3DAE: Binaural Quality Assessment for Audio Novel View Synthesis with Spatial Maps and Benchmark
Pith reviewed 2026-06-29 05:16 UTC · model grok-4.3
The pith
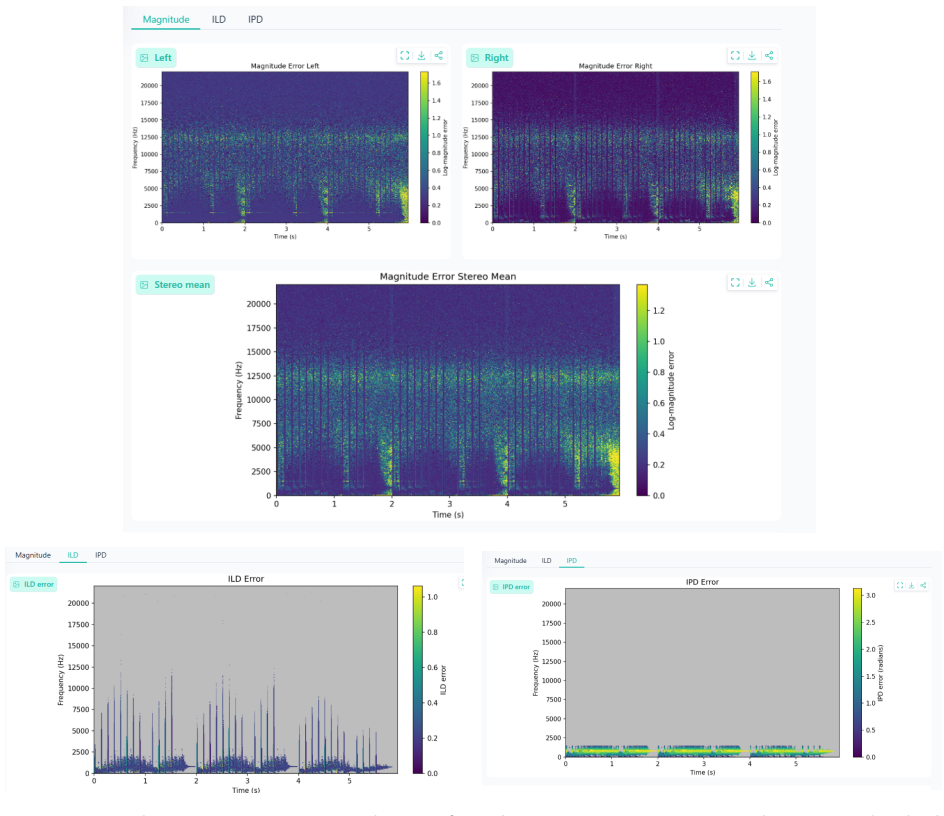
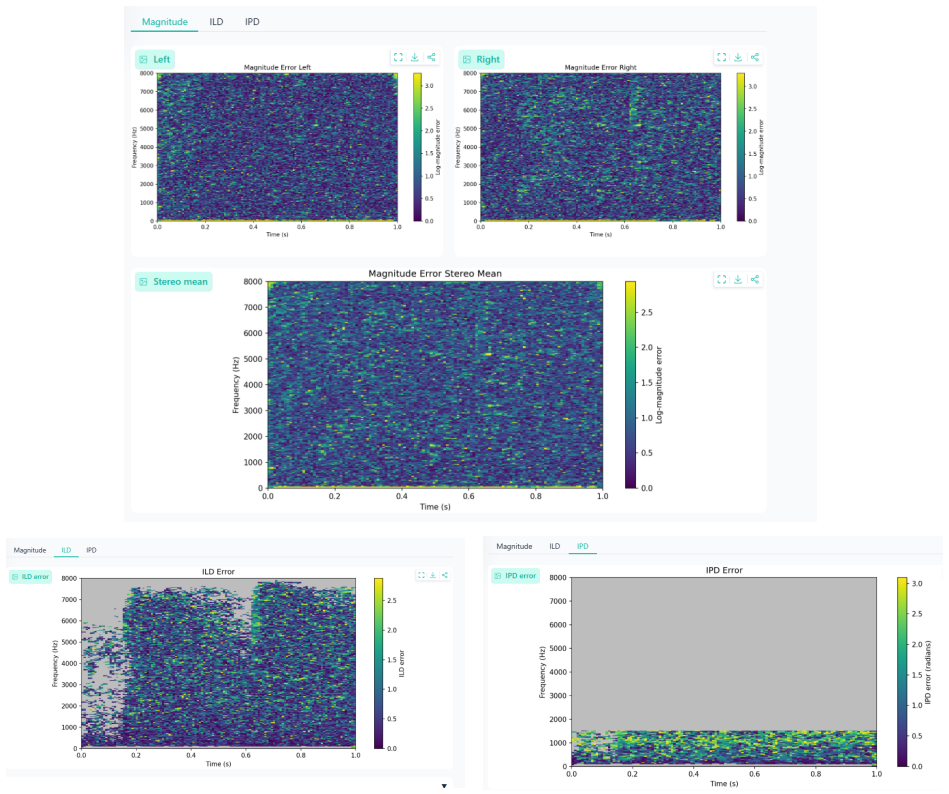
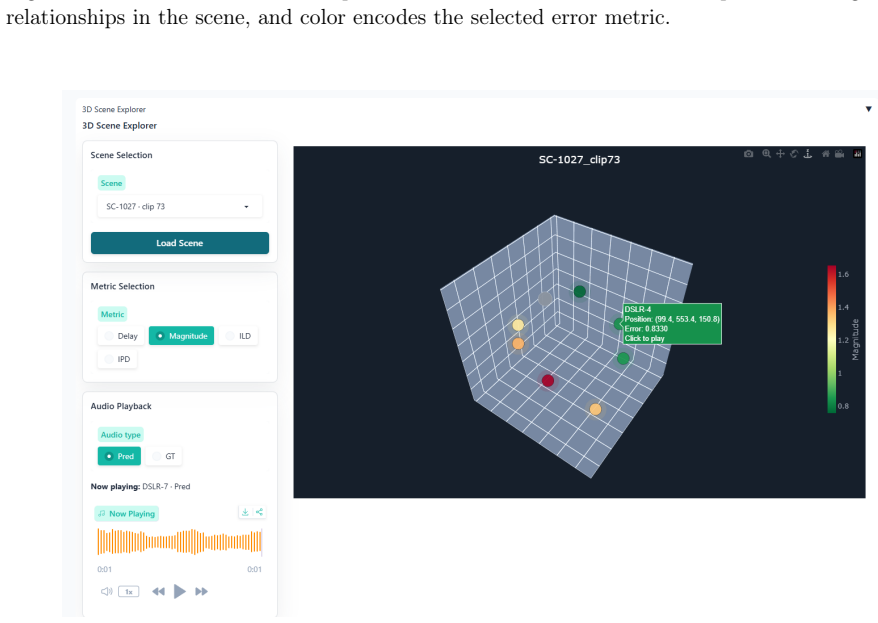
Time-frequency error maps for magnitude, ILD, IPD and other dimensions expose where binaural audio predictions fail in novel-view synthesis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
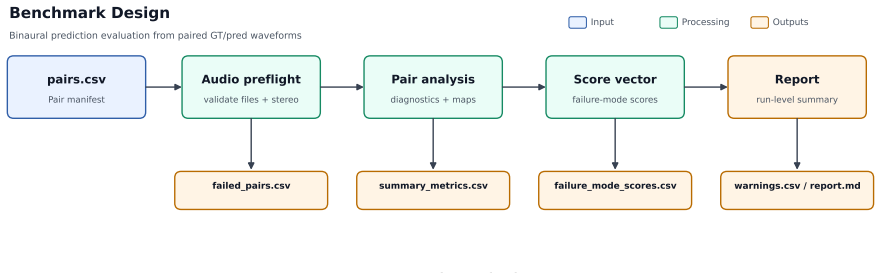
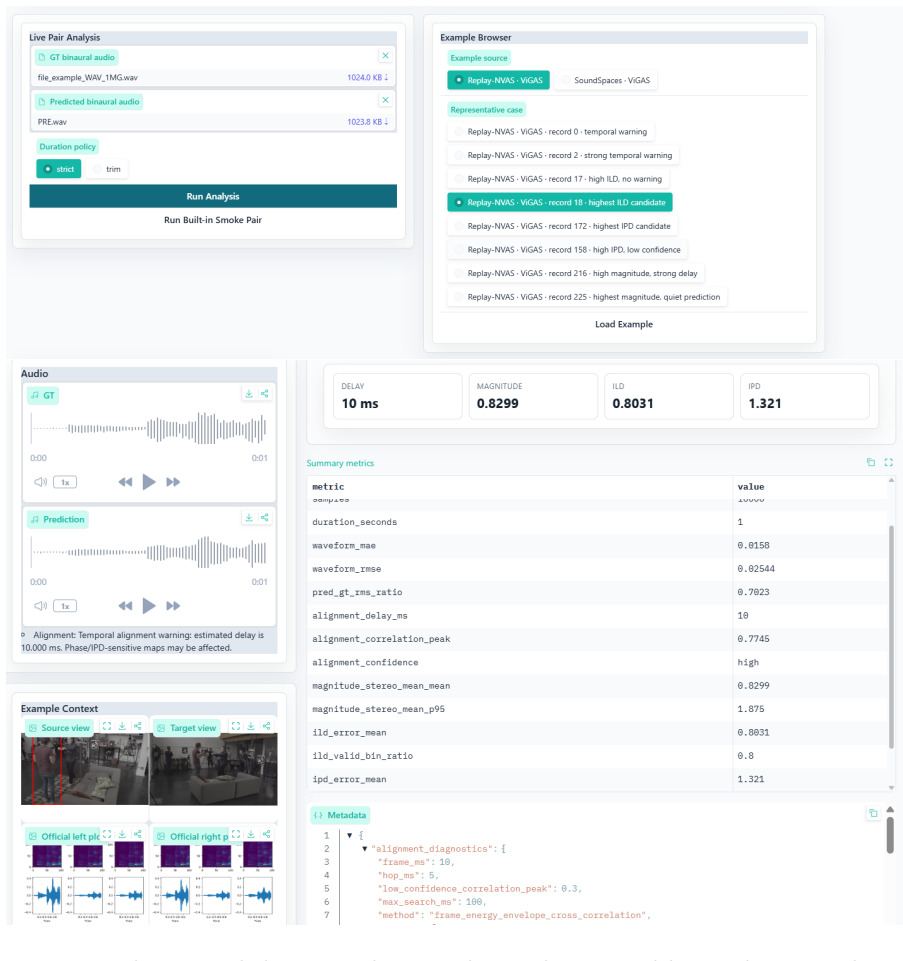
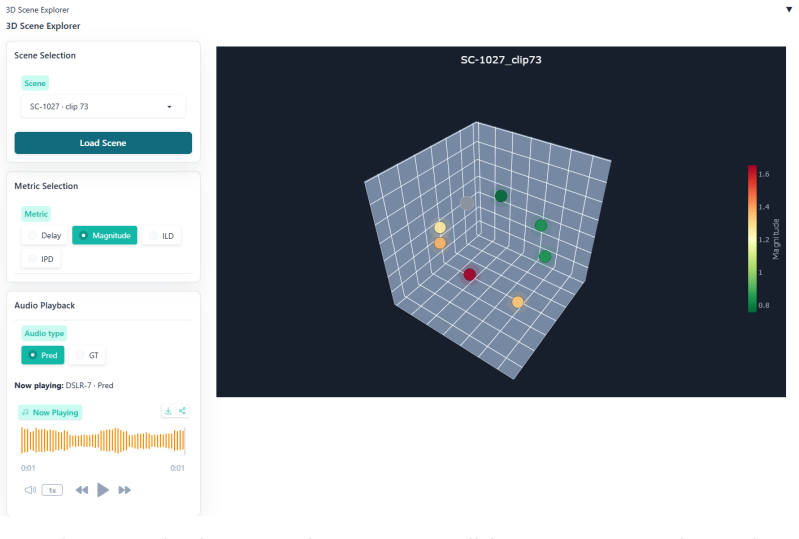
The paper claims that a diagnostic framework built from time-frequency error maps across six audio dimensions produces a 3D Audio Error Map that makes binaural prediction failures visible and actionable for novel-view synthesis models, and that packaging the maps into the Spatial Audio Error Bench supplies a standardized way to report and compare those failures.
What carries the argument
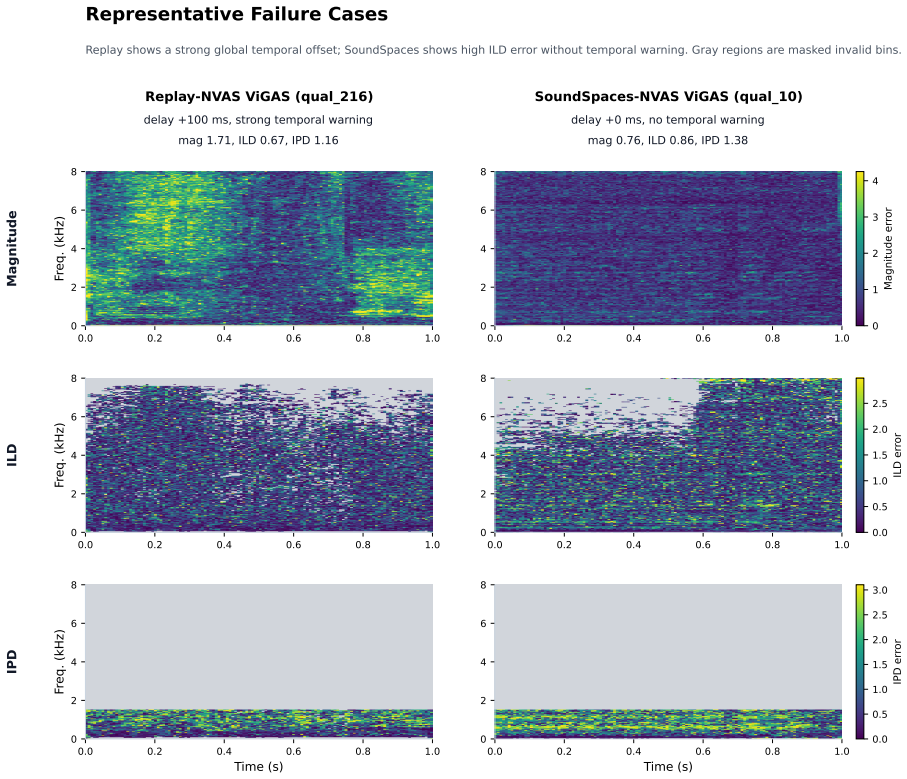
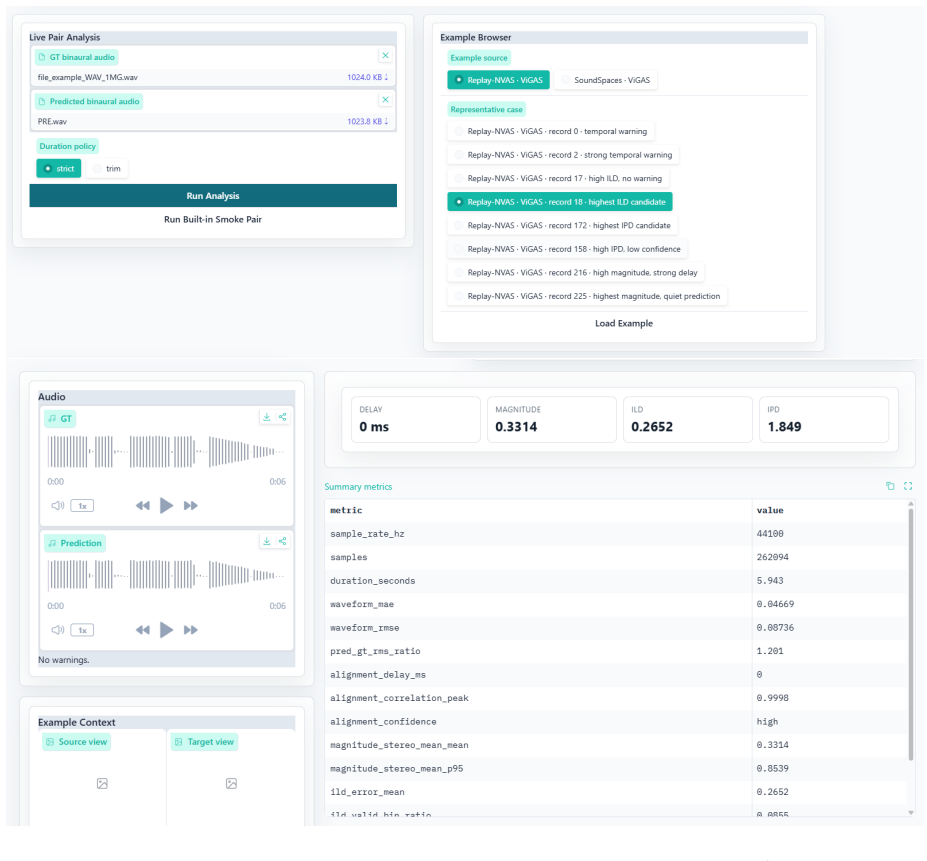
The 3D Audio Error Map (3DAE Map), a set of aligned time-frequency visualizations, one per error type, that together allow inspection of specific binaural mismatches between predicted and ground-truth signals.
If this is right
- Model developers can target isolated error types such as temporal misalignment or ILD mismatch rather than optimizing a single aggregate score.
- Different synthesis tasks or recording conditions will surface different primary failure modes, allowing targeted fixes per setting.
- The benchmark supplies a shared, interpretable report format that replaces or augments global metrics when comparing novel-view synthesis systems.
- Visual maps make it possible to localize errors in time and frequency, enabling precise debugging during training or post-processing.
Where Pith is reading between the lines
- The maps could be computed inside training loops to provide per-sample supervision signals beyond standard losses.
- If the maps align with human listening judgments, they might reduce reliance on subjective tests for iterative development.
- The same error-map approach could transfer to other spatial audio tasks such as room impulse response prediction or ambisonics decoding.
- Incomplete coverage of perceptual dimensions would leave some audible artifacts invisible to the framework.
Load-bearing premise
The six selected error categories capture the dominant perceptual failures that global metrics hide, and visual inspection of the resulting maps will usefully steer model changes.
What would settle it
A controlled comparison in which models tuned with the 3DAE maps produce no measurable perceptual improvement over models tuned only with global metrics, or in which listeners identify major failure types absent from the maps.
Figures
read the original abstract
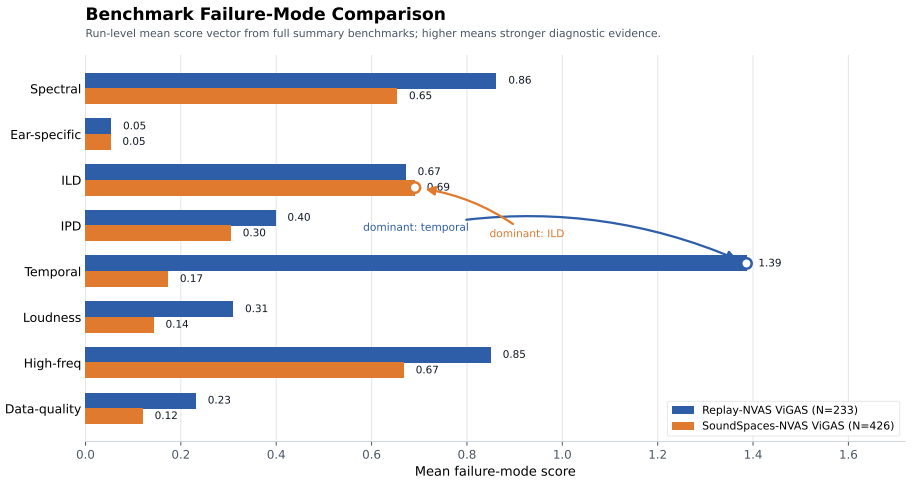
3D audio and novel-view acoustic synthesis models are usually evaluated with global metrics.However, global metrics often hide where and why binaural prediction fails. We propose a full-reference diagnostic framework that uses time-frequency audio error maps for magnitude, ILD, IPD, temporal alignment, loudness, and high-frequency failures, forming a 3D Audio Error Map (3DAE Map) for visual inspection. We frame these diagnostics into a model-agnostic benchmark, Spatial Audio Error Bench (3DAE Bench), which takes arbitrary ground-truth and predicted binaural pairs and reports the prediction quality of audio novel-view synthesis models. Experiments on ViGAS outputs over Replay-NVAS and SoundSpaces show different dominant failure modes: temporal misalignment on Replay-NVAS and ILD mismatch on SoundSpaces. Overall, the framework provides interpretable failure-mode summaries and intuitive visual maps for audio Novel-view-synthesis model development optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a full-reference diagnostic framework for binaural audio novel-view synthesis that generates time-frequency error maps for magnitude, ILD, IPD, temporal alignment, loudness, and high-frequency content; these are aggregated into 3D Audio Error (3DAE) Maps for visual inspection. It introduces the model-agnostic Spatial Audio Error Bench (3DAE Bench) that ingests arbitrary ground-truth/predicted binaural pairs and reports quality. Experiments apply the framework to ViGAS outputs on the Replay-NVAS and SoundSpaces datasets, identifying temporal misalignment as the dominant failure on Replay-NVAS and ILD mismatch on SoundSpaces. The manuscript claims that the resulting interpretable summaries and visual maps support audio NVS model development and optimization.
Significance. If the maps reliably expose perceptual failure modes that global metrics obscure and if visual inspection demonstrably accelerates or improves model optimization, the contribution would be useful for the spatial-audio synthesis community, where aggregate metrics (e.g., SI-SDR, STOI) are known to mask localized errors. The provision of an open benchmark and concrete error categories could standardize diagnostic practice. The current experiments, however, only illustrate failure-mode identification; they supply no quantitative evidence that map usage improves optimization outcomes relative to global metrics alone.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the central claim that the 3DAE framework 'provides interpretable failure-mode summaries and intuitive visual maps for audio Novel-view-synthesis model development optimization' is unsupported by the reported results. The experiments only document dominant failure modes on ViGAS outputs for two datasets; they contain no before/after optimization trials, no ablation on map-guided versus metric-only training, and no controlled comparison of convergence speed or final quality when developers use the maps.
- [Abstract] Abstract: the assertion that the six chosen error categories (magnitude, ILD, IPD, temporal alignment, loudness, high-frequency) are sufficient to expose the dominant perceptual failures is presented without justification, perceptual validation, or comparison against alternative error decompositions.
minor comments (1)
- [Method] The manuscript would benefit from explicit definitions or references for each error-map computation (e.g., how ILD and IPD maps are derived from STFT bins) to allow reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the experiments demonstrate failure-mode identification but do not empirically validate improvements in model optimization, and that the choice of error categories lacks explicit justification. We will revise the manuscript to address these points as outlined below.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the central claim that the 3DAE framework 'provides interpretable failure-mode summaries and intuitive visual maps for audio Novel-view-synthesis model development optimization' is unsupported by the reported results. The experiments only document dominant failure modes on ViGAS outputs for two datasets; they contain no before/after optimization trials, no ablation on map-guided versus metric-only training, and no controlled comparison of convergence speed or final quality when developers use the maps.
Authors: We acknowledge that the reported experiments identify dominant failure modes (temporal misalignment on Replay-NVAS, ILD mismatch on SoundSpaces) but provide no before/after trials, ablations, or comparisons of optimization outcomes with versus without the maps. The abstract claim regarding support for model development and optimization is therefore not directly supported by the results and reflects an intended use case rather than demonstrated evidence. We will revise the abstract and experiments section to remove or qualify this claim, limiting it to the diagnostic capabilities shown, and will add a limitations paragraph noting the absence of optimization trials. revision: yes
-
Referee: [Abstract] Abstract: the assertion that the six chosen error categories (magnitude, ILD, IPD, temporal alignment, loudness, high-frequency) are sufficient to expose the dominant perceptual failures is presented without justification, perceptual validation, or comparison against alternative error decompositions.
Authors: The categories were chosen to address core binaural and perceptual aspects (spatial cues via ILD/IPD, energy via magnitude/loudness, synchronization via temporal alignment, and detail via high-frequency content), drawing from established spatial audio evaluation practices. We agree, however, that the manuscript provides no explicit justification, perceptual validation, or comparison to alternatives. We will add a dedicated paragraph in the methods or discussion section with citations to binaural perception literature to justify the selection and will note the lack of validation studies as a limitation for future work. revision: yes
Circularity Check
No circularity: proposal contains no derivations or equations that reduce to inputs
full rationale
The paper proposes a diagnostic framework and benchmark based on selected error maps (magnitude, ILD, IPD, etc.) without any equations, fitted parameters, or derivation chain. The central claim that the maps 'provide interpretable failure-mode summaries and intuitive visual maps for audio Novel-view-synthesis model development optimization' is an unvalidated assertion rather than a self-referential definition or fitted prediction. No self-citations, ansatzes, or uniqueness theorems are invoked in a load-bearing way. The absence of any mathematical reduction means the work is self-contained as a methodological proposal, consistent with the reader's assessment of no equations present.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Novel-view acoustic synthesis,
C. Chen, A. Richard, R. Shapovalov, V. K. Ithapu, N. Neverova, K. Grauman, and A. Vedaldi, “Novel-view acoustic synthesis,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6409–6419, 2023
2023
-
[2]
ISO 3382-1: Acoustics — measurement of room acoustic parameters — part 1: Performance spaces,
International Organization for Standardization, “ISO 3382-1: Acoustics — measurement of room acoustic parameters — part 1: Performance spaces,” Standard ISO 3382-1:2009, Interna- tional Organization for Standardization, 2009
2009
-
[3]
Blauert,Spatial Hearing: The Psychophysics of Human Sound Localization
J. Blauert,Spatial Hearing: The Psychophysics of Human Sound Localization. Cambridge, MA: MIT Press, revised ed., 1997
1997
-
[4]
Replay: Multi-modal multi-view acted videos for casual hologra- phy,
R. Shapovalov, Y. Kleiman, I. Rocco, D. Novotny, A. Vedaldi, C. Chen, F. Kokkinos, B. Gra- ham, and N. Neverova, “Replay: Multi-modal multi-view acted videos for casual hologra- phy,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp. 20338–20348, 2023
2023
-
[5]
SoundSpaces 2.0: A simulation platform for visual-acoustic learning,
C. Chen, C. Schissler, S. Garg, P. Kobernik, A. Clegg, P. Calamia, D. Batra, P. W. Robin- son, and K. Grauman, “SoundSpaces 2.0: A simulation platform for visual-acoustic learning,” inAdvances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2022. 9
2022
-
[6]
AV-NeRF: Learning neural fields for real- world audio-visual scene synthesis,
S. Liang, C. Huang, Y. Tian, A. Kumar, and C. Xu, “AV-NeRF: Learning neural fields for real- world audio-visual scene synthesis,” inAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[7]
NeRAF: 3d scene infused neural radiance and acoustic fields,
A. Brunetto, S. Hornauer, and F. Moutarde, “NeRAF: 3d scene infused neural radiance and acoustic fields,” inProceedings of the International Conference on Learning Representations (ICLR), 2025
2025
-
[8]
AV-GS:Learningmaterialandgeometry aware priors for novel view acoustic synthesis,
S.Bhosale, H.Yang, D.Kanojia, J.Deng, andX.Zhu, “AV-GS:Learningmaterialandgeometry aware priors for novel view acoustic synthesis,” inAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[9]
2.5D visual sound,
R. Gao and K. Grauman, “2.5D visual sound,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 324–333, 2019
2019
-
[10]
Neuralsynthesisofbinauralspeechfrommonoaudio,
A. Richard, D. Markovic, I. D. Gebru, S. Krenn, G. Butler, F. de la Torre, and Y. Sheikh, “Neuralsynthesisofbinauralspeechfrommonoaudio,” inInternational Conference on Learning Representations (ICLR), 2021
2021
-
[11]
SoundSpaces: Audio-visual navigation in 3D environments,
C. Chen, U. Jain, C. Schissler, S. V. A. Gari, Z. Al-Halah, V. K. Ithapu, P. Robinson, and K. Grauman, “SoundSpaces: Audio-visual navigation in 3D environments,” inProceedings of the European Conference on Computer Vision (ECCV), 2020
2020
-
[12]
Fundamentals of binaural technology,
H. Møller, “Fundamentals of binaural technology,”Applied Acoustics, vol. 36, no. 3–4, pp. 171– 218, 1992
1992
-
[13]
3D gaussian splatting for real-time radiance field rendering,
B. Kerbl, G. Kopanas, T. Leimkühler, and G. Drettakis, “3D gaussian splatting for real-time radiance field rendering,”ACM Transactions on Graphics, vol. 42, no. 4, pp. 139:1–139:14, 2023
2023
-
[14]
A. V. Oppenheim and R. W. Schafer,Discrete-Time Signal Processing. Pearson Prentice Hall, third ed., 2009
2009
-
[15]
NeRF: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, “NeRF: Representing scenes as neural radiance fields for view synthesis,” inProceedings of the European Conference on Computer Vision (ECCV), pp. 405–421, 2020
2020
-
[16]
Method for the subjective assessment of intermediate quality level of audio systems (MUSHRA),
International Telecommunication Union, “Method for the subjective assessment of intermediate quality level of audio systems (MUSHRA),” Recommendation ITU-R BS.1534-3, International Telecommunication Union, 2015
2015
-
[17]
TorchAudio- Squim: Reference-less speech quality and intelligibility measures in TorchAudio,
A. Kumar, K. Tan, Z. Ni, P. Manocha, X. Zhang, E. Henderson, and B. Xu, “TorchAudio- Squim: Reference-less speech quality and intelligibility measures in TorchAudio,” inProceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5, 2023. 10 A 3D Audio Error Maps This appendix documents the visual interface u...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.