EvoGens: A Population-Based Heuristic Search Framework for Scientific Idea Generation
Pith reviewed 2026-06-28 22:27 UTC · model grok-4.3
The pith
EvoGens recasts LLM-based scientific idea generation as evolutionary search over idea populations to raise novelty and diversity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
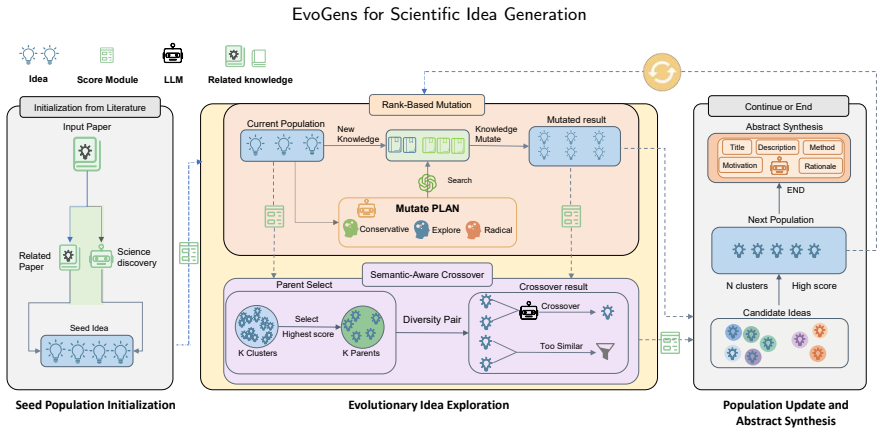
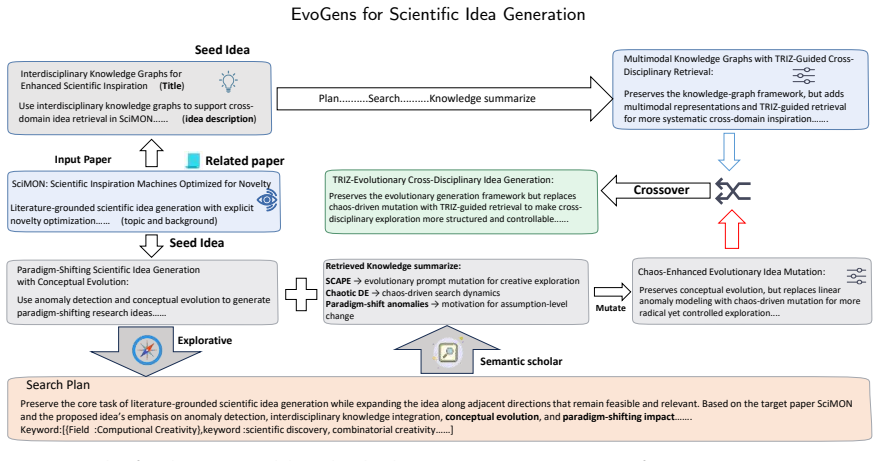
EvoGens recasts scientific idea generation as an evolutionary search over a population of ideas, iteratively applying rank-based mutation with differentiated retrieval planning to incorporate external knowledge, semantic-aware crossover to fuse complementary concepts, and a lightweight evaluation signal to guide selection and sustain exploration without premature convergence.
What carries the argument
Population-based evolutionary search using rank-based mutation, semantic-aware crossover, and lightweight evaluation-driven selection.
If this is right
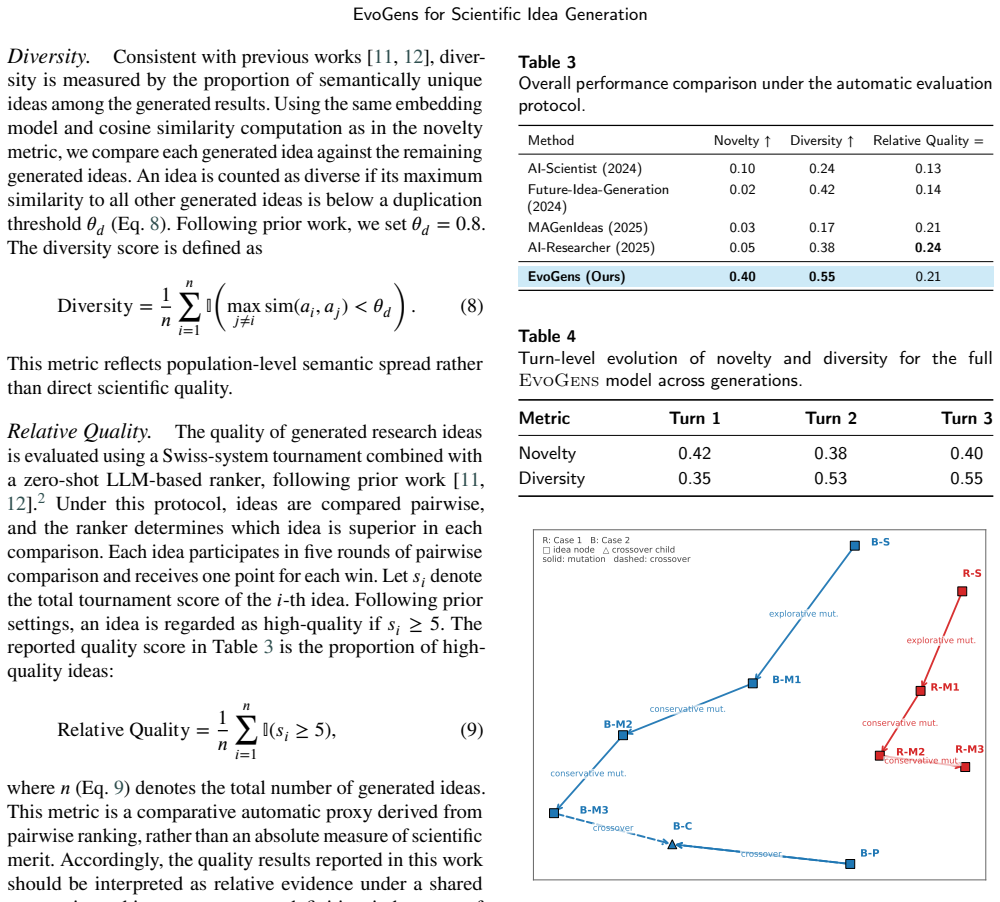
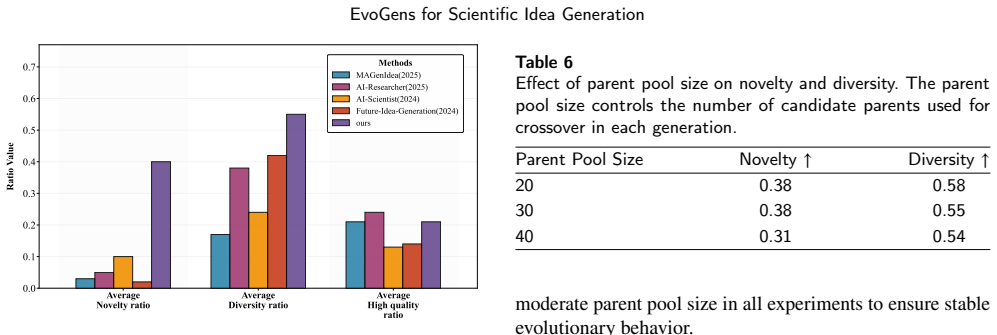
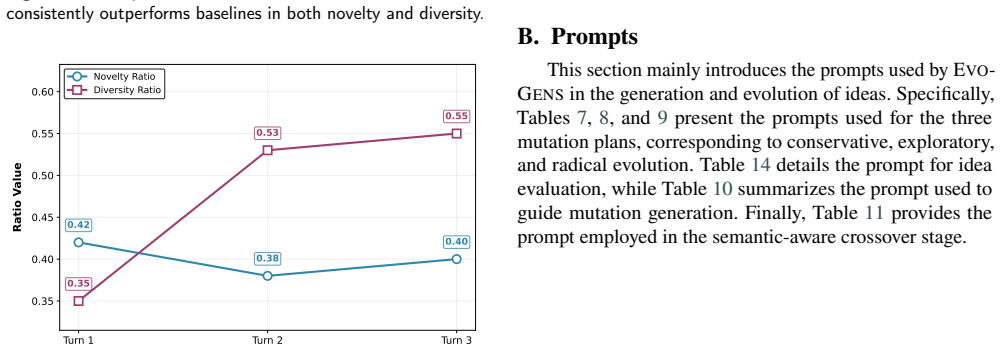
- Novelty of generated ideas rises from 0.1 to 0.4 under the automatic protocol.
- Diversity of generated ideas rises from 0.24 to 0.55 under the automatic protocol.
- Idea quality remains comparable to state-of-the-art baselines.
- Evolutionary mechanisms provide a workable framework for exploration-oriented research ideation.
Where Pith is reading between the lines
- The same population loop could be tested on non-scientific creative tasks such as story or product concept generation.
- If the automatic metrics later correlate better with human judgment, the framework could scale idea generation with less manual review.
- Domain-specific retrieval sources could be swapped in to adapt the mutation step to particular scientific fields.
Load-bearing premise
The paper's automatic evaluation protocol correctly measures novelty, diversity, and quality of the generated ideas.
What would settle it
Human experts rating sets of ideas from EvoGens and baselines find no reliable gain in perceived novelty or diversity.
Figures

read the original abstract
Generating novel research ideas is fundamental to scientific progress. While Large Language Models (LLMs) show promise in assisting this process, existing approaches often exhibit semantic convergence, resulting in limited diversity and novelty. To address this, we introduce EvoGens, an evolution-inspired framework that recasts scientific idea generation as an evolutionary search over a population of ideas. EvoGens iteratively applies rank-based mutation with differentiated retrieval planning to incorporate external knowledge, and semantic-aware crossover to fuse complementary concepts for conceptual reorganization. A lightweight evaluation signal guides the selection process, encouraging sustained exploration while mitigating premature convergence. Extensive experiments demonstrate that EvoGens substantially enhances exploration capabilities compared to state-of-the-art baselines. Specifically, it improves the Novelty from 0.1 to 0.4 and the Diversity from 0.24 to 0.55, while maintaining comparable idea quality under the current automatic evaluation protocol. These findings suggest that evolutionary mechanisms can serve as a useful framework for exploration-oriented research ideation, especially for broadening the novelty and diversity of candidate ideas under a shared automatic evaluation setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EvoGens, a population-based evolutionary search framework for LLM-assisted scientific idea generation. It recasts ideation as an evolutionary process over idea populations, applying rank-based mutation with differentiated retrieval planning to incorporate external knowledge, semantic-aware crossover for conceptual fusion, and a lightweight evaluation signal to guide selection and avoid premature convergence. Experiments claim that EvoGens substantially improves exploration, raising novelty from 0.1 to 0.4 and diversity from 0.24 to 0.55 relative to state-of-the-art baselines while keeping idea quality comparable, all under the paper's automatic evaluation protocol.
Significance. If the automatic metrics are shown to track human judgments of scientific novelty and diversity, the work would demonstrate a practical evolutionary heuristic for broadening the idea space generated by LLMs and mitigating semantic convergence, providing a reusable framework for exploration-oriented research ideation.
major comments (2)
- [Abstract] Abstract: the central claim of substantially enhanced exploration rests on reported gains in Novelty (0.1 o0.4) and Diversity (0.24 o0.55) produced by an automatic evaluation protocol, yet the abstract supplies no description of the protocol, baselines, measurement methods, statistical tests, or any correlation study with human expert judgments. Without this link the numerical deltas cannot be interpreted as evidence of genuine exploration improvement.
- [Abstract] Abstract (and Experiments section): no information is given on experimental design, including how candidate ideas are sampled, how the automatic metrics are computed, what the baselines are, or whether results are statistically significant. These omissions are load-bearing because the paper's conclusions about EvoGens's superiority depend entirely on the validity and reliability of the reported comparisons.
minor comments (1)
- [Abstract] The abstract states results hold "under the current automatic evaluation protocol" but does not name or briefly characterize that protocol, leaving readers without context for interpreting the metric values.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater clarity in the abstract and experimental reporting. We agree these details are essential for interpreting the reported gains and will revise the manuscript accordingly to scope claims explicitly to the automatic protocol while adding the requested information.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of substantially enhanced exploration rests on reported gains in Novelty (0.1 to 0.4) and Diversity (0.24 to 0.55) produced by an automatic evaluation protocol, yet the abstract supplies no description of the protocol, baselines, measurement methods, statistical tests, or any correlation study with human expert judgments. Without this link the numerical deltas cannot be interpreted as evidence of genuine exploration improvement.
Authors: We accept that the abstract must be expanded for interpretability. The original abstract already qualifies results as holding 'under the current automatic evaluation protocol,' but we will revise it to briefly name the metrics (novelty via embedding distance to prior work; diversity via pairwise semantic spread), list the main baselines, and note that no human correlation study is included in this work. Claims remain scoped to the automatic setting; we will add an explicit limitations paragraph acknowledging the absence of human validation and the proxy nature of the metrics. revision: yes
-
Referee: [Abstract] Abstract (and Experiments section): no information is given on experimental design, including how candidate ideas are sampled, how the automatic metrics are computed, what the baselines are, or whether results are statistically significant. These omissions are load-bearing because the paper's conclusions about EvoGens's superiority depend entirely on the validity and reliability of the reported comparisons.
Authors: We agree the experimental design details must be explicit. In the revised Experiments section we will add: (1) sampling procedure (fixed prompt templates, temperature, number of ideas per run), (2) precise metric definitions and computation (formulas or library calls for novelty and diversity), (3) full baseline descriptions, and (4) statistical significance tests (e.g., paired t-tests with p-values across multiple seeds). These additions will be placed before the results tables so readers can assess reliability without ambiguity. revision: yes
Circularity Check
No circularity: empirical results reported under an external protocol with no self-referential definitions or reductions by construction.
full rationale
The paper describes an evolutionary search framework and reports measured improvements in novelty (0.1 to 0.4) and diversity (0.24 to 0.55) under a stated automatic evaluation protocol. No equations, parameter fits, or derivations are presented that reduce the reported gains to the inputs by construction. The protocol is treated as an independent measurement step rather than a self-defining loop, and no self-citation chain is invoked to justify uniqueness or force the outcome. This is a standard empirical claim whose validity depends on external validation of the protocol, not on internal circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
J. Baek, S. K. Jauhar, S. Cucerzan, S. J. Hwang, ResearchAgent: Iterative Research Idea Generation over Scientific Literature with Large Language Models, in: L. Chiruzzo, A. Ritter, L. Wang (Eds.), Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume...
- [2]
-
[3]
H. Wang, T. Fu, Y. Du, W. Gao, K. Huang, Z. Liu, P. Chandak, S. Liu, P. V. Katwyk, A. Deac, A. Anandkumar, K. J. Bergen, C. P. Gomes, S. Ho, P. Kohli, J. Lasenby, J. Leskovec, T.-Y. Liu, A. K. Manrai, D. S. Marks, B. Ramsundar, L. Song, J. Sun, J. Tang, P. Velickovic, M. Welling, L. Zhang, C. W. Coley, Y. Bengio, M. Zitnik, Scientific discoveryintheageofa...
2023
-
[4]
M. Fire, C. Guestrin, Over-optimization of academic publishing metrics: Observing goodhart’s law in action, 2018. URL:https:// arxiv.org/abs/1809.07841.arXiv:1809.07841
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
OpenAI, J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman,D.Almeida,J.Altenschmidt,S.Altman,S.Anadkat,R.Avila, I. Babuschkin, S. Balaji, V. Balcom, P. Baltescu, H. Bao, M. Bavarian, J. Belgum, I. Bello, J. Berdine, G. Bernadett-Shapiro, C. Berner, L. Bogdonoff, O. Boiko, M. Boyd, A.-L. Brakman, G. Brockman, T. Brooks, M. Brundage, K. Butt...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Ma, T.-H
P. Ma, T.-H. Wang, M. Guo, Z. Sun, J. B. Tenenbaum, D. Rus, C. Gan, W.Matusik, Llmandsimulationasbileveloptimizers:anewparadigm to advance physical scientific discovery, in: Proceedings of the 41st International Conference on Machine Learning, ICML’24, JMLR.org, 2024
2024
-
[7]
Romera-Paredes, M
B. Romera-Paredes, M. Barekatain, A. Novikov, M. Balog, M. P. Kumar, E. Dupont, F. J. R. Ruiz, J. S. Ellenberg, P. Wang, O. Fawzi, P. Kohli, A. Fawzi, Mathematical discoveries from program search with large language models, Nature 625 (2024) 468–475
2024
-
[8]
Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions
H. Trivedi, N. Balasubramanian, T. Khot, A. Sabharwal, Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions, 2023. URL:https://arxiv.org/abs/2212.10509. arXiv:2212.10509
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Lewis, E
P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W. tau Yih, T. Rocktäschel, S. Riedel, D. Kiela, Retrieval-augmented generation for knowledge-intensive nlp tasks,
-
[10]
URL:https://arxiv.org/abs/2005.11401.arXiv:2005.11401
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[11]
Z. Wang, B. Peng, H. Tu, X. Li, Entity similarity rag: Enhancing llm answers with precise knowledge graph retrieval, in: T. Taniguchi, C. S. A. Leung, T. Kozuno, J. Yoshimoto, M. Mahmud, M. Doborjeh, K. Doya (Eds.), Neural Information Processing, Springer Nature Singapore, Singapore, 2026, pp. 229–243
2026
-
[12]
C. Si, D. Yang, T. Hashimoto, Can LLMs generate novel research ideas? a large-scale human study with 100+ NLP researchers, in: The Thirteenth International Conference on Learning Representations,
-
[13]
URL:https://openreview.net/forum?id=M23dTGWCZy
-
[14]
X. Hu, H. Fu, J. Wang, Y. Wang, Z. Li, R. Xu, Y. Lu, Y. Jin, L. Pan, Z. Lan, Nova: An Iterative Planning and Search Ap- proach to Enhance Novelty and Diversity of LLM Generated Ideas,
-
[15]
In: Medical Imaging with Deep Learning (MIDL)
URL: http://arxiv.org/abs/2410.14255. doi:10.48550/arXiv. 2410.14255, arXiv:2410.14255 [cs]
work page internal anchor Pith review doi:10.48550/arxiv
-
[16]
L. Li, W. Xu, J. Guo, R. Zhao, X. Li, Y. Yuan, B. Zhang, Y. Jiang, Y. Xin, R. Dang, D. Zhao, Y. Rong, T. Feng, L. Bing, Chain of Ideas: Revolutionizing Research Via Novel Idea Development with LLM Agents, 2024. URL:http://arxiv.org/abs/2410.13185. doi:10.48550/ arXiv.2410.13185, arXiv:2410.13185 [cs]
-
[17]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. Le, D. Zhou, Chain-of-thought prompting elicits reasoning in largelanguagemodels,2023.URL: https://arxiv.org/abs/2201.11903. arXiv:2201.11903
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
L. Meincke, E. R. Mollick, C. Terwiesch, Prompting Diverse Ideas: Increasing AI Idea Variance, 2024. URL:http://arxiv.org/abs/2402. 01727. doi:10.48550/arXiv.2402.01727, arXiv:2402.01727 [cs]
-
[19]
H. Su, R. Chen, S. Tang, Z. Yin, X. Zheng, J. Li, B. Qi, Q. Wu, H. Li, W. Ouyang, P. Torr, B. Zhou, N. Dong, Many Heads Are Better Than One: Improved Scientific Idea Generation by A LLM-Based Multi- Agent System, in: W. Che, J. Nabende, E. Shutova, M. T. Pilehvar (Eds.), Proceedings of the 63rd Annual Meeting of the Association for Li et al.:Preprint subm...
2025
-
[20]
S. Chen, C. Zhang, Enhancing Research Idea Generation through Combinatorial Innovation and Multi-Agent Iterative Search Strategies, in:Proceedingsofthe20thInternationalConferenceonScientometrics & Informetrics, 2025
2025
- [21]
- [22]
-
[23]
C. Lu, C. Lu, R. T. Lange, J. Foerster, J. Clune, D. Ha, The AI Scientist: Towards Fully Automated Open-Ended Scientific Dis- covery, 2024. URL:http://arxiv.org/abs/2408.06292. doi:10.48550/ arXiv.2408.06292, arXiv:2408.06292 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Girotra, L
K. Girotra, L. Meincke, C. Terwiesch, K. T. Ulrich, Ideas are dimes a dozen: Large language models for idea generation in innovation, SSRN Electronic Journal (2023)
2023
- [25]
-
[26]
Xiao, Evolutionary algorithms, in: R
N. Xiao, Evolutionary algorithms, in: R. Kitchin, N. Thrift (Eds.), International Encyclopedia of Human Geography, Else- vier, Oxford, 2009, pp. 660–665. URL:https://www.sciencedirect. com/science/article/pii/B9780080449104005253. doi:https://doi.org/ 10.1016/B978-008044910-4.00525-3
-
[27]
J. Kelly, Interactive genetic algorithms for use as creativity enhance- ment tools, in: Proceedings of the AAAI Conference on Artificial Intelligence, volume 22, AAAI Press, Chicago, Illinois, USA, 2008, pp. 123–130
2008
-
[28]
M. L. Hongying Song, Application of Using Improved Genetic Algorithm in Art Design, Journal of Electrical Systems 20 (2024) 1603–1612
2024
-
[29]
arXiv preprint arXiv:2206.08896
J. Lehman, J. Gordon, S. Jain, K. Ndousse, C. Yeh, K. O. Stanley, Evolution through large models, 2022. URL:https://arxiv.org/abs/ 2206.08896.arXiv:2206.08896
-
[30]
Meyerson, M
E. Meyerson, M. J. Nelson, H. Bradley, A. Gaier, A. Moradi, A. K. Hoover, J. Lehman, Language model crossover: Variation through few-shot prompting, ACM Transactions on Evolutionary Learning and Optimization 4 (2024) 1–40
2024
- [31]
-
[32]
Q. Guo, R. Wang, J. Guo, B. Li, K. Song, X. Tan, G. Liu, J. Bian, Y.Yang,EvoPrompt:ConnectingLLMswithEvolutionaryAlgorithms Yields Powerful Prompt Optimizers, 2025. URL:http://arxiv.org/ abs/2309.08532. doi:10.48550/arXiv.2309.08532, arXiv:2309.08532 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.08532 2025
- [33]
-
[34]
N. van Stein, T. Bäck, Llamea: A large language model evolutionary algorithm for automatically generating metaheuristics, 2025. URL: https://arxiv.org/abs/2405.20132.arXiv:2405.20132
-
[35]
C. Morris, M. Jurado, J. Zutty, LLM Guided Evolution – The Automation of Models Advancing Models, 2024. URL:http://arxiv. org/abs/2403.11446. doi:10.1145/3638529.3654178, arXiv:2403.11446 [cs]
-
[36]
Y. Zhang, G. Yi, Laos: Large language model-driven adaptive operator selection for evolutionary algorithms, in: Proceedings of the Genetic and Evolutionary Computation Conference, GECCO ’25, Association for Computing Machinery, New York, NY, USA, 2025, p. 517–526. URL:https://doi.org/10.1145/3712256.3726450. doi:10.1145/3712256.3726450
-
[37]
P. Shojaee, K. Meidani, S. Gupta, A. B. Farimani, C. K. Reddy, LLM- SR: Scientific Equation Discovery via Programming with Large Lan- guage Models, 2025. URL:http://arxiv.org/abs/2404.18400. doi:10. 48550/arXiv.2404.18400, arXiv:2404.18400 [cs]
-
[38]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E.Chi,Q.Le,D.Zhou,Chain-of-ThoughtPromptingElicitsReasoning in Large Language Models, 2023. URL:http://arxiv.org/abs/2201. 11903. doi:10.48550/arXiv.2201.11903, arXiv:2201.11903 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2201.11903 2023
-
[39]
S. Yao, D. Yu, J. Zhao, I. Shafran, T. L. Griffiths, Y. Cao, K. Narasimhan, Tree of thoughts: Deliberate problem solving with largelanguagemodels,2023.URL: https://arxiv.org/abs/2305.10601. arXiv:2305.10601
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [40]
-
[41]
R. Aksitov, S. Miryoosefi, Z. Li, D. Li, S. Babayan, K. Koppa- rapu, Z. Fisher, R. Guo, S. Prakash, P. Srinivasan, M. Zaheer, F. Yu, S. Kumar, Rest meets react: Self-improvement for multi-step reasoning llm agent, 2023. URL:https://arxiv.org/abs/2312.10003. arXiv:2312.10003
- [42]
- [43]
- [44]
-
[45]
F. Keya, G. Rabby, P. Mitra, S. Vahdati, S. Auer, Y. Jaradeh, Sci-idea: Context-awarescientificideationusingtokenandsentenceembeddings,
- [46]
-
[47]
Zhang, J
J. Zhang, J. Han, S. Ahmed-Kristensen, Exploring the use of llms to evaluate design creativity, Proceedings of the Design Society 5 (2025) 1773–1782
2025
- [48]
-
[49]
O.A.Hurst,A.Lerer,A.P.Goucher,A.Perelman,A.Ramesh,A.Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radford, A. Mkadry, A. Baker- Whitcomb, A. Beutel, A. Borzunov, A. Carney, A. Chow, A. Kirillov, A. Nichol, A. Paino, A. Renzin, A. P. etal, Gpt-4o system card, ArXiv abs/2410.21276 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
A. Singh, A. Fry, A. Perelman, A. Tart, A. Ganesh, A. El-Kishky, A.McLaughlin,A.Low,A.Ostrow,A.Ananthram,A.Nathan,A.Luo, A. Helyar, A. Madry, A. Efremov, A. Spyra, A. Baker-Whitcomb, A. Beutel, A. Karpenko, A. Makelov, A. Neitz, A. Wei, A. Barr, A. Kirchmeyer, A. etal, Openai gpt-5 system card, 2025. URL:https: //arxiv.org/abs/2601.03267.arXiv:2601.03267
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
W. Wang, F. Wei, L. Dong, H. Bao, N. Yang, M. Zhou, Minilm: Deep self-attention distillation for task-agnostic compression of pre- trained transformers, 2020. URL:https://arxiv.org/abs/2002.10957. arXiv:2002.10957. A. Additional Analysis of Evolution Dynamics Figure 5 presents a bar-chart comparison between EVO- GENSandbaselinemethodsintermsofnovelty,dive...
-
[52]
Understand the target paper and the old idea, and identify which core components of the old idea should be preserved
-
[53]
Understand the newly retrieved knowledge, and identify which insights, methods, assumptions, or evaluation strategies can be transferred
-
[54]
Please first generate5 possible mutated ideas, analyze the strengths and weaknesses of each, and then select thebest 2 final ideas
Propose improved ideas that remain grounded in the target paper and traceably evolve from the old idea, rather than replacing it with an unrelated proposal. Please first generate5 possible mutated ideas, analyze the strengths and weaknesses of each, and then select thebest 2 final ideas. In the thinking step, explicitly explain: - what is preserved from t...
-
[55]
remain aligned with the target paper’s research topic,
-
[56]
preserve a traceable connection to the old idea,
-
[57]
incorporate useful insights from the new knowledge,
-
[58]
Title": concise title -
introduce non-trivial but coherent changes in motivation, method, scope, or rationale. Format In<JSON>, provide the final idea list in JSON format, where every idea contains: -"Title": concise title - "thinking": explain what is preserved from the old idea, what is changed, which retrieved knowledge inspired the mutation, and why the result is coherent an...
-
[59]
The new idea should stay within the target paper’s topic and improve or extend the old idea
-
[60]
The new idea must be meaningfully different from the old idea, while preserving conceptual continuity
-
[61]
The retrieved knowledge is used as inspiration for mutation, not as text to be copied or directly cited
-
[62]
Avoid generating a completely unrelated new proposal
-
[63]
Please think step by step
-
[64]
Only the final 2 ideas should be returned in JSON format. Input: - target paper title:{t_title} - target paper abstract:{t_abstract} - old_idea:{seed_idea} - new_knowledge:{new_knowledge} Output: ### Thinking <Explain the target paper topic, what is preserved from the old idea, what is changed using the new knowledge, and why the mutation is coherent and ...
-
[65]
Decompose each parent into: core assumption, research motivation, method/mechanism, application scope, and expected contribution
-
[66]
Analyze compatibility, conflict, complementarity, and whether direct fusion is feasible
-
[67]
Generate offspring only through component-level recombination such as assumption replacement, mechanism transplant, scope transfer, causal workflow recomposition, or contribution reframing
-
[68]
If the parents are too distant, keep Parent1 as the structural anchor and import exactly one mechanism-level component from Parent2
-
[69]
Generate 5 variants if direct crossover is feasible, or 3 constrained variants if fallback is triggered
-
[70]
thinking
Select the best 2 variants with distinct innovation dimensions and coherent parent contribution. Avoid - simple concatenation of parent ideas - side-by-side restatement of both parents - minor wording variations of the parents - vague fusion language without explicit structural change - superficial hybrids with no coherent transfer path Evaluation Criteri...
-
[71]
Understanding of the target paper and related papers is essential: – The target paper is the primary research study you aim to enhance or build upon through future research, serving as the central source and focus for identifying and developing the specific research idea. – The referenced papers are studies that the target paper has cited, indicating thei...
-
[72]
You need to select appropriate theories and combine the information provided by the current paper to come up with creative, influential, and feasible ideas
Understanding of the scientific discovery theories is essential. You need to select appropriate theories and combine the information provided by the current paper to come up with creative, influential, and feasible ideas
-
[73]
Here are 10 general laws and methodologies of scientific discovery from the perspective of the philosophy of science. [The scientific discovery theories shown in Table 12 are inserted here in the actual prompt.] You can choose one or more of these methodologies and propose a new scientific research idea for the target paper. Requirements
-
[74]
Output an idea worth exploring
-
[75]
You should aim for new research ideas that can potentially win best paper awards at top conferences like ACL, NeurIPS, ICLR, and CVPR
-
[76]
Skip the research theories that may not well match the target paper; the theory and method you use should make sense and be reasonable for the target paper
-
[77]
Please explain which theory you used in your thinking process
Thinking is your thinking process. Please explain which theory you used in your thinking process
-
[78]
Please output your thought process
-
[79]
Title": A title for the idea, which will be used for the paper writing. –
Please think step by step. Input: target_paper: {} referenced_papers: {} Please respond in the following format: Thought: <THOUGHT> IDEA:“‘json<JSON>“‘ In <THOUGHT>, output your thinking process here, explain why you chose these theories to discover new ideas and why it should have a chance to win the best paper awards at top conferences. In <JSON>, provi...
-
[80]
The search plan should be developed around the given research idea
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.