One Channel to Rule Them All: Rethinking Input Representation for Visual Place Recognition
Pith reviewed 2026-06-28 17:51 UTC · model grok-4.3
The pith
Grayscale input matches or exceeds RGB performance for visual place recognition across benchmarks with appearance variation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
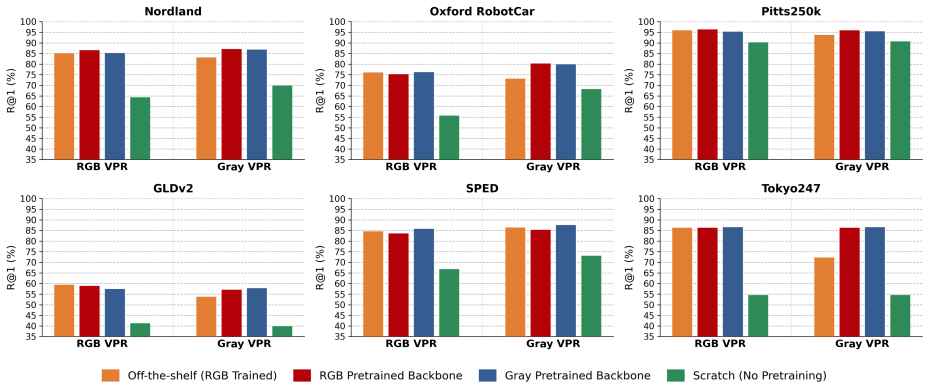
For global visual place recognition under real-world appearance changes, chromatic information contributes minimally and grayscale input alone is sufficient, as a gray-trained MixVPR model achieves 82.4 percent average Recall@1 versus 81.2 percent for the RGB counterpart, with color providing gains only in cases of persistent and discriminative chromatic cues.
What carries the argument
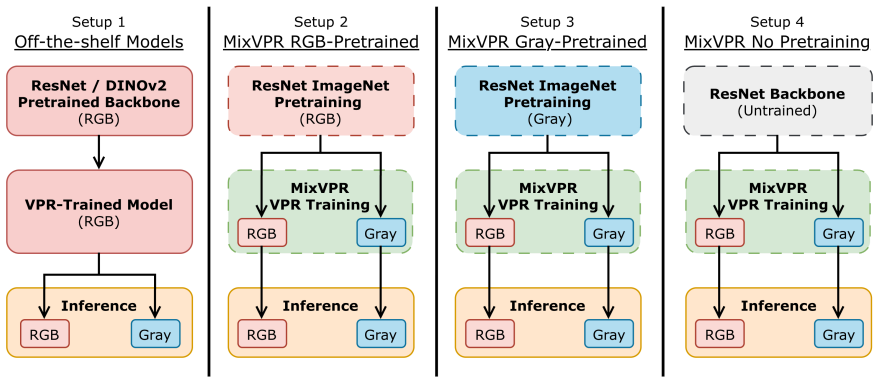
Direct comparison of single-channel grayscale versus three-channel RGB input representations during training and inference in models such as MixVPR for VPR tasks.
If this is right
- Grayscale models reach comparable or higher recall rates than RGB on standard VPR benchmarks.
- Lightweight grayscale variants using 60 percent fewer parameters can outperform heavier RGB models in some cases.
- Grayscale offers direct reductions in storage, bandwidth, and compute for resource-limited robotic systems.
- Color input yields meaningful improvements only when persistent and unique chromatic features are present in the scenes.
Where Pith is reading between the lines
- Robot localization pipelines could drop color cameras without loss of reliability in most outdoor or long-term settings.
- Existing RGB-trained VPR models might gain robustness by fine-tuning or retraining on grayscale versions of the same data.
- The finding may extend to other appearance-invariant vision tasks such as loop closure in SLAM where color is not the primary cue.
Load-bearing premise
The chosen benchmarks and training setups reflect conditions where RGB models have not fully learned color invariance, so any performance edge for grayscale can be traced mainly to the removal of color channels.
What would settle it
A new benchmark dataset containing scenes with persistent, highly discriminative color patterns across all tested variations where RGB models then show clearly higher Recall@1 than equivalent grayscale models.
Figures

read the original abstract
Visual Place Recognition (VPR) is fundamental to long-term robot localization and SLAM, yet current systems overwhelmingly rely on RGB input, implicitly assuming color is necessary for global place recognition. We challenge this assumption, investigating the role of chromatic information across training regimes, model architectures and standard benchmarks under real-world appearance variation. We find that grayscale matches RGB performance generally and outperforms it under severe appearance shifts where color invariance is insufficiently learned, while color provides meaningful gains only where persistent and discriminative chromatic cues are present. Across selected benchmarks, a fully gray-trained MixVPR model achieves an average 82.4% Recall@1 compared to 81.2% for its RGB counterpart. In some cases, lightweight grayscale variants with 60% fewer parameters can outperform heavier RGB models. Grayscale further offers practical advantages in storage, bandwidth and alignment with resource-constrained systems. We conclude that for global VPR where scenes vary across illumination, weather, season and setting, color contributes minimally, and grayscale alone is sufficient for reliable place recognition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper challenges the assumption that RGB input is necessary for Visual Place Recognition (VPR) by systematically comparing grayscale and RGB training regimes across model architectures (including MixVPR) and standard benchmarks under real-world appearance changes. It reports that a fully gray-trained MixVPR achieves 82.4% average Recall@1 versus 81.2% for its RGB counterpart, with grayscale matching or outperforming RGB in most cases (especially under severe shifts) and providing gains only where persistent chromatic cues exist; it further notes practical benefits of grayscale for storage, bandwidth, and lightweight variants.
Significance. If the central empirical comparison holds after controlling for training details, the result would meaningfully shift VPR practice toward grayscale inputs for global descriptors, reducing model size and resource demands while maintaining reliability across illumination, weather, and seasonal variation. The work is credited for its direct Recall@1 measurements across multiple regimes and benchmarks rather than parameter-fitted quantities, and for highlighting cases where color invariance is insufficiently learned by RGB models.
major comments (1)
- [Experiments] Experiments section (and abstract): the 1.2% Recall@1 gap between fully gray-trained MixVPR (82.4%) and RGB (81.2%) cannot be attributed solely to chromatic information without explicit confirmation that the two models differed only in input channels. The manuscript must report whether (a) identical hyperparameters, optimizer state, data order, and benchmark splits were used, (b) the RGB model received color-jitter or other invariance augmentations, and (c) the first convolutional layer was initialized identically (e.g., via channel averaging of ImageNet weights). Any mismatch would render the comparison non-diagnostic for the role of color.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The central concern regarding experimental controls is addressed below; we will revise the manuscript to make the comparison fully transparent.
read point-by-point responses
-
Referee: [Experiments] Experiments section (and abstract): the 1.2% Recall@1 gap between fully gray-trained MixVPR (82.4%) and RGB (81.2%) cannot be attributed solely to chromatic information without explicit confirmation that the two models differed only in input channels. The manuscript must report whether (a) identical hyperparameters, optimizer state, data order, and benchmark splits were used, (b) the RGB model received color-jitter or other invariance augmentations, and (c) the first convolutional layer was initialized identically (e.g., via channel averaging of ImageNet weights). Any mismatch would render the comparison non-diagnostic for the role of color.
Authors: We agree that the comparison is only diagnostic if all factors other than input channels are controlled. (a) Identical hyperparameters, optimizer, random seeds, data order, and benchmark splits were used for the grayscale and RGB MixVPR models; training was performed in the same codebase with the sole difference being the number of input channels. (b) No color-jitter or other chromatic augmentations were applied to the RGB model; both regimes used identical geometric and intensity augmentations. (c) The grayscale first convolutional layer was initialized by averaging the three RGB channels of the ImageNet-pretrained weights. We will add an explicit subsection in the revised Experiments section documenting these controls and will update the abstract to reference the controlled nature of the comparison. revision: yes
Circularity Check
No circularity: purely empirical comparison of input representations
full rationale
The paper reports direct experimental measurements of Recall@1 on standard VPR benchmarks for RGB-trained vs. grayscale-trained MixVPR models. No derivation chain, fitted parameters renamed as predictions, self-citation load-bearing uniqueness theorems, or ansatzes are present. The 82.4% vs 81.2% figures are raw performance metrics, not quantities defined in terms of themselves or prior self-citations. The central claim rests on benchmark results rather than any reduction to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Eigenplaces: Training viewpoint robust models for visual place recognition,
G. Berton, G. Trivigno, B. Caputo, and C. Masone, “Eigenplaces: Training viewpoint robust models for visual place recognition,” in2023 IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 11 046–11 056
2023
-
[2]
Rethinking visual geo- localization for large-scale applications,
G. Berton, C. Masone, and B. Caputo, “Rethinking visual geo- localization for large-scale applications,” in2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 4868– 4878
2022
-
[3]
Netvlad: Cnn architecture for weakly supervised place recognition,
R. Arandjelovic, P. Gronat, A. Torii, T. Pajdla, and J. Sivic, “Netvlad: Cnn architecture for weakly supervised place recognition,” in2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 5297–5307
2016
-
[4]
Mixvpr: Feature mixing for visual place recognition,
A. Ali-Bey, B. Chaib-Draa, and P. Gigu ´ere, “Mixvpr: Feature mixing for visual place recognition,” in2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2023, pp. 2997–3006
2023
-
[5]
Cricavpr: Cross-image correlation-aware representation learning for visual place recognition,
F. Lu, X. Lan, L. Zhang, D. Jiang, Y . Wang, and C. Yuan, “Cricavpr: Cross-image correlation-aware representation learning for visual place recognition,” in2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 16 772–16 782
2024
-
[6]
Megaloc: One retrieval to place them all,
G. Berton and C. Masone, “Megaloc: One retrieval to place them all,” in2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2025, pp. 2852–2858
2025
-
[7]
Gsv-cities: Toward appropri- ate supervised visual place recognition,
A. Ali-bey, B. Chaib-draa, and P. Gigu `ere, “Gsv-cities: Toward appropri- ate supervised visual place recognition,”Neurocomput., vol. 513, no. C, p. 194–203, Nov. 2022
2022
-
[8]
Visual place recognition with repetitive structures,
A. Torii, J. Sivic, T. Pajdla, and M. Okutomi, “Visual place recognition with repetitive structures,” in2013 IEEE Conference on Computer Vision and Pattern Recognition, 2013, pp. 883–890
2013
-
[9]
City-scale landmark identification on mobile de- vices,
D. M. Chen, G. Baatz, K. K ¨oser, S. S. Tsai, R. Vedantham, T. Pylv¨an¨ainen, K. Roimela, X. Chen, J. Bach, M. Pollefeys, B. Girod, and R. Grzeszczuk, “City-scale landmark identification on mobile de- vices,” inCVPR 2011, 2011, pp. 737–744
2011
-
[10]
Assessing the importance of colours for cnns in object recognition,
A. Singh, A. Bay, and A. Mirabile, “Assessing the importance of colours for cnns in object recognition,” inNeurIPS 2020 Workshop on Shared Visual Representations in Human and Machine Intelligence (SVRHM), 2020
2020
-
[11]
Impact of early visual experience on later usage of color cues,
M. V ogelsang, L. V ogelsang, P. Gupta, T. K. Gandhi, P. Shah, P. Swami, S. Gilad-Gutnick, S. Ben-Ami, S. Diamond, S. Ganesh, and P. Sinha, “Impact of early visual experience on later usage of color cues,”Science, vol. 384, no. 6698, pp. 907–912, 2024
2024
-
[12]
The role of color information on object recognition: A review and meta-analysis,
I. Bram ˜ao, A. Reis, K. M. Petersson, and L. Fa ´ısca, “The role of color information on object recognition: A review and meta-analysis,”Acta Psychologica, vol. 138, no. 1, pp. 244–253, 2011
2011
-
[13]
Colour blindness adversely impacts face recognition,
P. Brosseau, A. Nestor, and M. Behrmann, “Colour blindness adversely impacts face recognition,”Visual Cognition, vol. 28, no. 4, pp. 279–284, 2020
2020
-
[14]
Color improves edge classification in human vision,
C. Breuil, B. J. Jennings, S. Barthelm ´e, N. Guyader, and F. A. A. Kingdom, “Color improves edge classification in human vision,”PLOS Computational Biology, vol. 15, no. 10, pp. 1–15, 10 2019
2019
-
[15]
What’s color got to do with it? face recognition in grayscale,
A. Bhatta, D. Mery, H. Wu, J. Annan, M. C. King, and K. W. Bowyer, “What’s color got to do with it? face recognition in grayscale,”IEEE Transactions on Biometrics, Behavior, and Identity Science, vol. 7, no. 3, pp. 484–497, 2025
2025
-
[16]
Evaluating the impact of color information in deep neural networks,
V . Buhrmester, D. M ¨unch, D. Bulatov, and M. Arens, “Evaluating the impact of color information in deep neural networks,” inPattern Recognition and Image Analysis, A. Morales, J. Fierrez, J. S. S ´anchez, and B. Ribeiro, Eds. Cham: Springer International Publishing, 2019, pp. 302–316
2019
-
[17]
Color aids late but not early stages of rapid natural scene recognition,
A. Y . J. Yao and W. Einh ¨auser, “Color aids late but not early stages of rapid natural scene recognition,”Journal of Vision, vol. 8, no. 16, pp. 12–12, 12 2008
2008
-
[18]
Ultra-rapid categorisa- tion of natural scenes does not rely on colour cues: a study in monkeys and humans,
A. Delorme, G. Richard, and M. Fabre-Thorpe, “Ultra-rapid categorisa- tion of natural scenes does not rely on colour cues: a study in monkeys and humans,”Vision Research, vol. 40, no. 16, pp. 2187–2200, 2000
2000
-
[19]
Contribution of color to face recognition,
A. W. Yip and P. Sinha, “Contribution of color to face recognition,” Perception, vol. 31, no. 8, pp. 995–1003, 2002, pMID: 12269592
2002
-
[20]
The role of color in visual search in real-world scenes: Evidence from contextual cuing,
K. A. Ehinger and J. R. Brockmole, “The role of color in visual search in real-world scenes: Evidence from contextual cuing,”Perception & Psychophysics, vol. 70, no. 7, pp. 1366–1378, Oct 2008
2008
-
[21]
Optimal transport aggregation for visual place recognition,
S. Izquierdo and J. Civera, “Optimal transport aggregation for visual place recognition,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2024
2024
-
[22]
BoQ: A place is worth a bag of learnable queries,
A. Ali-bey, B. Chaib-draa, and P. Gigu `ere, “BoQ: A place is worth a bag of learnable queries,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2024, pp. 17 794–17 803
2024
-
[23]
Distinctive image features from scale-invariant keypoints,
D. G. Lowe, “Distinctive image features from scale-invariant keypoints,” Int. J. Comput. Vision, vol. 60, no. 2, p. 91–110, Nov. 2004
2004
-
[24]
Orb: An efficient alternative to sift or surf,
E. Rublee, V . Rabaud, K. Konolige, and G. Bradski, “Orb: An efficient alternative to sift or surf,” in2011 International Conference on Computer Vision, 2011, pp. 2564–2571
2011
-
[25]
Aggregating local de- scriptors into a compact image representation,
H. J ´egou, M. Douze, C. Schmid, and P. P ´erez, “Aggregating local de- scriptors into a compact image representation,” in2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2010, pp. 3304–3311
2010
-
[26]
Efficient visual search of videos cast as text retrieval,
J. Sivic and A. Zisserman, “Efficient visual search of videos cast as text retrieval,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 31, no. 4, pp. 591–606, 2009
2009
-
[27]
Fine-tuning cnn image retrieval with no human annotation,
F. Radenovi ´c, G. Tolias, and O. Chum, “Fine-tuning cnn image retrieval with no human annotation,”IEEE transactions on pattern analysis and machine intelligence, vol. 41, no. 7, pp. 1655–1668, 2018
2018
-
[28]
Close, but not there: Boosting geographic distance sensitivity in visual place recognition,
S. Izquierdo and J. Civera, “Close, but not there: Boosting geographic distance sensitivity in visual place recognition,” inComputer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, Part LXXIII. Berlin, Heidelberg: Springer-Verlag, 2024, p. 240–257
2024
-
[29]
Global proxy-based hard mining for visual place recognition,
A. Ali-Bey, B. Chaib-draa, and P. Giguere, “Global proxy-based hard mining for visual place recognition,” in33rd British Machine Vision Conference 2022, BMVC 2022, London, UK, November 21-24, 2022. BMV A Press, 2022
2022
-
[30]
Tiny machine learning: Progress and futures [feature],
J. Lin, L. Zhu, W.-M. Chen, W.-C. Wang, and S. Han, “Tiny machine learning: Progress and futures [feature],”IEEE Circuits and Systems Magazine, vol. 23, no. 3, pp. 8–34, 2023
2023
-
[31]
A novel motion blur resistant vSLAM framework for Micro/Nano-UA Vs,
B. S ¸ims ¸ek and H. S ¸. Bilge, “A novel motion blur resistant vSLAM framework for Micro/Nano-UA Vs,”Drones, vol. 5, no. 4, 2021
2021
-
[32]
Towards test-time efficient visual place recognition via asymmetric query processing,
J. Kim, Y . Cho, and S. Yoon, “Towards test-time efficient visual place recognition via asymmetric query processing,”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 7, pp. 5673–5681, 2026, publisher Copyright: © 2026, Association for the Advancement of Artificial Intelligence (www.aaai.org). All rights reserved.; 40th AAAI Conf...
2026
-
[33]
Recognising the forest, but not the trees: An effect of colour on scene perception and recognition,
T. C. Nijboer, R. Kanai, E. H. de Haan, and M. J. van der Smagt, “Recognising the forest, but not the trees: An effect of colour on scene perception and recognition,”Consciousness and Cognition, vol. 17, no. 3, pp. 741–752, 2008
2008
-
[34]
Color representation in deep neural networks,
M. Engilberge, E. Collins, and S. S ¨usstrunk, “Color representation in deep neural networks,” in2017 IEEE International Conference on Image Processing (ICIP), 2017, pp. 2786–2790
2017
-
[35]
Colorsense: A study on color vision in machine visual recognition,
M.-C. Chiu, Y . Wang, D. E. G. Kim, P.-Y . Chen, and X. Ma, “Colorsense: A study on color vision in machine visual recognition,” in2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), 2025, pp. 681–697
2025
-
[36]
Impact of colour on robustness of deep neural networks,
K. De and M. Pedersen, “Impact of colour on robustness of deep neural networks,” in2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), 2021, pp. 21–30
2021
-
[37]
On motion blur and deblurring in visual place recognition,
T. Ismagilov, B. Ferrarini, M. Milford, N. Tan Viet Tuyen, S. D. Ramchurn, and S. Ehsan, “On motion blur and deblurring in visual place recognition,”IEEE Robotics and Automation Letters, vol. 10, no. 5, pp. 4746–4753, 2025
2025
-
[38]
Don’t look back: Robusti- fying place categorization for viewpoint- and condition-invariant place recognition,
S. Garg, N. Suenderhauf, and M. Milford, “Don’t look back: Robusti- fying place categorization for viewpoint- and condition-invariant place recognition,” in2018 IEEE International Conference on Robotics and Automation (ICRA), 2018, pp. 3645–3652
2018
-
[39]
Vpr-bench: An open-source visual place recognition eval- uation framework with quantifiable viewpoint and appearance change,
M. Zaffar, S. Garg, M. Milford, J. Kooij, D. Flynn, K. McDonald-Maier, and S. Ehsan, “Vpr-bench: An open-source visual place recognition eval- uation framework with quantifiable viewpoint and appearance change,” International Journal of Computer Vision, pp. 1–39, 2021
2021
-
[40]
A survey on deep visual place recognition,
C. Masone and B. Caputo, “A survey on deep visual place recognition,” IEEE Access, vol. 9, pp. 19 516–19 547, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.