benchmark validation
full rationale
The paper presents MARS as a novel bi-level optimization framework that constructs semantic and artifact anchors from pre-trained and fine-tuned SSL spaces, then applies inner tangential exploration and outer manifold guidance. The central claims rest on algorithmic novelty and reported ASR gains on the external CtrSVDD benchmark rather than any reduction of outputs to fitted inputs, self-definitional constructs, or load-bearing self-citations. No equations or derivations in the provided text reduce predictions to the method's own definitions by construction, and the derivation chain remains self-contained against external evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption SSL models possess a pre-trained space containing natural semantics separable from a fine-tuned space containing artifact-sensitive directions
invented entities (3)
-
natural semantic anchor
no independent evidence
-
artifact anchor
no independent evidence
-
Linearity Trap
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Beyond Waveform Robustness: Robust Feature-Vocoder Adversarial Attacks on Automatic Speech Recognition
Introduces a feature-vocoder adversarial attack on ASR using SSL representations that reports +26.6 WER black-box transfer and +36.2 WER defense resistance over baselines.
Reference graph
Works this paper leans on
-
[1]
Diffsinger: Singing voice synthesis via shallow diffusion mechanism,
J. Liu, C. Li, Y . Ren, F. Chen, and Z. Zhao, “Diffsinger: Singing voice synthesis via shallow diffusion mechanism,” inThirty-Sixth AAAI Conference on Artificial Intelligence, AAAI 2022, Thirty-Fourth Conference on Innovative Applications of Artificial Intelligence, IAAI 2022, The Twelveth Symposium on Educational Advances in Artificial Intelligence, EAAI...
2022
-
[2]
AAAI Press, 2022, pp. 11 020–11 028. [Online]. Available: https://doi.org/10.1609/aaai.v36i10.21350 1
-
[3]
Nnsvs: A neural network-based singing voice synthesis toolkit,
R. Yamamoto, R. Yoneyama, and T. Toda, “Nnsvs: A neural network-based singing voice synthesis toolkit,” inICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5. 1
2023
-
[4]
Muskits: an end-to-end music processing toolkit for singing voice synthesis,
J. Shi, S. Guo, T. Qian, N. Huo, T. Hayashi, Y . Wu, F. Xu, X. Chang, H. Li, P. Wuet al., “Muskits: an end-to-end music processing toolkit for singing voice synthesis,” arXiv preprint arXiv:2205.04029, 2022. 1
-
[5]
(2023) The ai-generated song that sounds just like drake
BBC News. (2023) The ai-generated song that sounds just like drake. Accessed: 2026-01-29. [Online]. Available: https://www.bbc.com/news/articles/ cwyd3r62kp5o 1
2023
-
[6]
A review of modern audio deepfake detection methods: challenges and future directions,
Z. Almutairi and H. Elgibreen, “A review of modern audio deepfake detection methods: challenges and future directions,”Algorithms, vol. 15, no. 5, p. 155, 2022. 1
2022
-
[7]
Deepfake media forensics: Sta- tus and future challenges,
I. Amerini, M. Barni, S. Battiato, P. Bestagini, G. Boato, V . Bruni, R. Caldelli, F. De Natale, R. De Nicola, L. Guarneraet al., “Deepfake media forensics: Sta- tus and future challenges,”Journal of Imaging, vol. 11, no. 3, p. 73, 2025. 1
2025
-
[8]
Svdd 2024: The inaugural singing voice deep- fake detection challenge,
Y . Zhang, Y . Zang, J. Shi, R. Yamamoto, T. Toda, and Z. Duan, “Svdd 2024: The inaugural singing voice deep- fake detection challenge,” in2024 IEEE Spoken Lan- guage Technology Workshop (SLT). IEEE, 2024, pp. 782–787. 1
2024
-
[9]
Singfake: Singing voice deepfake detection,
Y . Zang, Y . Zhang, M. Heydari, and Z. Duan, “Singfake: Singing voice deepfake detection,” inICASSP 2024- 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 12 156–12 160. 1
2024
-
[10]
Xwsb: A blend system utilizing xls-r and wavlm with sls classifier detection system for svdd 2024 challenge,
Q. Zhang, S. Wen, F. Yan, T. Hu, and J. Li, “Xwsb: A blend system utilizing xls-r and wavlm with sls classifier detection system for svdd 2024 challenge,” in2024 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2024, pp. 788–794. 1, 8
2024
-
[11]
Black- box attacks on spoofing countermeasures using transfer- ability of adversarial examples
Y . Zhang, Z. Jiang, J. Villalba, and N. Dehak, “Black- box attacks on spoofing countermeasures using transfer- ability of adversarial examples.” inInterspeech, 2020, pp. 4238–4242. 1, 2
2020
-
[12]
Transferable adversarial attacks on audio deepfake de- tection,
M. U. Farooq, A. Khan, K. Uddin, and K. M. Malik, “Transferable adversarial attacks on audio deepfake de- tection,” inProceedings of the Winter Conference on Applications of Computer Vision, 2025, pp. 1640–1649. 1, 2
2025
-
[13]
Nesterov accelerated gradient and scale invariance for adversarial attacks,
J. Lin, C. Song, K. He, L. Wang, and J. E. Hopcroft, “Nesterov accelerated gradient and scale invariance for adversarial attacks,”arXiv preprint arXiv:1908.06281,
-
[14]
Enhancing the transferability of adversarial attacks through variance tuning,
X. Wang and K. He, “Enhancing the transferability of adversarial attacks through variance tuning,” inProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 1924–1933. 1, 2, 3, 8
2021
-
[15]
Boosting adver- sarial transferability via negative hessian trace regular- ization,
Y . Long, Z. Tian, L. Zhang, and H. Xu, “Boosting adver- sarial transferability via negative hessian trace regular- ization,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 2386–2395. 1, 2, 3
2025
-
[16]
Improving transferability of adversarial examples with input diversity,
C. Xie, Z. Zhang, Y . Zhou, S. Bai, J. Wang, Z. Ren, and A. L. Yuille, “Improving transferability of adversarial examples with input diversity,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 2730–2739. 1, 2, 3, 8
2019
-
[17]
Evading defenses to transferable adversarial examples by translation- invariant attacks,
Y . Dong, T. Pang, H. Su, and J. Zhu, “Evading defenses to transferable adversarial examples by translation- invariant attacks,” inProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, 2019, pp. 4312–4321. 1, 2, 3, 8
2019
-
[18]
Improving the transferability of adversarial samples with adversarial transformations,
W. Wu, Y . Su, M. R. Lyu, and I. King, “Improving the transferability of adversarial samples with adversarial transformations,” inProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, 2021, pp. 9024–9033. 1, 2, 3
2021
-
[19]
Enhancing adversarial transfer- ability with adversarial weight tuning,
J. Chen, Z. Feng, R. Zeng, Y . Pu, C. Zhou, Y . Jiang, Y . Gan, J. Li, and S. Ji, “Enhancing adversarial transfer- ability with adversarial weight tuning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 2, 2025, pp. 2061–2069. 1, 2, 3, 8
2025
-
[20]
Ix. on the problem of the most efficient tests of statistical hypotheses,
J. Neyman and E. S. Pearson, “Ix. on the problem of the most efficient tests of statistical hypotheses,”Philosoph- ical Transactions of the Royal Society of London. Series A, Containing Papers of a Mathematical or Physical Character, vol. 231, no. 694-706, pp. 289–337, 1933. 2, 4
1933
-
[21]
Diffsvc: A diffusion probabilistic model for singing voice conversion,
S. Liu, Y . Cao, D. Su, and H. Meng, “Diffsvc: A diffusion probabilistic model for singing voice conversion,” inIEEE Automatic Speech Recognition and Understanding Workshop, ASRU 2021, Cartagena, Colombia, December 13-17, 2021. IEEE, 2021, pp. 14 741–748. [Online]. Available: https://doi.org/10.1109/ ASRU51503.2021.9688219 2
-
[22]
A hierarchical speaker representation framework for one-shot singing voice conversion,
X. Li, S. Liu, and Y . Shan, “A hierarchical speaker representation framework for one-shot singing voice conversion,” in23rd Annual Conference of the International Speech Communication Association, Interspeech 2022, Incheon, Korea, September 18- 22, 2022, H. Ko and J. H. L. Hansen, Eds. ISCA, 2022, pp. 4307–4311. [Online]. Available: https://doi.org/10.21...
-
[23]
Improving ad- versarial waveform generation based singing voice con- version with harmonic signals,
H. Guo, Z. Zhou, F. Meng, and K. Liu, “Improving ad- versarial waveform generation based singing voice con- version with harmonic signals,” inIEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2022, Virtual and Singapore, 23-27 May
2022
-
[24]
ADD 2022: The first audio deep synthesis detection challenge,
IEEE, 2022, pp. 6657–6661. [Online]. Available: https://doi.org/10.1109/ICASSP43922.2022.9746709 2
-
[25]
The singing voice conversion challenge 2023,
W. Huang, L. P. Violeta, S. Liu, J. Shi, Y . Yasuda, and T. Toda, “The singing voice conversion challenge 2023,” CoRR, vol. abs/2306.14422, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2306.14422 2
-
[26]
An Extensive Analysis of the Singing Voice Conversion Challenge 2025 Evaluation Results
L. P. Violeta, X. Zhang, J. Shi, Y . Yasuda, W. Huang, Z. Wu, and T. Toda, “The singing voice conversion challenge 2025: From singer identity conversion to singing style conversion,” CoRR, vol. abs/2509.15629, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2509.15629 2
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.15629 2025
-
[27]
Efficient Learning on Successive Test Time Augmentation,
Y . Zang, Y . Zhang, M. Heydari, and Z. Duan, “Singfake: Singing voice deepfake detection,” inIEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2024, Seoul, Republic of Korea, April 14-19, 2024. IEEE, 2024, pp. 12 156–12 160. [Online]. Available: https://doi.org/10. 1109/ICASSP48485.2024.10448184 2
-
[28]
Ctrsvdd: A benchmark dataset and baseline analysis for controlled singing voice deepfake detection,
Y . Zang, J. Shi, Y . Zhang, R. Yamamoto, J. Han, Y . Tang, S. Xu, W. Zhao, J. Guo, T. Toda, and Z. Duan, “Ctrsvdd: A benchmark dataset and baseline analysis for controlled singing voice deepfake detection,” in25th Annual Conference of the International Speech Communication Association, Interspeech 2024, Kos, Greece, September 1-5, 2024, I. Lapidot and S....
-
[29]
SVDD 2024: The inaugural singing voice deepfake detection challenge,
Y . Zhang, Y . Zang, J. Shi, R. Yamamoto, T. Toda, and Z. Duan, “SVDD 2024: The inaugural singing voice deepfake detection challenge,” inIEEE Spoken Language Technology Workshop, SLT 2024, Macao, December 2-5, 2024. IEEE, 2024, pp. 782–787. [Online]. Available: https://doi.org/10.1109/SLT61566. 2024.10832284 3, 8
-
[30]
Singing voice graph modeling for singfake detection,
X. Chen, H. Wu, R. Jang, and H. Lee, “Singing voice graph modeling for singfake detection,” in 25th Annual Conference of the International Speech Communication Association, Interspeech 2024, Kos, Greece, September 1-5, 2024, I. Lapidot and S. Gannot, Eds. ISCA, 2024. [Online]. Available: https://doi.org/10.21437/Interspeech.2024-1185 3
-
[31]
Hubert: Self- supervised speech representation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhutdinov, and A. Mohamed, “Hubert: Self- supervised speech representation learning by masked prediction of hidden units,”IEEE/ACM transactions on audio, speech, and language processing, vol. 29, pp. 3451–3460, 2021. 3, 8
2021
-
[32]
Wavlm: Large-scale self-supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiaoet al., “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022. 3, 8
2022
-
[33]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,”Advances in neural infor- mation processing systems, vol. 33, pp. 12 449–12 460,
-
[34]
Xls-r: Self-supervised cross-lingual speech representation learning at scale,
A. Babu, C. Wang, A. Tjandra, K. Lakhotia, Q. Xu, N. Goyal, K. Singh, P. V on Platen, Y . Saraf, J. Pinoet al., “Xls-r: Self-supervised cross-lingual speech representa- tion learning at scale,”arXiv preprint arXiv:2111.09296,
-
[35]
Unispeech-sat: Uni- versal speech representation learning with speaker aware pre-training,
S. Chen, Y . Wu, C. Wang, Z. Chen, Z. Chen, S. Liu, J. Wu, Y . Qian, F. Wei, J. Liet al., “Unispeech-sat: Uni- versal speech representation learning with speaker aware pre-training,” inICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 6152–6156. 3, 8
2022
-
[36]
H. Tak, M. Todisco, X. Wang, J.-w. Jung, J. Yamagishi, and N. Evans, “Automatic speaker verification spoof- ing and deepfake detection using wav2vec 2.0 and data augmentation,”arXiv preprint arXiv:2202.12233, 2022. 3
-
[37]
Large-scale self-supervised speech representation learning for automatic speaker verification,
Z. Chen, S. Chen, Y . Wu, Y . Qian, C. Wang, S. Liu, Y . Qian, and M. Zeng, “Large-scale self-supervised speech representation learning for automatic speaker verification,” inICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 6147–6151. 3
2022
-
[38]
Explaining and Harnessing Adversarial Examples
I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,” in3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, Y . Bengio and Y . LeCun, Eds., 2015. [Online]. Available: http://arxiv.org/abs/ 1412.6572 3
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[39]
Towards deep learning models resistant to adversarial attacks,
A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to adversarial attacks,” in6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. OpenReview.net, 2018. [Online]. 15 Available: https://openreview.net/forum?id=rJzIBfZAb 3
2018
-
[40]
Adversarial attacks on spoofing countermeasures of automatic speaker verification,
S. Liu, H. Wu, H. Lee, and H. Meng, “Adversarial attacks on spoofing countermeasures of automatic speaker verification,” inIEEE Automatic Speech Recognition and Understanding Workshop, ASRU 2019, Singapore, December 14-18, 2019. IEEE, 2019, pp. 312–319. [Online]. Available: https: //doi.org/10.1109/ASRU46091.2019.9003763 3
-
[41]
Imperceptible, robust, and targeted adversarial examples for automatic speech recognition,
Y . Qin, N. Carlini, G. W. Cottrell, I. J. Goodfellow, and C. Raffel, “Imperceptible, robust, and targeted adversarial examples for automatic speech recognition,” inProceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, ser. Proceedings of Machine Learning Research, K. Chaudhuri and R....
2019
-
[42]
Understanding contrastive rep- resentation learning through alignment and uniformity on the hypersphere,
T. Wang and P. Isola, “Understanding contrastive rep- resentation learning through alignment and uniformity on the hypersphere,” inInternational conference on ma- chine learning. PMLR, 2020, pp. 9929–9939. 4
2020
-
[43]
The power spherical distribu- tion,
N. De Cao and W. Aziz, “The power spherical distribu- tion,”arXiv preprint arXiv:2006.04437, 2020. 4
-
[44]
V oice activity detection (vad) in noisy environ- ments,
J. Ball, “V oice activity detection (vad) in noisy environ- ments,”arXiv preprint arXiv:2312.05815, 2023. 7
-
[45]
Nes2net: A lightweight nested architecture for founda- tion model driven speech anti-spoofing,
T. Liu, D.-T. Truong, R. K. Das, K. A. Lee, and H. Li, “Nes2net: A lightweight nested architecture for founda- tion model driven speech anti-spoofing,”arXiv preprint arXiv:2504.05657, 2025. 8, 13
-
[46]
Aasist: Audio anti- spoofing using integrated spectro-temporal graph atten- tion networks,
J.-w. Jung, H.-S. Heo, H. Tak, H.-j. Shim, J. S. Chung, B.-J. Lee, H.-J. Yu, and N. Evans, “Aasist: Audio anti- spoofing using integrated spectro-temporal graph atten- tion networks,” inICASSP 2022-2022 IEEE interna- tional conference on acoustics, speech and signal pro- cessing (ICASSP). IEEE, 2022, pp. 6367–6371. 8
2022
-
[47]
Audio deepfake detec- tion with self-supervised xls-r and sls classifier,
Q. Zhang, S. Wen, and T. Hu, “Audio deepfake detec- tion with self-supervised xls-r and sls classifier,” inPro- ceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 6765–6773. 8
2024
-
[48]
Multi-level ssl feature gating for au- dio deepfake detection,
H. M. Tran, D. Lolive, A. Sini, A. Delhay, P.-F. Marteau, and D. Guennec, “Multi-level ssl feature gating for au- dio deepfake detection,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 11 766–11 775. 8
2025
-
[49]
Delving into Transferable Adversarial Examples and Black-box Attacks
Y . Liu, X. Chen, C. Liu, and D. Song, “Delving into transferable adversarial examples and black-box attacks,” arXiv preprint arXiv:1611.02770, 2016. 8
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[50]
Adversarial attacks on audio deepfake detection: A benchmark and comparative study,
K. Uddin, M. U. Farooq, A. Khan, and K. M. Ma- lik, “Adversarial attacks on audio deepfake detection: A benchmark and comparative study,”arXiv preprint arXiv:2509.07132, 2025. 8
-
[51]
Boosting adversarial attacks with momentum,
Y . Dong, F. Liao, T. Pang, H. Su, J. Zhu, X. Hu, and J. Li, “Boosting adversarial attacks with momentum,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 9185–9193. 8
2018
-
[52]
Comprehensive layer-wise analysis of ssl models for audio deepfake detection,
Y . El Kheir, Y . Samih, S. Maharjan, T. Polzehl, and S. Möller, “Comprehensive layer-wise analysis of ssl models for audio deepfake detection,” inFindings of the Association for Computational Linguistics: NAACL 2025, 2025, pp. 4070–4082. 9, 18
2025
-
[53]
Fsd: An initial chinese dataset for fake song detection,
Y . Xie, J. Zhou, X. Lu, Z. Jiang, Y . Yang, H. Cheng, and L. Ye, “Fsd: An initial chinese dataset for fake song detection,” inICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 4605–4609. 10
2024
-
[54]
Sonics: Synthetic or not–identifying counterfeit songs,
M. A. Rahman, Z. I. A. Hakim, N. H. Sarker, B. Paul, and S. A. Fattah, “Sonics: Synthetic or not–identifying counterfeit songs,”arXiv preprint arXiv:2408.14080,
-
[55]
Udio: The ai music creation platform,
Udio, “Udio: The ai music creation platform,” 2024, accessed: 2026-01-27. [Online]. Available: https://www.udio.com/ 10
2024
-
[56]
Suno: Make a song with ai,
Suno AI, “Suno: Make a song with ai,” 2024, accessed: 2026-01-27. [Online]. Available: https://suno.com/ 10
2024
-
[57]
Hybrid trans- formers for music source separation,
S. Rouard, F. Massa, and A. Défossez, “Hybrid trans- formers for music source separation,” inICASSP 23,
-
[58]
Perceptual evaluation of speech quality (pesq)-a new method for speech quality assessment of telephone networks and codecs,
A. W. Rix, J. G. Beerends, M. P. Hollier, and A. P. Hek- stra, “Perceptual evaluation of speech quality (pesq)-a new method for speech quality assessment of telephone networks and codecs,” in2001 IEEE international con- ference on acoustics, speech, and signal processing. Pro- ceedings (Cat. No. 01CH37221), vol. 2. IEEE, 2001, pp. 749–752. 12
2001
-
[59]
An algorithm for intelligibility prediction of time– frequency weighted noisy speech,
C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, “An algorithm for intelligibility prediction of time– frequency weighted noisy speech,”IEEE Transactions on audio, speech, and language processing, vol. 19, no. 7, pp. 2125–2136, 2011. 12
2011
-
[60]
Sdr–half-baked or well done?
J. Le Roux, S. Wisdom, H. Erdogan, and J. R. Hershey, “Sdr–half-baked or well done?” inICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp. 626–630. 12
2019
-
[61]
Spgm: Prioritizing local features for enhanced speech separa- tion performance,
J. Q. Yip, S. Zhao, Y . Ma, C. Ni, C. Zhang, H. Wang, T. H. Nguyen, K. Zhou, D. Ng, E. S. Chnget al., “Spgm: Prioritizing local features for enhanced speech separa- tion performance,” inICASSP 2024-2024 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 326–330. 12
2024
-
[62]
K.-T. Xu, F.-L. Xie, X. Tang, and Y . Hu, “Fireredasr: Open-source industrial-grade mandarin speech recogni- tion models from encoder-decoder to llm integration,” arXiv preprint arXiv:2501.14350, 2025. 13 16
-
[63]
Songbsab: A dual prevention approach against singing voice conversion based illegal song covers,
G. Chen, Y . Zhang, F. Song, T. Wang, X. Du, and Y . Liu, “Songbsab: A dual prevention approach against singing voice conversion based illegal song covers,” arXiv preprint arXiv:2401.17133, 2024. 13
-
[64]
I can hear you: Selec- tive robust training for deepfake audio detection,
Z. Zhang, W. Hao, A. Sankoh, W. Lin, E. Mendiola- Ortiz, J. Yang, and C. Mao, “I can hear you: Selec- tive robust training for deepfake audio detection,”arXiv preprint arXiv:2411.00121, 2024. 13
-
[65]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.”Iclr, vol. 1, no. 2, p. 3, 2022. 13 17 A Method A.1 Deepfake Effectiveness Performance Table 4: EER % of different SLS Deepfake Detectors (Mid-layer) on the CtrSVDD dataset. SSL Models EER (%) Wav2vec-B 8.39 Wav2vec-X ...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.