When Is 0.1% Enough? Analyzing the Combined Effects of Dimensionality Reduction and Quantization on Text Embedding Compression
Pith reviewed 2026-06-28 17:19 UTC · model grok-4.3
The pith
Combining dimensionality reduction and quantization compresses text embeddings to 0.1% of original size with almost no performance loss in tested cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
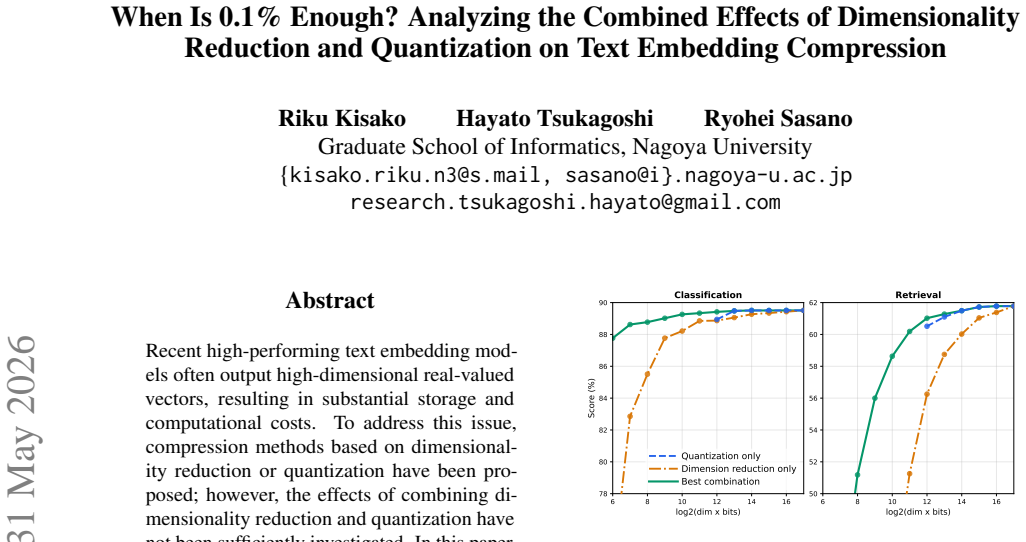
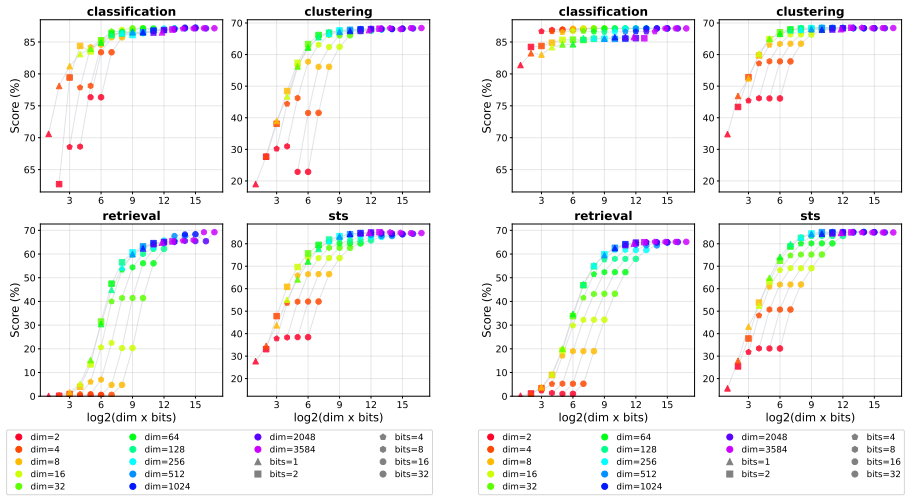
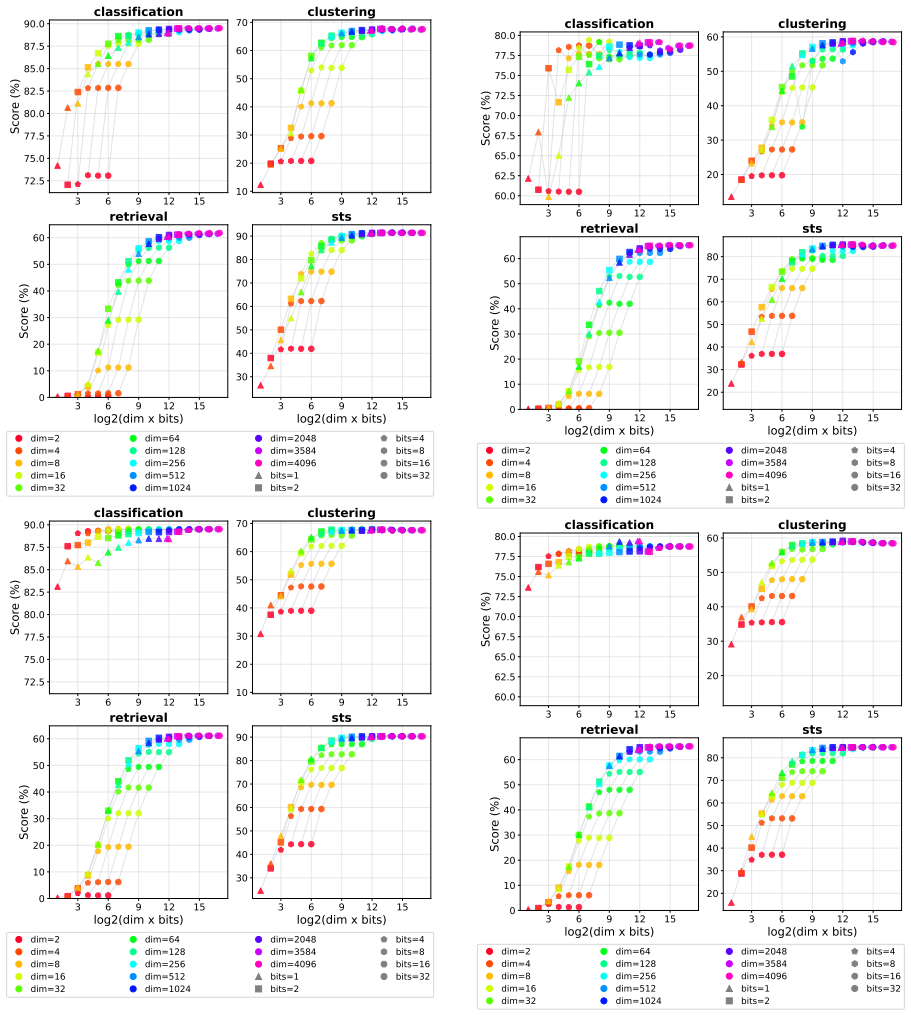
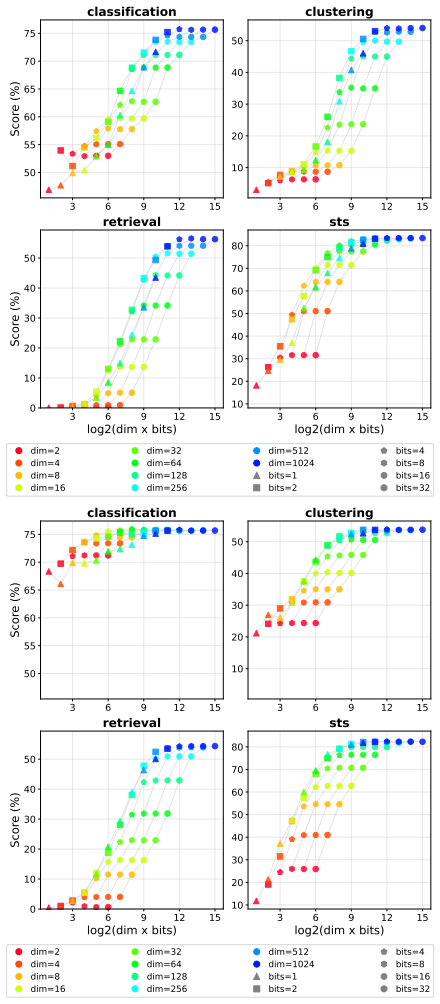
The experimental results demonstrate that combining dimensionality reduction and quantization enables substantially stronger compression than using either method alone, that in some settings embeddings can be reduced to as little as 0.1% of their original size with almost no performance degradation, and that the optimal compression strategy depends on the task.
What carries the argument
Sequential or joint application of dimensionality reduction (lowering vector length) followed by quantization (lowering value precision) to fixed text embedding vectors from pretrained models.
If this is right
- Storage systems could index orders of magnitude more embeddings without added hardware.
- Task-specific compression pipelines would replace uniform approaches in production retrieval setups.
- Resource-limited devices could run embedding-based applications that currently require full-precision vectors.
- Performance on retrieval, classification, and clustering tasks stays close to baseline under aggressive joint compression.
Where Pith is reading between the lines
- Embedding models may carry redundant capacity in both dimension count and numeric precision for many current uses.
- Training pipelines could add compression objectives so that models are optimized for size from the start.
- Dynamic selection of reduction-plus-quantization settings per query type could become a standard runtime step.
Load-bearing premise
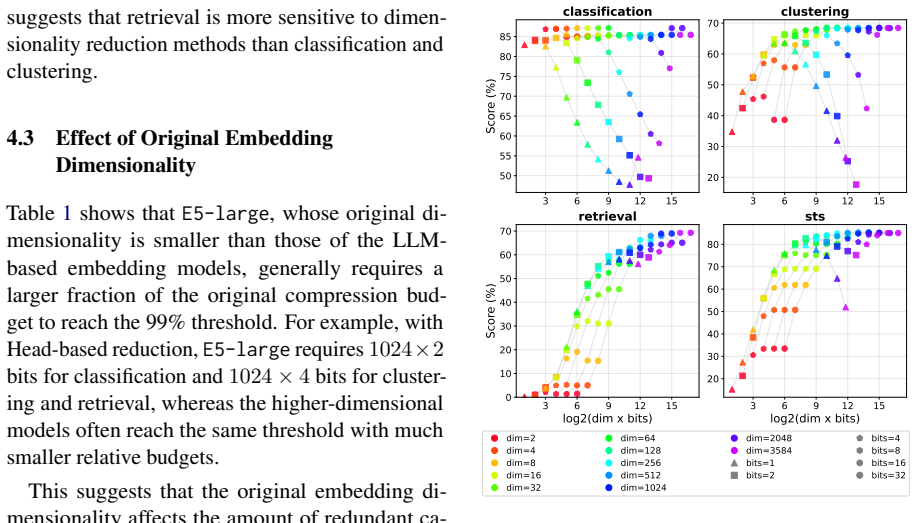
The four MTEB task families and four pretrained embedding models chosen are representative enough that the observed compression behavior and task-dependent optima will generalize to other embedding models and real-world applications not covered by these benchmarks.
What would settle it
Applying the same compression ratios to a new embedding model or task family outside the four tested ones and measuring clear performance drops at the 0.1% size level.
Figures
read the original abstract
Recent high-performing text embedding models often output high-dimensional real-valued vectors, resulting in substantial storage and computational costs. To address this issue, compression methods based on dimensionality reduction or quantization have been proposed; however, the effects of combining dimensionality reduction and quantization have not been sufficiently investigated. In this paper, we systematically examine the effectiveness of compressing text embeddings by combining dimensionality reduction and quantization, using four MTEB task families and four pretrained embedding models. The experimental results demonstrate that combining dimensionality reduction and quantization enables substantially stronger compression than using either method alone, that in some settings embeddings can be reduced to as little as 0.1% of their original size with almost no performance degradation, and that the optimal compression strategy depends on the task.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that combining dimensionality reduction and quantization enables substantially stronger compression of text embeddings than either technique alone. Experiments across four MTEB task families and four pretrained embedding models show that embeddings can be reduced to as little as 0.1% of original size with almost no performance degradation in some settings, and that the optimal compression strategy is task-dependent.
Significance. If the reported synergies and 0.1% compression results hold under a complete evaluation protocol with proper statistical controls, the work would offer practical value for deploying high-dimensional embedding models under storage and compute constraints. The empirical focus on interactions between the two compression stages is a clear strength.
major comments (2)
- [Abstract and experimental sections] Abstract and experimental sections: the central claims rest on experiments limited to four MTEB task families and four pretrained models. The interaction between dimensionality reduction and quantization (e.g., how reduced dimensionality affects quantization error) may differ for other model families or task distributions, undermining the generality of the task-dependent optima and 0.1% compression findings.
- [Experimental protocol (throughout results sections)] Experimental protocol (throughout results sections): no error bars, statistical tests, data exclusion rules, or full evaluation details are described, making it impossible to determine whether the 0.1% size claim with negligible degradation rests on post-hoc selection or holds under the full protocol.
minor comments (1)
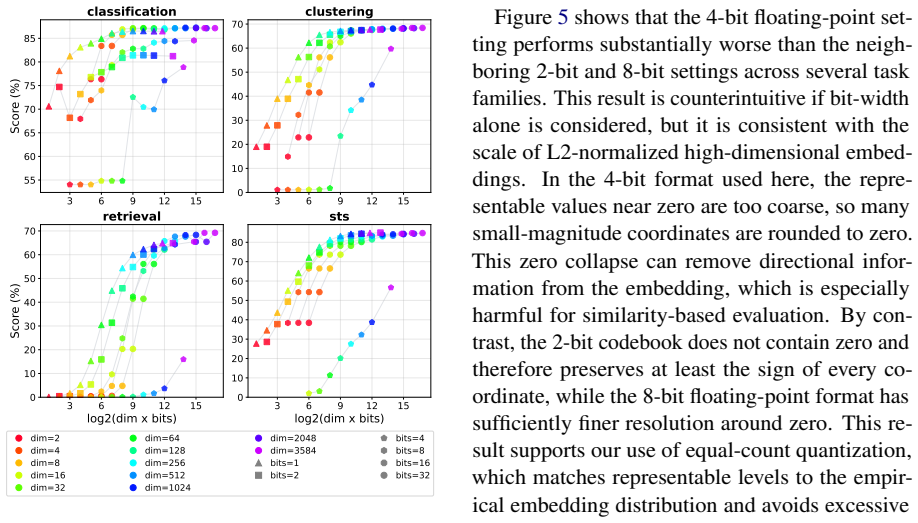
- [Abstract] The abstract uses the phrase 'almost no performance degradation' without defining the threshold or reporting the exact metric values used to support it.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. Below we provide point-by-point responses to the major comments, indicating the revisions we intend to make to address the concerns raised.
read point-by-point responses
-
Referee: [Abstract and experimental sections] Abstract and experimental sections: the central claims rest on experiments limited to four MTEB task families and four pretrained models. The interaction between dimensionality reduction and quantization (e.g., how reduced dimensionality affects quantization error) may differ for other model families or task distributions, undermining the generality of the task-dependent optima and 0.1% compression findings.
Authors: We recognize the limitation in the breadth of our experimental evaluation. Our selection of four task families and four models aimed to provide initial insights into the combined compression effects across representative settings. To address the referee's concern, we will revise the abstract and add a limitations section in the manuscript to explicitly note that the observed synergies and task-dependent optima may not generalize to all model families or task distributions. This will include a discussion of how reduced dimensionality might affect quantization error in other contexts. revision: partial
-
Referee: [Experimental protocol (throughout results sections)] Experimental protocol (throughout results sections): no error bars, statistical tests, data exclusion rules, or full evaluation details are described, making it impossible to determine whether the 0.1% size claim with negligible degradation rests on post-hoc selection or holds under the full protocol.
Authors: We agree that the experimental protocol requires more detailed reporting to allow proper assessment of the results. In the revised manuscript, we will include a thorough description of the full evaluation protocol, data exclusion rules, and any preprocessing steps. We will also add error bars to the performance metrics (e.g., based on task-level variance) and conduct statistical tests where appropriate to support the claims of minimal degradation at 0.1% compression. This will help clarify that the results are not the result of post-hoc selection. revision: yes
Circularity Check
No circularity: purely empirical measurements on fixed benchmarks
full rationale
The paper performs direct experiments: it applies dimensionality reduction and quantization to embeddings from four fixed pretrained models, evaluates on four MTEB task families, and reports observed size/performance trade-offs. There are no equations, fitted parameters presented as predictions, self-citations used to justify uniqueness, or derivations that reduce results to prior fitted quantities. The central claims are statements about the measured outcomes on the chosen benchmarks; they do not rely on any internal reduction or self-referential construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Universal Sentence Encoder.Preprint, arXiv:1803.11175. Alexis Conneau, Douwe Kiela, Holger Schwenk, Loïc Barrault, and Antoine Bordes
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
InProceedings of the 2017 Conference on Empirical Methods in Natu- ral Language Processing (EMNLP), pages 670–680, Copenhagen, Denmark
Supervised Learning of Universal Sentence Representations from Natural Language Inference Data. InProceedings of the 2017 Conference on Empirical Methods in Natu- ral Language Processing (EMNLP), pages 670–680, Copenhagen, Denmark. Association for Computa- tional Linguistics. Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh
2017
-
[3]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transform- ers.arXiv preprint arXiv:2210.17323. Tianyu Gao, Xingcheng Yao, and Danqi Chen
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
InProceedings of the 2021 conference on empirical methods in natural language processing (EMNLP), pages 6894–6910
SimCSE: Simple Contrastive Learning of Sentence Embeddings. InProceedings of the 2021 conference on empirical methods in natural language processing (EMNLP), pages 6894–6910. Naamán Huerga-Pérez, Rubén Álvarez, Rubén Ferrero- Guillén, Alberto Martínez-Gutiérrez, and Javier Díez-González
2021
-
[5]
Optimization of embed- dings storage for RAG systems using quantization and dimensionality reduction techniques.Preprint, arXiv:2505.00105. Taehee Jeong
-
[6]
Gemini Embedding: Generalizable Embeddings from Gemini
Ma- tryoshka Representation Learning. InAdvances in Neural Information Processing Systems (NeurIPS), volume 35, pages 30233–30249. Curran Associates, Inc. Chankyu Lee, Rajarshi Roy, Mengyao Xu, Jonathan Raiman, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. 2025a. NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models. InInternat...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Towards General Text Embeddings with Multi-stage Contrastive Learning
Towards General Text Embeddings with Multi-stage Con- trastive Learning.arXiv preprint arXiv:2308.03281. Siyu Liao, Jie Chen, Yanzhi Wang, Qinru Qiu, and Bo Yuan
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
UMAP: Uniform Manifold Approximation and Pro- jection for Dimension Reduction.arXiv preprint arXiv:1802.03426. Niklas Muennighoff, Nouamane Tazi, Loic Magne, and Nils Reimers
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
InProceedings of the 17th Con- ference of the European Chapter of the Association for Computational Linguistics (EACL), pages 2014– 2037, Dubrovnik, Croatia
MTEB: Massive Text Embed- ding Benchmark. InProceedings of the 17th Con- ference of the European Chapter of the Association for Computational Linguistics (EACL), pages 2014– 2037, Dubrovnik, Croatia. Association for Computa- tional Linguistics. Zach Nussbaum, John Xavier Morris, Andriy Mul- yar, and Brandon Duderstadt
2014
-
[10]
InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 853–
Efficient Document Retrieval by End-to- End Refining and Quantizing BERT Embedding with Contrastive Product Quantization. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 853–
2022
-
[11]
Sentence- BERT: Sentence Embeddings using Siamese BERT- Networks. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 3982–
2019
-
[12]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 27705–27726, Suzhou, China
Randomly Re- moving 50% of Dimensions in Text Embeddings has Minimal Impact on Retrieval and Classification Tasks. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 27705–27726, Suzhou, China. Association for Computational Linguistics. Joshua B Tenenbaum, Vin de Silva, and John C Langford
2025
-
[13]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Text Embeddings by Weakly- Supervised Contrastive Pre-training.arXiv preprint arXiv:2212.03533. Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate
TurboQuant: Online Vector Quanti- zation with Near-optimal Distortion Rate.Preprint, arXiv:2504.19874. Jingtao Zhan, Jiaxin Mao, Yiqun Liu, Jiafeng Guo, Min Zhang, and Shaoping Ma
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Mod- els.Preprint, arXiv:2506.05176. A Model Details Used in Our Experiments Table 2 summarizes the pretrained text embedding models used in our experiments. For the instruction-based models in Table 2, we encode input texts with task-specific instructions for all tasks. For classi...
work page internal anchor Pith review Pith/arXiv arXiv 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.