Retriever Portfolios: A Principled Approach to Adaptive RAG
Pith reviewed 2026-06-28 23:31 UTC · model grok-4.3
The pith
A small fixed portfolio of retrievers chosen to maximize expected best-of-k performance covers query heterogeneity better than any single retriever.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a method that automatically selects a small, diverse subset of retrievers (a portfolio) from a large pool of candidates, to cover different regions of the target query distribution. We formalize this setting via an expected best-of-k objective over the query distribution and show that it admits an efficient portfolio construction algorithm with near-optimal guarantees. Across multiple QA benchmarks, our learned portfolios and router pipeline consistently outperform single-retriever and naive multi-retriever baselines on both retrieval metrics and answer quality.
What carries the argument
The expected best-of-k objective, which selects the portfolio maximizing average performance when the best of the k chosen retrievers is taken for each query.
If this is right
- Learned portfolios plus router improve both retrieval metrics and downstream answer quality on standard QA benchmarks.
- Fixed portfolios allow parallel retrieval and LLM calls, matching or exceeding the accuracy of inference-time hyperparameter tuning at substantially lower latency and token cost.
- The portfolio construction algorithm runs efficiently and carries near-optimal approximation guarantees relative to the best possible portfolio.
- The approach replaces the need to tune a single retriever's hyperparameters per query with a static small set that still adapts via a router.
Where Pith is reading between the lines
- The same portfolio idea could be applied to other retrieval-dependent pipelines such as long-context summarization or tool-use agents.
- If retriever quality distributions shift over time, periodic re-optimization of the portfolio on fresh query samples would be a natural extension.
- The router that picks which portfolio member to use for a given query could itself be made more expressive without changing the underlying portfolio construction.
Load-bearing premise
A small fixed subset of retrievers can cover heterogeneous regions of the target query distribution sufficiently well that the expected best-of-k objective yields practically useful gains over single-retriever baselines.
What would settle it
A new QA benchmark on which the best fixed portfolio of size k selected by the algorithm fails to improve both retrieval metrics and answer quality over the single best retriever from the original pool.
Figures


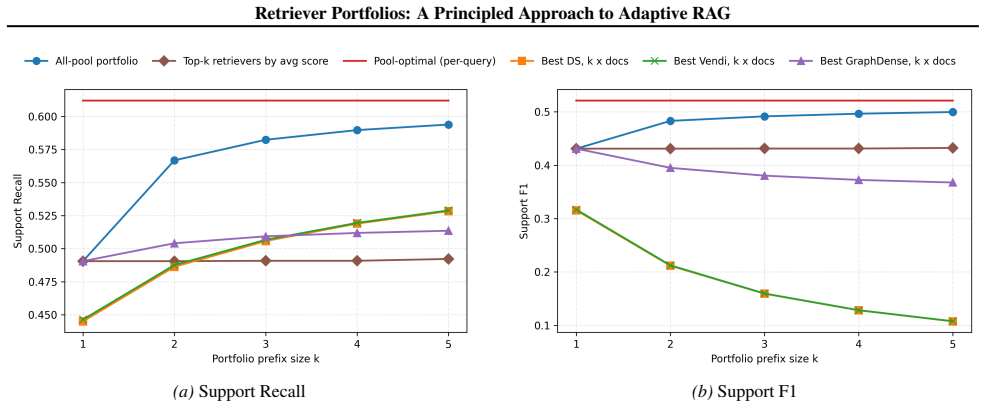
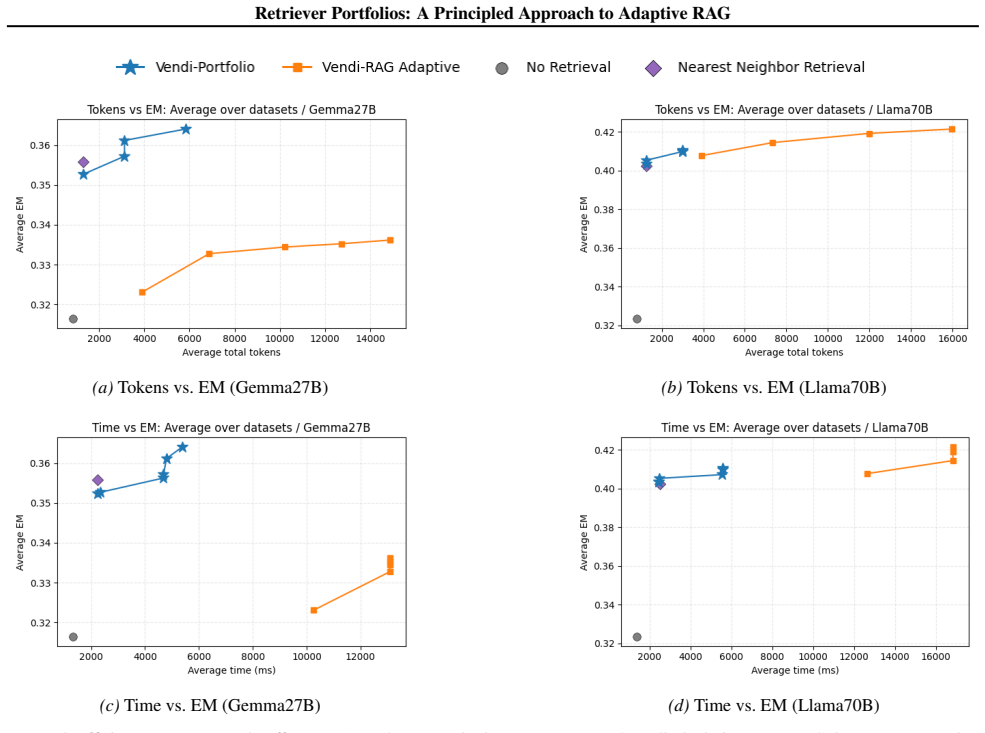

read the original abstract
Retrieval-augmented generation (RAG) systems typically rely on a single retriever and a single set of hyperparameters, despite facing highly heterogeneous queries that range from simple factoid questions to complex multi-hop reasoning. We propose a method that automatically selects a small, diverse subset of retrievers (a portfolio) from a large pool of candidates, to cover different regions of the target query distribution. We formalize this setting via an expected best-of-$k$ objective over the query distribution and show that it admits an efficient portfolio construction algorithm with near-optimal guarantees. Across multiple QA benchmarks, our learned portfolios and router pipeline consistently outperform single-retriever and naive multi-retriever baselines on both retrieval metrics and answer quality. In addition, compared to inference-time hyperparameter tuning approaches, fixed portfolios enable parallel retrieval and LLM calls, achieving comparable (and sometimes better) accuracy with substantially lower latency and token cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces 'retriever portfolios' for RAG systems: an algorithm that selects a small, fixed, diverse subset of retrievers from a candidate pool to cover heterogeneous regions of a target query distribution. It formalizes the problem via an expected best-of-k objective, derives an efficient construction procedure with near-optimal guarantees, and reports that the resulting portfolios plus a router outperform single-retriever and naive multi-retriever baselines on retrieval metrics and downstream QA accuracy across multiple benchmarks while also reducing latency relative to inference-time hyperparameter search.
Significance. If the formal guarantees and the reported empirical gains hold under scrutiny, the work supplies a principled, low-overhead alternative to both monolithic retrievers and dynamic per-query selection, directly addressing a practical pain point in production RAG pipelines. The emphasis on fixed portfolios enabling parallel retrieval and the explicit comparison against latency/token-cost baselines are concrete strengths.
minor comments (2)
- The abstract and introduction claim 'near-optimal guarantees' and 'consistent outperformance' but the provided text does not include the precise statement of the approximation ratio, the dataset statistics, or error bars on the reported metrics; these details should be added to the main body or a dedicated experimental appendix.
- Notation for the expected best-of-k objective and the router pipeline should be introduced with a single, self-contained definition block early in the paper to avoid forward references.
Simulated Author's Rebuttal
We thank the referee for the thorough and positive review, which highlights the practical relevance of fixed retriever portfolios for production RAG pipelines. We are encouraged by the assessment that the formal guarantees and latency comparisons address a real pain point. Since the report contains no specific major comments requiring clarification or changes, we provide no point-by-point responses below.
Circularity Check
No significant circularity
full rationale
The paper defines an expected best-of-k objective over an external query distribution, derives an efficient portfolio construction algorithm with near-optimal guarantees, and validates via empirical outperformance on QA benchmarks. No load-bearing step reduces by construction to fitted inputs, self-citations, or renamed known results; the derivation chain remains independent of the target claims.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Metamorphictestingoflarge languagemodelsfornaturallanguageprocessing.doi:10.48550/arXiv
URL https://aclanthology.org/2025. emnlp-main.601/. Karpukhin, V ., Oguz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., and Yih, W.-t. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 6769–6781, 2020. Kleinberg, J., Papadimitriou, C., a...
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[2]
Prefer statements that are specific and unambiguous; favor answers supported by multiple passages
Evidence-first: If the passages contain explicit evidence that entails the answer, use it. Prefer statements that are specific and unambiguous; favor answers supported by multiple passages
-
[3]
No evidence -> best-guess: If the passages are irrelevant, too vague, or do not entail an answer, give your best-guess from your general knowledge, but mark mode=’ guess’
-
[4]
Do not invent unsupported details
Never contradict the passages: If any passage clearly contradicts your prior knowledge, trust the passages unless they are clearly off-topic (irrelevant to the question). Do not invent unsupported details
-
[5]
Be concise: The answer must be a single word, name, date, number, or very short phrase
-
[6]
evidence|guess
Always put the final answer inside <answer>...</answer> tags. Conflict handling: - If passages disagree, pick the answer with the strongest explicit support (more passages, clearer wording). - If the evidence is ambiguous, output your best guess but mark the mode as ’guess’ and explicitly mention this in your explanation. - If multi-hop reasoning is neede...
1998
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.