A Multi-AI-agent Framework Enabling End-to-end Finite Element Analysis for Solid Mechanics Problems
Pith reviewed 2026-06-29 06:36 UTC · model grok-4.3
The pith
A six-agent LLM framework called AbaqusAgent converts natural-language instructions into executed Abaqus finite element analyses for solid mechanics problems at 86 percent success on 50 cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
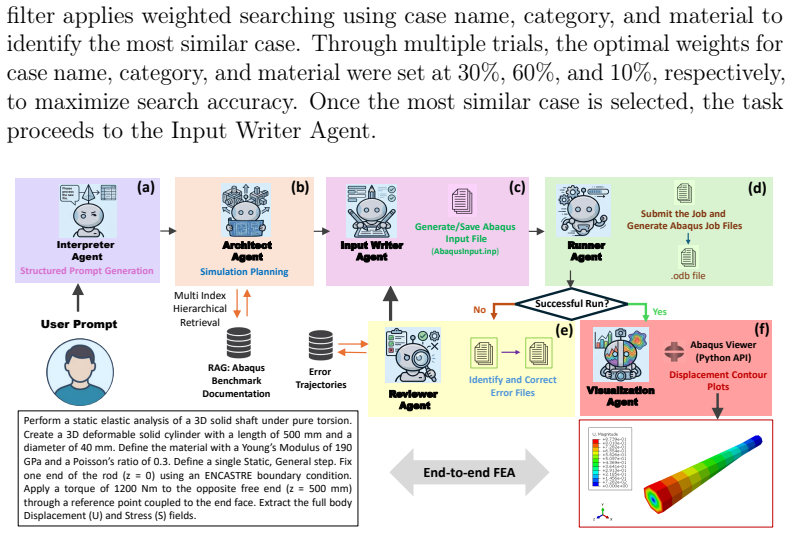
AbaqusAgent, built from six LLM agents (interpreter, architect, input writer, runner, reviewer, and visualizer), successfully generates and executes Abaqus FEA analyses for a wide variety of solid mechanics problems, achieving an overall success rate of 86 percent on 50 validated cases while encompassing all essential pre-processing and post-processing steps.
What carries the argument
AbaqusAgent, a multi-agent framework of six LLM agents that together convert natural-language instructions into complete, executed Abaqus FEA analyses and visualizations.
If this is right
- FEA for solid mechanics becomes faster and requires less specialized training.
- The system lowers the barrier for computational mechanics education.
- Human-simulation interaction shifts toward natural language inputs.
- The framework can integrate with AI-driven optimization and material characterization workflows.
Where Pith is reading between the lines
- The same agent structure could be adapted to other commercial FEA packages beyond Abaqus.
- Extending validation to dynamic or nonlinear problems would test whether success rates remain high.
- The approach may enable automated sensitivity studies by repeatedly generating and running variants of a base model.
Load-bearing premise
LLM-generated Abaqus input files and post-processing steps will produce physically correct results for problems not covered in the 50-case validation set without systematic human review.
What would settle it
Expert review of Abaqus models generated by the system on a new solid mechanics problem outside the original 50 cases reveals incorrect boundary conditions, loads, or solution variables that produce non-physical results.
Figures

read the original abstract
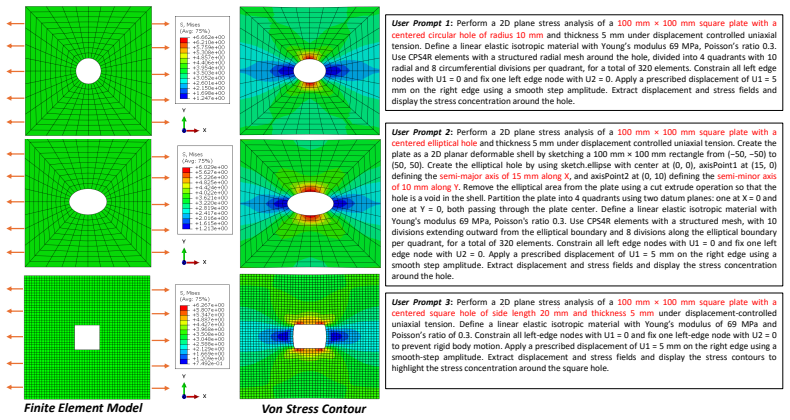
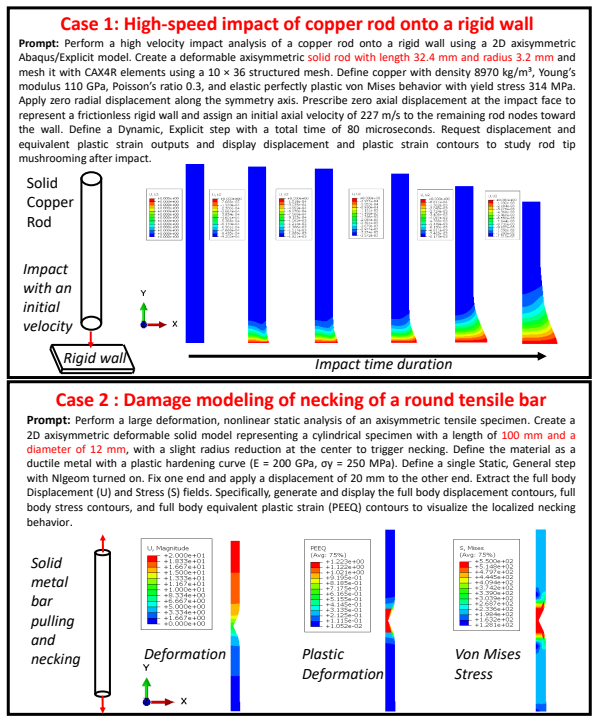
Finite element analysis (FEA) is the most important numerical approach for solid mechanics. Challenges of FEA include a steep learning curve for entry-level users and potential false simulations due to incorrect definitions of key simulation components, such as boundary conditions, load cases, and solution variables. Years of engineering experience are usually necessary for real-world problem-solving. To address these issues, we present AbaqusAgent, a multi-agent framework grounded in large language models (LLMs) for solid mechanics analyses. AbaqusAgent is developed to facilitate analysis case generation and execution using Abaqus, one of the most widely used FEA packages, by turning users' natural-language instructions into executed FEA analyses and result visualization. AbaqusAgent is composed of six agents, including interpreter, architect, input writer, runner, reviewer, and visualizer agents, encompassing all the essential pre-processing and post-processing steps of standard FEA analyses. A wide variety of 50 solid mechanics problems have been successfully validated, achieving an overall success rate of 86%. Beyond improving the efficiency of FEA for solid mechanics problems and lowering the barrier to computational mechanics education, AbaqusAgent advances the human-simulation interaction paradigm and enables integration with AI-empowered optimization and material characterization workflows. The code is available at https://github.com/LIRAM-LIN/AbaqusAgent
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents AbaqusAgent, a multi-LLM-agent framework with six specialized agents (interpreter, architect, input writer, runner, reviewer, visualizer) that converts natural-language instructions into complete, executed Abaqus finite-element analyses for solid mechanics, including pre- and post-processing steps. It reports an overall success rate of 86% on 50 validated cases and releases the code at the cited GitHub repository.
Significance. If the validation protocol can be shown to confirm physical fidelity rather than merely syntactic executability, the work would lower the barrier to computational mechanics education and enable AI-driven optimization and material-characterization pipelines. The open-source release is a clear strength supporting reproducibility.
major comments (2)
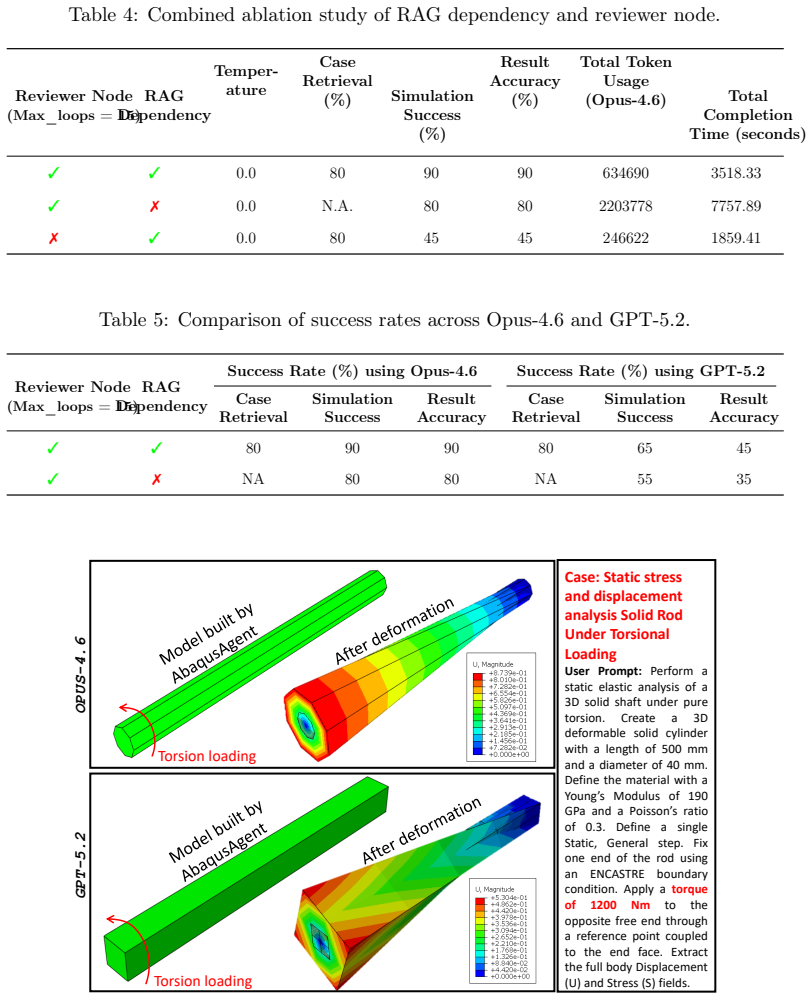
- [Abstract] Abstract: the central empirical claim of an 86% success rate on 50 cases supplies no definition of success (solver exit code 0, absence of warnings, or quantitative agreement with analytical/experimental benchmarks). Because the reviewer agent is itself LLM-based, this omission prevents verification that generated models are physically faithful rather than merely runnable.
- [Results / Validation] Validation protocol (implicit in the results description): no per-problem-type breakdown, no error analysis of the 14% failures, and no baseline comparison (single-LLM prompting or scripted templates) is reported. These omissions are load-bearing for the claim that the six-agent architecture enables reliable end-to-end FEA.
minor comments (1)
- [Abstract] The abstract states that the framework 'advances the human-simulation interaction paradigm' without citing prior work on LLM-assisted simulation interfaces; a brief related-work paragraph would clarify novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the validation aspects of our work. We respond point by point below and indicate revisions where the manuscript will be updated.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim of an 86% success rate on 50 cases supplies no definition of success (solver exit code 0, absence of warnings, or quantitative agreement with analytical/experimental benchmarks). Because the reviewer agent is itself LLM-based, this omission prevents verification that generated models are physically faithful rather than merely runnable.
Authors: We agree that the definition of success must be stated explicitly. Success in our evaluation is defined as the Abaqus job completing with exit code 0 (no solver errors) as reported by the runner agent, together with the reviewer agent confirming that the model setup matches the natural-language problem description. We acknowledge that LLM-based review does not guarantee quantitative physical fidelity against analytical or experimental benchmarks. We will revise the abstract and methods section to include this definition and note the limitation regarding physical validation. revision: yes
-
Referee: [Results / Validation] Validation protocol (implicit in the results description): no per-problem-type breakdown, no error analysis of the 14% failures, and no baseline comparison (single-LLM prompting or scripted templates) is reported. These omissions are load-bearing for the claim that the six-agent architecture enables reliable end-to-end FEA.
Authors: We will add a table in the results section providing success rates broken down by problem category (e.g., linear elasticity, nonlinear material behavior, contact). We will also include a brief error analysis of the seven failure cases, classifying issues such as incorrect boundary conditions or convergence failures. Baseline comparisons against single-LLM prompting or template methods were not performed in this study; we will note this as a limitation and identify it as future work, but cannot supply such data without new experiments. revision: partial
- Providing quantitative baseline comparisons (single-LLM or scripted templates), which would require new experimental runs not available in the current study.
Circularity Check
No circularity: empirical software framework with external case validation
full rationale
The paper describes a multi-LLM-agent system for generating and running Abaqus FEA analyses, reporting an 86% success rate on 50 validated cases. No mathematical derivations, equations, fitted parameters, or uniqueness theorems appear in the provided text. The central claim rests on empirical execution outcomes rather than any self-referential reduction of a prediction to its inputs or load-bearing self-citations. The validation protocol, while potentially underspecified for physical accuracy, does not create a definitional loop by construction. This is a standard non-circular empirical software paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can reliably generate correct Abaqus input syntax and interpret simulation outputs when given appropriate role prompts.
invented entities (6)
-
Interpreter agent
no independent evidence
-
Architect agent
no independent evidence
-
Input writer agent
no independent evidence
-
Runner agent
no independent evidence
-
Reviewer agent
no independent evidence
-
Visualizer agent
no independent evidence
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
L. Yue, P. Xu, T. Zhang, N. Somasekharan, S. Pan, Foamgpt: Fine- tuning large language model for agentic automation of cfd simulations with openfoam, San Diego, CA (2025)
2025
-
[4]
Z. Dong, Z. Lu, Y. Yang, Fine-tuning a large language model for au- tomating computational fluid dynamics simulations, Theoretical and Applied Mechanics Letters 15 (3) (2025) 100594
2025
-
[5]
Y. Qu, K. Huang, M. Yin, K. Zhan, D. Liu, D. Yin, H. C. Cousins, W. A. Johnson, X. Wang, M. Shah, et al., Crispr-gpt for agentic automation of gene-editing experiments, Nature Biomedical Engineering 10 (2) (2026) 245–258
2026
- [6]
-
[7]
Y. Ruan, C. Lu, N. Xu, Y. He, Y. Chen, J. Zhang, J. Xuan, J. Pan, Q. Fang, H. Gao, et al., An automatic end-to-end chemical synthe- sis development platform powered by large language models, Nature communications 15 (1) (2024) 10160
2024
-
[8]
Y. Zou, A. H. Cheng, A. Aldossary, J. Bai, S. X. Leong, J. A. Campos- Gonzalez-Angulo, C. Choi, C. T. Ser, G. Tom, A. Wang, et al., El agente: An autonomous agent for quantum chemistry, Matter 8 (7) (2025). 19
2025
-
[9]
Ghosh, A
S. Ghosh, A. Tewari, Llm-based ai agents for automated extraction of material properties and structural features, Computational Materials Science 265 (2026) 114521
2026
-
[10]
Jalali, Y
M. Jalali, Y. Luo, L. Caulfield, E. Sauter, A. Nefedov, C. Wöll, Large language models in electronic laboratory notebooks: Transforming ma- terials science research workflows, Materials Today Communications 40 (2024) 109801
2024
-
[11]
K. M. Jablonka, Q. Ai, A. Al-Feghali, S. Badhwar, J. D. Bocarsly, A. M. Bran, S. Bringuier, L. C. Brinson, K. Choudhary, D. Circi, et al., 14 examples of how llms can transform materials science and chemistry: a reflection on a large language model hackathon, Digital discovery 2 (5) (2023) 1233–1250
2023
-
[12]
S. Gao, A. Fang, Y. Huang, V. Giunchiglia, A. Noori, J. R. Schwarz, Y. Ektefaie, J. Kondic, M. Zitnik, Empowering biomedical discovery with ai agents, Cell 187 (22) (2024) 6125–6151
2024
-
[13]
C. Lu, C. Lu, R. T. Lange, Y. Yamada, S. Hu, J. Foerster, D. Ha, J. Clune, Towards end-to-end automation of ai research, Nature 651 (8107) (2026) 914–919
2026
-
[14]
D. A. Boiko, R. MacKnight, B. Kline, G. Gomes, Autonomous chemical research with large language models, Nature 624 (7992) (2023) 570–578
2023
-
[15]
J. Ji, R. Lei, X. Pan, Z. Wei, H. Sun, Y. Lin, X. Chen, Y. Yang, Y. Li, B. Ding, et al., Leveraging llm-based agents for social science research: insights from citation network simulations, Humanities and Social Sciences Communications (2026)
2026
-
[16]
M. J. Turner, R. W. Clough, H. C. Martin, L. Topp, Stiffness and deflection analysis of complex structures, Journal of the Aeronautical Sciences 23 (9) (1956) 805–823
1956
-
[17]
Plevris, G
V. Plevris, G. Markeset, Educational challenges in computer-based finite element analysis and design of structures (2018)
2018
-
[18]
W. R. Johnson, X.-K. Zhu, R. Sindelar, B. Wiersma, A parametric finite element study for determining burst strength of thin and thick-walled 20 pressure vessels, International Journal of Pressure Vessels and Piping 204 (2023) 104968
2023
-
[19]
Z. H. Zuo, Y. M. Xie, A simple and compact python code for complex 3d topology optimization, Advances in Engineering Software 85 (2015) 1–11
2015
-
[20]
Y. Lim, S. Ha, Rufgen: A plug-in for rough surface generation in abaqus/cae, SoftwareX 22 (2023) 101380
2023
-
[21]
Riaño, Y
L. Riaño, Y. Joliff, An abaqus™plug-in for the geometry generation of representative volume elements with randomly distributed fibers and interphases, Composite Structures 209 (2019) 644–651
2019
-
[22]
S. L. Omairey, P. D. Dunning, S. Sriramula, Development of an abaqus plugin tool for periodic rve homogenisation, Engineering with Computers 35 (2) (2019) 567–577
2019
-
[23]
S. Lin, A. M. Waas, Accelerating computational analyses of low velocity impact and compression after impact of laminated composite materials, Composite Structures 260 (2021) 113456
2021
-
[24]
S. Lin, A. M. Waas, The effect of stacking sequence on the lvi damage of laminated composites; experiments and analysis, Composites Part A: Applied Science and Manufacturing 145 (2021) 106377
2021
-
[25]
Lin, Himex: A hybrid implicit-explicit analysis platform for progressive damage modeling of composite materials, in: AIAA SCITECH 2025 Forum, 2025, p
S. Lin, Himex: A hybrid implicit-explicit analysis platform for progressive damage modeling of composite materials, in: AIAA SCITECH 2025 Forum, 2025, p. 1598
2025
-
[26]
Dhondt, Calculix crunchix user’s manual version 2.12, Munich, Ger- many, accessed Sept 21 (2017) 2017
G. Dhondt, Calculix crunchix user’s manual version 2.12, Munich, Ger- many, accessed Sept 21 (2017) 2017
2017
-
[27]
S. Hou, R. Johnson, R. Makhija, L. Chen, Y. Ye, Autofea: Enhancing ai copilot by integrating finite element analysis using large language models with graph neural networks, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 39, 2025, pp. 24078–24085
2025
-
[28]
M. Yu, Y. Sheng, Z. Wan, S. Yang, M. Sun, H. Cai, An intelligent interactive system based on llm to combine cad api development with fea, in: 2024 8th International Conference on Electrical, Mechanical and Computer Engineering (ICEMCE), IEEE, 2024, pp. 1749–1755. 21
2024
-
[29]
Z. Li, H. Ge, G. Tang, Y. Liu, Modsolagent: Automated finite element code generation for abaqus via llm-based agent, IEEE Transactions on Industrial Informatics (2026)
2026
- [30]
-
[31]
C. J. Permann, D. R. Gaston, D. Andrš, R. W. Carlsen, F. Kong, A. D. Lindsay, J. M. Miller, J. W. Peterson, A. E. Slaughter, R. H. Stogner, et al., Moose: Enabling massively parallel multiphysics simulation, Soft- wareX 11 (2020) 100430
2020
- [32]
-
[33]
J. Guo, C. Park, D. Qian, T. J. Hughes, W. K. Liu, Large language model-empowered next-generation computer-aided engineering, Com- puter Methods in Applied Mechanics and Engineering 450 (2026) 118591
2026
-
[34]
B. Ni, M. J. Buehler, Mechagents: Large language model multi-agent collaborations can solve mechanics problems, generate new data, and integrate knowledge, Extreme Mechanics Letters 67 (2024) 102131
2024
- [35]
-
[36]
Q. Wu, G. Bansal, J. Zhang, Y. Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liu, et al., Autogen: Enabling next-gen llm applications via multi-agent conversations, in: First conference on language modeling, 2024
2024
-
[37]
Deotale, A
R. Deotale, A. Srinivasan, Y. Tian, T. Zhang, P. Vlachos, H. Gomez, All-fem: Agentic large language models fine-tuned for finite element methods, Available at SSRN 6103826 (2026)
2026
-
[38]
Douze, A
M. Douze, A. Guzhva, C. Deng, J. Johnson, G. Szilvasy, P.-E. Mazaré, M. Lomeli, L. Hosseini, H. Jégou, The faiss library, IEEE Transactions on Big Data (2025). 22
2025
-
[39]
Alnæs, J
M. Alnæs, J. Blechta, J. Hake, A. Johansson, B. Kehlet, A. Logg, C. Richardson, J. Ring, M. E. Rognes, G. N. Wells, The fenics project version 1.5, Archive of numerical software 3 (100) (2015)
2015
-
[40]
A. S. U. Manual, Abaqus 6.11, http://130.149 89 (2080) (2012) v6
2080
-
[41]
Iannitti, N
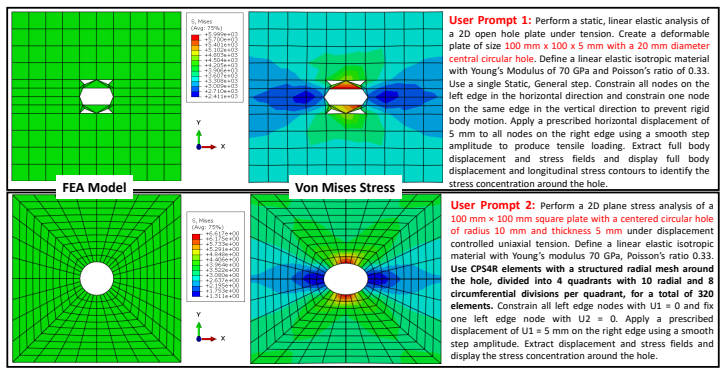
G. Iannitti, N. Bonora, A. Ruggiero, G. Testa, Ductile damage in taylor- anvil and rod-on-rod impact experiment, in: Journal of Physics: Confer- ence Series, Vol. 500, 2014, p. 112035. 23 Appendix A. ValidationandExtendedCapabilitiesofAbaqusAgent Appendix A.1. Validation Against Analytical Benchmark The physical correctness of AbaqusAgent-generated models...
2014
-
[42]
Rewrite the user's raw request into a clear, professional Abaqus-style,→ engineering prompt
-
[43]
Check whether these 5 required items are present: - geometry - material properties - boundary conditions - loading conditions - requested output Rules:
-
[44]
Preserve the user's original technical intent
-
[45]
Rewrite the request using proper Abaqus and finite element analysis,→ terminology
-
[46]
Improve clarity, grammar, and structure
-
[47]
rewritten_prompt
Do not invent numerical values or technical details that the user,→ did not provide. ... Return output strictly in this JSON format: { "rewritten_prompt": "string", "missing_items": [ "list of missing items from: geometry, material properties, boundary conditions, loading conditions, requested output" ] } """ 28 User Prompt — Example Raw Input Perform a s...
-
[48]
Read and understand the user requirement
-
[49]
</input_file>.,→
Read and analyze the reference input_file inside <input_file> ... </input_file>.,→
-
[50]
Identify from the reference file: - geometry structure - part definition - node and element organization - sets (nsets and elsets) - section definitions - material structure - assembly and instance structure - step structure - output structure
-
[51]
Identify from the user requirement: - intended physical behavior (bending, tension, compression, buckling, etc.),→ - correct loading type and direction - correct boundary conditions - required geometry and dimensions - correct element formulation if implied
-
[52]
Separate clearly: - Physics→MUST come from user requirement 31 - Syntax and structure --> may come from reference file,→
-
[53]
Modify ONLY what is required to satisfy the user requirement.,→
-
[54]
Generate a complete and runnable Abaqus input_file file.,→ ================================== PHYSICS PRIORITY RULE (CRITICAL) ================================== The user requirement ALWAYS overrides the retrieved reference case.,→ If there is any conflict between the user requirement and the reference case:,→ - Use the user requirement for: - load type -...
-
[55]
*PART - *NODE - *ELEMENT - *NSET / *ELSET - *SECTION
-
[56]
*ASSEMBLY - *INSTANCE - *END INSTANCE
-
[57]
*STEP - procedure (*STATIC, *DYNAMIC, etc.) - *BOUNDARY - loads (*CLOAD, *DLOAD, *DSLOAD) - *OUTPUT - *NODE OUTPUT - *ELEMENT OUTPUT
-
[58]
"" User Prompt — Abaqus Input File Generator user_prompt = ( f
*END STEP 34 ======================== BLOCK VALIDATION RULES ======================== - Every opened block MUST be closed: *PART→*END PART *INSTANCE→*END INSTANCE *ASSEMBLY→*END ASSEMBLY *STEP→*END STEP ================= PLACEMENT RULES ================= - Sections MUST be inside *PART - *BOUNDARY MUST be inside *STEP - All loads MUST be inside *STEP - Ou...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.