When Parallelism Pays Off: Cohesion-Aware Task Partitioning for Multi-Agent Coding
Pith reviewed 2026-06-28 17:52 UTC · model grok-4.3
The pith
Cohesion-aware partitioning of code dependency graphs lets multi-agent LLM coders raise pass rates while cutting time and cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
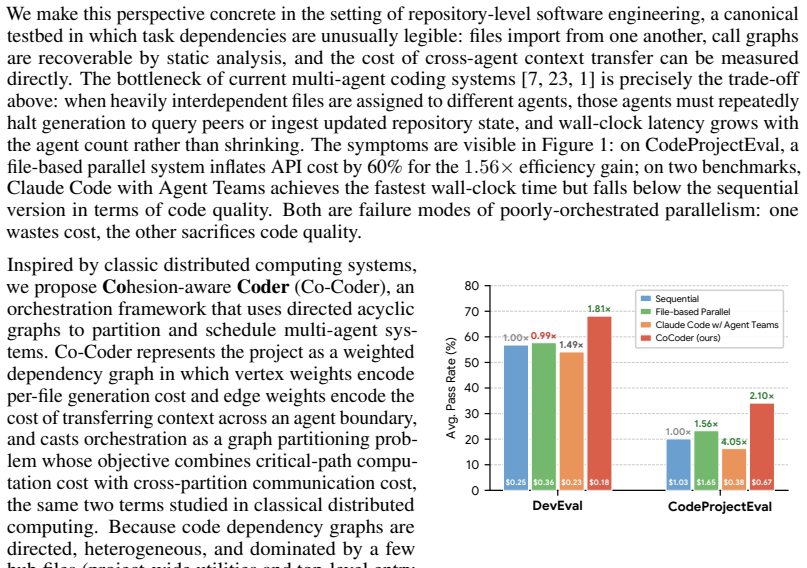
Treating repository-level coding tasks as a graph partitioning problem on static dependency graphs, solved by isolating hubs and using community detection followed by dependency-aware scheduling, yields task assignments that improve pass rate by up to 14 percent, wall-clock speedup up to 2.1 times, and API cost reduction up to 35 percent compared with sequential and file-based parallel baselines.
What carries the argument
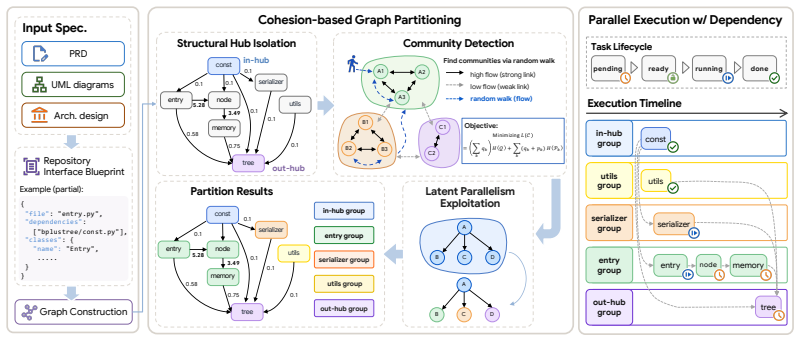
Static-analysis dependency graph partitioned by community detection after hub isolation, executed by a dependency-aware scheduler that assigns cohesive subgraphs to separate agents.
If this is right
- Partitions that group files with many shared dependencies reduce the volume of context that must cross agent boundaries.
- Community detection on the dependency graph produces more efficient task splits than assigning whole files or running everything sequentially.
- The largest efficiency and quality gains appear on projects whose dependency graphs are densest.
- Dependency-aware scheduling prevents agents from starting work on tasks whose prerequisites have not yet completed.
- Reducing redundant context transfers directly lowers the number of tokens sent to the underlying LLM.
Where Pith is reading between the lines
- The same graph-partitioning logic could be applied to other multi-agent workflows that involve shared state, such as collaborative planning or distributed data analysis.
- If the static graph underestimates certain runtime dependencies, an online refinement step that updates the partition during execution could recover some of the lost gains.
- Replacing the fixed community-detection heuristic with a learned cost model that predicts actual LLM context-transfer expense might tighten the partitions further.
Load-bearing premise
Static analysis of the repository produces dependency graphs that accurately reflect the real communication costs agents incur when passing context to one another.
What would settle it
Measure whether the reported gains disappear on a high-dependency project when the static graph is replaced by one built from actual runtime call traces that include dynamic dependencies missed by static analysis.
Figures

read the original abstract
Multi-agent Large Language Model (LLM) systems offer a way to decompose complex tasks, such as coding, through parallelization and context isolation. However, adding agents in practice introduces inter-agent communication overhead, which incurs extra cost and can sometimes offset the efficiency gains. We formalize multi-agent orchestration as a graph partitioning problem that captures the communication-to-computation trade-off: task decomposition can shorten critical-path computation, but cross-agent dependencies require costly context transfer. We instantiate this view in repository-level software engineering and present Cohesion-aware Coder (Co-Coder), which builds dependency graphs from static analysis, isolates structural hub files, partitions the graph via community detection, and executes the partition with a dependency-aware scheduler. Across 28 real-world tasks on DevEval and CodeProjectEval, Co-Coder advances the Pareto-frontier over sequential and file-based parallel baselines as well as Claude Code with Agent Teams, lifting pass rate by up to 14.0%, achieving up to a 2.10x wall-clock speedup, and reducing API cost by up to 35%, with the largest gains on the most dependency-dense projects. Co-coder demonstrates how cohesion-aware orchestration can make parallel coding agents both theoretically grounded and practically efficient, suggesting a broader design principle for multi-agent systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that formalizing multi-agent LLM coding as a graph-partitioning problem—where static-analysis dependency graphs are partitioned via community detection to balance communication-to-computation costs—yields Co-Coder, which improves over sequential, file-based parallel, and Claude Code baselines. On 28 tasks from DevEval and CodeProjectEval it reports up to 14% higher pass rate, 2.1× wall-clock speedup, and 35% lower API cost, with largest gains on dependency-dense projects.
Significance. If the empirical results survive scrutiny of baseline fairness, statistical significance, and the validity of static graphs as proxies for LLM context-transfer costs, the work supplies a concrete, graph-theoretic design principle for orchestrating parallel LLM agents. The explicit modeling of the communication-to-computation trade-off and the use of community detection on real repository graphs are strengths that could generalize beyond coding.
major comments (2)
- [Evaluation] Evaluation section: the reported 14.0% / 2.10× / 35% gains are presented as point estimates without reported standard deviations, number of runs, or statistical significance tests; this makes it impossible to judge whether the Pareto-frontier advance is robust or could be explained by run-to-run variance or post-hoc partition selection.
- [Method] Method (graph construction and scheduler): the central claim that cohesion-aware partitioning improves the relevant trade-off rests on the untested assumption that static-analysis edges (imports, calls) accurately encode the context-transfer costs actually incurred by LLM agents; no ablation, correlation study, or human annotation validates that syntactic dependencies predict semantic context volume or latency.
minor comments (2)
- [Abstract] Abstract and §1: the phrase "advances the Pareto-frontier" is used without defining the axes or showing the full frontier plot; a single sentence clarifying the three metrics and how the frontier is constructed would help.
- [Throughout] Notation: the paper introduces "Cohesion-aware Coder (Co-Coder)" but later refers to "Co-coder"; consistent capitalization and acronym usage throughout would reduce minor confusion.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on evaluation robustness and the grounding of our graph-partitioning assumptions. We respond to each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the reported 14.0% / 2.10× / 35% gains are presented as point estimates without reported standard deviations, number of runs, or statistical significance tests; this makes it impossible to judge whether the Pareto-frontier advance is robust or could be explained by run-to-run variance or post-hoc partition selection.
Authors: We acknowledge the limitation in the current presentation. The reported figures are single-run point estimates obtained under fixed random seeds for reproducibility. In the revised manuscript we will re-execute all 28 tasks with at least five independent runs per method, report means and standard deviations, and include paired statistical tests (Wilcoxon signed-rank) together with p-values. We will also document the deterministic partition-selection procedure to rule out post-hoc bias. revision: yes
-
Referee: [Method] Method (graph construction and scheduler): the central claim that cohesion-aware partitioning improves the relevant trade-off rests on the untested assumption that static-analysis edges (imports, calls) accurately encode the context-transfer costs actually incurred by LLM agents; no ablation, correlation study, or human annotation validates that syntactic dependencies predict semantic context volume or latency.
Authors: Static-analysis edges are a standard, inexpensive proxy in repository-level software engineering; our results already show that gains scale with dependency density, providing indirect empirical support. Nevertheless, we agree that an explicit ablation would strengthen the claim. The revision will add (i) a comparison of community-detection partitions against random and file-based baselines on the same graphs and (ii) a brief discussion of the proxy’s limitations. A dedicated human annotation or correlation study of context volume is beyond the scope of the present work and is noted as future research. revision: partial
Circularity Check
No significant circularity; empirical claims rest on external benchmarks
full rationale
The paper formalizes orchestration as graph partitioning but reports results solely via empirical evaluation on external benchmarks (DevEval, CodeProjectEval) against published baselines. No equations, fitted parameters, or predictions reduce the reported pass-rate/speedup/cost gains to quantities defined inside the paper. No self-citation chains or ansatzes are load-bearing for the central claims. The derivation is self-contained against external data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
C., Arun Iyer, Suresh Parthasarathy, Sriram K
Ramakrishna Bairi, Atharv Sonwane, Aditya Kanade, Vageesh D. C., Arun Iyer, Suresh Parthasarathy, Sriram K. Rajamani, Balasubramanyan Ashok, and Shashank Shet. Codeplan: Repository-level coding using llms and planning.CoRR, abs/2309.12499, 2023
-
[2]
Why Do Multi-Agent LLM Systems Fail?
Mert Cemri, Melissa Z. Pan, Shuyi Yang, Lakshya A. Agrawal, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya G. Parameswaran, Dan Klein, Kannan Ramchandran, Matei Zaharia, Joseph E. Gonzalez, and Ion Stoica. Why do multi-agent LLM systems fail?CoRR, abs/2503.13657, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Culler, Richard M
David E. Culler, Richard M. Karp, David A. Patterson, Abhijit Sahay, Klaus E. Schauser, Eunice E. Santos, Ramesh Subramonian, and Thorsten von Eicken. Logp: Towards a realistic model of parallel computation. In Marina C. Chen and Robert Halstead, editors,Proceedings of the Fourth ACM SIGPLAN Symposium on Principles & Practice of Parallel Programming (PPOP...
1993
-
[4]
TCP: a benchmark for temporal constraint-based planning
Zifeng Ding, Sikuan Yan, Moy Yuan, Xianglong Hu, Fangru Lin, and Andreas Vlachos. TCP: a benchmark for temporal constraint-based planning. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, EMNLP 2025, Suzhou, China, November 4-9...
2025
-
[5]
DevBench: A Realistic, Developer-Informed Benchmark for Code Generation Models
Pareesa Ameneh Golnari, Adarsh Kumarappan, Wen Wen, Xiaoyu Liu, Gabriel Ryan, Yuting Sun, Shengyu Fu, and Elsie Nallipogu. Devbench: A realistic, developer-informed benchmark for code generation models.CoRR, abs/2601.11895, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
R. L. Graham. Bounds for certain multiprocessing anomalies.The Bell System Technical Journal, 45(9):1563–1581, 1966
1966
-
[7]
Metagpt: Meta programming for A multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. Metagpt: Meta programming for A multi-agent collaborative framework. InThe Twelfth International Conference on Learning Representations, ICL...
2024
-
[8]
Livecodebench: Holistic and contamination free evaluation of large language models for code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025
2025
-
[9]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. Swe-bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024
2024
-
[10]
Planning and scheduling in the process industry.OR Spectr., 24(3):219–250, 2002
Josef Kallrath. Planning and scheduling in the process industry.OR Spectr., 24(3):219–250, 2002
2002
-
[11]
A fast and high quality multilevel scheme for partitioning irregular graphs.SIAM J
George Karypis and Vipin Kumar. A fast and high quality multilevel scheme for partitioning irregular graphs.SIAM J. Sci. Comput., 20(1):359–392, 1998
1998
-
[12]
Kernighan and Shen Lin
Brian W. Kernighan and Shen Lin. An efficient heuristic procedure for partitioning graphs.Bell Syst. Tech. J., 49(2):291–307, 1970
1970
-
[13]
Lieberwirth, Xinkai Yu, Yicheng Fu, Michael J
Arpandeep Khatua, Hao Zhu, Peter Tran, Arya Prabhudesai, Frederic Sadrieh, Johann K. Lieberwirth, Xinkai Yu, Yicheng Fu, Michael J. Ryan, Jiaxin Pei, and Diyi Yang. Cooperbench: Why coding agents cannot be your teammates yet.CoRR, abs/2601.13295, 2026
-
[14]
Mahoney, Kurt Keutzer, and Amir Gholami
Sehoon Kim, Suhong Moon, Ryan Tabrizi, Nicholas Lee, Michael W. Mahoney, Kurt Keutzer, and Amir Gholami. An LLM compiler for parallel function calling. In Ruslan Salakhutdinov, Zico Kolter, Katherine A. Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Forty-first International Conference on Machine Learning, ICML 2024,...
2024
-
[15]
Prompting large language models to tackle the full software development lifecycle: A case study
Bowen Li, Wenhan Wu, Ziwei Tang, Lin Shi, John Yang, Jinyang Li, Shunyu Yao, Chen Qian, Binyuan Hui, Qicheng Zhang, Zhiyin Yu, He Du, Ping Yang, Dahua Lin, Chao Peng, and Kai Chen. Prompting large language models to tackle the full software development lifecycle: A case study. In Owen Rambow, Leo Wanner, Marianna Apidianaki, Hend Al-Khalifa, Barbara Di Eu...
2025
-
[16]
CAMEL: communicative agents for "mind" exploration of large language model society
Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. CAMEL: communicative agents for "mind" exploration of large language model society. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, Advances in Neural Information Processing Systems 36: Annual Conference on Neural Infor- matio...
2023
-
[17]
Deveval: A manually-annotated code generation benchmark aligned with real-world code repositories
Jia Li, Ge Li, Yunfei Zhao, Yongmin Li, Huanyu Liu, Hao Zhu, Lecheng Wang, Kaibo Liu, Zheng Fang, Lanshen Wang, Jiazheng Ding, Xuanming Zhang, Yuqi Zhu, Yihong Dong, Zhi Jin, Binhua Li, Fei Huang, Yongbin Li, Bin Gu, and Mengfei Yang. Deveval: A manually-annotated code generation benchmark aligned with real-world code repositories. In Lun-Wei Ku, Andre Ma...
2024
-
[18]
Cohn, and Janet B
Fangru Lin, Emanuele La Malfa, Valentin Hofmann, Elle Michelle Yang, Anthony G. Cohn, and Janet B. Pierrehumbert. Graph-enhanced large language models in asynchronous plan reasoning. In Ruslan Salakhutdinov, Zico Kolter, Katherine A. Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Forty-first International Conference ...
2024
-
[19]
Tianyang Liu, Canwen Xu, and Julian J. McAuley. Repobench: Benchmarking repository- level code auto-completion systems. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024
2024
-
[20]
Large language models miss the multi-agent mark
Emanuele La Malfa, Gabriele La Malfa, Samuele Marro, Jie M. Zhang, Elizabeth Black, Michael Luck, Philip Torr, and Michael J. Wooldridge. Large language models miss the multi-agent mark.CoRR, abs/2505.21298, 2025
-
[21]
Martin.Agile Software Development: Principles, Patterns, and Practices
R.C. Martin.Agile Software Development: Principles, Patterns, and Practices. Alan Apt series. Pearson Education, 2003
2003
-
[22]
Collins, Ilia Sucholutsky, Natalia Vélez, and Thomas L
Elizabeth Mieczkowski, Katherine M. Collins, Ilia Sucholutsky, Natalia Vélez, and Thomas L. Griffiths. Language model teams as distributed systems.CoRR, abs/2603.12229, 2026
-
[23]
Chatdev: Communicative agents for software development
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. Chatdev: Communicative agents for software development. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Li...
2024
-
[24]
Scaling large language model- based multi-agent collaboration
Chen Qian, Zihao Xie, Yifei Wang, Wei Liu, Kunlun Zhu, Hanchen Xia, Yufan Dang, Zhuoyun Du, Weize Chen, Cheng Yang, Zhiyuan Liu, and Maosong Sun. Scaling large language model- based multi-agent collaboration. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025
2025
-
[25]
Maps of random walks on complex networks reveal community structure.Proceedings of the National Academy of Sciences, 105(4):1118–1123, 2008
Martin Rosvall and Carl T Bergstrom. Maps of random walks on complex networks reveal community structure.Proceedings of the National Academy of Sciences, 105(4):1118–1123, 2008
2008
-
[26]
Silverman, Jason D
Alvin Wei Ming Tan, Chunhua Yu, Bria Long, Wanjing Ma, Tonya Murray, Rebecca D. Silverman, Jason D. Yeatman, and Michael C. Frank. Devbench: A multimodal developmental 11 benchmark for language learning. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Advances in Neural Informatio...
2024
-
[27]
Performance-effective and low-complexity task scheduling for heterogeneous computing.IEEE Trans
Haluk Topcuoglu, Salim Hariri, and Min-You Wu. Performance-effective and low-complexity task scheduling for heterogeneous computing.IEEE Trans. Parallel Distributed Syst., 13(3):260– 274, 2002
2002
-
[28]
Leslie G. Valiant. A bridging model for parallel computation.Commun. ACM, 33(8):103–111, 1990
1990
-
[29]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, and et al. Openhands: An open platform for AI software developers as generalist agents. InThe...
2025
-
[30]
Repoformer: Selective retrieval for repository-level code completion
Di Wu, Wasi Uddin Ahmad, Dejiao Zhang, Murali Krishna Ramanathan, and Xiaofei Ma. Repoformer: Selective retrieval for repository-level code completion. In Ruslan Salakhutdinov, Zico Kolter, Katherine A. Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Forty-first International Conference on Machine Learning, ICML 2024,...
2024
-
[31]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, and Chi Wang. Autogen: Enabling next-gen LLM applications via multi-agent conversation framework.CoRR, abs/2308.08155, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Agentless: Demystifying LLM-based Software Engineering Agents
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. Agentless: Demystifying llm-based software engineering agents.CoRR, abs/2407.01489, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Advances in Neural Information Processing Syst...
2024
-
[34]
Qianhui Zhao, Li Zhang, Fang Liu, Junhang Cheng, Chengru Wu, Junchen Ai, Qiaoyuanhe Meng, Lichen Zhang, Xiaoli Lian, Shubin Song, and Yuanping Guo. Towards realistic project- level code generation via multi-agent collaboration and semantic architecture modeling.CoRR, abs/2511.03404, 2025
-
[35]
DevBench
Mingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and Jürgen Schmidhuber. Gptswarm: Language agents as optimizable graphs. In Ruslan Salakhutdinov, Zico Kolter, Katherine A. Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Forty-first International Conference on Machine Learning, ICML 2024...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.