Text-guided Feature Disentanglement for Cross-modal Gait Recognition
Pith reviewed 2026-06-28 23:16 UTC · model grok-4.3
The pith
Textual descriptions from language models act as anchors to disentangle modality-shared gait features between LiDAR point clouds and RGB videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
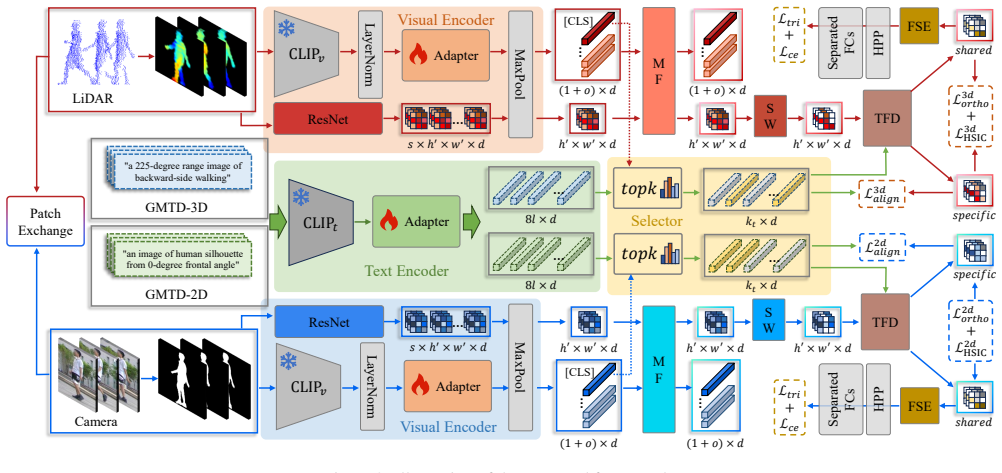
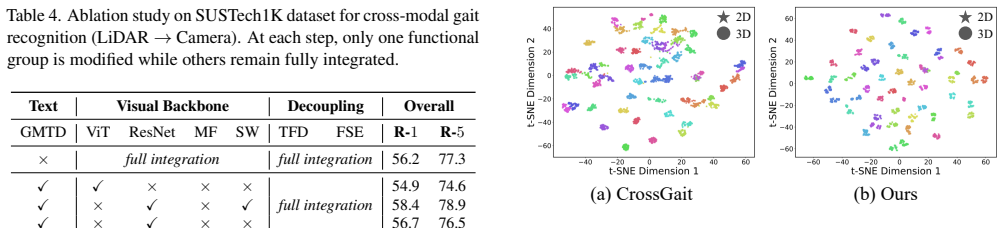
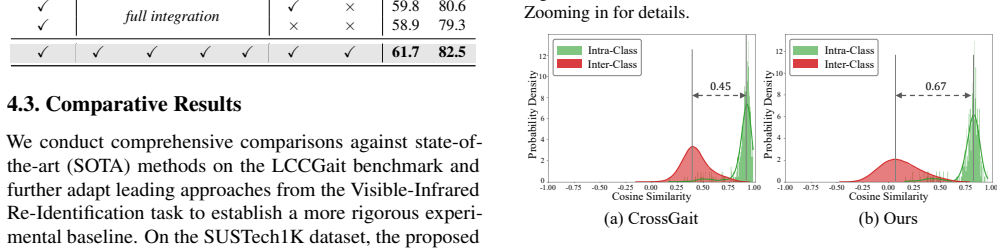
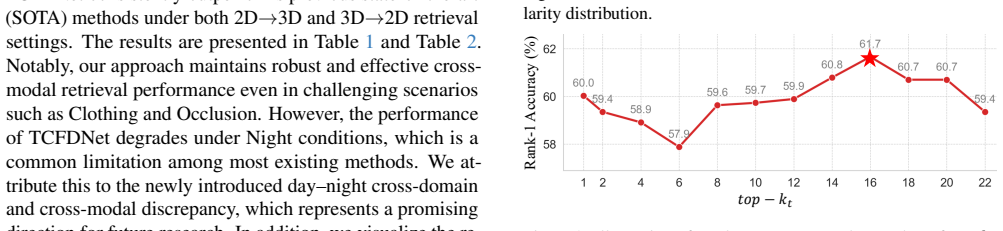
TCFDNet builds a Gait Modality Text Dictionary via large language models, aligns features in a unified vision-language space with a CLIP-based encoder, then applies the Text-guided Feature Disentanglement module to select top-k texts, reconstruct modality-specific parts, and isolate shared gait features through residual decomposition plus orthogonality constraints. A Feature Stability Enhancement module models spatial and channel correlations to stabilize the shared features, while cross-modal patch exchange further aids generalization. On the SUSTech1K and FreeGait benchmarks this yields new state-of-the-art accuracy for LiDAR-camera cross-modal gait recognition.
What carries the argument
The Text-guided Feature Disentanglement (TFD) module, which selects top-k matched textual descriptions to reconstruct modality-specific representations and derives modality-shared features via residual decomposition and orthogonality constraints.
If this is right
- Modality-aware textual priors enable extraction of representations usable across LiDAR and camera without paired samples at inference.
- Orthogonality constraints and residual decomposition produce shared features that remain stable under the Feature Stability Enhancement module.
- Cross-modal patch exchange improves generalization of the disentangled representations on the evaluated datasets.
- The overall pipeline sets new performance records on SUSTech1K and FreeGait for the LiDAR-camera cross-modal task.
Where Pith is reading between the lines
- If the text dictionary can be generated once and reused, the approach may lower the data requirements for training cross-modal models compared with purely visual methods.
- Similar text-anchoring could be tested on other sensor pairs such as infrared versus visible for the same gait task.
- The explicit textual component offers a route to inspect which gait semantics survive the disentanglement step.
Load-bearing premise
Large language models can generate rich, accurate semantic descriptions of gait across modalities and viewpoints that serve as reliable semantic anchors for feature disentanglement.
What would settle it
Replace the Gait Modality Text Dictionary with random or non-gait text and check whether the reported accuracy advantage over prior baselines on SUSTech1K disappears.
Figures




read the original abstract
Gait recognition is a biometric technique that identifies individuals based on their walking patterns, offering advantages in long-range, non-intrusive scenarios. However, real-world scenarios often involve heterogeneous sensing modalities such as LiDAR and RGB cameras, making LiDAR-Camera Cross-modal Gait recognition (LCCGR) a critical yet challenging task due to the substantial modality gap between 2D videos and 3D point cloud sequences. To address this challenge, we propose TCFDNet, a Text-guided Cross-modal Feature Disentanglement Network, which leverages modality-aware textual priors as semantic anchors to guide the learning of disentangled modality-shared representations. Specifically, we construct a Gait Modality Text Dictionary (GMTD) using large language models to generate rich semantic descriptions of gait across modalities and viewpoints. A CLIP-based Multi-grained Feature Encoder then aligns visual and textual features within a unified vision-language space. Furthermore, the Text-guided Feature Disentanglement (TFD) module selects the topk matched textual descriptions to reconstruct modality-specific representations and derive modality-shared features via residual decomposition and orthogonality constraints. To mitigate the fragility of the disentangled shared features, we propose a Feature Stability Enhancement (FSE) module, which models spatial and channel-wise correlations to improve feature robustness. In addition, a cross-modal patch exchange strategy is introduced to further improve generalization. Extensive experiments on SUSTech1K and FreeGait datasets demonstrate that TCFDNet achieves new state-of-the-art results and validate the effectiveness of the proposed modules.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TCFDNet for LiDAR-Camera Cross-modal Gait Recognition (LCCGR). It constructs a Gait Modality Text Dictionary (GMTD) via large language models to produce modality- and viewpoint-aware semantic descriptions of gait, aligns visual and textual features with a CLIP-based Multi-grained Feature Encoder, employs a Text-guided Feature Disentanglement (TFD) module that selects top-k text matches to reconstruct modality-specific features and derives shared features via residual decomposition plus orthogonality constraints, adds a Feature Stability Enhancement (FSE) module to model spatial/channel correlations, and applies cross-modal patch exchange for generalization. The central claim is that these components yield new state-of-the-art results on the SUSTech1K and FreeGait datasets while validating module effectiveness.
Significance. If the reported results hold, the work is significant for extending vision-language techniques to cross-modal biometrics: modality-aware textual priors serve as semantic anchors to learn disentangled shared representations, directly addressing the 2D-3D modality gap in gait recognition. The modular pipeline (GMTD construction, TFD residual/orthogonality, FSE, patch exchange) permits targeted ablation and is internally consistent with standard disentanglement practice. The explicit use of LLMs for gait semantics is a timely architectural contribution that could transfer to other heterogeneous sensing tasks.
minor comments (3)
- Abstract: the claim of 'new state-of-the-art results' would be strengthened by a single sentence reporting the absolute gains (e.g., Rank-1 accuracy deltas) on each dataset rather than leaving the quantitative improvement implicit.
- Method section (GMTD construction): the prompt templates and post-processing steps used to generate the Gait Modality Text Dictionary are described at a high level; adding one concrete example prompt and the resulting dictionary size would improve reproducibility.
- Notation: the symbols for the residual decomposition (shared vs. specific components) and the orthogonality loss are introduced without an explicit equation reference in the main text; a numbered equation would clarify the exact form of the orthogonality constraint.
Simulated Author's Rebuttal
We thank the referee for the detailed summary of our TCFDNet manuscript and the positive assessment of its significance in extending vision-language techniques to cross-modal gait recognition. The recommendation for minor revision is noted. However, the report lists no specific major comments to address.
Circularity Check
No significant circularity
full rationale
The paper describes a standard architectural pipeline for cross-modal gait recognition: LLM-based construction of a Gait Modality Text Dictionary, CLIP alignment, text-guided residual decomposition with orthogonality constraints in the TFD module, FSE for robustness, and patch exchange. No equations or steps in the provided description reduce a claimed prediction or result to its own inputs by construction, nor do they rely on load-bearing self-citations or imported uniqueness theorems. The method is presented as an empirical architectural contribution validated on external datasets (SUSTech1K, FreeGait), with no self-referential definitions or fitted-input-as-prediction patterns visible. This is the common case of a self-contained engineering paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Large language models generate rich semantic descriptions of gait across modalities and viewpoints
- domain assumption CLIP-based encoder can align visual gait features with textual descriptions in a unified space
invented entities (3)
-
Gait Modality Text Dictionary (GMTD)
no independent evidence
-
Text-guided Feature Disentanglement (TFD) module
no independent evidence
-
Feature Stability Enhancement (FSE) module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023. 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xi- aodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities.arXiv preprint arXiv:2308.12966, 1(2):3,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Icam: Inter- pretable classification via disentangled representations and feature attribution mapping.Advances in Neural Information Processing Systems, 33:7697–7709, 2020
Cher Bass, Mariana da Silva, Carole Sudre, Petru-Daniel Tudosiu, Stephen Smith, and Emma Robinson. Icam: Inter- pretable classification via disentangled representations and feature attribution mapping.Advances in Neural Information Processing Systems, 33:7697–7709, 2020. 2
2020
-
[5]
Gaitset: Regarding gait as a set for cross-view gait recogni- tion
Hanqing Chao, Yiwei He, Junping Zhang, and Jianfeng Feng. Gaitset: Regarding gait as a set for cross-view gait recogni- tion. InProceedings of the AAAI Conference on Artificial Intelligence, pages 8126–8133, 2019. 1, 2, 3
2019
-
[6]
Gaitset: Cross-view gait recognition through utilizing gait as a deep set.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(7):3467–3478, 2021
Hanqing Chao, Kun Wang, Yiwei He, Junping Zhang, and Jianfeng Feng. Gaitset: Cross-view gait recognition through utilizing gait as a deep set.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(7):3467–3478, 2021. 6
2021
-
[7]
Rodla: Benchmarking the robustness of document layout analysis models
Yufan Chen, Jiaming Zhang, Kunyu Peng, Junwei Zheng, Ruiping Liu, Philip Torr, and Rainer Stiefelhagen. Rodla: Benchmarking the robustness of document layout analysis models. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 15556–15566,
-
[8]
A Survey on In-context Learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Tianyu Liu, et al. A survey on in-context learning.arXiv preprint arXiv:2301.00234, 2022. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
Gaitpart: Temporal part-based model for gait recognition
Chao Fan, Yunjie Peng, Chunshui Cao, Xu Liu, Saihui Hou, Jiannan Chi, Yongzhen Huang, Qing Li, and Zhiqiang He. Gaitpart: Temporal part-based model for gait recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14225–14233, 2020. 2, 3
2020
-
[10]
Opengait: Revisiting gait recognition towards better practicality
Chao Fan, Junhao Liang, Chuanfu Shen, Saihui Hou, Yongzhen Huang, and Shiqi Yu. Opengait: Revisiting gait recognition towards better practicality. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9707–9716, 2023. 1, 3, 6, 7
2023
-
[11]
Skeletongait: Gait recognition using skeleton maps
Chao Fan, Jingzhe Ma, Dongyang Jin, Chuanfu Shen, and Shiqi Yu. Skeletongait: Gait recognition using skeleton maps. InProceedings of the AAAI Conference on Artificial Intelli- gence, pages 1662–1669, 2024. 2, 3
2024
-
[12]
Open- gait: A comprehensive benchmark study for gait recognition towards better practicality.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Chao Fan, Saihui Hou, Junhao Liang, Chuanfu Shen, Jingzhe Ma, Dongyang Jin, Yongzhen Huang, and Shiqi Yu. Open- gait: A comprehensive benchmark study for gait recognition towards better practicality.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. 3, 7
2025
-
[13]
Visible-infrared person re-identification via semantic alignment and affinity inference
Xingye Fang, Yang Yang, and Ying Fu. Visible-infrared person re-identification via semantic alignment and affinity inference. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11270–11279, 2023. 7
2023
-
[14]
Gpgait: Generalized pose-based gait recognition
Yang Fu, Shibei Meng, Saihui Hou, Xuecai Hu, and Yongzhen Huang. Gpgait: Generalized pose-based gait recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 19595–19604, 2023. 3
2023
-
[15]
Camera-lidar cross-modality gait recognition
Wenxuan Guo, Yingping Liang, Zhiyu Pan, Ziheng Xi, Jian- jiang Feng, and Jie Zhou. Camera-lidar cross-modality gait recognition. InEuropean Conference on Computer Vision, pages 439–455. Springer, 2025. 1, 3, 7
2025
-
[16]
Individual recognition using gait energy image.IEEE Transactions on Pattern Analysis and Machine Intelligence, 28(2):316–322, 2005
Jinguang Han and Bir Bhanu. Individual recognition using gait energy image.IEEE Transactions on Pattern Analysis and Machine Intelligence, 28(2):316–322, 2005. 2, 3
2005
-
[17]
Gait recognition in large- scale free environment via single lidar
Xiao Han, Yiming Ren, Peishan Cong, Yujing Sun, Jingya Wang, Lan Xu, and Yuexin Ma. Gait recognition in large- scale free environment via single lidar. InProceedings of the ACM International Conference on Multimedia, pages 380– 389, 2024. 1, 2, 3, 7
2024
-
[18]
Empowering visible- infrared person re-identification with large foundation mod- els.Advances in Neural Information Processing Systems, 37: 117363–117387, 2024
Zhangyi Hu, Bin Yang, and Mang Ye. Empowering visible- infrared person re-identification with large foundation mod- els.Advances in Neural Information Processing Systems, 37: 117363–117387, 2024. 7
2024
-
[19]
V2x- r: Cooperative lidar-4d radar fusion with denoising diffusion for 3d object detection
Xun Huang, Jinlong Wang, Qiming Xia, Siheng Chen, Bisheng Yang, Xin Li, Cheng Wang, and Chenglu Wen. V2x- r: Cooperative lidar-4d radar fusion with denoising diffusion for 3d object detection. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 27390–27400, 2025. 1
2025
-
[20]
L4dr: Lidar-4dradar fusion for weather-robust 3d object detection
Xun Huang, Ziyu Xu, Hai Wu, Jinlong Wang, Qiming Xia, Yan Xia, Jonathan Li, Kyle Gao, Chenglu Wen, and Cheng Wang. L4dr: Lidar-4dradar fusion for weather-robust 3d object detection. InProceedings of the AAAI Conference on Artificial Intelligence, pages 3806–3814, 2025. 1
2025
-
[21]
Ex- ploring more from multiple gait modalities for human identi- fication
Dongyang Jin, Chao Fan, Weihua Chen, and Shiqi Yu. Ex- ploring more from multiple gait modalities for human identi- fication. InProceedings of the AAAI Conference on Artificial Intelligence, pages 4120–4128, 2025. 1, 2, 3
2025
-
[22]
On denoising walking videos for gait recognition
Dongyang Jin, Chao Fan, Jingzhe Ma, Jingkai Zhou, Weihua Chen, and Shiqi Yu. On denoising walking videos for gait recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12347– 12357, 2025. 1, 2, 3
2025
-
[23]
A strong and robust skeleton-based gait recognition method with gait periodicity priors.IEEE Transactions on Multimedia, 25:3046–3058, 2022
Na Li and Xinbo Zhao. A strong and robust skeleton-based gait recognition method with gait periodicity priors.IEEE Transactions on Multimedia, 25:3046–3058, 2022. 2
2022
-
[24]
Gait recognition via ef- fective global-local feature representation and local temporal aggregation
Beibei Lin, Shunli Zhang, and Xin Yu. Gait recognition via ef- fective global-local feature representation and local temporal aggregation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14648–14656, 2021. 2, 3
2021
-
[25]
A compre- hensive survey on instruction following.arXiv preprint arXiv:2303.10475, 1, 2023
Renze Lou, Kai Zhang, and Wenpeng Yin. A compre- hensive survey on instruction following.arXiv preprint arXiv:2303.10475, 1, 2023. 3 9
-
[26]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning, pages 8748–8763. PmLR, 2021. 2, 3
2021
-
[27]
Implicit discriminative knowledge learning for visible-infrared person re-identification
Kaijie Ren and Lei Zhang. Implicit discriminative knowledge learning for visible-infrared person re-identification. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 393–402, 2024. 7
2024
-
[28]
Lidargait: Benchmarking 3d gait recog- nition with point clouds
Chuanfu Shen, Chao Fan, Wei Wu, Rui Wang, George Q Huang, and Shiqi Yu. Lidargait: Benchmarking 3d gait recog- nition with point clouds. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1054–1063, 2023. 1, 2, 5, 6, 7
2023
-
[30]
A comprehensive survey on deep gait recognition: Algorithms, datasets, and challenges.IEEE Transactions on Biometrics, Behavior, and Identity Science,
Chuanfu Shen, Shiqi Yu, Jilong Wang, George Q Huang, and Liang Wang. A comprehensive survey on deep gait recognition: Algorithms, datasets, and challenges.IEEE Transactions on Biometrics, Behavior, and Identity Science,
-
[31]
Li- dargait++: Learning local features and size awareness from lidar point clouds for 3d gait recognition
Chuanfu Shen, Rui Wang, Lixin Duan, and Shiqi Yu. Li- dargait++: Learning local features and size awareness from lidar point clouds for 3d gait recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6627–6636, 2025. 1, 7
2025
-
[32]
Multi- memory matching for unsupervised visible-infrared person re-identification
Jiangming Shi, Xiangbo Yin, Yeyun Chen, Yachao Zhang, Zhizhong Zhang, Yuan Xie, and Yanyun Qu. Multi- memory matching for unsupervised visible-infrared person re-identification. InEuropean Conference on Computer Vi- sion, pages 456–474. Springer, 2024. 8
2024
-
[33]
Two-stage knowledge distillation for visible-infrared person re-identification.Pattern Recogni- tion, 169:111850, 2026
Jiangming Shi, Xiangbo Yin, Demao Zhang, Zhizhong Zhang, Yuan Xie, and Yanyun Qu. Two-stage knowledge distillation for visible-infrared person re-identification.Pattern Recogni- tion, 169:111850, 2026. 7
2026
-
[34]
Gaitgraph: Graph con- volutional network for skeleton-based gait recognition
Torben Teepe, Ali Khan, Johannes Gilg, Fabian Herzog, Ste- fan H ¨ormann, and Gerhard Rigoll. Gaitgraph: Graph con- volutional network for skeleton-based gait recognition. In IEEE International Conference on Image Processing, pages 2314–2318. IEEE, 2021. 2, 3
2021
-
[35]
Visualizing data using t-sne.Journal of Machine Learning Research, 9 (11), 2008
Laurens Van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of Machine Learning Research, 9 (11), 2008. 8
2008
-
[36]
Chrono-gait image: A novel temporal template for gait recognition
Chen Wang, Junping Zhang, Jian Pu, Xiaoru Yuan, and Liang Wang. Chrono-gait image: A novel temporal template for gait recognition. InEuropean Conference on Computer Vision, pages 257–270. Springer, 2010. 2, 3
2010
-
[37]
Gait recog- nition with multi-level skeleton-guided refinement.IEEE Transactions on Multimedia, 2023
Runsheng Wang, Yuxuan Shi, Hefei Ling, Zongyi Li, Chengxin Zhao, Bohao Wei, He Li, and Ping Li. Gait recog- nition with multi-level skeleton-guided refinement.IEEE Transactions on Multimedia, 2023. 2
2023
-
[38]
Cross-modality gait recogni- tion: Bridging lidar and camera modalities for human identifi- cation
Rui Wang, Chuanfu Shen, Manuel J Marin-Jimenez, George Q Huang, and Shiqi Yu. Cross-modality gait recogni- tion: Bridging lidar and camera modalities for human identifi- cation. InIEEE International Joint Conference on Biometrics, pages 1–11. IEEE, 2024. 1, 3, 6, 7
2024
-
[39]
Tokenmatcher: Diverse tokens matching for unsupervised visible-infrared person re-identification
Xiao Wang, Lekai Liu, Bin Yang, Mang Ye, Zheng Wang, and Xin Xu. Tokenmatcher: Diverse tokens matching for unsupervised visible-infrared person re-identification. InPro- ceedings of the AAAI Conference on Artificial Intelligence, pages 7934–7942, 2025. 1
2025
-
[40]
Chain-of- thought prompting elicits reasoning in large language mod- els.Advances in Neural Information Processing Systems, 35: 24824–24837, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of- thought prompting elicits reasoning in large language mod- els.Advances in Neural Information Processing Systems, 35: 24824–24837, 2022. 3
2022
-
[41]
Bridging gait recognition and large language models sequence modeling
Shaopeng Yang, Jilong Wang, Saihui Hou, Xu Liu, Chun- shui Cao, Liang Wang, and Yongzhen Huang. Bridging gait recognition and large language models sequence modeling. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3460–3469, 2025. 1, 2, 3
2025
-
[42]
Chan- nel augmented joint learning for visible-infrared recognition
Mang Ye, Weijian Ruan, Bo Du, and Mike Zheng Shou. Chan- nel augmented joint learning for visible-infrared recognition. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13567–13576, 2021. 7
2021
-
[43]
Modality unifying network for visible-infrared person re-identification
Hao Yu, Xu Cheng, Wei Peng, Weihao Liu, and Guoying Zhao. Modality unifying network for visible-infrared person re-identification. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 11185–11195,
-
[44]
No escape: To- wards suggestive clues guidance for cross-modality person re-identification.Information Fusion, page 103185, 2025
Mingxin Yu, Yiyuan Ge, Zhihao Chen, Rui You, Lian- qing Zhu, Mingwei Lin, and Zeshui Xu. No escape: To- wards suggestive clues guidance for cross-modality person re-identification.Information Fusion, page 103185, 2025. 7
2025
-
[45]
Gaitref: Gait recognition with refined sequential skeletons
Haidong Zhu, Wanrong Zheng, Zhaoheng Zheng, and Ram Nevatia. Gaitref: Gait recognition with refined sequential skeletons. InIEEE International Joint Conference on Biomet- rics, pages 1–10. IEEE, 2023. 3
2023
-
[46]
Where and what? examining interpretable disentangled representations
Xinqi Zhu, Chang Xu, and Dacheng Tao. Where and what? examining interpretable disentangled representations. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5861–5870, 2021. 2
2021
-
[47]
A multi-stage adaptive feature fusion neural network for multimodal gait recognition.IEEE Transactions on Biometrics, Behavior, and Identity Science, 6(4):539–549,
Shinan Zou, Jianbo Xiong, Chao Fan, Chuanfu Shen, Shiqi Yu, and Jin Tang. A multi-stage adaptive feature fusion neural network for multimodal gait recognition.IEEE Transactions on Biometrics, Behavior, and Identity Science, 6(4):539–549,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.