Graphical einops: bridging tensor networks and computation graphs
Pith reviewed 2026-06-28 22:57 UTC · model grok-4.3
The pith
A graphical calculus represents tensor axes as nested graded tubes so that architecture diagrams become formal proofs for einops identities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our calculus represents tensor axes as nested graded tubes around a base type. The tube boundary recovers the undirected tensor-network view of axes, while the directed interior retains the operational reading of computation graphs. The key rewrite is grade-naturality: sliding spectacles over tubes. Standard equivariance proofs become short diagrammatic derivations. We additionally demonstrate how our rewrite system may be applied to convert attention masks into pre-processing operations, recovering efficient implementations of sparse attention blocks.
What carries the argument
nested graded tubes around a base type, with grade-naturality (sliding spectacles over tubes) as the central rewrite rule
If this is right
- Equivariance proofs for einops operations reduce to short diagrammatic derivations using grade-naturality.
- Attention masks convert directly into pre-processing operations that yield efficient sparse attention implementations.
- Architecture diagrams shift from purely representational to proof-enabling for tensor-program identities.
- The undirected tensor-network and directed computation-graph views of axes become compatible within a single calculus.
Where Pith is reading between the lines
- The same tube representation might let researchers test whether new tensor rearrangements preserve equivariance before writing code.
- If the rewrite system is implemented, it could serve as a lightweight checker for identities that currently rely on manual axis tracking.
- Connections between tensor networks and computation graphs could extend to other structural tensor libraries that share the same axis-manipulation primitives.
Load-bearing premise
The structural fragment of tensor programming underlying einops admits a complete representation via nested graded tubes and grade-naturality suffices to reduce all relevant equivariance proofs to diagrammatic form without gaps or extra assumptions.
What would settle it
An equivariance identity expressible in einops whose shortest proof still requires tensor-axis prose or non-diagrammatic steps after all possible grade-naturality rewrites would show the calculus is incomplete.
Figures

read the original abstract
Architecture diagrams are ubiquitous in deep learning, but they are usually only representational: the tensor-program identities they suggest are still proved by prose and tensor-axis manipulation. We introduce a formal graphical calculus for the structural fragment of tensor programming underlying einops, making such diagrams proof-enabling. Our calculus represents tensor axes as nested graded tubes around a base type. The tube boundary recovers the undirected tensor-network view of axes, while the directed interior retains the operational reading of computation graphs. The key rewrite is grade-naturality: sliding spectacles over tubes. Standard equivariance proofs become short diagrammatic derivations. We additionally demonstrate how our rewrite system may be applied to convert attention masks into pre-processing operations, recovering efficient implementations of sparse attention blocks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a formal graphical calculus for the structural fragment of tensor programming underlying einops. Tensor axes are represented as nested graded tubes around a base type, recovering the undirected tensor-network view at the boundary while retaining the directed operational reading inside. The central rewrite rule is grade-naturality (sliding spectacles over tubes), which is claimed to turn standard equivariance proofs into short diagrammatic derivations. The calculus is additionally applied to convert attention masks into pre-processing operations, recovering efficient implementations of sparse attention blocks.
Significance. If the nested graded tube representation is complete for the relevant fragment and grade-naturality suffices for the claimed derivations without hidden assumptions, the work would provide a proof-enabling bridge between tensor-network diagrams and computation-graph reasoning. This could shorten equivariance arguments in deep-learning architecture papers and offer a systematic route to mask-to-preprocessing rewrites for attention. The absence of any machine-checked proofs or reproducible code in the manuscript means these strengths remain potential rather than demonstrated.
major comments (3)
- [Abstract] Abstract: the central claim that 'standard equivariance proofs become short diagrammatic derivations' is stated without any concrete before/after example, derivation length comparison, or reference to a specific equivariance statement. Without such an illustration the reduction in proof length cannot be evaluated.
- [Abstract] Abstract: the completeness assumption that 'the structural fragment of tensor programming underlying einops admits a complete representation via nested graded tubes' is asserted but not accompanied by a statement of the fragment's syntax, a soundness theorem, or a counter-example check. This is load-bearing for all subsequent claims.
- [Abstract] Abstract: the attention-mask application is described only at the level of 'recovering efficient implementations'; no rewrite sequence, complexity argument, or comparison to existing sparse-attention methods is supplied, leaving the practical utility unassessable.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback focused on the abstract. We address each major comment below and will revise the abstract to improve concreteness and assessability of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'standard equivariance proofs become short diagrammatic derivations' is stated without any concrete before/after example, derivation length comparison, or reference to a specific equivariance statement. Without such an illustration the reduction in proof length cannot be evaluated.
Authors: We agree that a concrete illustration would allow readers to evaluate the claim directly. In the revised abstract we will insert a short before/after example referencing a standard statement (head-permutation equivariance of multi-head attention), showing the length of the conventional prose argument versus the corresponding diagrammatic derivation. revision: yes
-
Referee: [Abstract] Abstract: the completeness assumption that 'the structural fragment of tensor programming underlying einops admits a complete representation via nested graded tubes' is asserted but not accompanied by a statement of the fragment's syntax, a soundness theorem, or a counter-example check. This is load-bearing for all subsequent claims.
Authors: The fragment comprises precisely the operations expressible via einops; its syntax is given in Section 2. The nested graded tube representation is complete for this fragment by construction. We will add a concise statement of the fragment together with a forward reference to the completeness argument in the revised abstract. A separate formal soundness theorem is not present in the manuscript. revision: partial
-
Referee: [Abstract] Abstract: the attention-mask application is described only at the level of 'recovering efficient implementations'; no rewrite sequence, complexity argument, or comparison to existing sparse-attention methods is supplied, leaving the practical utility unassessable.
Authors: We will expand the abstract to outline the mask-to-preprocessing rewrite at a high level and note the resulting complexity improvement (elimination of explicit masking inside the attention kernel). A detailed comparison with prior sparse-attention techniques remains outside the abstract's scope but is consistent with the manuscript's focus on the rewrite system. revision: yes
- The manuscript contains no machine-checked proofs or reproducible code; the referee correctly notes that this leaves the claimed strengths potential rather than demonstrated. We cannot supply these without substantial additional development beyond the present theoretical contribution.
Circularity Check
No significant circularity: new formal system introduced without self-referential reductions
full rationale
The paper presents a newly introduced graphical calculus for the structural fragment of tensor programming, representing axes as nested graded tubes with grade-naturality as the central rewrite rule. No load-bearing step reduces by construction to fitted parameters, self-citations, or prior results from the same authors; the abstract and description frame the system as a formal innovation whose completeness is posited as an assumption rather than derived from its own outputs. The derivation chain is self-contained as an axiomatic presentation of a diagrammatic language, with no evidence of renaming known results, smuggling ansatzes via citation, or uniqueness theorems imported from overlapping authorship. This matches the default expectation of no circularity for papers that define new formalisms outright.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Iz Beltagy, Matthew E
Open-source library https://github.com/thomasahle/tensorgrad and textbook draft https://tensorcookbook.com/. Iz Beltagy, Matthew E. Peters, and Arman Cohan. Longformer: The long-document transformer,
-
[2]
Longformer: The Long-Document Transformer
arXiv:2004.05150. David Chiang, Alexander M. Rush, and Boaz Barak. Named tensor notation, 2023. arXiv:2102.13196. Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers, 2019. arXiv:1904.10509. Bob Coecke and Ross Duncan. Interacting quantum observables: Categorical algebra and diagram- matics, 2011. ...
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[3]
Transformer language models without positional encodings still learn positional information
Technical report; sliding window 1024, 5:1 sliding/full alternation. Adi Haviv, Ori Ram, Ofir Press, Peter Izsak, and Omer Levy. Transformer language models without positional encodings still learn positional information. InFindings of the Association for Computational Linguistics (EMNLP), pages 1382–1390, 2022. arXiv:2203.16634. Albert Q. Jiang, Alexandr...
-
[4]
arXiv:2107.02027v3 (companion blog post). Mario Michael Krell, Matej Kosec, Sergio P. Perez, and Andrew Fitzgibbon. Efficient sequence packing without cross-contamination: Accelerating large language models without impacting performance, 2021. arXiv:2107.02027. Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonza...
-
[5]
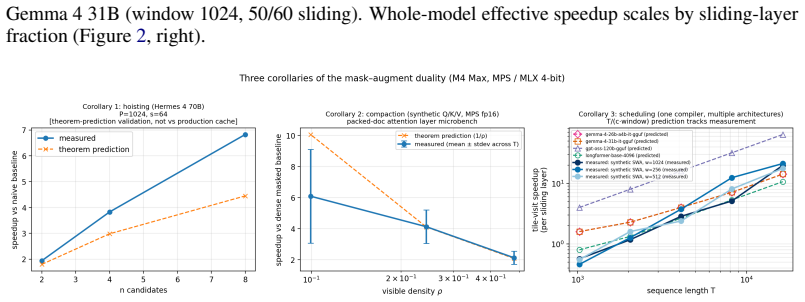
This is a standard trick used to implement masked self-attention. 21 E Mask-augment duality: Comparison with code Below we repeat the eleven frames of the derivation, each paired with the correspondingforward function, implemented in torch + einops . The code transcription proves the same identity without diagrams. Its length is the point: the graphical p...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.