FSM-Net: An Efficient Frequency-Spatial Network for Real-World Deblurring
Pith reviewed 2026-06-28 22:33 UTC · model grok-4.3
The pith
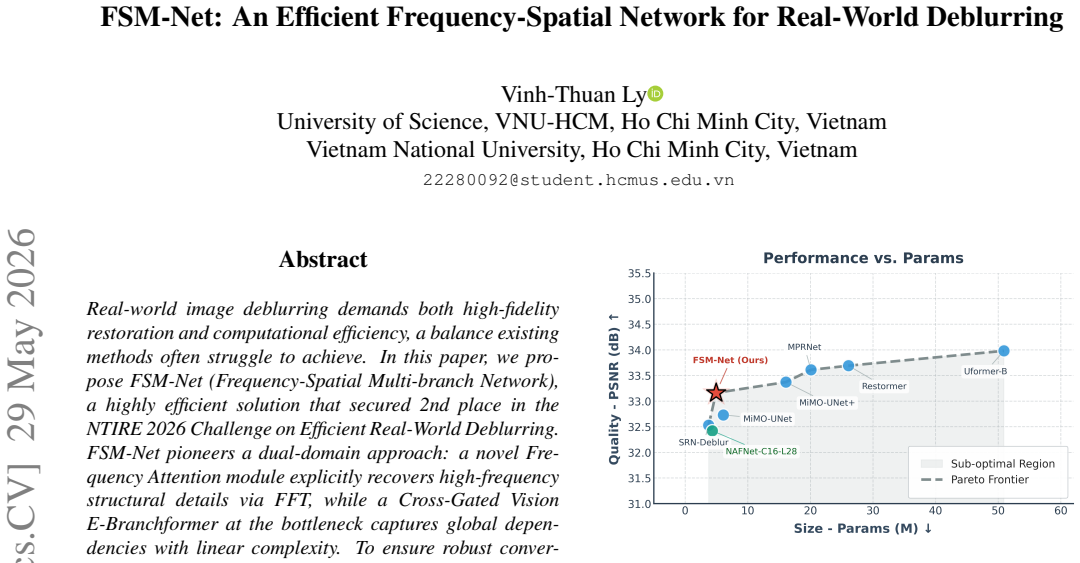
FSM-Net restores real-world blurred images to 33.144 dB PSNR using a dual frequency-spatial network with only 4.94 million parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
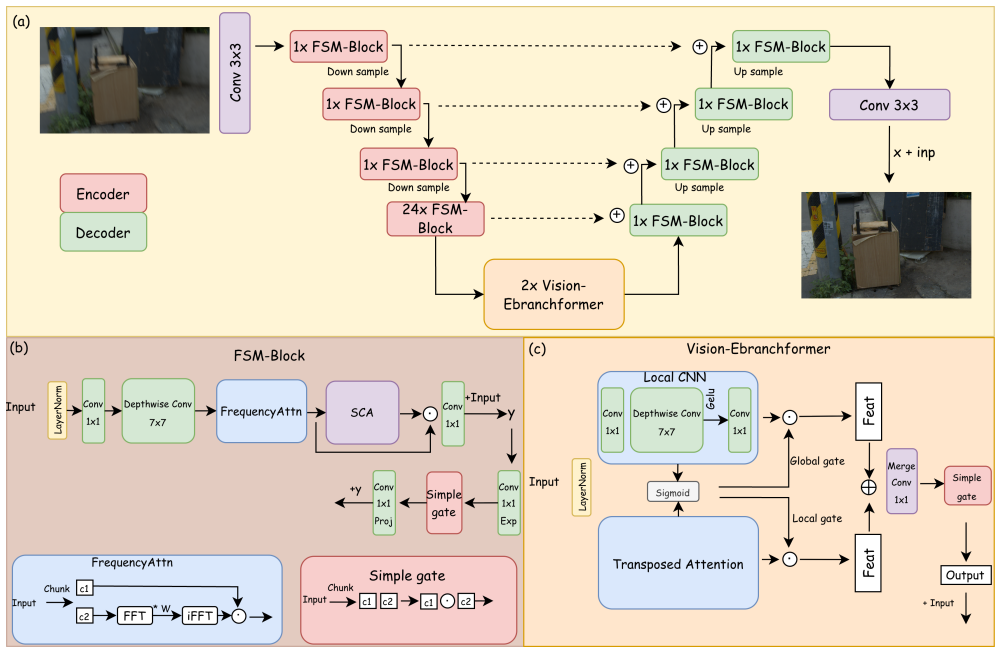
FSM-Net is a Frequency-Spatial Multi-branch Network that applies a Frequency Attention module to recover high-frequency structural details via FFT operations and places a Cross-Gated Vision E-Branchformer at the bottleneck to capture global dependencies with linear complexity. A progressive curriculum training strategy guided by a composite loss function of Multi-Scale Charbonnier, Structural Edge, and Frequency terms enables robust convergence, resulting in 33.144 dB PSNR, 4.94M parameters, and 159.35 GMACs at 1920x1200 resolution on the RSBlur benchmark.
What carries the argument
Frequency Attention module that recovers high-frequency structural details via FFT, paired with Cross-Gated Vision E-Branchformer for global dependencies at linear complexity
If this is right
- The dual-domain architecture achieves second place in the NTIRE 2026 Challenge on Efficient Real-World Deblurring.
- The method improves the efficiency-quality Pareto frontier for real-world deblurring at 1920x1200 resolution.
- The linear-complexity E-Branchformer combined with frequency attention supports high-fidelity output under tight parameter and GMAC budgets.
- The composite loss and progressive training schedule enable reliable convergence on real captured blur without heavy overfitting.
Where Pith is reading between the lines
- The frequency attention mechanism could be extended to video sequences by incorporating temporal frequency components.
- Linear complexity in the bottleneck suggests the design may scale to higher resolutions without quadratic memory growth.
- The same frequency-spatial split and composite loss might transfer to related tasks such as denoising or deraining.
- Ablating the FFT-based attention versus the E-Branchformer on the same backbone would isolate which component drives the efficiency gain.
Load-bearing premise
The progressive curriculum training with the composite loss produces robust convergence on real-world data without overfitting to the RSBlur distribution.
What would settle it
Evaluating the same architecture on an independent real-world blur dataset with different capture conditions and measuring whether PSNR remains near 33 dB would test whether the training strategy generalizes.
Figures

read the original abstract
Real-world image deblurring demands both high-fidelity restoration and computational efficiency, a balance existing methods often struggle to achieve. In this paper, we propose FSM-Net (Frequency-Spatial Multi-branch Network), a highly efficient solution that secured 2nd place in the NTIRE 2026 Challenge on Efficient Real-World Deblurring. FSM-Net pioneers a dual-domain approach: a novel Frequency Attention module explicitly recovers high-frequency structural details via FFT, while a Cross-Gated Vision E-Branchformer at the bottleneck captures global dependencies with linear complexity. To ensure robust convergence, we employ a progressive curriculum training strategy guided by a composite loss function (Multi-Scale Charbonnier, Structural Edge, and Frequency). Evaluated on the RSBlur benchmark, FSM-Net achieves an outstanding 33.144 dB PSNR with only 4.94M parameters and 159.35 GMACs (at 1920x1200 resolution). By effectively pushing the Pareto frontier of efficiency and quality, FSM-Net establishes a strong baseline for resource-constrained image restoration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FSM-Net, a dual-domain Frequency-Spatial Multi-branch Network for real-world image deblurring. It introduces a Frequency Attention module that uses FFT to recover high-frequency details, a Cross-Gated Vision E-Branchformer at the bottleneck for global dependencies with linear complexity, and a progressive curriculum training strategy driven by a composite loss (Multi-Scale Charbonnier + Structural Edge + Frequency). The central claim is that this architecture secured 2nd place in the NTIRE 2026 Challenge on Efficient Real-World Deblurring and delivers 33.144 dB PSNR on the RSBlur benchmark at 1920x1200 resolution using only 4.94M parameters and 159.35 GMACs, thereby advancing the efficiency-quality Pareto frontier.
Significance. If the reported metrics are supported by proper controls, the work would be significant for resource-constrained image restoration by showing that a compact dual-domain design can reach competitive real-world deblurring performance. The explicit frequency-domain recovery mechanism and linear-complexity global modeling are concrete contributions that could serve as a reproducible baseline for subsequent efficient restoration networks.
major comments (3)
- [§5] §5 (Experiments) and associated tables: No ablation studies isolate the contribution of the progressive curriculum stages or the individual terms in the composite loss. The headline 33.144 dB PSNR is therefore unattributed, leaving open whether the gain stems from the Frequency Attention module and E-Branchformer or from dataset-specific tuning of the free parameters (loss weights and curriculum schedule).
- [§5.1] §5.1 (Quantitative results): The manuscript states the RSBlur benchmark result and challenge ranking but supplies neither a comparison table against other NTIRE 2026 entries nor standard baselines (e.g., Restormer, NAFNet) with identical training protocols. This omission directly weakens the Pareto-frontier claim.
- [§4.3] §4.3 (Training strategy): The composite loss and curriculum are described at a high level without the exact weighting schedule or stage-transition criteria. Because these are the only free parameters identified, their omission prevents verification that convergence is robust rather than overfit to the RSBlur distribution.
minor comments (2)
- [Figure 2] Figure 2 (architecture diagram): The data-flow arrows between the Frequency Attention module and the E-Branchformer are not labeled with tensor dimensions, making it difficult to verify the claimed linear complexity.
- [Eq. (3)] Eq. (3) (Frequency loss): The notation for the FFT-based term is introduced without an explicit definition of the frequency weighting mask, which should be clarified for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§5] §5 (Experiments) and associated tables: No ablation studies isolate the contribution of the progressive curriculum stages or the individual terms in the composite loss. The headline 33.144 dB PSNR is therefore unattributed, leaving open whether the gain stems from the Frequency Attention module and E-Branchformer or from dataset-specific tuning of the free parameters (loss weights and curriculum schedule).
Authors: We agree that the current version lacks these ablations. In the revised manuscript we will add ablation studies in §5 isolating the progressive curriculum stages and each term of the composite loss to attribute the reported performance gains. revision: yes
-
Referee: [§5.1] §5.1 (Quantitative results): The manuscript states the RSBlur benchmark result and challenge ranking but supplies neither a comparison table against other NTIRE 2026 entries nor standard baselines (e.g., Restormer, NAFNet) with identical training protocols. This omission directly weakens the Pareto-frontier claim.
Authors: We acknowledge the omission. We will add a comparison table in the revised §5.1 that includes other NTIRE 2026 entries (where public) and standard baselines retrained under identical protocols on RSBlur to support the efficiency-quality claim. revision: yes
-
Referee: [§4.3] §4.3 (Training strategy): The composite loss and curriculum are described at a high level without the exact weighting schedule or stage-transition criteria. Because these are the only free parameters identified, their omission prevents verification that convergence is robust rather than overfit to the RSBlur distribution.
Authors: We will expand §4.3 in the revision to include the precise loss weights and stage-transition criteria, improving reproducibility and allowing verification of robust convergence. revision: yes
Circularity Check
No significant circularity; empirical performance claims are independent of inputs
full rationale
The paper describes a novel dual-domain architecture (Frequency Attention via FFT, Cross-Gated Vision E-Branchformer) plus a progressive curriculum with composite loss (Multi-Scale Charbonnier + Structural Edge + Frequency), then reports an empirical PSNR result on the RSBlur benchmark from the NTIRE 2026 challenge. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the provided text. The reported 33.144 dB PSNR at given parameter/GMAC counts is presented as an outcome of training and evaluation, not derived by construction from the architecture description itself. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- Composite loss weights
- Curriculum schedule parameters
axioms (2)
- domain assumption FFT-based Frequency Attention can explicitly recover high-frequency structural details from blurred images
- domain assumption Cross-Gated Vision E-Branchformer captures global dependencies at linear complexity
Reference graph
Works this paper leans on
-
[1]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer normalization, 2016. 3
2016
-
[2]
Charbonnier, L
P. Charbonnier, L. Blanc-Feraud, G. Aubert, and M. Bar- laud. Two deterministic half-quadratic regularization algo- rithms for computed imaging. InProceedings of 1st Inter- national Conference on Image Processing, pages 168–172 vol.2, 1994. 5
1994
-
[3]
Pre-trained image processing transformer
Hanting Chen, Yunhe Wang, Tianyu Guo, Chang Xu, Yip- ing Deng, Zhenhua Liu, Siwei Ma, Chunjing Xu, Chao Xu, and Wen Gao. Pre-trained image processing transformer. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), pages 12299–12310,
-
[4]
Hinet: Half instance normalization network for image restoration
Liangyu Chen, Xin Lu, Jie Zhang, Xiaojie Chu, and Cheng- peng Chen. Hinet: Half instance normalization network for image restoration. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR) Workshops, pages 182–192, 2021. 2
2021
-
[5]
Simple baselines for image restoration
Liangyu Chen, Xiaojie Chu, Xiangyu Zhang, and Jian Sun. Simple baselines for image restoration. InComputer Vision – ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part VII, page 17–33, Berlin, Heidelberg, 2022. Springer-Verlag. 1, 2, 3, 7, 8
2022
-
[6]
Fast fourier convolu- tion
Lu Chi, Borui Jiang, and Yadong Mu. Fast fourier convolu- tion. InAdvances in Neural Information Processing Systems, pages 4479–4488. Curran Associates, Inc., 2020. 2
2020
-
[7]
Rethinking coarse-to-fine approach in sin- gle image deblurring
Sung-Jin Cho, Seo-Won Ji, Jun-Pyo Hong, Seung-Won Jung, and Sung-Jea Ko. Rethinking coarse-to-fine approach in sin- gle image deblurring. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 4641–4650, 2021. 2, 8
2021
-
[8]
Selective frequency network for image restoration
Yuning Cui, Yi Tao, Zhenshan Bing, Wenqi Ren, Xinwei Gao, Xiaochun Cao, Kai Huang, and Alois Knoll. Selective frequency network for image restoration. InThe Eleventh In- ternational Conference on Learning Representations, 2023. 3
2023
-
[9]
Dauphin, Angela Fan, Michael Auli, and David Grangier
Yann N. Dauphin, Angela Fan, Michael Auli, and David Grangier. Language modeling with gated convolutional net- works. InProceedings of the 34th International Confer- ence on Machine Learning - Volume 70, page 933–941. JMLR.org, 2017. 3
2017
-
[10]
Repvgg: Making vgg-style convnets great again
Xiaohan Ding, Xiangyu Zhang, Ningning Ma, Jungong Han, Guiguang Ding, and Jian Sun. Repvgg: Making vgg-style convnets great again. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13733–13742, 2021. 2
2021
-
[11]
An image is worth 16x16 words: Transformers for image recognition at scale, 2021
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale, 2021. 1, 2
2021
-
[12]
Ef- ficient real-world deblurring using single images: Aim 2025 challenge report
Daniel Feijoo, Paula Garrido, Marcos V Conde, Jaesung Rim, Alvaro Garcia, Sunghyun Cho, and Radu Timofte. Ef- ficient real-world deblurring using single images: Aim 2025 challenge report. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 5713–5721,
2025
-
[13]
Gaussian error linear units (gelus), 2023
Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus), 2023. 4
2023
-
[14]
Xydeblur: Divide and conquer for single image deblur- ring
Seo-Won Ji, Jeongmin Lee, Seung-Wook Kim, Jun-Pyo Hong, Seung-Jin Baek, Seung-Won Jung, and Sung-Jea Ko. Xydeblur: Divide and conquer for single image deblur- ring. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 17421– 17430, 2022. 2
2022
-
[15]
Focal frequency loss for image reconstruction and synthesis
Liming Jiang, Bo Dai, Wayne Wu, and Chen Change Loy. Focal frequency loss for image reconstruction and synthesis. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 13919–13929, 2021. 2, 5
2021
-
[16]
Percep- tual losses for real-time style transfer and super-resolution
Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Percep- tual losses for real-time style transfer and super-resolution. InComputer Vision – ECCV 2016, pages 694–711, Cham,
2016
-
[17]
Springer International Publishing. 1
-
[18]
Han, and Shinji Watanabe
Kwangyoun Kim, Felix Wu, Yifan Peng, Jing Pan, Prashant Sridhar, Kyu J. Han, and Shinji Watanabe. E-branchformer: Branchformer with enhanced merging for speech recogni- tion. In2022 IEEE Spoken Language Technology Workshop (SLT), pages 84–91, 2023. 2, 4
2023
-
[19]
Efficient frequency domain-based trans- formers for high-quality image deblurring
Lingshun Kong, Jiangxin Dong, Jianjun Ge, Mingqiang Li, and Jinshan Pan. Efficient frequency domain-based trans- formers for high-quality image deblurring. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 5886–5895, 2023. 2
2023
-
[20]
Deblurgan: Blind motion deblurring using conditional adversarial networks
Orest Kupyn, V olodymyr Budzan, Mykola Mykhailych, Dmytro Mishkin, and Ji ˇr´ı Matas. Deblurgan: Blind motion deblurring using conditional adversarial networks. InPro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018. 1
2018
-
[21]
Deblurgan-v2: Deblurring (orders-of-magnitude) faster and better
Orest Kupyn, Tetiana Martyniuk, Junru Wu, and Zhangyang Wang. Deblurgan-v2: Deblurring (orders-of-magnitude) faster and better. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV), 2019. 8
2019
-
[22]
Ntire 2022 challenge on efficient super- resolution: Methods and results
Yawei Li et al. Ntire 2022 challenge on efficient super- resolution: Methods and results. In2022 IEEE/CVF Con- ference on Computer Vision and Pattern Recognition Work- shops (CVPRW), pages 1061–1101, 2022. 2
2022
-
[23]
Ntire 2023 challenge on image denoising: Methods and results
Yawei Li et al. Ntire 2023 challenge on image denoising: Methods and results. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR) Workshops, pages 1905–1921, 2023. 2
2023
-
[24]
Swinir: Image restoration us- ing swin transformer
Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, and Radu Timofte. Swinir: Image restoration us- ing swin transformer. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision (ICCV) Workshops, pages 1833–1844, 2021. 1
2021
-
[25]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 10012–10022, 2021. 4
2021
-
[26]
Sgdr: Stochastic gradient descent with warm restarts, 2017
Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradient descent with warm restarts, 2017. 6
2017
-
[27]
Decoupled weight decay regularization, 2019
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization, 2019. 6
2019
-
[28]
Intriguing findings of frequency selection for image deblurring.Proceedings of the AAAI Conference on Artificial Intelligence, 37(2):1905–1913, 2023
Xintian Mao, Yiming Liu, Fengze Liu, Qingli Li, Wei Shen, and Yan Wang. Intriguing findings of frequency selection for image deblurring.Proceedings of the AAAI Conference on Artificial Intelligence, 37(2):1905–1913, 2023. 2
1905
-
[29]
Marr and E
D. Marr and E. Hildreth. Theory of edge detection.Proceed- ings of the Royal Society of London. B. Biological Sciences, 207(1167):187–217, 1980. 5
1980
-
[30]
Exponential moving average of weights in deep learning: Dynamics and benefits.Transactions on Machine Learning Research, 2024
Daniel Morales-Brotons, Thijs V ogels, and Hadrien Hen- drikx. Exponential moving average of weights in deep learning: Dynamics and benefits.Transactions on Machine Learning Research, 2024. 5
2024
-
[31]
Deep multi-scale convolutional neural network for dynamic scene deblurring
Seungjun Nah, Tae Hyun Kim, and Kyoung Mu Lee. Deep multi-scale convolutional neural network for dynamic scene deblurring. InProceedings of the IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 3883– 3891, 2017. 1, 8
2017
-
[32]
Ntire 2021 challenge on image deblur- ring
Seungjun Nah et al. Ntire 2021 challenge on image deblur- ring. In2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 149– 165, 2021. 2
2021
-
[33]
Conformer: Local fea- tures coupling global representations for visual recognition
Zhiliang Peng, Wei Huang, Shanzhi Gu, Lingxi Xie, Yaowei Wang, Jianbin Jiao, and Qixiang Ye. Conformer: Local fea- tures coupling global representations for visual recognition. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 367–376, 2021. 2
2021
-
[34]
Real-world blur dataset for learning and benchmarking de- blurring algorithms
Jaesung Rim, Haeyun Lee, Jucheol Won, and Sunghyun Cho. Real-world blur dataset for learning and benchmarking de- blurring algorithms. InComputer Vision – ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXV, page 184–201, Berlin, Heidelberg,
2020
-
[35]
Springer-Verlag. 1, 7
-
[36]
Realistic blur synthesis for learning image deblurring
Jaesung Rim, Geonung Kim, Jungeon Kim, Junyong Lee, Seungyong Lee, and Sunghyun Cho. Realistic blur synthesis for learning image deblurring. InComputer Vision – ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part VII, page 487–503, Berlin, Heidelberg, 2022. Springer-Verlag. 5
2022
-
[37]
Mobilenetv2: Inverted residuals and linear bottlenecks
Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zh- moginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018. 2
2018
-
[38]
Aitken, Rob Bishop, Daniel Rueckert, and Zehan Wang
Wenzhe Shi, Jose Caballero, Ferenc Huszar, Johannes Totz, Andrew P. Aitken, Rob Bishop, Daniel Rueckert, and Zehan Wang. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016. 3
2016
-
[39]
Maitreya Suin, Kuldeep Purohit, and A. N. Rajagopalan. Spatially-attentive patch-hierarchical network for adaptive motion deblurring. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR),
-
[40]
Scale-recurrent network for deep image deblurring
Xin Tao, Hongyun Gao, Xiaoyong Shen, Jue Wang, and Ji- aya Jia. Scale-recurrent network for deep image deblurring. In2018 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 8174–8182, 2018. 8
2018
-
[41]
Stripformer: Strip transformer for fast image deblurring
Fu-Jen Tsai, Yan-Tsung Peng, Yen-Yu Lin, Chung-Chi Tsai, and Chia-Wen Lin. Stripformer: Strip transformer for¬†fast image deblurring. InComputer Vision – ECCV 2022, pages 146–162, Cham, 2022. Springer Nature Switzerland. 2
2022
-
[42]
Maxim: Multi-axis mlp for image processing
Zhengzhong Tu, Hossein Talebi, Han Zhang, Feng Yang, Peyman Milanfar, Alan Bovik, and Yinxiao Li. Maxim: Multi-axis mlp for image processing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5769–5780, 2022. 1
2022
-
[43]
Bovik, H.R
Zhou Wang, A.C. Bovik, H.R. Sheikh, and E.P. Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4): 600–612, 2004. 6
2004
-
[44]
Uformer: A general u-shaped transformer for image restoration
Zhendong Wang, Xiaodong Cun, Jianmin Bao, Wengang Zhou, Jianzhuang Liu, and Houqiang Li. Uformer: A general u-shaped transformer for image restoration. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 17683–17693, 2022. 2, 7, 8
2022
-
[45]
Fda: Fourier domain adaptation for semantic segmentation
Yanchao Yang and Stefano Soatto. Fda: Fourier domain adaptation for semantic segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020. 2
2020
-
[46]
Multi-stage progressive image restoration
Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, Ming-Hsuan Yang, and Ling Shao. Multi-stage progressive image restoration. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14821–14831, 2021. 2, 7, 8
2021
-
[47]
Restormer: Efficient transformer for high-resolution image restoration
Syed Waqas Zamir, Aditya Arora, Salman Khan, Mu- nawar Hayat, Fahad Shahbaz Khan, and Ming-Hsuan Yang. Restormer: Efficient transformer for high-resolution image restoration. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5728–5739, 2022. 1, 2, 4, 8
2022
-
[48]
Efros, Eli Shecht- man, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2018. 6
2018
-
[49]
Ntire 2024 challenge on bracketing image restoration and enhancement: Datasets methods and results
Zhilu Zhang et al. Ntire 2024 challenge on bracketing image restoration and enhancement: Datasets methods and results. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, pages 6153–6166, 2024. 2
2024
-
[50]
Deep fourier up-sampling
Man Zhou, Hu Yu, Jie Huang, Feng Zhao, Jinwei Gu, Chen Change Loy, Deyu Meng, and Chongyi Li. Deep fourier up-sampling. InAdvances in Neural Information Processing Systems, pages 22995–23008. Curran Associates, Inc., 2022. 3
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.