WristCompass: Kinematic Coupling as a Learnable Visual Concept for Ego-Camera Orientation
Pith reviewed 2026-06-28 23:27 UTC · model grok-4.3
The pith
Kinematic coupling between wrist motion and body chain recovers ego-camera orientation in manipulation videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
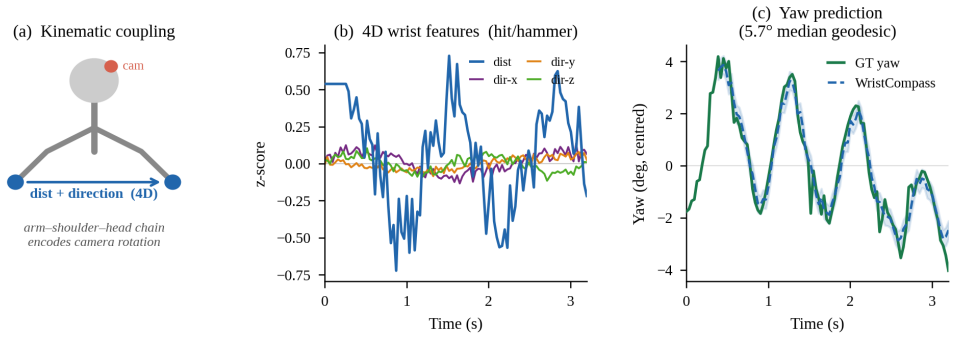
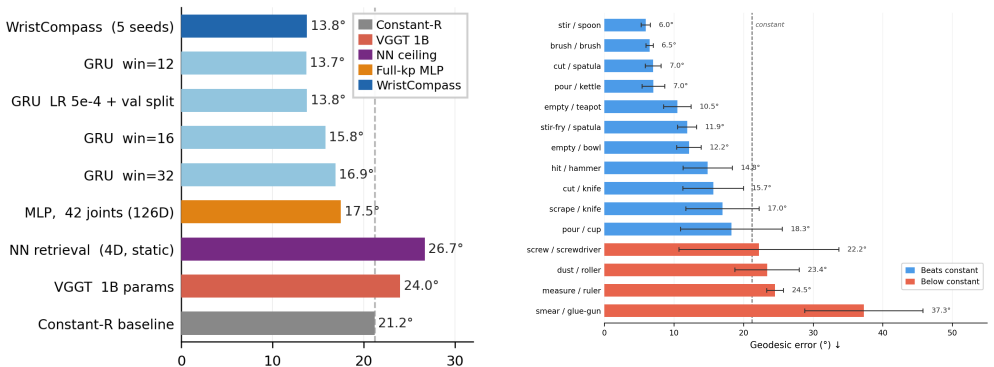
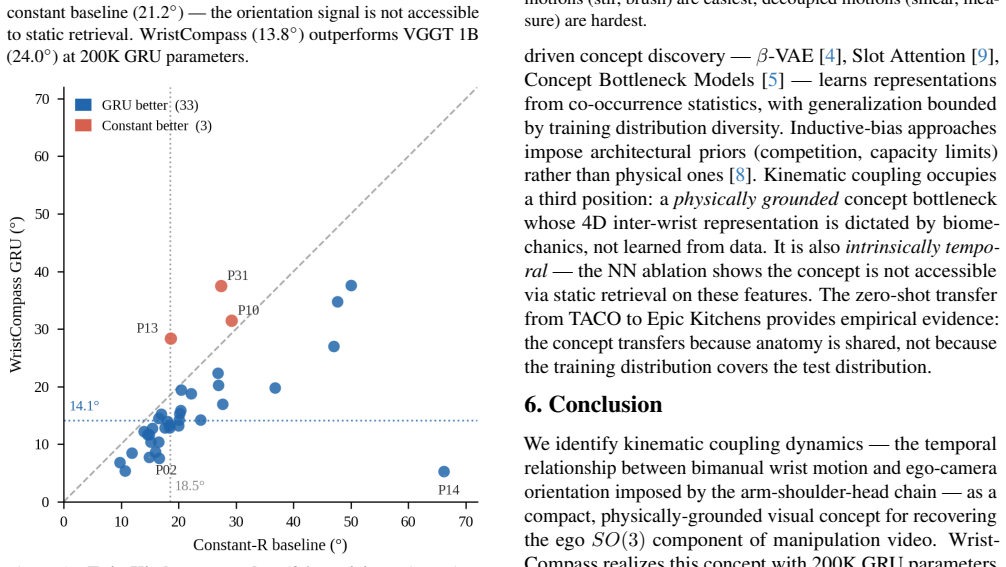
Kinematic coupling dynamics, the structured physical relationship between wrist motion and camera orientation imposed by the arm-shoulder-head chain, forms a learnable visual concept that recovers ego-camera orientation. It is compact with 4D features outperforming full hand keypoints, temporal requiring GRU, and physically grounded allowing zero-shot transfer from tabletop manipulation training to Epic Kitchens cooking videos, achieving 14.3 degrees median error with a small model.
What carries the argument
Kinematic coupling dynamics: the structured physical relationship between wrist motion and camera orientation imposed by the arm-shoulder-head chain.
Load-bearing premise
The kinematic coupling relationship depends on anatomy rather than scene appearance.
What would settle it
A failure of zero-shot transfer to a new dataset with different scenes but identical body kinematics would falsify the claim that the method relies on anatomy.
Figures
read the original abstract
Recovering ego-camera orientation from manipulation video is a prerequisite for disentangling hand motion from camera motion, a key step in imitation learning from egocentric demonstrations. The obvious approach, inferring orientation from scene geometry, fails when hands occlude the frame: VGGT, a 1B-parameter scene reconstruction model, scores worse than a constant predictor on the TACO benchmark. We identify an alternative visual concept that is present precisely when scene geometry is absent: kinematic coupling dynamics, the structured physical relationship between wrist motion and camera orientation imposed by the arm-shoulder-head chain. We find that this concept is compact (4D inter-wrist features outperform 126D full hand keypoints), temporal (requiring a GRU over short windows rather than per-frame retrieval), and physically grounded (transferring zero-shot across datasets because it is rooted in anatomy rather than scene appearance). Trained only on tabletop manipulation, WristCompass transfers zero-shot to Epic Kitchens cooking video, achieving 14.3$^\circ$ median geodesic error and approaching the performance of a 1B-parameter scene model at 200K GRU parameters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that kinematic coupling dynamics—the structured physical relationship between wrist motion and camera orientation imposed by the arm-shoulder-head chain—constitute a compact (4D inter-wrist features outperform 126D full hand keypoints), temporal (GRU over short windows), and physically grounded visual concept that can be learned from tabletop manipulation videos and transfers zero-shot to Epic Kitchens cooking video. This yields 14.3° median geodesic error, outperforming a constant predictor and approaching the performance of the 1B-parameter VGGT scene model at only 200K GRU parameters, providing an alternative when scene geometry is occluded by hands.
Significance. If the result holds, the work identifies a lightweight, anatomy-rooted alternative to heavy scene-reconstruction models for ego-camera orientation recovery in egocentric manipulation video, directly relevant to imitation learning. Credit is due for the empirical cross-dataset zero-shot transfer results, the compactness finding (4D vs. 126D), and the explicit comparison showing VGGT underperforming a constant predictor on the TACO benchmark.
major comments (2)
- [Abstract] Abstract: the central claim that zero-shot transfer to Epic Kitchens is explained by anatomical invariance (arm-shoulder-head chain) rather than shared motion statistics across manipulation videos is load-bearing but under-determined; no control experiment is described that holds temporal motion statistics fixed while violating shoulder-head anatomical constraints (e.g., via synthetic wrist trajectories).
- [Abstract] Abstract: performance numbers (14.3° median error, VGGT and constant-predictor comparisons) and the claim of physical grounding are stated without any description of training protocol, dataset splits, error bars, or ablation studies on the 4D feature choice, preventing verification that the reported transfer supports the kinematic-coupling interpretation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that zero-shot transfer to Epic Kitchens is explained by anatomical invariance (arm-shoulder-head chain) rather than shared motion statistics across manipulation videos is load-bearing but under-determined; no control experiment is described that holds temporal motion statistics fixed while violating shoulder-head anatomical constraints (e.g., via synthetic wrist trajectories).
Authors: We agree that a synthetic control experiment holding motion statistics fixed while violating anatomical constraints would provide stronger causal evidence for the anatomical-invariance interpretation. Our current support for the claim rests on three empirical observations reported in the paper: (1) 4D inter-wrist features outperform 126D full-hand keypoints, (2) a GRU over short temporal windows is required rather than per-frame matching, and (3) zero-shot transfer occurs across datasets with different scene statistics. We will revise the abstract to qualify the claim as supported by these observations rather than definitively proven by them, and we will add an explicit limitations paragraph discussing the lack of a synthetic control. Generating anatomically invalid yet statistically matched synthetic trajectories is non-trivial and is noted as future work. revision: partial
-
Referee: [Abstract] Abstract: performance numbers (14.3° median error, VGGT and constant-predictor comparisons) and the claim of physical grounding are stated without any description of training protocol, dataset splits, error bars, or ablation studies on the 4D feature choice, preventing verification that the reported transfer supports the kinematic-coupling interpretation.
Authors: We agree that the abstract is missing essential experimental context. We will revise the abstract to include a concise statement of the training protocol (supervised training on tabletop manipulation videos from the TACO dataset), the zero-shot evaluation split (Epic Kitchens cooking videos), reference to error bars and statistical significance reported in the results section, and a brief mention of the 4D-vs-126D ablation that supports the compactness finding. revision: yes
Circularity Check
No circularity; claims rest on empirical cross-dataset transfer
full rationale
The provided abstract and context describe an empirical pipeline: training a GRU on 4D inter-wrist features from tabletop data, then measuring zero-shot geodesic error on Epic Kitchens. No equations, parameter-fitting steps presented as predictions, self-citations, or uniqueness theorems appear. The central claim (anatomical grounding enabling transfer) is supported by falsifiable performance numbers rather than reducing to a definitional identity or self-referential loop. This matches the default expectation of a non-circular empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
G ´omez Rodr´ıguez, Jos´e M
Carlos Campos, Richard Elvira, Juan J. G ´omez Rodr´ıguez, Jos´e M. M. Montiel, and Juan D. Tard´os. ORB-SLAM3: An accurate open-source library for visual, visual-inertial and multi-map SLAM.IEEE Transactions on Robotics, 2021. 1
2021
-
[2]
Scaling egocentric vision: The EPIC- KITCHENS dataset
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Sanja Fidler, Antonino Furnari, Evangelos Kazakos, Da- vide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, and Michael Wray. Scaling egocentric vision: The EPIC- KITCHENS dataset. InECCV, 2018. 1, 2
2018
-
[3]
Ego-Exo4D: Understanding skilled human activity from first- and third-person perspectives
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyllos Afouras, Kumar Ashutosh, et al. Ego-Exo4D: Understanding skilled human activity from first- and third-person perspectives. InCVPR,
-
[4]
β-V AE: Learning basic visual concepts with a constrained variational framework
Irina Higgins, Loic Matthey, Arka Pal, Christopher Burgess, Xavier Glorot, Matthew Botvinick, Shakir Mohamed, and Alexander Lerchner. β-V AE: Learning basic visual concepts with a constrained variational framework. InICLR, 2017. 2, 4
2017
-
[5]
Concept bottleneck models
Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Muss- mann, Emma Pierson, Been Kim, and Percy Liang. Concept bottleneck models. InICML, 2020. 2, 4
2020
-
[6]
Ego-body pose estima- tion via ego-head pose estimation
Jiaman Li, Karen Liu, and Jiajun Wu. Ego-body pose estima- tion via ego-head pose estimation. InCVPR, 2023. 2
2023
-
[7]
TACO: Benchmarking generalizable bimanual tool-action- object understanding
Yun Liu, Haolin Yang, Xu Xu, Mingsheng Ding, Weicheng Li, Yuxin Li, Ziyu Liu, Jianyu Luo, Jing Cheng, and Li Cheng. TACO: Benchmarking generalizable bimanual tool-action- object understanding. InCVPR, 2024. 1, 2
2024
-
[8]
Challenging common assumptions in the unsu- pervised learning of disentangled representations
Francesco Locatello, Stefan Bauer, Mario Lucic, Gunnar R¨atsch, Sylvain Gelly, Bernhard Sch ¨olkopf, and Olivier Bachem. Challenging common assumptions in the unsu- pervised learning of disentangled representations. InICML,
-
[9]
Object-centric learn- ing with slot attention
Francesco Locatello, Dirk Weissenborn, Thomas Unterthiner, Aravindh Mahendran, Georg Heigold, Jakob Uszkoreit, Alexey Dosovitskiy, and Thomas Kipf. Object-centric learn- ing with slot attention. InNeurIPS, 2020. 2, 4
2020
-
[10]
WiLoR: End-to-end 3D hand localization and reconstruction in-the-wild
Rolandos Alexandros Potamias, Jinglei Shu, German Bar- quero, Cristina Palmero, Sergio Escalera, and Stefanos Zafeiriou. WiLoR: End-to-end 3D hand localization and reconstruction in-the-wild. InECCV, 2024. 2
2024
-
[11]
Sch¨onberger and Jan-Michael Frahm
Johannes L. Sch¨onberger and Jan-Michael Frahm. Structure- from-motion revisited. InCVPR, 2016. 1
2016
-
[12]
EPIC Fields: Marrying 3D geometry and video understanding.NeurIPS,
Vadim Tschernezki, Ahmad Darkhalil, Zhifan Zhu, David Fouhey, Iro Laina, Diane Sheratt, Mike Brookes, Roberto Cipolla, Spyridon Leonardos, and Dima Damen. EPIC Fields: Marrying 3D geometry and video understanding.NeurIPS,
-
[13]
VGGT: Visual geometry grounded deep structure from motion
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. VGGT: Visual geometry grounded deep structure from motion. In CVPR, 2025. 1, 3
2025
-
[14]
Chang, and Li Yi
Jiaman Ye, Yiye Ye, Manolis Savva, Angel X. Chang, and Li Yi. EgoAllo: Egocentric human motion estimation via explicit alignment with a grounded world coordinate system. InECCV, 2024. 2
2024
-
[15]
Hawor: World-space hand motion reconstruction from egocentric videos.2025 IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR), pages 1805–1815, 2025
Jinglei Zhang, Jiankang Deng, Chao Ma, and Rolan- dos Alexandros Potamias. Hawor: World-space hand motion reconstruction from egocentric videos.2025 IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR), pages 1805–1815, 2025. 2
2025
-
[16]
On the continuity of rotation representations in neural networks
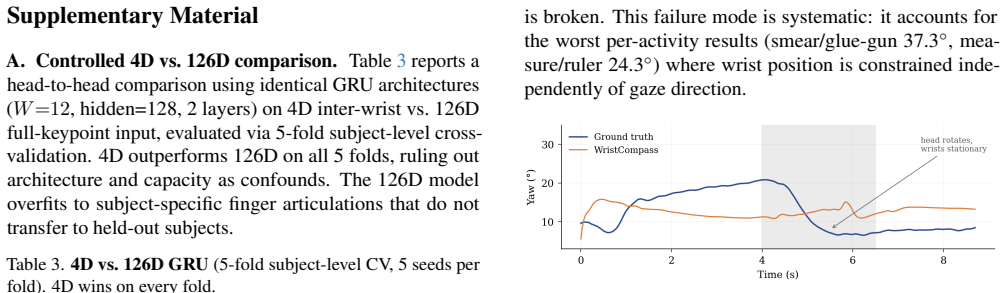
Yi Zhou, Connelly Barnes, Jingwan Lu, Jimei Yang, and Hao Li. On the continuity of rotation representations in neural networks. InCVPR, 2019. 2 Supplementary Material A. Controlled 4D vs. 126D comparison.Table 3 reports a head-to-head comparison using identical GRU architectures (W=12 , hidden=128, 2 layers) on 4D inter-wrist vs. 126D full-keypoint input,...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.