Choosing the right MCMC sampler: a systematic benchmark of gradient-free methods
Pith reviewed 2026-06-29 00:21 UTC · model grok-4.3
The pith
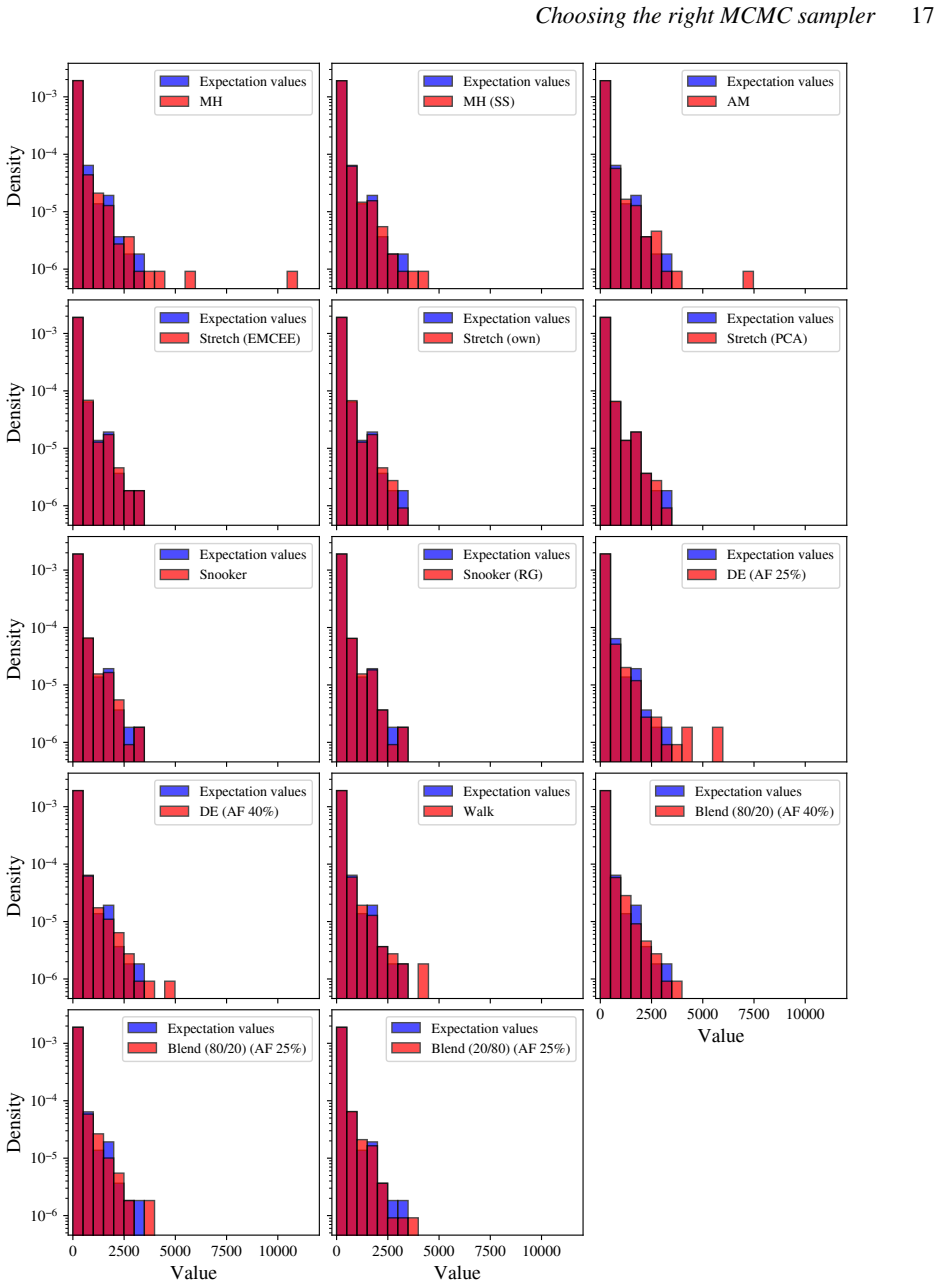
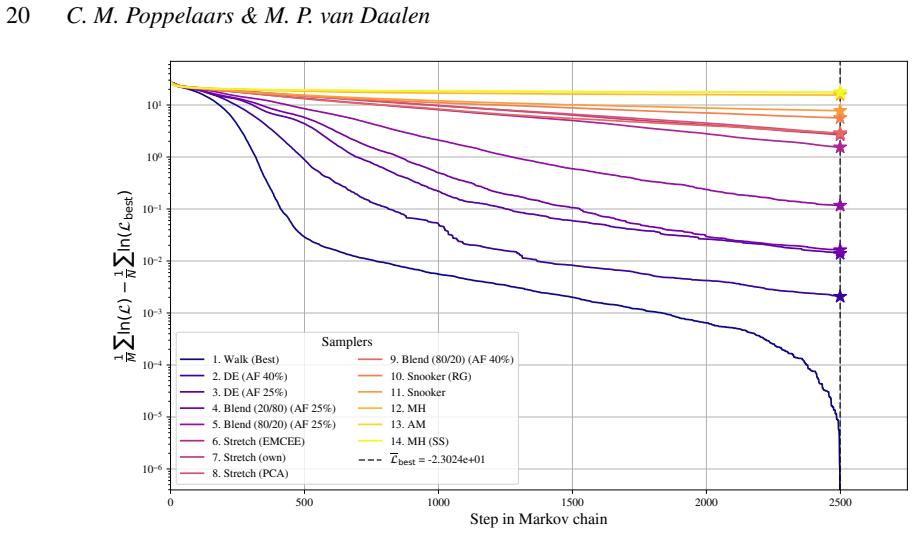
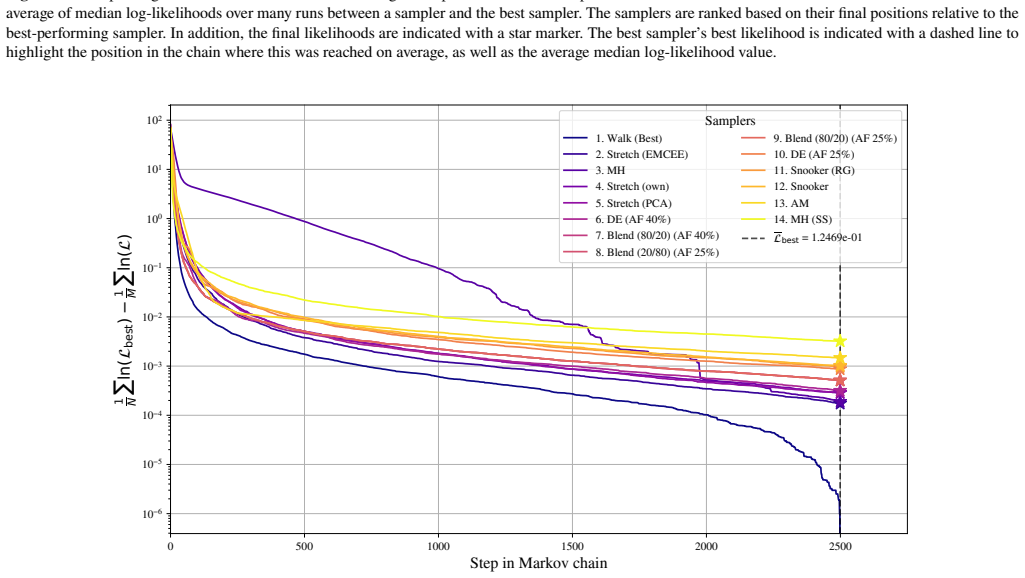
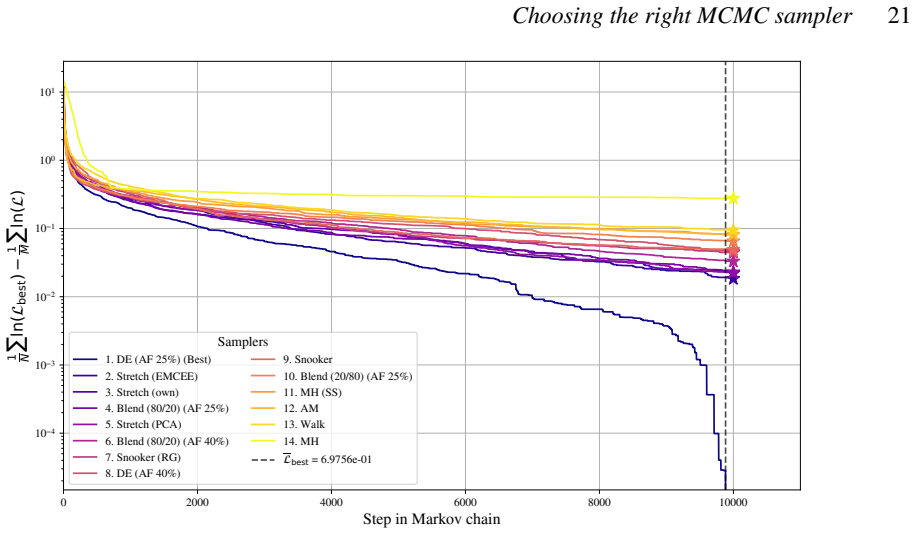
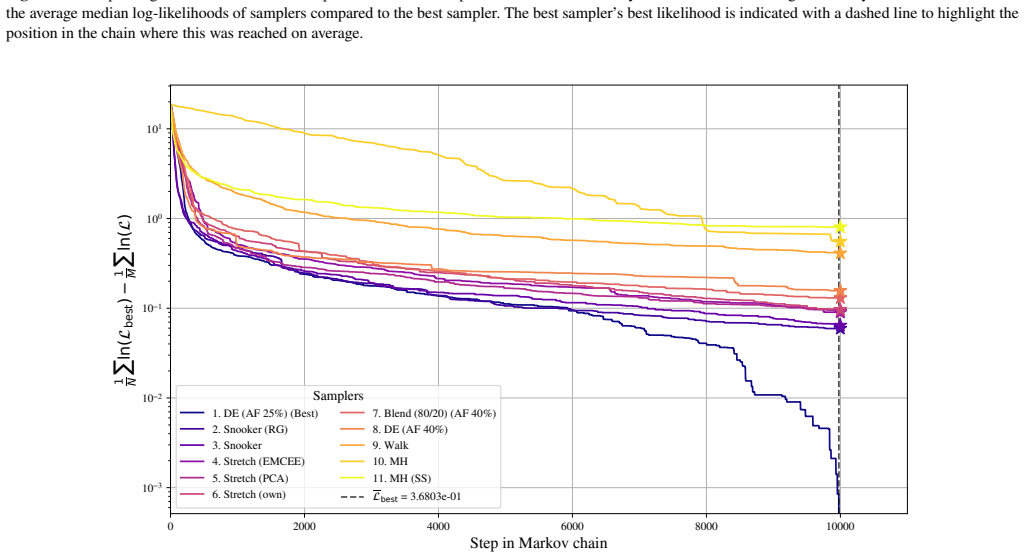
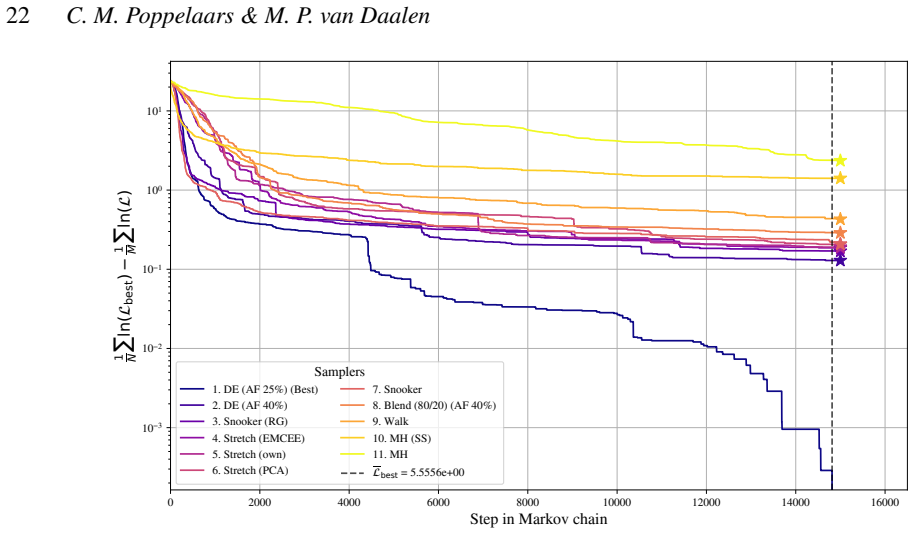
Differential evolution MCMC, tuned to 25 percent acceptance, outperforms stretch, walk, snooker and hybrid moves on the chosen test functions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
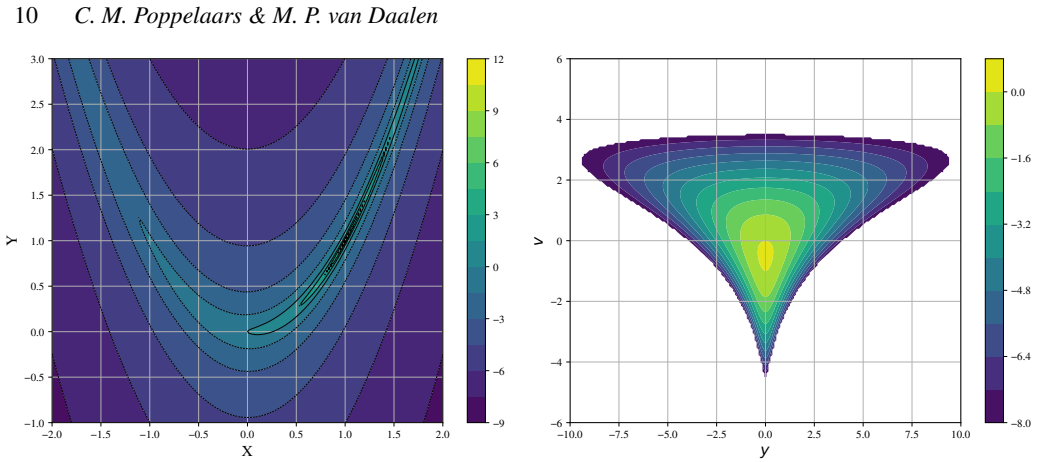
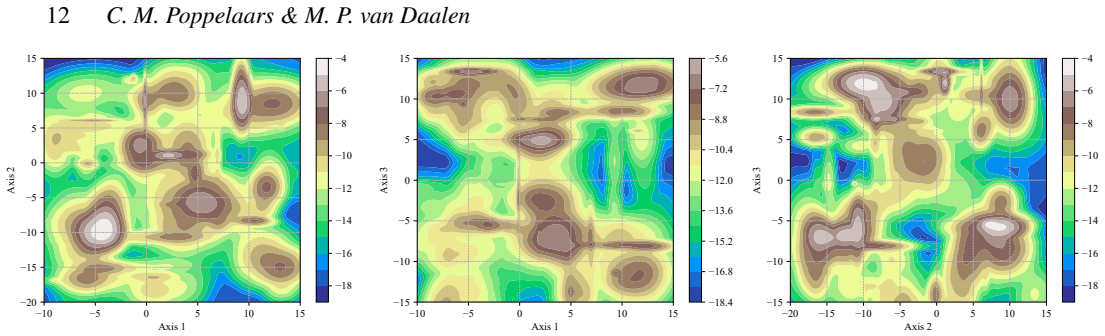
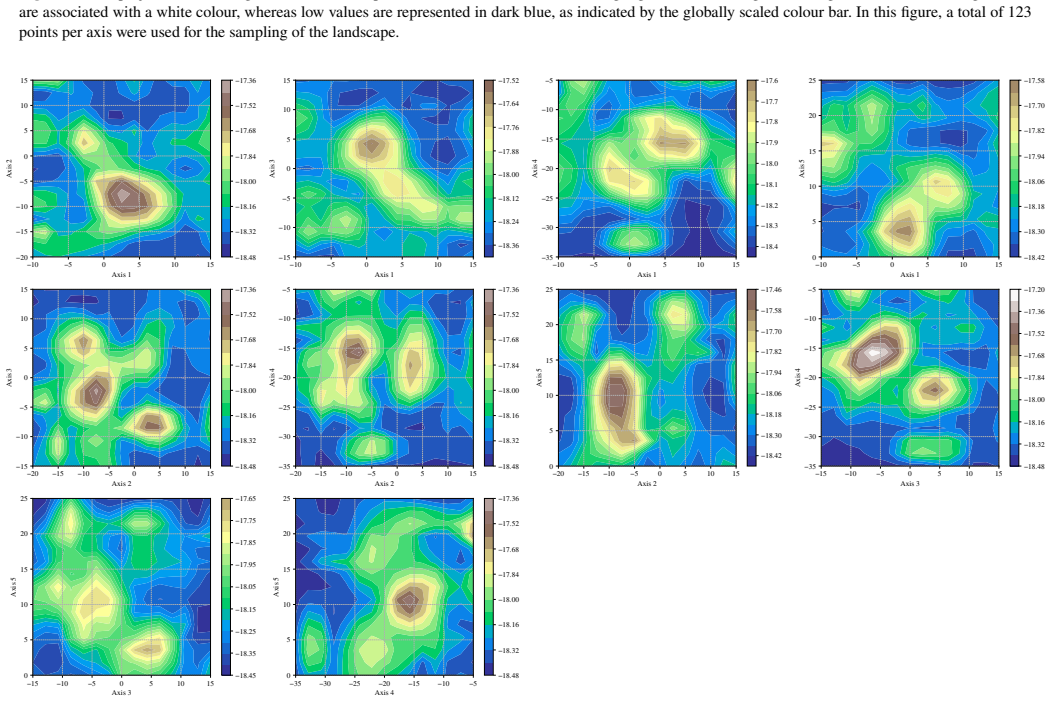
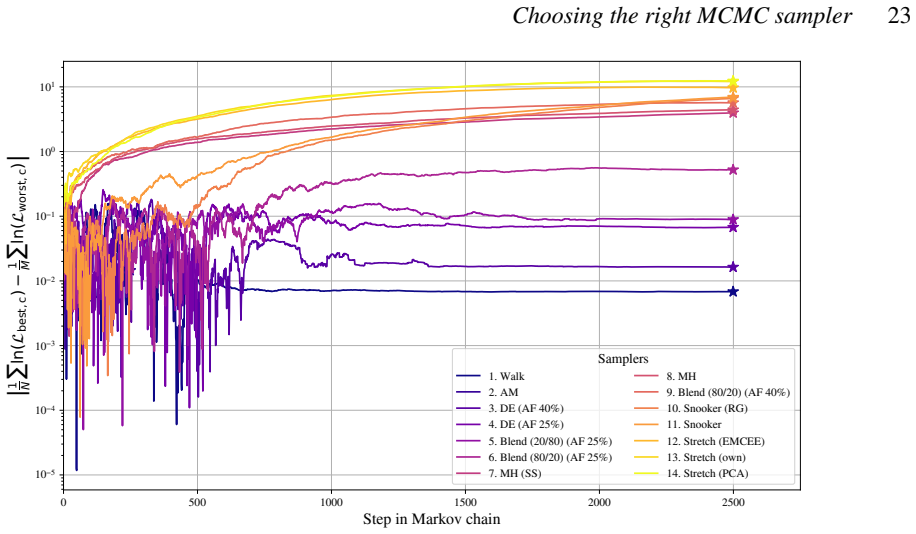
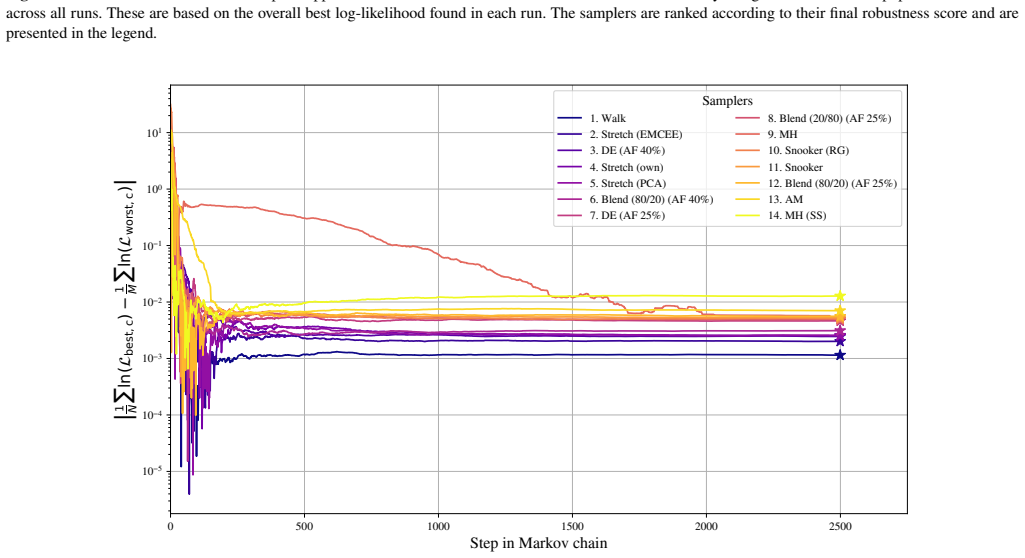
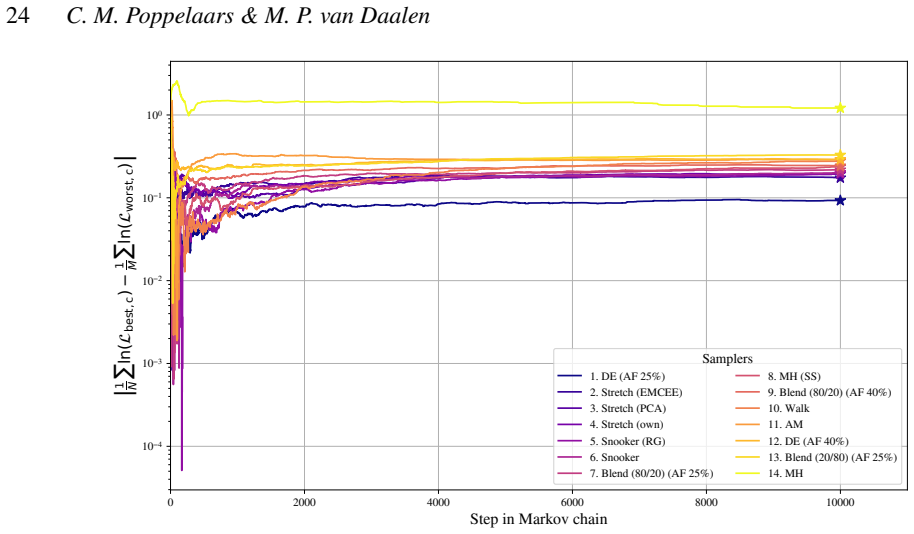
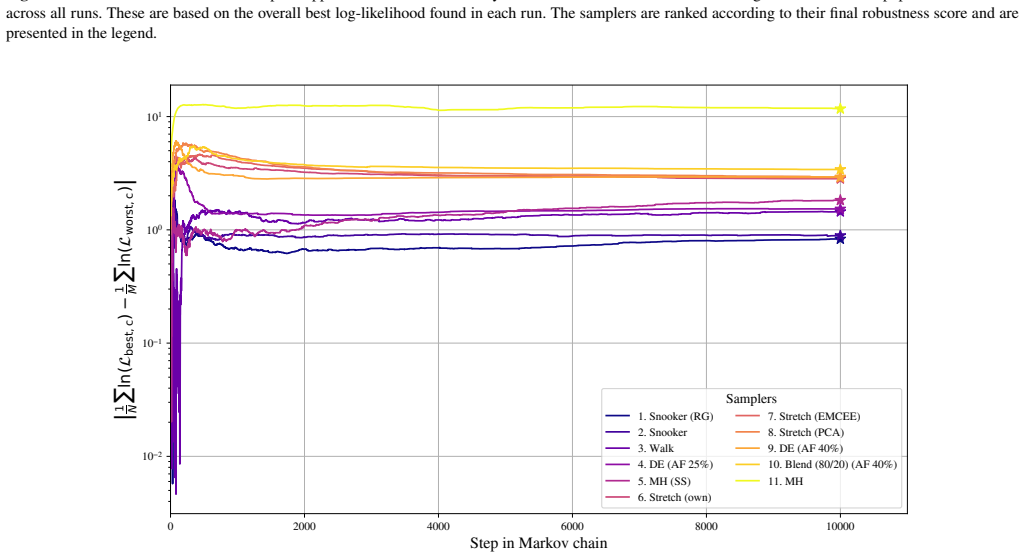
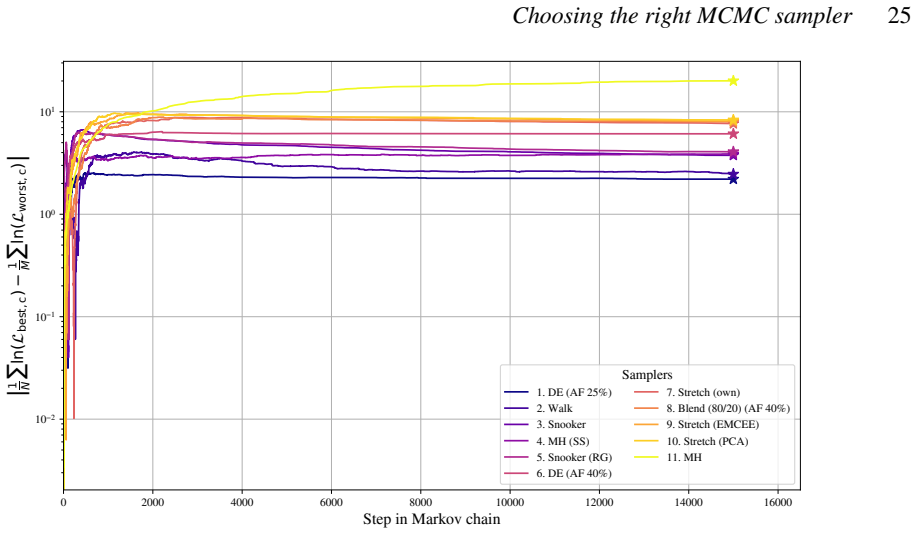
When the differential evolution move is tuned to a target acceptance fraction of 25 percent, it produces higher ergodicity, greater robustness across starting positions, and better likelihood performance than the stretch move, walk move, snooker move, PCA-modified stretch move, and hybrid blend move on the Rosenbrock, Neal's funnel, and multimodal Gaussian random landscapes.
What carries the argument
The differential evolution proposal step, adjusted to maintain a 25 percent acceptance rate, used inside an otherwise standard Metropolis-Hastings framework.
If this is right
- Astrophysical codes that currently default to stretch or walk moves could switch to differential evolution with a 25 percent acceptance target to reach higher-likelihood regions in fewer steps.
- The post-sampling optimization refinement becomes more valuable as dimension increases, suggesting it should be applied routinely after any MCMC run in problems with five or more parameters.
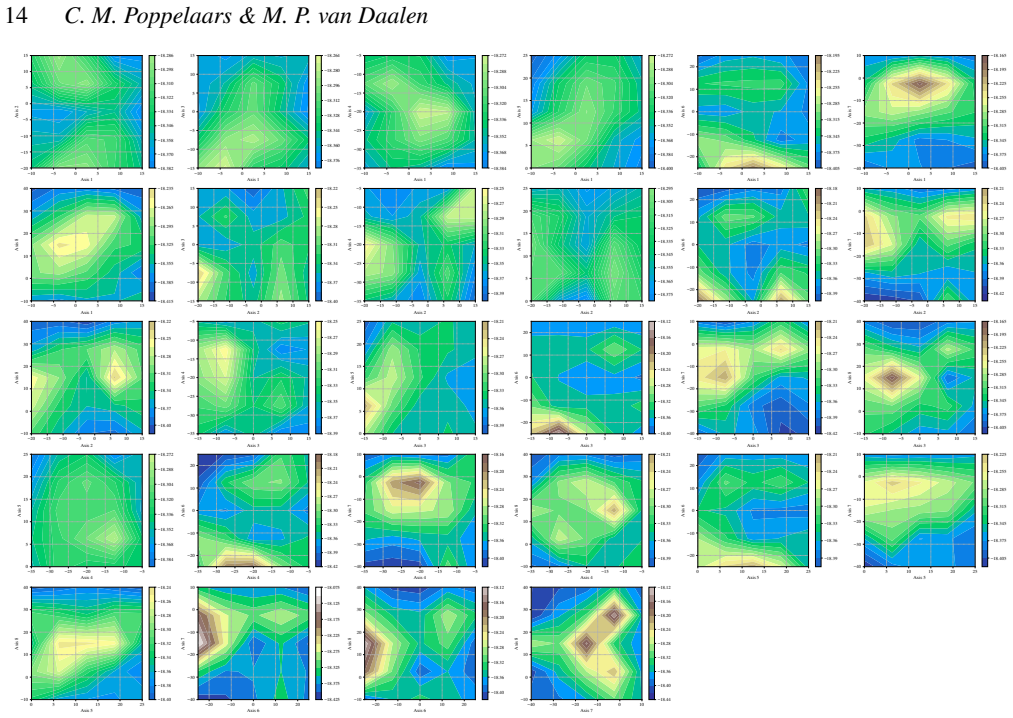
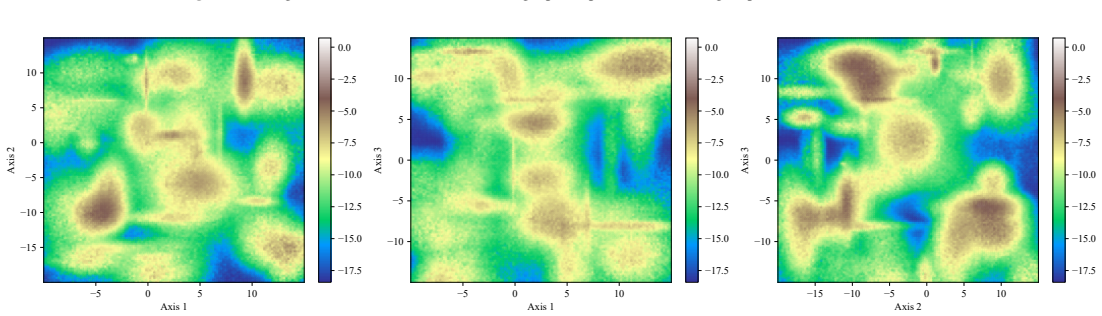
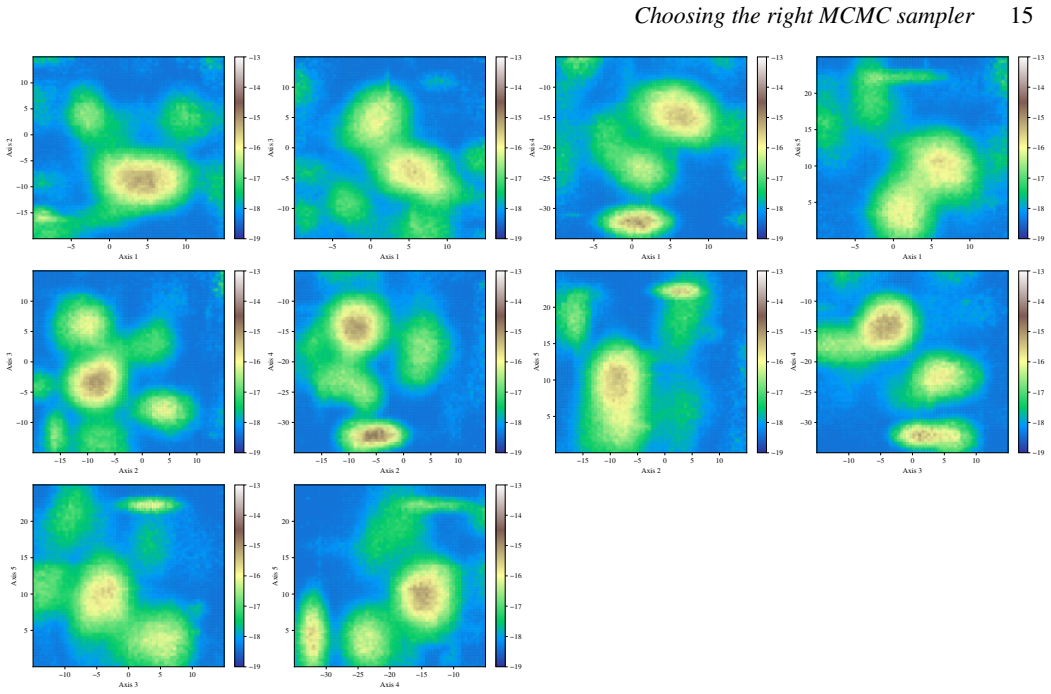
- Reconstruction of likelihood surfaces via quadtree from the sampled points offers a practical way to visualize and diagnose sampling quality without additional model evaluations.
- The relative ordering of samplers may shift if the target acceptance rate is left at its default value instead of being tuned to 25 percent.
Where Pith is reading between the lines
- If the performance ordering holds on real data, many existing MCMC pipelines in astronomy could reduce their burn-in time by adopting the tuned differential evolution move without changing any other part of the code.
- The same benchmark protocol could be applied to gradient-based samplers such as Hamiltonian Monte Carlo to test whether the advantage persists when gradients are available.
Load-bearing premise
The Rosenbrock, Neal's funnel, and low-dimensional Gaussian random fields capture the essential difficulties of the multimodal, high-dimensional likelihood surfaces that arise in actual astrophysical data analysis.
What would settle it
Run the same suite of samplers on a real eight-or-higher-dimensional astrophysical posterior, such as a weak-lensing or exoplanet transit fit, and record whether the tuned differential evolution chain still reaches the highest likelihood and mixes fastest.
Figures



read the original abstract
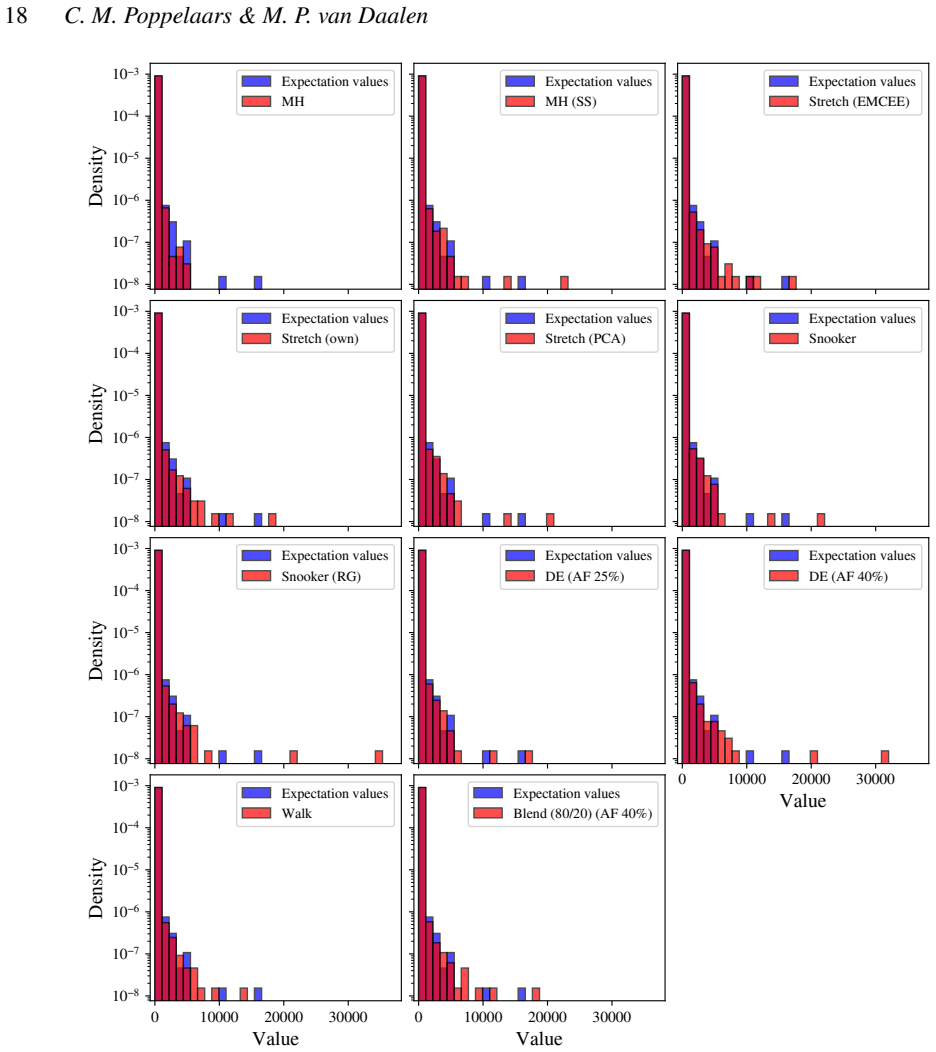
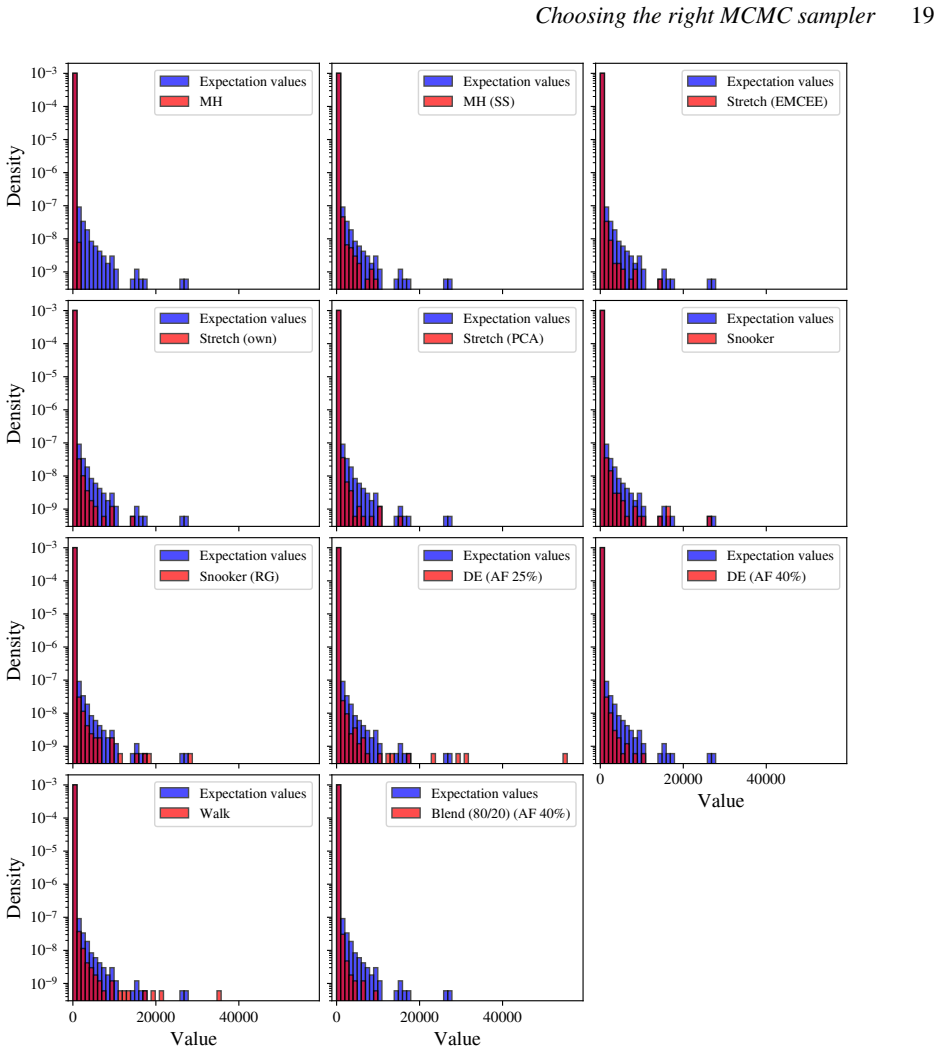
We present a set of metrics and methods for testing and comparing a range of modern gradient-free Markov Chain Monte Carlo (MCMC) samplers against the commonly used Metropolis-Hastings (MH) algorithm. The goal is to quantify key performance metrics, including sampler ergodicity, robustness and overall likelihood performance. To provide a controlled and interpretable testbed, we use the Rosenbrock function and Neal's funnel as representative unimodal cases, while Gaussian random likelihood landscapes in three, five, and eight dimensions serve as multimodal test scenarios. The samplers considered include affine-invariant moves from the literature, such as the stretch and walk moves, the differential evolution move, and the snooker move. We additionally introduce two novel variations: a modified stretch move that incorporates a Principal Component Analysis (PCA) transformation, and a hybrid blend move that combines features of both differential evolution and stretch dynamics. Beyond sampler evaluation, we demonstrate reconstructing likelihood landscapes from sampled points using a quadtree algorithm. Additionally, we explore the use of optimisation algorithms to refine the best parameter set in terms of its likelihood, and find consistent improvements in log-likelihood values, with the post-sampling gain becoming more significant in higher-dimensional problems. Our comparative results of sampler testing show that the differential evolution algorithm, when tuned to a target acceptance fraction of 25%, consistently outperforms all other samplers in terms of ergodicity, robustness, and likelihood performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript benchmarks gradient-free MCMC samplers (affine-invariant stretch/walk/snooker moves, differential evolution, and two novel variants: PCA-modified stretch and hybrid blend) against Metropolis-Hastings. Using Rosenbrock and Neal's funnel as unimodal tests plus Gaussian random landscapes in 3/5/8 dimensions as multimodal cases, it reports that differential evolution tuned to 25% target acceptance consistently outperforms others in ergodicity, robustness, and likelihood. Additional contributions include quadtree reconstruction of likelihood landscapes from samples and post-sampling optimization that improves log-likelihood, with larger gains in higher dimensions.
Significance. If the reported ranking is robust, the work supplies a controlled comparison that could inform sampler choice in astrophysical inference pipelines. The novel moves and quadtree method are concrete methodological additions. However, the low-dimensional synthetic test suite limits the strength of any general recommendation for real problems.
major comments (2)
- [Abstract and test-function sections] Abstract and test-function sections: the central claim that differential evolution (25% acceptance) 'consistently outperforms all other samplers' rests entirely on Rosenbrock, Neal's funnel, and Gaussian random landscapes in ≤8 dimensions. These lack the parameter degeneracies, non-Gaussian tails, expensive forward models, and dimensionality (>10–20) typical of astrophysical posteriors; without additional tests on realistic cases or an explicit discussion of when the ranking may reverse, the comparative result does not support the broader claim for astro inference.
- [Sampler comparison and tuning description] Sampler comparison and tuning description: the 25% acceptance target is applied specifically to differential evolution, yet the manuscript does not report whether the other samplers (stretch, walk, snooker, novel variants) were subjected to equivalent acceptance-fraction tuning or left at default settings; this asymmetry could affect the reported ranking and must be clarified with explicit protocol details.
minor comments (1)
- The quadtree reconstruction and optimization sections would benefit from explicit pseudocode or a small worked example to make the methods reproducible.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major comment below, proposing targeted revisions to improve transparency and appropriately qualify our claims.
read point-by-point responses
-
Referee: [Abstract and test-function sections] Abstract and test-function sections: the central claim that differential evolution (25% acceptance) 'consistently outperforms all other samplers' rests entirely on Rosenbrock, Neal's funnel, and Gaussian random landscapes in ≤8 dimensions. These lack the parameter degeneracies, non-Gaussian tails, expensive forward models, and dimensionality (>10–20) typical of astrophysical posteriors; without additional tests on realistic cases or an explicit discussion of when the ranking may reverse, the comparative result does not support the broader claim for astro inference.
Authors: The test functions were selected to provide a controlled benchmark with analytically known properties, enabling isolation of sampler behavior on features such as multimodality and correlations. We acknowledge that these cases are lower-dimensional and lack the full complexity of typical astrophysical posteriors. In the revised manuscript we will expand the discussion (primarily in the conclusions) to explicitly address the limitations of the test suite, qualify the scope of the performance ranking, and note conditions under which the ranking could reverse in higher-dimensional or more realistic settings. revision: yes
-
Referee: [Sampler comparison and tuning description] Sampler comparison and tuning description: the 25% acceptance target is applied specifically to differential evolution, yet the manuscript does not report whether the other samplers (stretch, walk, snooker, novel variants) were subjected to equivalent acceptance-fraction tuning or left at default settings; this asymmetry could affect the reported ranking and must be clarified with explicit protocol details.
Authors: We agree that the tuning protocol must be stated explicitly. Differential evolution was tuned to a 25% target acceptance fraction following literature recommendations for that sampler, while the remaining samplers used their standard/default parameter settings. We will add a dedicated methods subsection (with an accompanying table) that reports the acceptance fractions achieved by each sampler and the precise tuning protocol applied, thereby removing any ambiguity about the comparison. revision: yes
Circularity Check
Empirical benchmark with no circular derivations
full rationale
The paper is a direct empirical comparison of MCMC sampler performance on fixed synthetic test functions (Rosenbrock, Neal's funnel, Gaussian random landscapes). Performance metrics are computed from the sampling runs themselves; the 25% acceptance target is a conventional tuning value, not a fitted parameter renamed as a prediction. No equations, self-citations, or ansatzes are invoked to derive the central ranking, so the reported outperformance stands as an independent experimental result on the chosen testbed.
Axiom & Free-Parameter Ledger
free parameters (1)
- target acceptance fraction
axioms (1)
- domain assumption Rosenbrock, Neal's funnel, and Gaussian random fields adequately proxy real astrophysical likelihood surfaces
Reference graph
Works this paper leans on
-
[1]
AkeretJ.,SeeharsS.,AmaraA.,RefregierA.,CsillaghyA.,2013,Astronomy and Computing, 2, 27–39 Angus R., Morton T., Aigrain S., Foreman-Mackey D., Rajpaul V., 2017, Monthly Notices of the Royal Astronomical Society, 474, 2094 Atchadé Y. F., Rosenthal J. S., 2005, Bernoulli, 11, 815 Betancourt M., 2017, arXiv preprint arXiv:1509.02230v2 Bierkens J., Roberts G. ...
Pith/arXiv arXiv 2013
-
[2]
To obtain cells of a hypercube, we divide eachaxisintoequallyspacedsegments,whichdefinetheboundaries of each cell
3 https://docs.scipy.org/doc/scipy/reference/generated/scipy.special.erf.html C2 Hypercube division EachGaussianlandscapecanbedefinedoveraboundeddomainrep- resented by a hypercube, where the bounds on each axis correspond totheparameterrangeslistedintables3,4,and5forthe3D,5D,and 8D models, respectively. To obtain cells of a hypercube, we divide eachaxisin...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.