Towards Optimal Robustness in Learning-Augmented Paging
Pith reviewed 2026-06-28 16:00 UTC · model grok-4.3
The pith
A new framework for learning-augmented paging reaches robustness of H_k plus an additive constant.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors prove a new property of the latest H_k-competitive online paging algorithm and introduce the relative prediction budget as a unifying primitive. This primitive reveals that prior learning-augmented methods either overuse or underutilize predictions. Guided by the analysis, they build a framework whose robustness is H_k + O(1), matching the optimal online ratio up to an additive constant.
What carries the argument
The relative prediction budget primitive, which measures how much prediction information an algorithm actually consumes relative to the optimal offline solution and thereby controls the robustness bound.
If this is right
- Any future learning-augmented paging algorithm can be analyzed through the relative prediction budget to certify its robustness bound.
- The framework inherits the H_k-competitive guarantee of the underlying online algorithm when predictions are completely ignored.
- When predictions are perfect, the framework can reduce to the optimal offline cost up to lower-order terms.
- The same primitive can be applied to other paging variants without changing the robustness target.
Where Pith is reading between the lines
- The same budget accounting may extend to other online problems whose optimal competitive ratio is known, such as k-server on certain metrics.
- Practical implementations could monitor the running prediction budget in real time to decide when to trust or distrust the ML predictor.
- If the additive constant can be driven to zero by a more refined budget rule, the framework would achieve exact optimality in the learning-augmented model.
Load-bearing premise
The new property of the latest H_k-competitive algorithm holds and the relative prediction budget correctly accounts for all costs without hidden adjustments.
What would settle it
An explicit counter-example in which the new framework incurs more than H_k + C cost on some sequence whose predictions are arbitrarily bad, for any fixed constant C.
Figures

read the original abstract
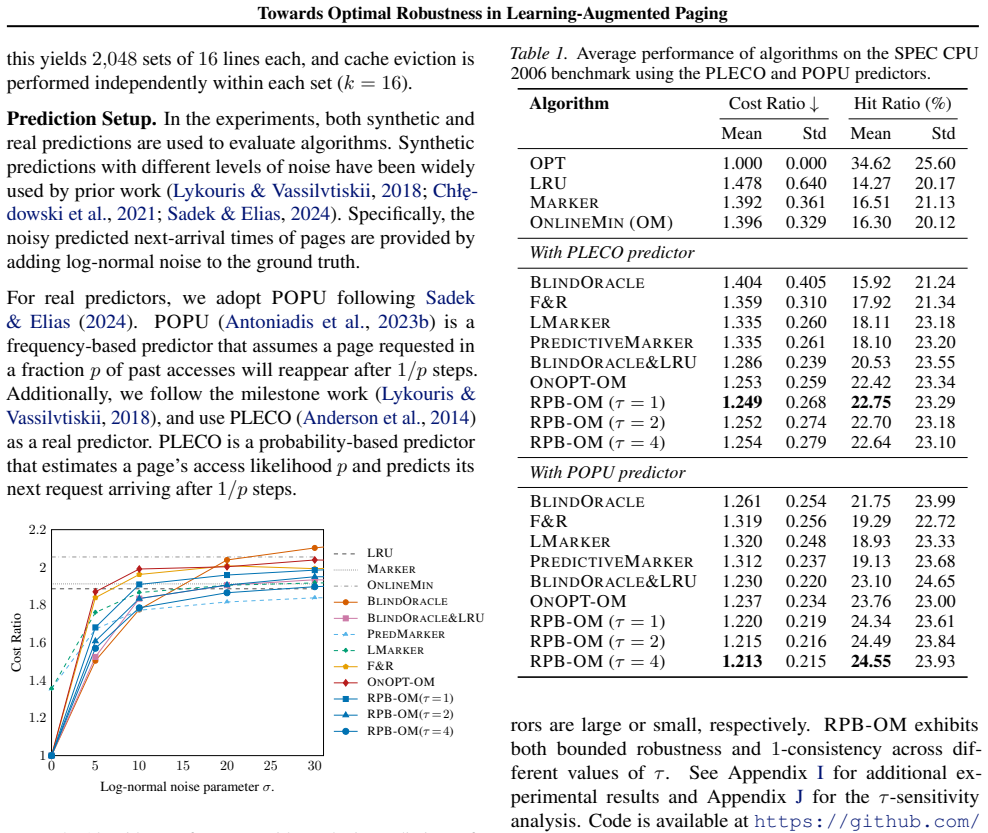
Learning-augmented paging has been extensively studied in recent years. A key advantage over naive ML-based approaches is \emph{bounded robustness}, which guarantees worst-case performance even when predictions are inaccurate, making these algorithms valuable for real-world systems. Prior work achieves robustness bounds of $2H_k + O(1)$ in the randomized setting, leaving a gap to the optimal competitive ratio $H_k$. In this paper, we study how to close this gap. We begin by reviewing online optimality and proving a new property of the latest $H_k$-competitive algorithm, which facilitates our analysis in the learning-augmented setting. Then, we review existing learning-augmented paging algorithms and introduce a unifying primitive, the \emph{relative prediction budget}, which captures the essence of establishing robustness and reveals that prior algorithms either overuse or underutilize predictions. Guided by the above analysis, we develop a new framework that achieves the best-possible robustness up to an additive constant for learning-augmented paging: $H_k + O(1)$. Experiments further demonstrate strong practical performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to close the gap in learning-augmented paging from prior robustness of 2H_k + O(1) to the best-possible H_k + O(1) (up to additive constant) in the randomized setting. It does so by proving a new property of the latest H_k-competitive online paging algorithm, introducing the relative prediction budget as a unifying primitive that captures prediction usage and reveals overuse/underutilization in prior algorithms, and developing a new framework guided by this analysis. Experiments are cited to show strong practical performance.
Significance. If the bound holds, the result is significant: it achieves robustness matching the optimal competitive ratio H_k up to O(1), a conceptual advance over prior work. The relative prediction budget primitive provides a new unifying lens for analyzing prediction budgets in online algorithms and could extend to other learning-augmented problems. The paper explicitly credits the new property and primitive for enabling the improvement.
major comments (2)
- [Section reviewing online optimality and proving a new property of the latest H_k-competitive algorithm] The section reviewing online optimality and proving a new property of the latest H_k-competitive algorithm: this property is load-bearing for the central H_k + O(1) claim, as the abstract states it 'facilitates our analysis in the learning-augmented setting'; the manuscript must explicitly state the property and show how it enables the bound without circularity or additional assumptions.
- [Section introducing the relative prediction budget primitive] The section introducing the relative prediction budget primitive: the claim that this primitive 'unifies and improves upon all prior learning-augmented methods without introducing hidden costs or post-hoc adjustments' is load-bearing for achieving H_k + O(1) rather than 2H_k + O(1); the manuscript must provide explicit comparisons demonstrating unification and the absence of hidden costs.
minor comments (1)
- The abstract states that 'experiments further demonstrate strong practical performance' but provides no details on methodology, baselines, or metrics; this should be expanded in the main text for clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for identifying the load-bearing elements of our claims. We address each major comment below and will revise the manuscript to improve explicitness and clarity.
read point-by-point responses
-
Referee: [Section reviewing online optimality and proving a new property of the latest H_k-competitive algorithm] The section reviewing online optimality and proving a new property of the latest H_k-competitive algorithm: this property is load-bearing for the central H_k + O(1) claim, as the abstract states it 'facilitates our analysis in the learning-augmented setting'; the manuscript must explicitly state the property and show how it enables the bound without circularity or additional assumptions.
Authors: We agree that the new property must be stated with maximal clarity. The property is proved independently in the online setting before any learning-augmented analysis is introduced. In the revision we will add an explicit boxed statement of the property together with a short dedicated paragraph that traces, step by step and without circularity, how the property is invoked to obtain the H_k + O(1) robustness bound. revision: yes
-
Referee: [Section introducing the relative prediction budget primitive] The section introducing the relative prediction budget primitive: the claim that this primitive 'unifies and improves upon all prior learning-augmented methods without introducing hidden costs or post-hoc adjustments' is load-bearing for achieving H_k + O(1) rather than 2H_k + O(1); the manuscript must provide explicit comparisons demonstrating unification and the absence of hidden costs.
Authors: The manuscript already reviews prior algorithms and uses the relative prediction budget to expose their overuse or underutilization of predictions. To make the unification and lack of hidden costs fully explicit, we will insert a concise comparison table (or subsection) that directly juxtaposes the prediction-budget accounting of each prior method against our framework, confirming that no post-hoc adjustments are required. revision: yes
Circularity Check
Derivation self-contained via new proofs and primitive
full rationale
The paper's central claim of H_k + O(1) robustness rests on two explicitly new contributions: a proved property of the latest H_k-competitive online paging algorithm and the introduction of the relative prediction budget primitive that unifies prior methods. These are presented as original analysis steps that close the gap from 2H_k + O(1), with no reduction to fitted inputs, self-citation chains, or renamed known results. The abstract and structure indicate an independent derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math The optimal randomized competitive ratio for paging is H_k.
invented entities (1)
-
relative prediction budget
no independent evidence
Reference graph
Works this paper leans on
-
[1]
URL https://proceedings.mlr.press/ v139/chledowski21a.html. Cho, E., Myers, S. A., and Leskovec, J. Friendship and mobility: user movement in location-based so- cial networks. InProceedings of the 17th ACM SIGKDD International Conference on Knowledge Dis- covery and Data Mining, KDD ’11, pp. 1082–1090, New York, NY , USA, 2011. Association for Comput- ing...
-
[2]
Daneshvaramoli, M., Karisani, H., Lechowicz, A., Sun, B., Musco, C
URLhttps://crc2.ece.tamu.edu/. Daneshvaramoli, M., Karisani, H., Lechowicz, A., Sun, B., Musco, C. N., and Hajiesmaili, M. Near-optimal consistency-robustness trade-offs for learning-augmented online knapsack problems. In Singh, A., Fazel, M., Hsu, D., Lacoste-Julien, S., Berkenkamp, F., Maharaj, T., Wagstaff, K., and Zhu, J. (eds.),Proceedings of the 42n...
-
[3]
DePavia, A
URL https://proceedings.mlr.press/ v267/daneshvaramoli25a.html. DePavia, A. F., Tani, E., and Vakilian, A. Learning-based algorithms for graph searching problems. InInternational Conference on Artificial Intelligence and Statistics, pp. 928–936. PMLR, 2024. 10 Towards Optimal Robustness in Learning-Augmented Paging Drygala, M., Nagarajan, S. G., and Svens...
2024
-
[4]
PMLR, 2023. Fiat, A., Karp, R. M., Luby, M., McGeoch, L. A., Sleator, D. D., and Young, N. E. Competitive paging algorithms. Journal of Algorithms, 12(4):685–699, 1991. He, H.-Y . and Li, M. Learning-augmented smooth integer programs with pac-learnable oracles, 2026. URLhttps: //arxiv.org/abs/2602.02505. Im, S., Kumar, R., Montazer Qaem, M., and Purohit, ...
-
[5]
McGeoch, L
URL https://proceedings.mlr.press/ v80/lykouris18a.html. McGeoch, L. A. and Sleator, D. D. A strongly competitive randomized paging algorithm.Algorithmica, 6(1):816– 825, 1991. Mitzenmacher, M. A model for learned bloom filters and op- timizing by sandwiching.Advances in neural information processing systems, 31, 2018. Moruz, G. and Negoescu, A. Outperfor...
1991
-
[6]
URL https://openreview.net/forum? id=QuIiLSktO4. Sleator, D. D. and Tarjan, R. E. Amortized efficiency of list update and paging rules.Communications of the ACM, 28(2):202–208, 1985. Vietri, G., Rodriguez, L. V ., Martinez, W. A., Lyons, S., Liu, J., Rangaswami, R., Zhao, M., and Narasimhan, G. Driving cache replacement with {ML-based}{LeCaR}. In10th USEN...
-
[7]
Ifp∈L 0, the update depends on the support size: (L0\{p}, L1, ..., Lk−1 ∪L k,{p})if|S(ω)|<3k, (L0\{p} ∪L 1, L2, ..., Lk,{p})if|S(ω)|= 3k
-
[8]
Ifp∈L i, i >0, the update is the same as EQUITABLE. The intuition is that a large support indicates that the adversary has already deviated from the worst-case behavior, creating slack between the realized ratio and the worst-case bound of Hk. Since future requests cannot recover this slack, the online algorithm can safely deviate from the exact layer upd...
2024
-
[9]
Instead, it evicts an arbitrary page in C∩Q j
ONOPT does not follow OM’s priorities. Instead, it evicts an arbitrary page in C∩Q j. Since the evicted page may or may not belong toC ∗, we have∆D≤0
-
[10]
Below, we prove that the evicted page q satisfies q /∈C∗, which implies ∆D=−1
ONOPT follows OM’s priorities. Below, we prove that the evicted page q satisfies q /∈C∗, which implies ∆D=−1 . In this case, ONOPT evicts q= arg min x∈C∩Q j π(x),(9) whereπ(x)denotes the priority ofxassigned by OM. Letq∈L b, whereb≤j. Define h= max{0≤l < b:|C ∗ ∩Q l|=l}, where Q0 =∅ . Thus Qh is the last prefix before q’s layer that is saturated byC ∗, an...
-
[11]
Instead, it evicts an arbitrary page in C∩Q j
ONOPT does not follow OM’s priorities. Instead, it evicts an arbitrary page in C∩Q j. Since this page may or may not belong toC ∗, and OM may or may not evict a page belonging toC, we have∆D≤1
-
[12]
Let C ′ and C ∗′ be the cache configurations of ONOPT and OM after serving p, respectively
ONOPT follows OM’s priorities. Let C ′ and C ∗′ be the cache configurations of ONOPT and OM after serving p, respectively. Below, we prove that the evicted pageqsatisfiesq /∈C ∗′. In this case, ONOPT evicts q= arg min x∈C∩Q j π(x), 14 Towards Optimal Robustness in Learning-Augmented Paging yielding C ′ =C\ {q} ∪ {p} . Meanwhile, OM also loads p. By Defini...
2015
-
[13]
Thus, there existsy∈N(ω)such that Pr[y /∈C(ω)]≥ |N(ω)| −1 |N(ω)| ≥ U(ω) U(ω) + 1 ≥ 1 2 , where |N(ω)| ≥U(ω) + 1 = 2 , as otherwise all pages in N(ω) are revealed
For the base caseU(ω) = 1, only one page inN(ω)exists inC(ω). Thus, there existsy∈N(ω)such that Pr[y /∈C(ω)]≥ |N(ω)| −1 |N(ω)| ≥ U(ω) U(ω) + 1 ≥ 1 2 , where |N(ω)| ≥U(ω) + 1 = 2 , as otherwise all pages in N(ω) are revealed. Moreover ϕ(ωp) =ϕ(ω y) = 0 , as U(ω p) =U(ω y) = 0. Combining with (12), ∆ϕ=ϕ(ω p)−ϕ(ω) =ϕ(ω y)−ϕ(ω) =−Pr[y /∈C(ω)]≤ −1/2
-
[14]
Let Mtotal(ω) denote the total miss probability mass over unrevealed pages
Now we consider the caseU(ω)>1, assuming that the lemma holds for anyω ′ withU(ω ′) =U(ω)−1. Let Mtotal(ω) denote the total miss probability mass over unrevealed pages. Since all pages in R(ω) reside in the cache, exactlyU(ω)pages inN(ω)exist inC(ω), and Mtotal(ω) = X x∈N(ω) Pr[x /∈C(ω)] =|N(ω)| −U(ω). After servingp, Mtotal(ωp) = X x∈N(ω p) Pr[x /∈C(ωp)]...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.