Healthcare Mechanisms from Policy-as-Code Search under Strategic Provider Response
Pith reviewed 2026-06-28 22:42 UTC · model grok-4.3
The pith
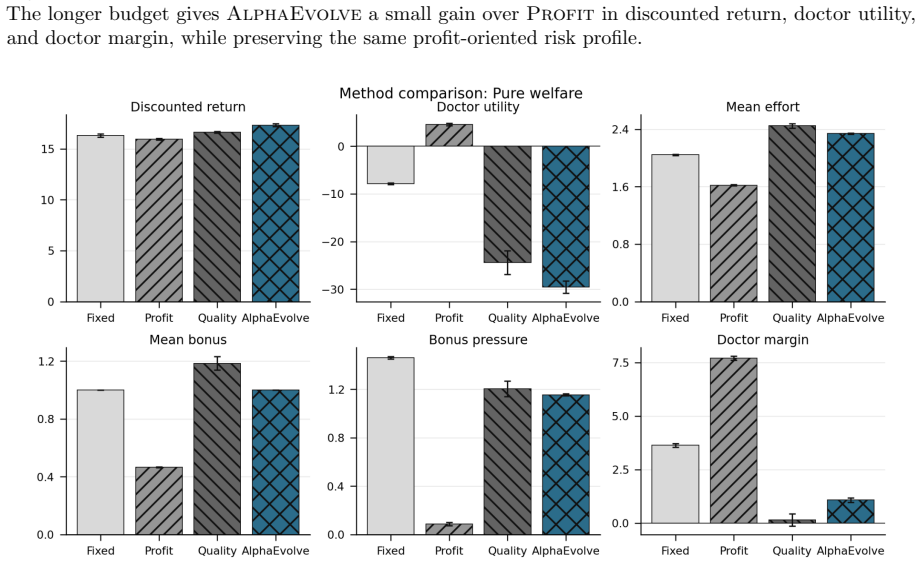
LLM-guided code search over rule programs yields a mixed-objective healthcare incentive that eliminates up-coding, halves rejections, and keeps most baseline funds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
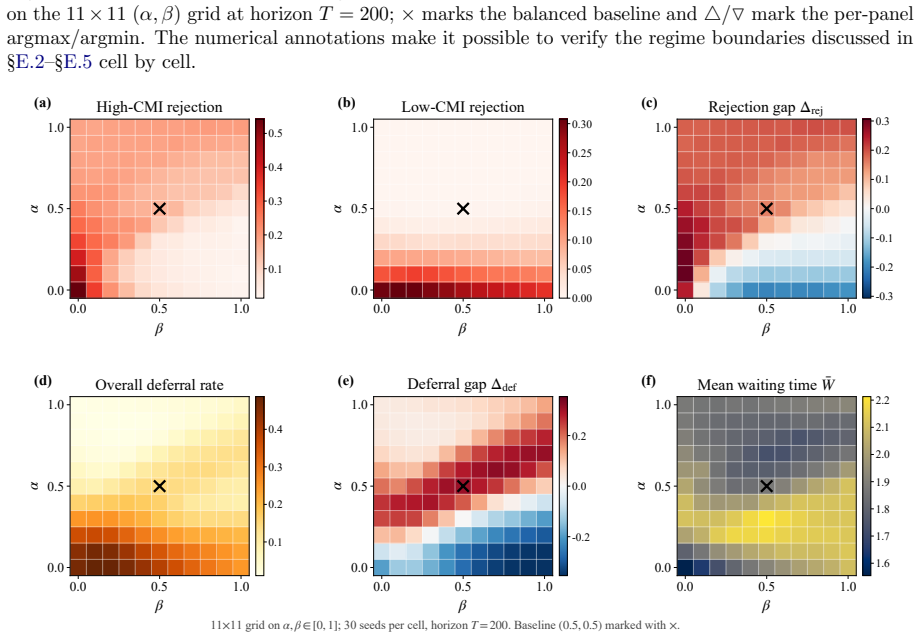
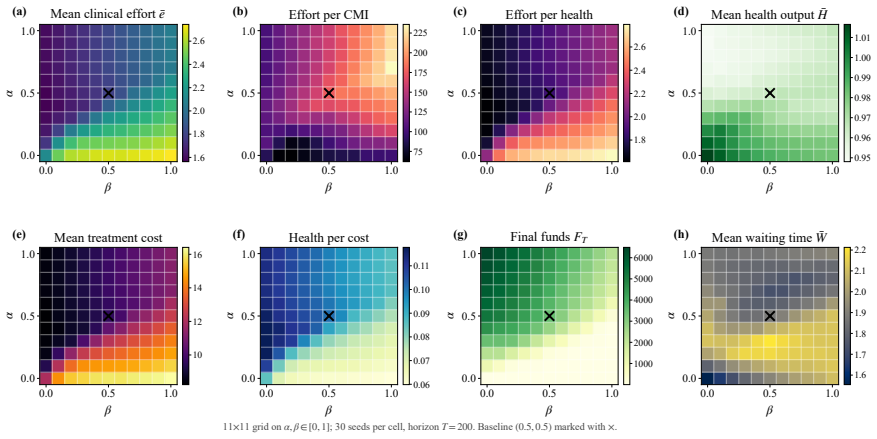
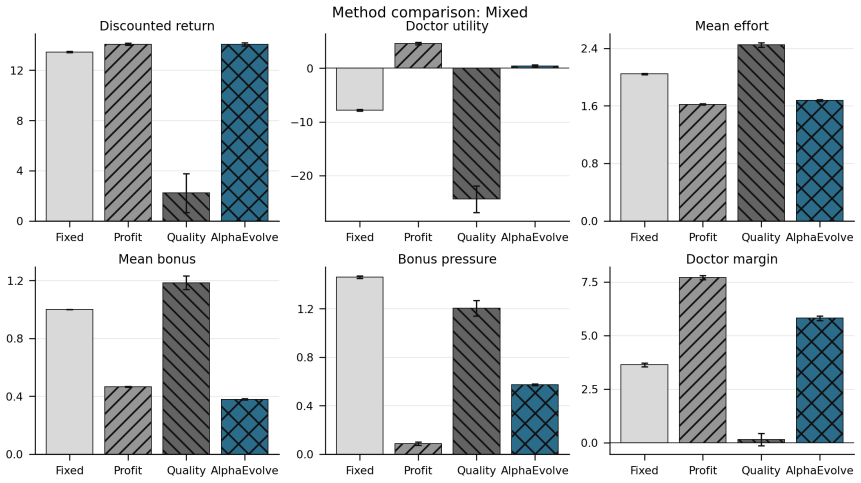
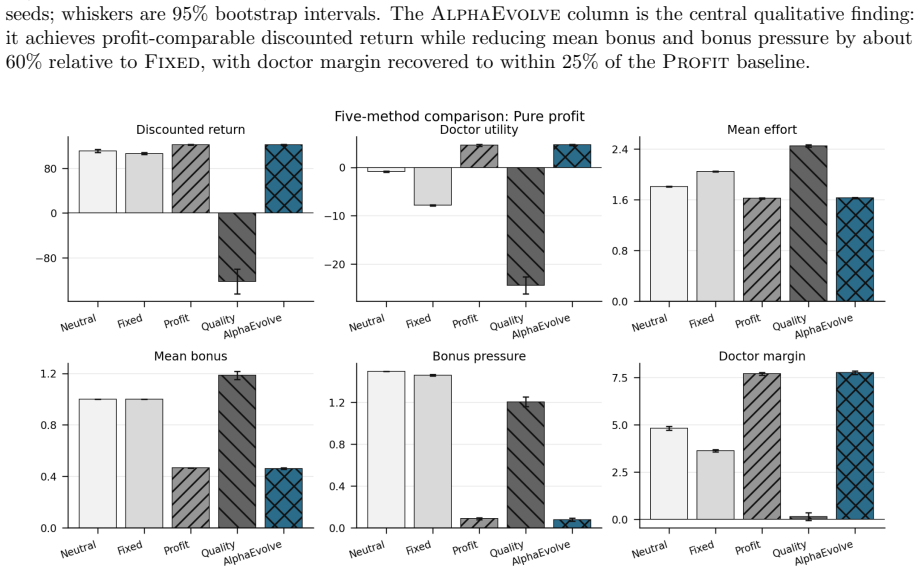
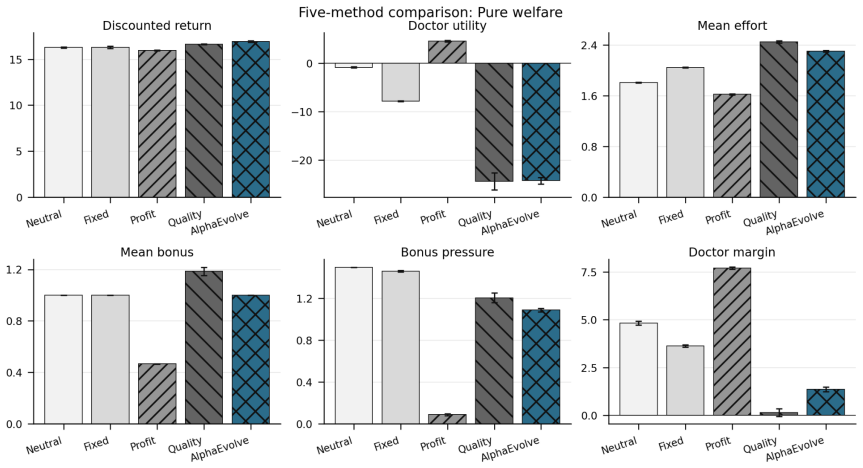
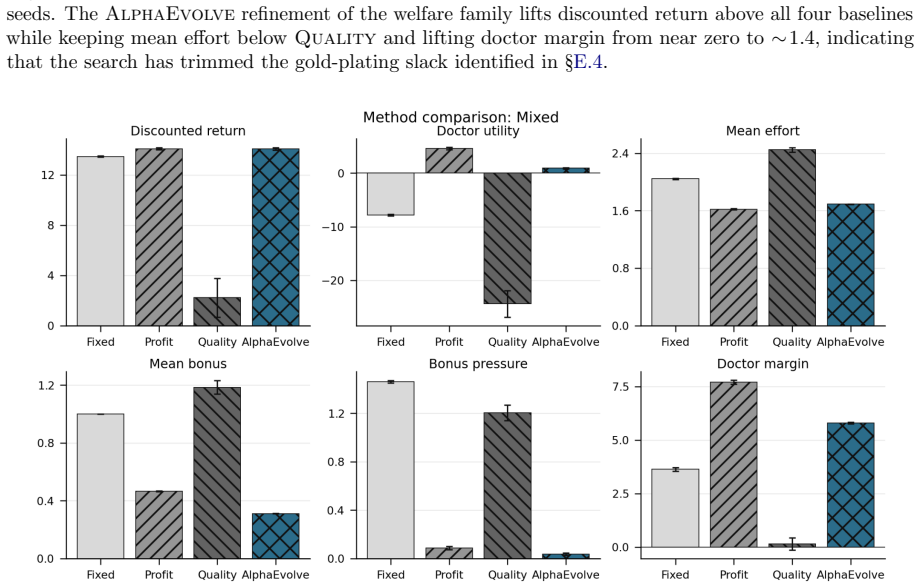
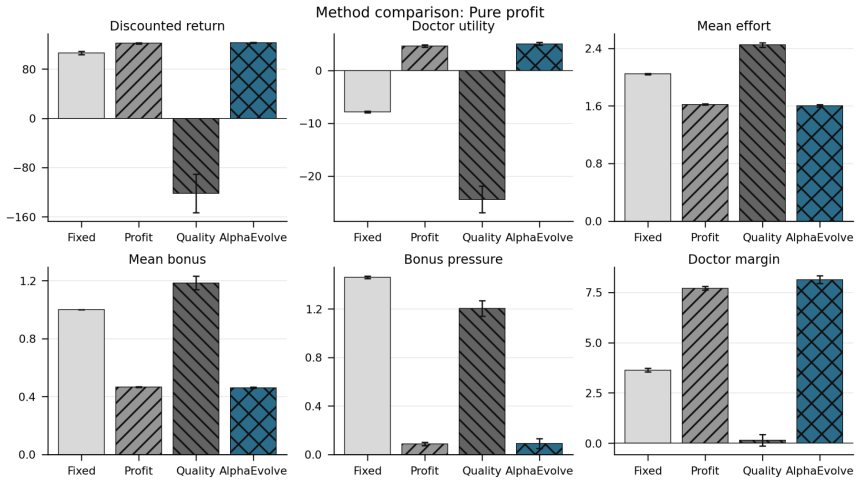
Framing mechanism design as synthesis of typed rule programs scored by the Medi-Sim simulator recovers classical incentive patterns and allows search to produce a mixed-objective program that removes up-coding, halves rejection rates, and retains most of the funds generated by a profit-oriented baseline.
What carries the argument
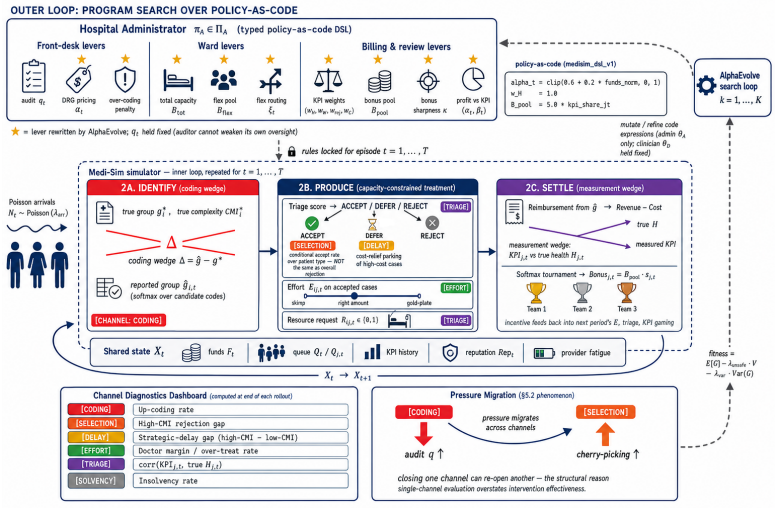
LLM-guided evolutionary code search over typed, inspectable rule programs executed inside the five-channel Medi-Sim multi-agent simulator
If this is right
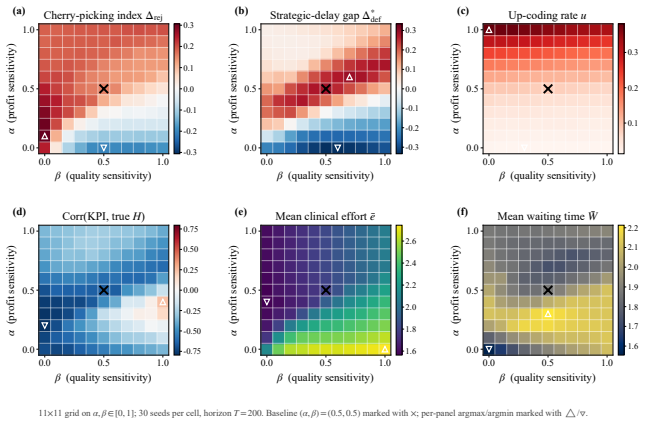
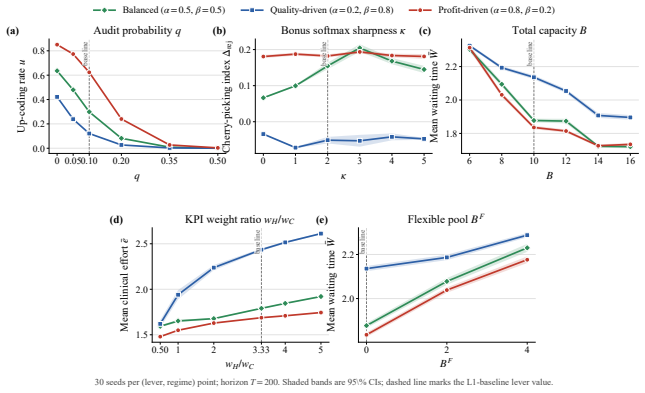
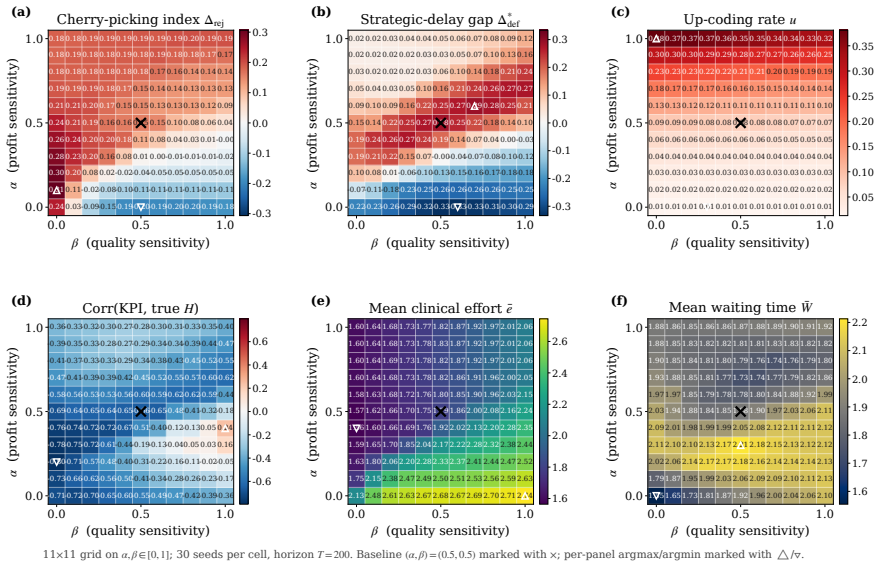
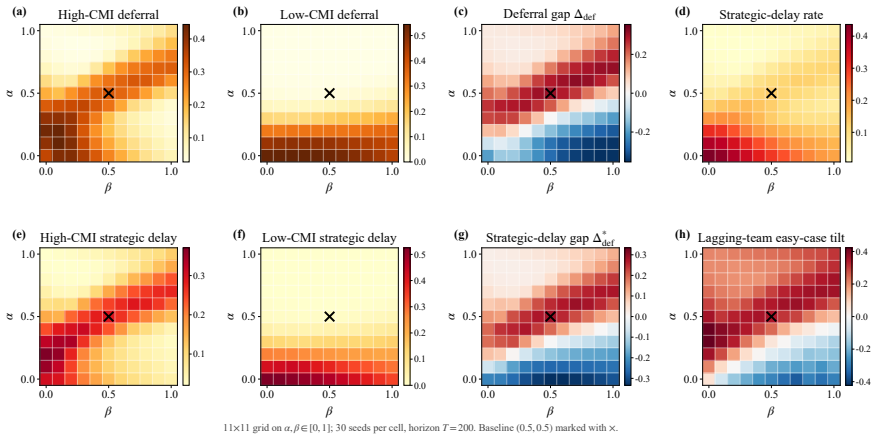
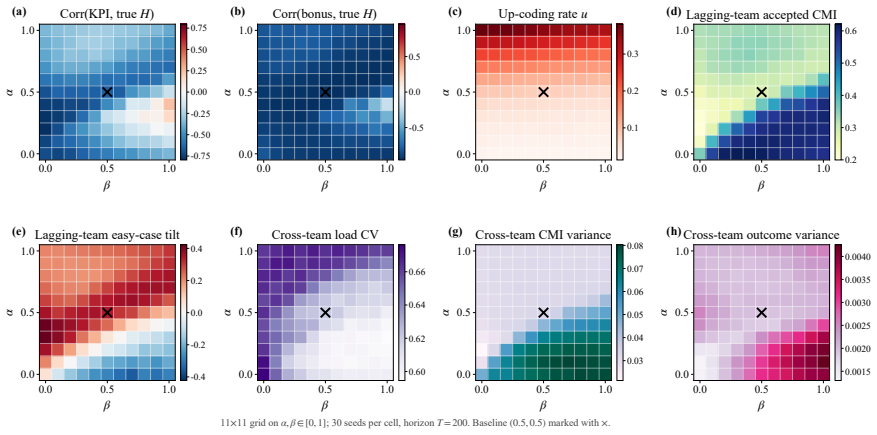
- An incentive sweep across rule programs reproduces up-coding and low-complexity patient selection under profit pressure.
- Closing the coding audit channel more than doubles low-complexity patient selection.
- Goodhart-style drift appears where measured performance becomes anti-correlated with true clinical outcomes.
- The synthesized mixed-objective program eliminates up-coding while halving rejections relative to the profit baseline.
Where Pith is reading between the lines
- The same search approach could be used to design rules in other domains with strategic agents, such as tax compliance or environmental permitting.
- Because the output programs are typed and inspectable, regulators can audit exactly which behaviors are rewarded or penalized.
- Extending the simulator with additional channels or real claims data would test whether the synthesized program remains effective outside the original five channels.
Load-bearing premise
The five-channel Medi-Sim simulator produces provider equilibria that match real-world responses to the tested incentive rules.
What would settle it
Deploy the synthesized rule program in an actual hospital claims system and measure whether up-coding rates and rejection rates match the simulator outputs under the same payment schedule.
Figures
read the original abstract
Healthcare mechanisms are inseparable from the strategic provider response they induce: existing healthcare AI benchmarks hold this response fixed and so cannot evaluate mechanisms by the equilibrium they produce. We recast hospital mechanism design as program synthesis for language models: typed, inspectable rule programs are executed and scored by Medi-Sim, a multi-agent simulator with five strategic provider channels (coding, selection, delay, effort, triage). An incentive sweep recovers classical health-economics findings as adjacent regimes -- up-coding and low-complexity-patient selection under profit pressure, and Goodhart-style drift where measured performance becomes anti-correlated with true outcomes -- and a single audit lever exposes pressure migration: closing the coding channel more than doubles low-complexity selection. LLM-guided evolutionary code search over the same rule-program space then synthesizes an inspectable mixed-objective program that eliminates up-coding, halves rejection, and retains most of the profit-oriented baseline's funds.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper recasts healthcare mechanism design as LLM-guided evolutionary synthesis of typed, inspectable rule programs that are executed and scored inside Medi-Sim, a multi-agent simulator containing five strategic provider channels (coding, selection, delay, effort, triage). An incentive sweep over rule programs recovers classical health-economics patterns (up-coding and low-complexity selection under profit pressure, Goodhart drift, and migration to selection when the coding channel is closed). The search then produces a mixed-objective program claimed to eliminate up-coding, halve rejection rates, and retain most of the funds generated by a profit-oriented baseline.
Significance. If the simulator equilibria match real provider behavior, the method would supply a route to equilibrium-aware, human-inspectable mechanisms that improve on fixed-response benchmarks. The recovery of classical findings supplies internal consistency evidence, and the production of executable rule code is a concrete strength. The absence of any external anchor, however, confines the demonstrated gains to the simulator itself.
major comments (2)
- [Abstract] Abstract: the central performance claims (eliminates up-coding, halves rejection, retains most funds) are obtained by evaluating the synthesized program inside the same Medi-Sim instance used to generate it; the manuscript supplies no comparison of simulated coding rates, selection thresholds, rejection elasticities, or equilibrium outcomes against empirical estimates from claims data, audits, or field studies.
- [Abstract] Abstract: the five strategic channels are introduced without reported calibration to external data or sensitivity analysis showing that the synthesized program's improvements are robust to plausible changes in the functional forms of provider response.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims (eliminates up-coding, halves rejection, retains most funds) are obtained by evaluating the synthesized program inside the same Medi-Sim instance used to generate it; the manuscript supplies no comparison of simulated coding rates, selection thresholds, rejection elasticities, or equilibrium outcomes against empirical estimates from claims data, audits, or field studies.
Authors: The evaluation is indeed performed entirely within Medi-Sim. This is by design, as the contribution lies in showing that evolutionary program synthesis can discover equilibrium-aware rules that improve on baselines while recovering known incentive problems as adjacent regimes. We have no empirical claims data for this study and therefore cannot supply the requested external comparisons. In revision we will temper the abstract language and insert a dedicated limitations section that states the simulator-internal scope explicitly. revision: yes
-
Referee: [Abstract] Abstract: the five strategic channels are introduced without reported calibration to external data or sensitivity analysis showing that the synthesized program's improvements are robust to plausible changes in the functional forms of provider response.
Authors: The channel specifications are stylized but are chosen to reproduce documented phenomena from the health-economics literature. The fact that the incentive sweep reproduces up-coding, selection, Goodhart drift, and channel migration supplies qualitative validation of the functional forms. We will add a sensitivity-analysis subsection that varies the main behavioral parameters and confirms that the synthesized rule retains its advantage over the profit baseline across the tested range. revision: yes
Circularity Check
No circularity: explicit simulation-based search and evaluation
full rationale
The paper performs an incentive sweep inside Medi-Sim to recover classical health-economics patterns as an internal consistency check, then runs LLM-guided search over rule programs scored by the same simulator. This is standard simulation-based mechanism design rather than any derivation, prediction, or first-principles result that reduces to its inputs by construction. No self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations appear. The performance claims are simulator outputs, not externally validated, but that is a fidelity issue, not circularity per the enumerated patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Medi-Sim's five strategic provider channels capture the dominant real-world responses to payment incentives
invented entities (1)
-
Medi-Sim multi-agent simulator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Health Care Management Science, 20(4):453–466
Flexible bed allocations for hospital wards. Health Care Management Science, 20(4):453–466. Gwyn Bevan and Christopher Hood. 2006. What’s measured is what matters: Targets and gaming in the english public health care system.Public Administration, 84(3):517–538. Sally C. Brailsford, Paul R. Harper, Bhakti Patel, and Martin Pitt. 2009. An analysis of the ac...
2006
-
[2]
Optimal auctions through deep learning: Advances in differentiable economics.Journal of the ACM, 71(1). Karen Eggleston. 2005. Multitasking and mixed systems for provider payment.Journal of Health Economics, 24(1):211–223. Frank Eijkenaar, Martin Emmert, Manfred Schep- pach, and Oliver Sch¨ offski. 2013. Effects of pay for performance in health care: A sy...
arXiv 2005
-
[3]
Generative agent-based modeling with ac- tions grounded in physical, social, or digital space using Concordia.Preprint, arXiv:2312.03664. Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanx- iao Liu, Quoc V. Le, Denny Zhou, and Xinyun Chen. 2023. Large language models as optimizers. arXiv preprint arXiv:2309.03409. Chao Yu, Jiming Liu, Shamim Nemati, and Gu- oshe...
arXiv 2023
-
[4]
strategic delay
and to practical, end-to-end differen- tiable training pipelines (Levanon and Rosen- feld, 2021).Performative predictiongeneralizes this to settings in which the deployed model itself shifts the data distribution and charac- terizes performative equilibria (Perdomo et al., 2020). The reward-shaping side of this litera- ture gives formal notions ofreward h...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.