Magnum.np.distributed: Accelerating Finite Difference Micromagnetic Simulations with Multiple GPUs
Pith reviewed 2026-06-28 16:44 UTC · model grok-4.3
The pith
Extending magnum.np with PyTorch Distributed creates the first Python-native multi-GPU micromagnetic simulator with 7x speedup on demagnetisation calculations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
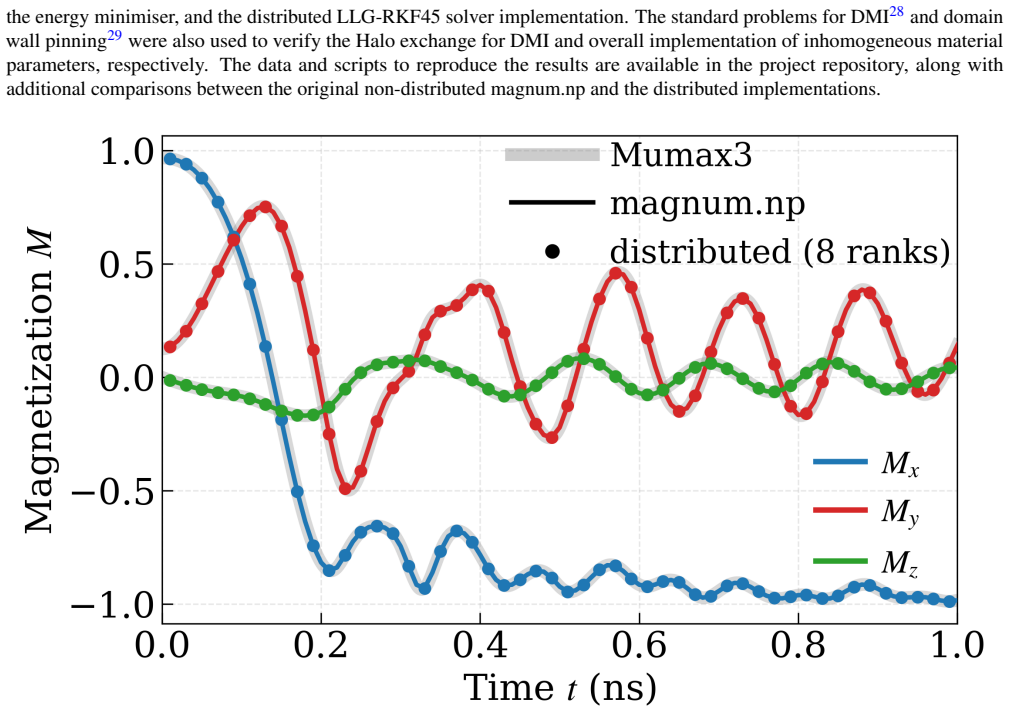
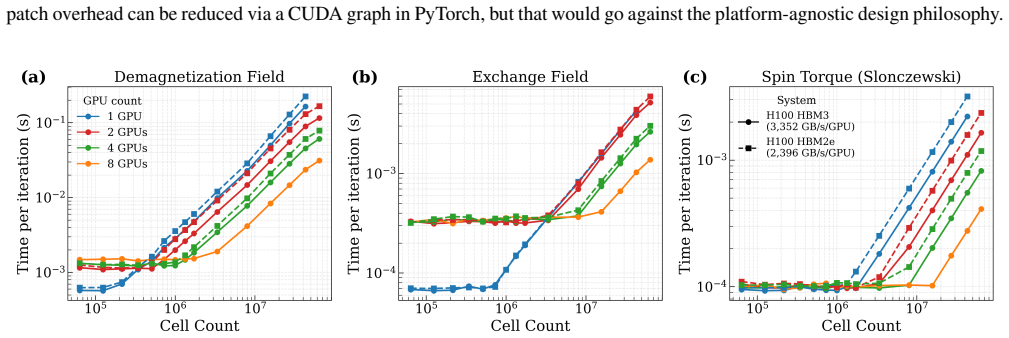
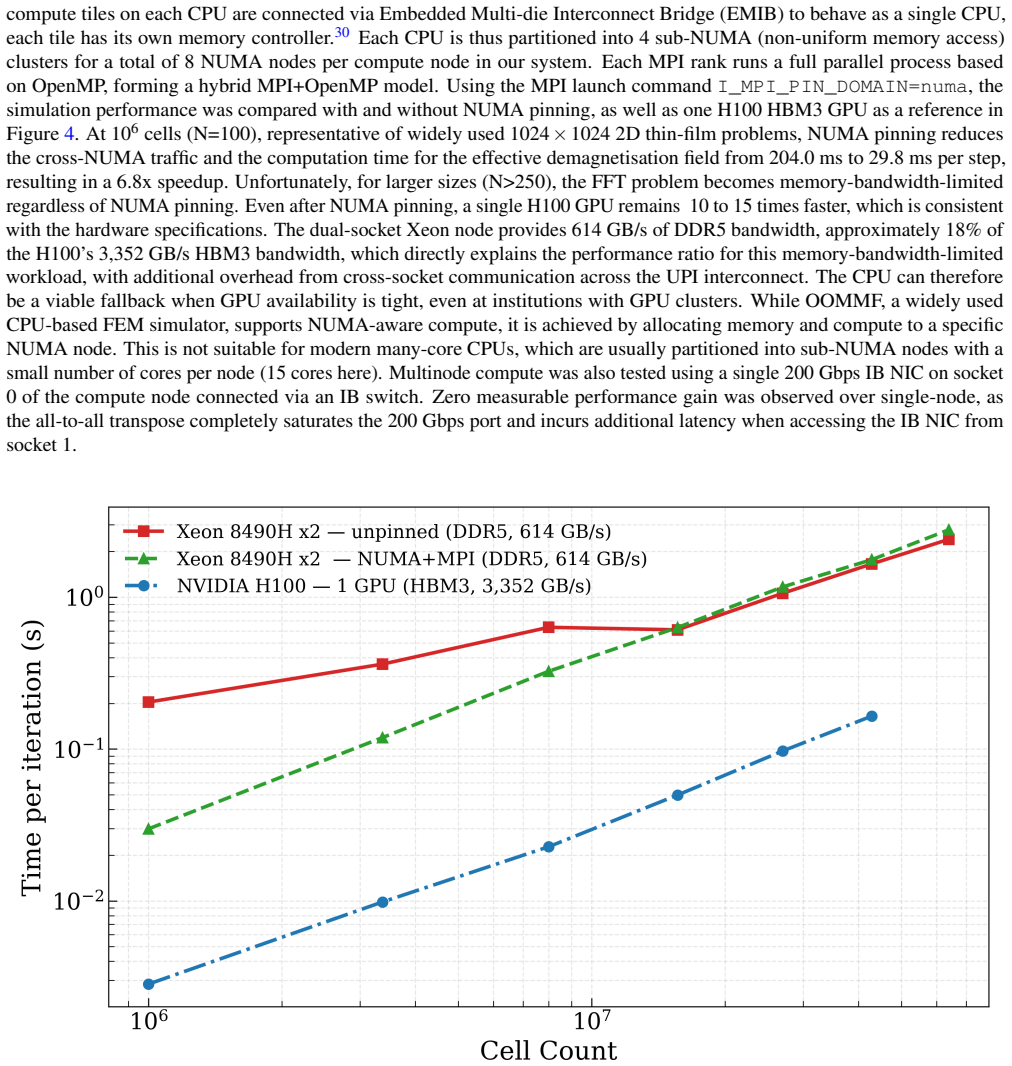
The authors present the first Python-native multi-GPU micromagnetic framework by extending magnum.np with PyTorch Distributed. This leverages high-speed communication and computation across multiple GPUs while retaining the benefits of ease of installation, platform-agnostic design, and compatibility with Python. For computationally intensive demagnetisation effective-field calculations, they achieve a 7.0x speedup across 8 GPUs connected via NVLink, whereas Halo exchange required for Heisenberg exchange shows limited scaling due to kernel dispatch latency. They also demonstrated the framework's versatility by achieving a 6.8x speedup in demagnetisation field computation on CPU with NUMA pin
What carries the argument
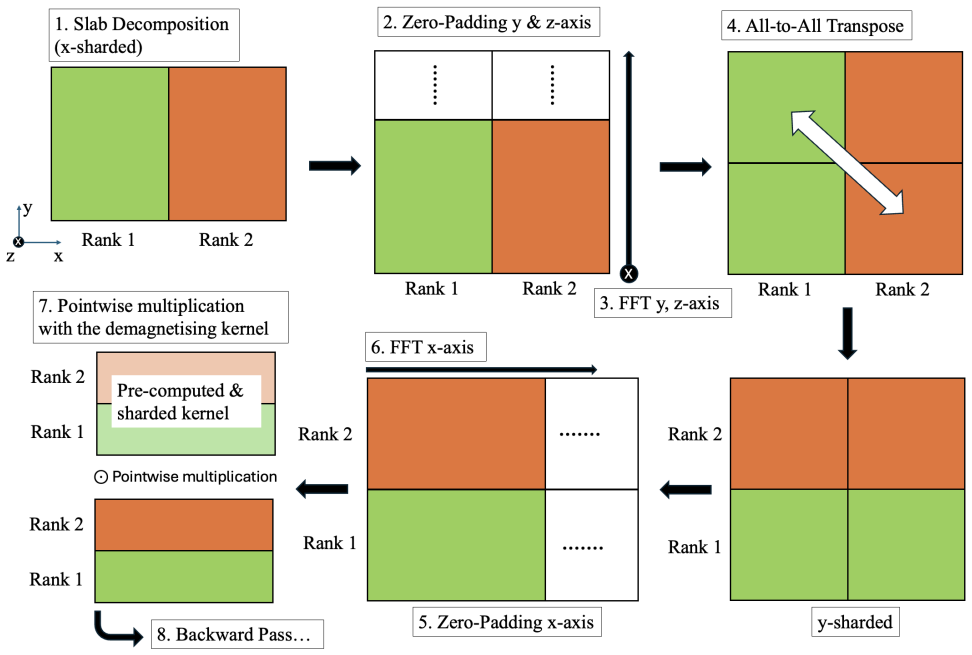
PyTorch Distributed backend applied to distribute micromagnetic effective-field computations, especially the demagnetisation field, across multiple GPUs or CPUs.
If this is right
- Researchers can simulate larger magnetic structures in less time than before.
- Faster turnaround times accelerate the design cycle for novel spintronic devices.
- The framework keeps the original ease of installation and Python compatibility.
- Similar speedups apply to CPU clusters when using NUMA pinning with the MPI backend.
- Heisenberg exchange calculations remain limited by kernel dispatch latency and may need separate optimization.
Where Pith is reading between the lines
- Other single-GPU Python-based micromagnetic packages could adopt the same PyTorch Distributed extension for multi-device scaling.
- The observed bottleneck in halo exchange suggests that reducing kernel launch overheads could improve scaling for exchange terms.
- Hybrid GPU and CPU distributed configurations might enable flexible allocation of heterogeneous computing resources.
Load-bearing premise
The distributed implementation preserves numerical correctness equivalent to the original single-GPU magnum.np while delivering the stated speedups.
What would settle it
Running an identical micromagnetic problem on both the original single-GPU version and the new multi-GPU version and obtaining different magnetization dynamics results would falsify preserved correctness.
Figures
read the original abstract
Micromagnetic simulations are essential tools in nanomagnetism and spintronics research. Although widely adopted solvers like Mumax3 and the Python-native magnum.np use GPU acceleration to improve performance, these tools are limited to single-device computation. In this work, we present the first Python-native multi-GPU micromagnetic framework by extending magnum.np with PyTorch Distributed. This leverages high-speed communication and computation across multiple GPUs while retaining the benefits of ease of installation, platform-agnostic design, and compatibility with Python. For computationally intensive demagnetisation effective-field calculations, we achieve a 7.0x speedup across 8 GPUs connected via NVLink, whereas Halo exchange required for Heisenberg exchange shows limited scaling due to kernel dispatch latency. We also demonstrated the framework's versatility by achieving a 6.8x speedup in demagnetisation field computation on CPU with NUMA pinning via the MPI backend of PyTorch Distributed. Faster turnaround times will enable researchers to explore larger, more complex systems and accelerate the design cycle for novel spintronic devices.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript extends the single-GPU magnum.np micromagnetic framework to multiple GPUs via PyTorch Distributed, presenting it as the first Python-native multi-GPU implementation. It reports a 7.0x speedup for demagnetization effective-field calculations across 8 GPUs connected by NVLink, a 6.8x speedup on CPU with the MPI backend and NUMA pinning, and notes limited scaling for Heisenberg-exchange halo exchange due to kernel dispatch latency.
Significance. If numerical equivalence to the single-GPU baseline is demonstrated, the work would provide a practical route to larger-scale micromagnetic simulations while preserving Python ease-of-use and installation simplicity. The explicit use of PyTorch Distributed for both GPU and CPU backends is a concrete engineering contribution that could be adopted by other finite-difference codes.
major comments (1)
- [Abstract] Abstract: the central performance claims (7.0x on 8 GPUs for demagnetization, 6.8x on CPU) are presented without any quantitative verification that the distributed results reproduce the single-GPU magnum.np reference. No L2 or max-norm differences on effective fields, no NIST standard-problem comparisons, and no tolerance thresholds for halo-exchange or all-reduce operations are supplied; without these checks the reported speedups cannot be interpreted as evidence that the multi-GPU solver is functionally interchangeable with the original code.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. The major comment highlights an important gap in the presentation of numerical verification, which we address below by committing to revisions that strengthen the manuscript without misrepresenting the current content.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims (7.0x on 8 GPUs for demagnetization, 6.8x on CPU) are presented without any quantitative verification that the distributed results reproduce the single-GPU magnum.np reference. No L2 or max-norm differences on effective fields, no NIST standard-problem comparisons, and no tolerance thresholds for halo-exchange or all-reduce operations are supplied; without these checks the reported speedups cannot be interpreted as evidence that the multi-GPU solver is functionally interchangeable with the original code.
Authors: We agree that the abstract (and, by extension, the current manuscript) does not supply the requested quantitative checks such as L2 or max-norm differences, NIST standard-problem results, or explicit tolerance thresholds for halo-exchange and all-reduce operations. The manuscript emphasizes the implementation details and reported speedups but lacks these equivalence metrics. In the revised version we will add the missing numerical verification to the results section (including the suggested norms, NIST comparisons where applicable, and communication tolerances) and revise the abstract to reference the demonstrated agreement with the single-GPU baseline. This will allow the speedups to be interpreted as evidence of functional interchangeability. revision: yes
Circularity Check
No circularity: empirical performance report with no derivations or fitted predictions
full rationale
The manuscript reports an engineering implementation (PyTorch Distributed extension of magnum.np) together with measured wall-clock speedups on concrete hardware (NVLink 8-GPU and NUMA-pinned CPU). No equations, first-principles derivations, parameter fits, or predictions appear in the provided text; the central claims are direct empirical timings rather than any quantity derived from itself by construction. Self-citations, if present, are not load-bearing for any result. This matches the default expectation that most papers contain no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
physics 20, 615–622 (2024)
Hassan, M.et al.Dipolar skyrmions and antiskyrmions of arbitrary topological charge at room temperature.Nat. physics 20, 615–622 (2024)
2024
-
[2]
A.et al.Quantification of mixed bloch-néel topological spin textures stabilized by the dzyaloshinskii-moriya interaction in co/pd multilayers.Phys
Garlow, J. A.et al.Quantification of mixed bloch-néel topological spin textures stabilized by the dzyaloshinskii-moriya interaction in co/pd multilayers.Phys. Rev. Lett.122, 237201 (2019)
2019
-
[3]
communications15, 4077 (2024)
Dion, T.et al.Ultrastrong magnon-magnon coupling and chiral spin-texture control in a dipolar 3d multilayered artificial spin-vortex ice.Nat. communications15, 4077 (2024). 5.Song, K. M.et al.Skyrmion-based artificial synapses for neuromorphic computing.Nat. Electron.3, 148–155 (2020)
2024
-
[4]
AIP Adv 4(10), 107133 (2014) https://doi.org/10.1063/1.4899186
Vansteenkiste, A. & Van de Wiele, B. Mumax: A new high-performance micromagnetic simulation tool.J. Magn. Magn. Mater.323, 2585–2591 (2011). 7.Vansteenkiste, A.et al.The design and verification of Mumax3.AIP Adv.4, 107133, DOI: 10.1063/1.4899186 (2014). 8.Donahue, M. J. & Porter, D. G. Oommf user’s guide: Version 1.0 (1999)
-
[5]
Beg, M., Lang, M. & Fangohr, H. Ubermag: Towards more effective micromagnetic workflows.IEEE Transactions on Magn.58, 1–5, DOI: 10.1109/TMAG.2021.3078896 (2022). 10.Moreels, L.et al.mumax+: extensible gpu-accelerated micromagnetics and beyond.npj Comput. Mater.12, 71 (2026)
-
[6]
& Suess, D
Bruckner, F., Koraltan, S., Abert, C. & Suess, D. magnum. np: a pytorch based gpu enhanced finite difference micromagnetic simulation framework for high level development and inverse design.Sci. Reports13, 12054 (2023)
2023
-
[7]
neural information processing systems32(2019)
Paszke, A.et al.Pytorch: An imperative style, high-performance deep learning library.Adv. neural information processing systems32(2019). 13.PyTorch. torch.compile programming model (2025)
2019
-
[8]
Abert, C.et al.Neuralmag: an open-source nodal finite-difference code for inverse micromagnetics.npj Comput. Mater. 11, 193 (2025)
2025
-
[9]
Boris computational spintronics—high performance multi-mesh magnetic and spin transport modeling software.J
Lepadatu, S. Boris computational spintronics—high performance multi-mesh magnetic and spin transport modeling software.J. Appl. Phys.128(2020). 16.Lepadatu, S. Accelerating micromagnetic and atomistic simulations using multiple gpus.J. Appl. Phys.134(2023)
2020
-
[10]
Landau, L., Lifshitz, E.et al.On the theory of the dispersion of magnetic permeability in ferromagnetic bodies.Phys. Z. Sowjetunion8, 101–114 (1935)
1935
-
[11]
Gilbert, T. L. A phenomenological theory of damping in ferromagnetic materials.IEEE transactions on magnetics40, 3443–3449 (2004). 19.Abert, C. Micromagnetics and spintronics: models and numerical methods.The Eur. Phys. J. B92, 120 (2019). 20.Slonczewski, J. C. Current-driven excitation of magnetic multilayers.J. Magn. Magn. Mater.159, L1–L7 (1996). 21.Mo...
2004
-
[12]
A thermodynamic theory of “weak” ferromagnetism of antiferromagnetics.J
Dzyaloshinsky, I. A thermodynamic theory of “weak” ferromagnetism of antiferromagnetics.J. physics chemistry solids4, 241–255 (1958)
1958
-
[13]
J., Williams, W
Newell, A. J., Williams, W. & Dunlop, D. J. A generalization of the demagnetizing tensor for nonuniform magnetization. J. Geophys. Res. Solid Earth98, 9551–9555 (1993)
1993
-
[14]
Abert, C.et al.A full-fledged micromagnetic code in fewer than 70 lines of numpy.J. Magn. Magn. Mater.387, 13–18 (2015)
2015
-
[15]
& Keyes, D
Dalcin, L., Mortensen, M. & Keyes, D. E. Fast parallel multidimensional fft using advanced mpi.J. Parallel Distributed Comput.128, 137–150 (2019). 9/10
2019
-
[16]
& Dongarra, J
Ayala, A., Tomov, S., Stoyanov, M., Haidar, A. & Dongarra, J. Performance analysis of parallel fft on large multi-gpu systems. In2022 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), 372–381 (IEEE, 2022). 27.Eicke, J. mumag standard problem 4 (2020)
2022
-
[17]
Phys.20, 113015 (2018)
Cortés-Ortuño, D.et al.Proposal for a micromagnetic standard problem for materials with dzyaloshinskii–moriya interaction.New J. Phys.20, 113015 (2018)
2018
-
[18]
& Suess, D
Heistracher, P., Abert, C., Bruckner, F., Schrefl, T. & Suess, D. Proposal for a micromagnetic standard problem: domain wall pinning at phase boundaries.J. Magn. Magn. Mater.548, 168875 (2022). 30.Intel. Technical overview of the 4th gen intel xeon scalable processor family (2022). 31.Cheng, T. C.et al.Computational study of skyrmion stability and transpo...
2022
-
[19]
materials15, 501–506 (2016)
Woo, S.et al.Observation of room-temperature magnetic skyrmions and their current-driven dynamics in ultrathin metallic ferromagnets.Nat. materials15, 501–506 (2016). 33.Joos, J. J.et al.Tutorial: Simulating modern magnetic material systems in mumax3.J. Appl. Phys.134(2023). 34.Legrand, W.et al.Hybrid chiral domain walls and skyrmions in magnetic multilay...
2016
-
[20]
https://pubs.aip.org/aip/apm/article-pdf/doi/10.1063/5
Zhang, L.et al.Direct observation of skyrmions by lorentz tem and evaluation of sot efficiency in pt/gd/co/ni laminated systems.APL Mater.13, 111112, DOI: 10.1063/5.0294523 (2025). https://pubs.aip.org/aip/apm/article-pdf/doi/10.1063/5. 0294523/20802219/111112_1_5.0294523.pdf. 10/10
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.