Everywhere Learning: Artificial Intelligence with Pointwise Constraints
Pith reviewed 2026-06-28 15:32 UTC · model grok-4.3
The pith
Everywhere learning trains AI to satisfy loss constraints with probability one over the data distribution rather than minimizing average loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
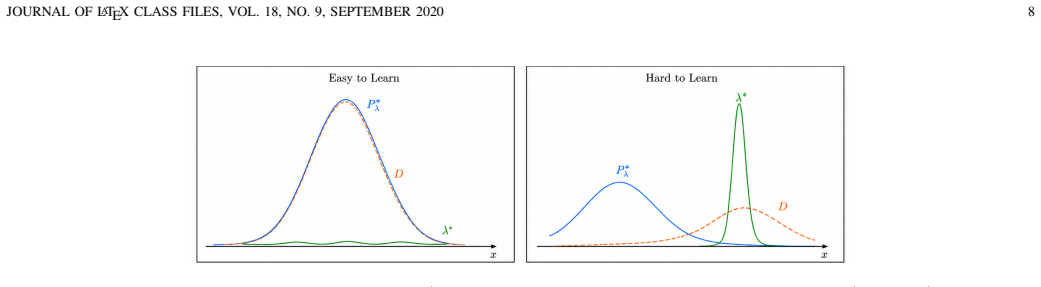
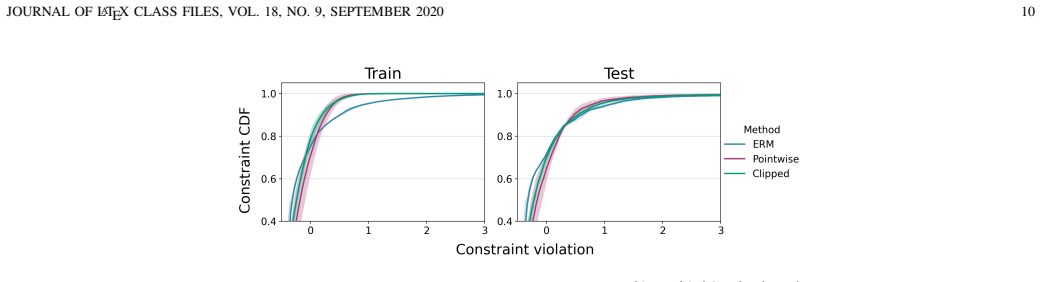
We develop an approximate duality theory to substantiate a generalization analysis that establishes the proximity between solutions of empirical and statistical everywhere learning problems. Our results show that dual variables reweigh the data distribution towards points in which loss constraints are more difficult to satisfy and that generalization is controlled by the mismatch between the concentration of mass of the data distribution and the concentration of mass on points where constraints are more difficult to satisfy. We further show that we can control generalization with a sparse L1 penalty on constraint relaxations.
What carries the argument
Approximate duality theory whose dual variables reweight the data distribution toward points where loss constraints are hardest to satisfy.
If this is right
- Dual variables reweigh the data distribution toward points where loss constraints are more difficult to satisfy.
- Generalization is controlled by the mismatch between the concentration of mass of the data distribution and the concentration on difficult points.
- A sparse L1 penalty on constraint relaxations controls generalization.
- Empirical and statistical everywhere learning solutions remain proximate under the duality theory.
Where Pith is reading between the lines
- The reweighting view may connect everywhere learning to existing robust optimization methods that emphasize tail behavior.
- The L1 penalty mechanism could be tested on sequential decision tasks where constraint violations accumulate over time.
- Extending the duality approximation to non-convex losses would clarify whether the proximity result survives in modern deep models.
- The concentration-mismatch view suggests that everywhere learning may be easier to apply when data distributions are already somewhat uniform.
Load-bearing premise
The approximate duality theory holds and produces meaningful reweighting that controls generalization via concentration mismatch.
What would settle it
A numerical experiment in which the empirical everywhere learning solution diverges substantially from the statistical solution even after applying the duality-based reweighting.
Figures
read the original abstract
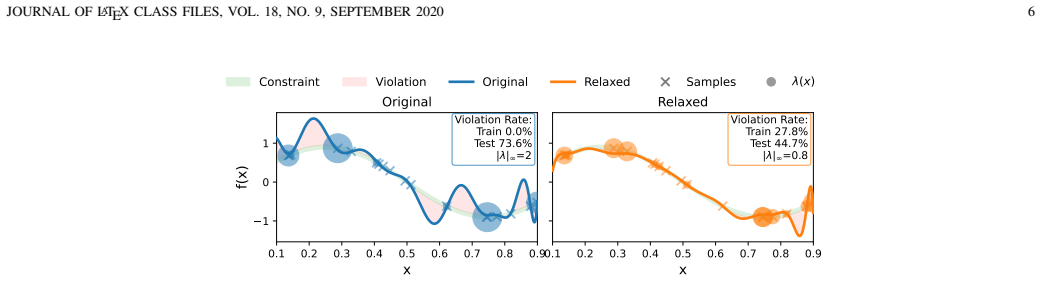
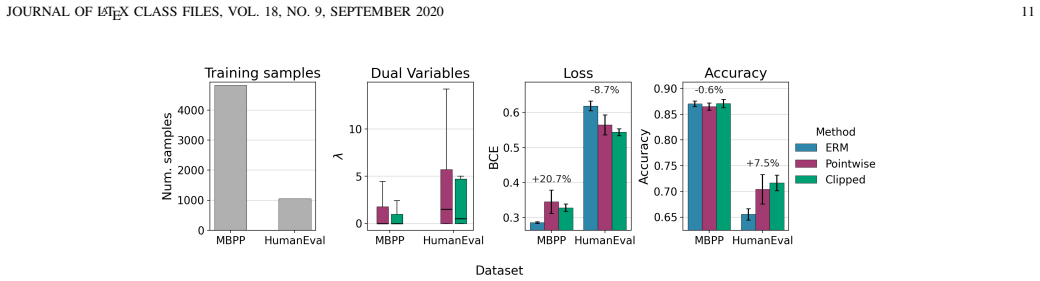
Everywhere learning is a new paradigm whereby Artificial Intelligence (AI) systems are trained to satisfy loss constraints with probability one over the data distribution. This is in contrast to the standard paradigm of training AI systems to minimize average losses. We develop an approximate duality theory to substantiate a generalization analysis that establishes the proximity between solutions of empirical and statistical everywhere learning problems. Our results show that dual variables reweigh the data distribution towards points in which loss constraints are more difficult to satisfy and that generalization is controlled by the mismatch between the concentration of mass of the data distribution and the concentration of mass on points where constraints are more difficult to satisfy. We further show that we can control generalization with a sparse L1 penalty on constraint relaxations. We illustrate the merits of everywhere learning with an experiment in agentic classification for language model tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces 'everywhere learning,' a paradigm in which AI systems are trained to satisfy loss constraints with probability one over the data distribution, in contrast to minimizing average losses. It develops an approximate duality theory to support a generalization analysis establishing proximity between solutions of empirical and statistical everywhere learning problems. Dual variables are claimed to reweight the data distribution toward points where constraints are harder to satisfy, with generalization controlled by the mismatch in concentration of mass between the data distribution and difficult points; a sparse L1 penalty on constraint relaxations is proposed to control generalization. The approach is illustrated via an experiment on agentic classification for language model tasks.
Significance. If the approximate duality theory holds with valid approximation conditions and produces non-vacuous generalization bounds, the framework could provide a distinct approach to enforcing strict pointwise constraints in machine learning, potentially benefiting robustness in sequential decision-making tasks such as language model agents. The reweighting interpretation and L1 penalty mechanism would offer interpretable levers for generalization that differ from standard empirical risk minimization.
major comments (2)
- [Abstract (duality theory claim)] The approximate duality theory is presented as the foundation for the generalization analysis that establishes proximity between empirical and statistical everywhere learning problems, yet no derivation, approximation error bounds, or conditions for validity are supplied; this is load-bearing for all subsequent claims about dual-variable reweighting and concentration mismatch.
- [Abstract (generalization analysis)] The statement that 'generalization is controlled by the mismatch between the concentration of mass of the data distribution and the concentration of mass on points where constraints are more difficult to satisfy' depends on the un-derived duality theory; without explicit conditions or a proof sketch, it is impossible to determine whether the bound is meaningful or reduces to a tautology.
minor comments (1)
- [Abstract (experiment)] The abstract references an experiment in agentic classification but supplies no details on task definition, baselines, metrics, or quantitative results, which would be needed to evaluate whether the merits are demonstrated.
Simulated Author's Rebuttal
We thank the referee for their careful reading and for highlighting the centrality of the approximate duality theory. The comments correctly identify that the current manuscript does not supply the requested derivation, bounds, or validity conditions. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract (duality theory claim)] The approximate duality theory is presented as the foundation for the generalization analysis that establishes proximity between empirical and statistical everywhere learning problems, yet no derivation, approximation error bounds, or conditions for validity are supplied; this is load-bearing for all subsequent claims about dual-variable reweighting and concentration mismatch.
Authors: We agree that the abstract states the existence of an approximate duality theory without supplying its derivation, error bounds, or validity conditions. This omission weakens the foundation for the subsequent claims. In the revised version we will (i) add a concise statement of the approximation conditions and error bounds to the abstract and (ii) include an explicit derivation together with the required bounds in the main text. revision: yes
-
Referee: [Abstract (generalization analysis)] The statement that 'generalization is controlled by the mismatch between the concentration of mass of the data distribution and the concentration of mass on points where constraints are more difficult to satisfy' depends on the un-derived duality theory; without explicit conditions or a proof sketch, it is impossible to determine whether the bound is meaningful or reduces to a tautology.
Authors: We concur that the generalization claim rests on the un-derived duality result and that, absent conditions or a sketch, its status cannot be assessed. The revision will incorporate the missing derivation and a proof sketch of the generalization bound, together with the explicit conditions under which the bound is non-vacuous. revision: yes
Circularity Check
No significant circularity; derivation self-contained against external benchmarks
full rationale
The abstract outlines an approximate duality theory supporting generalization bounds between empirical and statistical everywhere learning problems, with dual variables reweighting data toward difficult constraints and control via concentration mismatch or L1 penalty. No equations, self-citations, or fitted inputs are presented that reduce the claimed results to definitions or prior author work by construction. The provided text contains no load-bearing steps matching the enumerated circularity patterns, and the central claims rest on the development of the duality theory rather than renaming or self-referential fitting. Absent explicit derivations in the supplied abstract, the analysis is treated as independent.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cam- bridge university press, 2014
Shai Shalev-Shwartz and Shai Ben-David.Understand- ing machine learning: From theory to algorithms. Cam- bridge university press, 2014
2014
-
[2]
Springer Berlin Hei- delberg, Berlin, Heidelberg, 2008
Theodor Stewart, Oliver Bandte, Heinrich Braun, Niru- pam Chakraborti, Matthias Ehrgott, Mathias G ¨obelt, Yaochu Jin, Hirotaka Nakayama, Silvia Poles, and Danilo Di Stefano.Real-World Applications of Multiobjective Optimization, pages 285–327. Springer Berlin Hei- delberg, Berlin, Heidelberg, 2008. ISBN 978-3-540- 88908-3. doi: 10.1007/978-3-540-88908-3 ...
-
[3]
Amir R. Zamir, Alexander Sax, Teresa Yeo, Oguzhan Fatih Kar, Nikhil Cheerla, Rohan Suri, Zhangjie Cao, Jitendra Malik, and Leonidas J. Guibas. Robust learning through cross-task consistency.CoRR, abs/2006.04096, 2020. URL https://arxiv.org/abs/2006.04096
arXiv 2006
-
[4]
A pareto-efficient algorithm for multiple objective optimization in e-commerce recommendation
Xiao Lin, Hongjie Chen, Changhua Pei, Fei Sun, Xuanji Xiao, Hanxiao Sun, Yongfeng Zhang, Wenwu Ou, and Peng Jiang. A pareto-efficient algorithm for multiple objective optimization in e-commerce recommendation. InProceedings of the 13th ACM Conference on Recom- mender Systems, RecSys ’19, page 20–28, New York, NY , USA, 2019. Association for Computing Mach...
-
[5]
Multi-task learning as multi-objective optimization.Advances in neural information processing systems, 31, 2018
Ozan Sener and Vladlen Koltun. Multi-task learning as multi-objective optimization.Advances in neural information processing systems, 31, 2018
2018
-
[6]
A survey on multi-task learning.IEEE transactions on knowledge and data engineering, 34(12):5586–5609, 2021
Yu Zhang and Qiang Yang. A survey on multi-task learning.IEEE transactions on knowledge and data engineering, 34(12):5586–5609, 2021
2021
-
[7]
Agnostic learning with multiple objectives
Corinna Cortes, Mehryar Mohri, Javier Gonzalvo, and Dmitry Storcheus. Agnostic learning with multiple objectives. InAdvances in Neural Information Processing Systems, volume 33, pages 20485–20495. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/paper files/paper/2020/ file/ebea2325dc670423afe9a1f4d9d1aef5-Paper.pdf
2020
-
[8]
Timo M. Deist, Monika Grewal, Frank J. W. M. Dankers, Tanja Alderliesten, and Peter A. N. Bosman. Multi- objective learning to predict pareto fronts using hypervol- ume maximization.CoRR, abs/2102.04523, 2021. URL https://arxiv.org/abs/2102.04523
arXiv 2021
-
[9]
Multi-task learning with deep neural networks: A survey.CoRR, abs/2009.09796, 2020
Michael Crawshaw. Multi-task learning with deep neural networks: A survey.CoRR, abs/2009.09796, 2020. URL https://arxiv.org/abs/2009.09796
arXiv 2009
-
[10]
Alignment of large language models with constrained learning, 2025
Botong Zhang, Shuo Li, Ignacio Hounie, Osbert Bastani, Dongsheng Ding, and Alejandro Ribeiro. Alignment of large language models with constrained learning, 2025. URL https://arxiv.org/abs/2505.19387
arXiv 2025
-
[11]
Learning with complex loss functions and constraints
Harikrishna Narasimhan. Learning with complex loss functions and constraints. InProceedings of the Twenty-First International Conference on Artificial In- telligence and Statistics, volume 84 ofProceedings of Machine Learning Research, pages 1646–1654. PMLR, 09–11 Apr 2018. URL https://proceedings.mlr.press/v84/ narasimhan18a.html
2018
-
[12]
Composition and alignment of diffusion models using constrained learning
Shervin Khalafi, Ignacio Hounie, Dongsheng Ding, and Alejandro Ribeiro. Composition and alignment of diffusion models using constrained learning. InAdvances in Neural Information Processing Systems, volume 38, pages 18629– 18676. Curran Associates, Inc., 2025. URL https: //proceedings.neurips.cc/paper files/paper/2025/file/ 1af991de2d4c4e679bcc5d9e23ac6ba...
2025
-
[13]
Constrained learning with non-convex losses.IEEE Transactions on Infor- mation Theory, 69(3):1739–1760, 2022
Luiz FO Chamon, Santiago Paternain, Miguel Calvo- Fullana, and Alejandro Ribeiro. Constrained learning with non-convex losses.IEEE Transactions on Infor- mation Theory, 69(3):1739–1760, 2022
2022
-
[14]
Juan Elenter, Luiz F. O. Chamon, and Alejandro Ribeiro. Near-optimal solutions of constrained learning problems,
-
[15]
URL https://arxiv.org/abs/2403.11844
-
[16]
Springer: New York, 1999
Vladimir Vapnik.The Nature of Statistical Learning Theory. Springer: New York, 1999
1999
-
[17]
Learning optimal power flow with pointwise constraints, 2025
Damian Owerko, Anna Scaglione, and Alejandro Ribeiro. Learning optimal power flow with pointwise constraints, 2025. URL https://arxiv.org/abs/2510.20777
arXiv 2025
-
[18]
Feasible learning,
Juan Ramirez, Ignacio Hounie, Juan Elenter, Jose Gallego-Posada, Meraj Hashemizadeh, Alejandro Ribeiro, and Simon Lacoste-Julien. Feasible learning,
-
[19]
URL https://arxiv.org/abs/2501.14912
-
[20]
Luiz F. O. Chamon and Alejandro Ribeiro. Probably approximately correct constrained learning, 2021. URL https://arxiv.org/abs/2006.05487
arXiv 2021
-
[21]
Ben-Tal, L.E
A. Ben-Tal, L.E. Ghaoui, and A. Nemirovski.Robust Optimization. Princeton Series in Applied Mathematics. Princeton University Press, 2009. ISBN 9781400831050. URL https://books.google.com/books?id=DttjR7IpjUEC
2009
-
[22]
Brown, and Constantine Caramanis
Dimitris Bertsimas, David B. Brown, and Constantine Caramanis. Theory and applications of robust optimiza- tion, 2010. URL https://arxiv.org/abs/1010.5445
Pith/arXiv arXiv 2010
-
[23]
Robust opti- mization using machine learning for uncertainty sets,
Theja Tulabandhula and Cynthia Rudin. Robust opti- mization using machine learning for uncertainty sets,
-
[24]
URL https://arxiv.org/abs/1407.1097
-
[25]
Chance- constrained programming.Management science, 6(1): 73–79, 1959
Abraham Charnes and William W Cooper. Chance- constrained programming.Management science, 6(1): 73–79, 1959
1959
-
[26]
Society for Indus- trial and Applied Mathematics, Philadelphia, PA, 2021
Alexander Shapiro, Darinka Dentcheva, and Andrzej Ruszczynski.Lectures on Stochastic Programming: Modeling and Theory, Third Edition. Society for Indus- trial and Applied Mathematics, Philadelphia, PA, 2021. doi: 10.1137/1.9781611976595. URL https://epubs.siam. org/doi/abs/10.1137/1.9781611976595
-
[27]
Dionysis Kalogerias and Spyridon Pougkakiotis. Strong duality in risk-constrained nonconvex functional pro- gramming.arXiv preprint arXiv:2206.11948, 2022
arXiv 2022
-
[28]
Marco C. Campi and Simone Garatti.Introduction to the Scenario Approach. Society for Industrial and Applied Mathematics, Philadelphia, PA, 2018. doi: 10.1137/1. 9781611975444. URL https://epubs.siam.org/doi/abs/10. 1137/1.9781611975444
work page doi:10.1137/1 2018
-
[29]
Arkadi Nemirovski and Alexander Shapiro.Scenario Approximations of Chance Constraints, pages 3–47. Springer London, London, 2006. ISBN 978-1-84628- 095-5. doi: 10.1007/1-84628-095-8 1. URL https: //doi.org/10.1007/1-84628-095-8 1
-
[30]
Henderson
Sujin Kim, Raghu Pasupathy, and Shane G. Henderson. A guide to sample average approximation. 2015. URL https://api.semanticscholar.org/CorpusID:17021796
2015
-
[31]
James Luedtke and Shabbir Ahmed. A sample ap- proximation approach for optimization with probabilistic constraints.SIAM Journal on Optimization, 19(2):674– 699, 2008. doi: 10.1137/070702928. URL https://doi. org/10.1137/070702928
-
[32]
Generalization bounds for stochastic saddle point problems, 2020
Junyu Zhang, Mingyi Hong, Mengdi Wang, and Shuzhong Zhang. Generalization bounds for stochastic saddle point problems, 2020. URL https://arxiv.org/abs/ 2006.02067
arXiv 2020
-
[33]
What is a good metric to study gen- eralization of minimax learners?, 2022
Asuman Ozdaglar, Sarath Pattathil, Jiawei Zhang, and Kaiqing Zhang. What is a good metric to study gen- eralization of minimax learners?, 2022. URL https: //arxiv.org/abs/2206.04502
arXiv 2022
-
[34]
Train simulta- neously, generalize better: Stability of gradient-based minimax learners, 2020
Farzan Farnia and Asuman Ozdaglar. Train simulta- neously, generalize better: Stability of gradient-based minimax learners, 2020. URL https://arxiv.org/abs/2010. 12561
2020
-
[35]
Why l1 is a good approximation to l0: A geometric JOURNAL OF LATEX CLASS FILES, VOL
Carlos Ramirez, Vladik Kreinovich, and Miguel Argaez. Why l1 is a good approximation to l0: A geometric JOURNAL OF LATEX CLASS FILES, VOL. 18, NO. 9, SEPTEMBER 2020 13 explanation. 2013
2020
-
[36]
Functional nonlinear sparse models.IEEE Transactions on Signal Processing, 68:2449–2463, 2020
Luiz FO Chamon, Yonina C Eldar, and Alejandro Ribeiro. Functional nonlinear sparse models.IEEE Transactions on Signal Processing, 68:2449–2463, 2020
2020
-
[37]
Boyd and L
S.P. Boyd and L. Vandenberghe.Convex Opti- mization. Number pt. 1 in Berichte ¨uber verteilte messysteme. Cambridge University Press, 2004. ISBN 9780521833783. URL https://books.google.com/books? id=mYm0bLd3fcoC
2004
-
[38]
Multilayer feedforward networks are universal approxi- mators.Neural networks, 2(5):359–366, 1989
Kurt Hornik, Maxwell Stinchcombe, and Halbert White. Multilayer feedforward networks are universal approxi- mators.Neural networks, 2(5):359–366, 1989
1989
-
[39]
Gnns as predictors of agentic workflow performances.arXiv preprint arXiv:2503.11301, 2025
Yuanshuo Zhang, Yuchen Hou, Bohan Tang, Shuo Chen, Muhan Zhang, Xiaowen Dong, and Siheng Chen. Gnns as predictors of agentic workflow performances.arXiv preprint arXiv:2503.11301, 2025
arXiv 2025
-
[40]
Evaluating large language models trained on code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021
Pith/arXiv arXiv 2021
-
[41]
Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
Pith/arXiv arXiv 2021
-
[42]
Aflow: Au- tomating agentic workflow generation.arXiv preprint arXiv:2410.10762, 2024
Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, Xionghui Chen, Jiaqi Chen, Mingchen Zhuge, Xin Cheng, Sirui Hong, Jinlin Wang, et al. Aflow: Au- tomating agentic workflow generation.arXiv preprint arXiv:2410.10762, 2024
Pith/arXiv arXiv 2024
-
[43]
Springer, 1991
Michel Ledoux and Michel Talagrand.Probability in Banach Spaces: isoperimetry and processes, volume 23. Springer, 1991
1991
-
[44]
Springer Science & Business Media, 3rd edition, 2006
Charalambos D Aliprantis and Kim C Border.Infinite Dimensional Analysis: A Hitchhiker’s Guide. Springer Science & Business Media, 3rd edition, 2006
2006
-
[45]
Bertsekas.Convex Optimization Theory
D. Bertsekas.Convex Optimization Theory. Athena Scientific optimization and computation series. Athena Scientific, 2009. ISBN 9781886529311. URL https: //books.google.com/books?id=lC1EEAAAQBAJ. JOURNAL OF LATEX CLASS FILES, VOL. 18, NO. 9, SEPTEMBER 2020 14 APPENDIXA RADAMACHERCOMPLEXITY ANDUCRATE DERIVATION In Assumption 1 we assume the existence of an u...
2009
-
[46]
Probably approximately supra-optimal: E(x,y)∼D ℓ0(fθ(x), y) ≤P ⋆ + 2ζ0(N, δ),(55)
-
[47]
1 N sup fθ∈H NX i=1 σig(zi)ℓ(fθ, zi) # (96) =E σ
Probably approximately feasible: P r ℓ(fθ(x),y)≤c i ≥1−ζ I(N, δ).(56) Proof.Feasibility. We first prove that ˆfθ is feasible for ˆP. Suppose it is not; then ˆP=∞. ButP≤ ∞imply that ∃fθ feasible for P. As the constraint holdsD−a.e.,f θ must be feasible for ˆP. Combined with the boundedness ofℓ 0 it implies thatf θ is a feasible point with bounded objective...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.