Polaris: Scaling Up Instruction-Guided Image Generation Towards Millions of Personalized Style Needs
Pith reviewed 2026-06-28 15:04 UTC · model grok-4.3
The pith
Polaris retrieves from 6500 checkpoints and 75000 adapters to generate personalized images matching user instructions without new training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
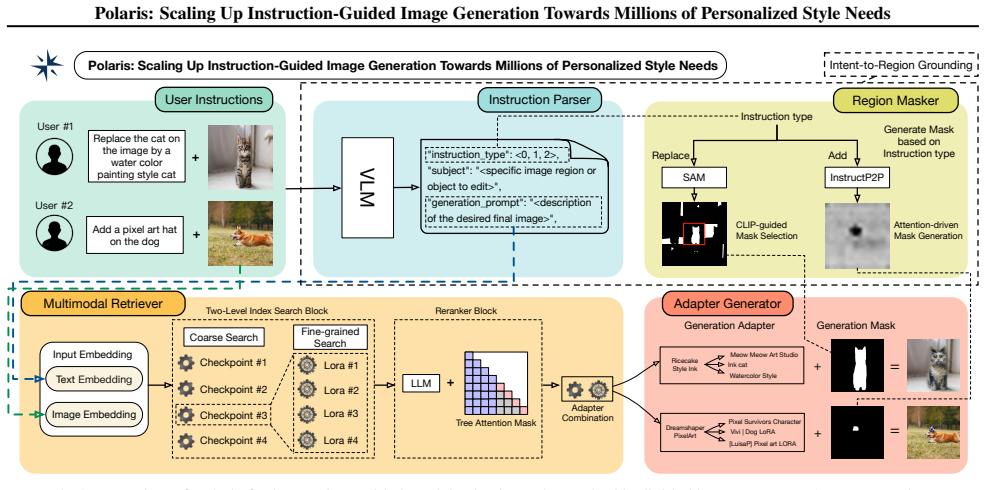
Polaris is an intelligent retrieval framework that automatically selects and integrates suitable models from the model library based on a user's instructions. The key insight is that harnessing such a massive and heterogeneous pool requires not only finding the most relevant modules among thousands of candidates, but also aligning them effectively for instruction-driven generation and editing. Polaris addresses this challenge by indexing over 6,500 checkpoints and 75,000 adapters, and retrieving the most relevant components given a user's input and instruction. In doing so, it delivers scalable, controllable, and well-aligned generation without any additional training.
What carries the argument
The retrieval framework that indexes and selects relevant pre-trained checkpoints and adapters from a heterogeneous library to match user instructions for image generation and editing.
If this is right
- Users obtain personalized image generation for diverse requirements without incurring the cost of fine-tuning new models for each case.
- The growing library of fine-tuned modules and adapters can be systematically exploited rather than training fresh models repeatedly.
- Generation remains scalable and controllable while staying well-aligned with the given instructions.
- New personalized style needs can be addressed by retrieval from the existing pool instead of additional training.
Where Pith is reading between the lines
- Larger libraries could eventually cover an even wider range of user instructions as more modules are added over time.
- The same retrieval idea might reduce the need for task-specific training in other generative domains.
- Effective combination of retrieved modules could produce results that exceed the capabilities of any single component in the library.
Load-bearing premise
A retrieval mechanism can reliably identify and combine heterogeneous pre-trained modules to satisfy arbitrary user instructions without any fine-tuning or additional training steps.
What would settle it
A user instruction for a specific novel style where the retrieved modules produce outputs that fail to match the requested characteristics, even when the library contains components trained on related styles.
Figures



read the original abstract
Users increasingly expect image generation models to quickly adapt to highly diverse and personalized requirements, such as producing images with distinctive styles or characteristics. Traditional approaches rely on fine-tuning, which is costly and difficult to scale. To cope with these limitations, the community has accumulated a growing library of fine-tuned modules and adapters, where each component targets specific generation needs and collectively serves as a foundation for handling new demands. This naturally raises a question: instead of repeatedly training new models, can we systematically exploit this expanding ecosystem to better fulfill user instructions? To this end, we present Polaris, an intelligent retrieval framework that automatically selects and integrates suitable models from the model library based on a user's instructions. The key insight is that harnessing such a massive and heterogeneous pool requires not only finding the most relevant modules among thousands of candidates, but also aligning them effectively for instruction-driven generation and editing. Polaris addresses this challenge by indexing over 6,500 checkpoints and 75,000 adapters, and retrieving the most relevant components given a user's input and instruction. In doing so, it delivers scalable, controllable, and well-aligned generation -- without any additional training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Polaris, a retrieval framework that indexes over 6,500 checkpoints and 75,000 adapters and automatically selects and integrates the most relevant components to fulfill arbitrary user instructions for image generation and editing, claiming to deliver scalable, controllable, and well-aligned outputs without any additional training or fine-tuning.
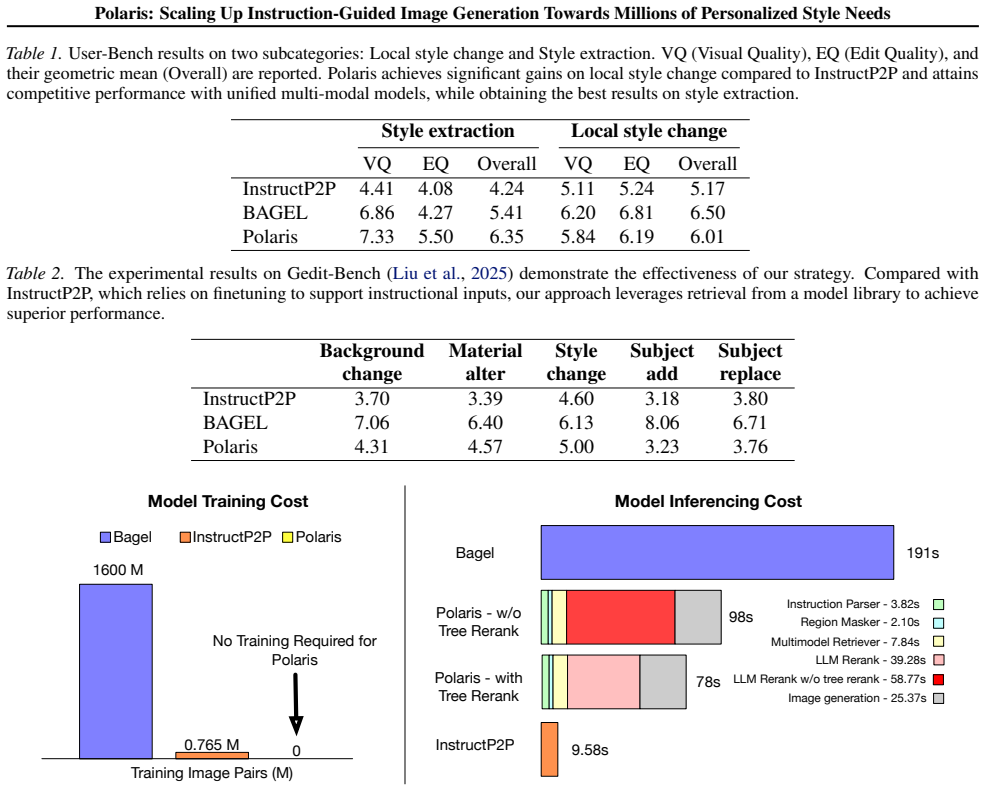
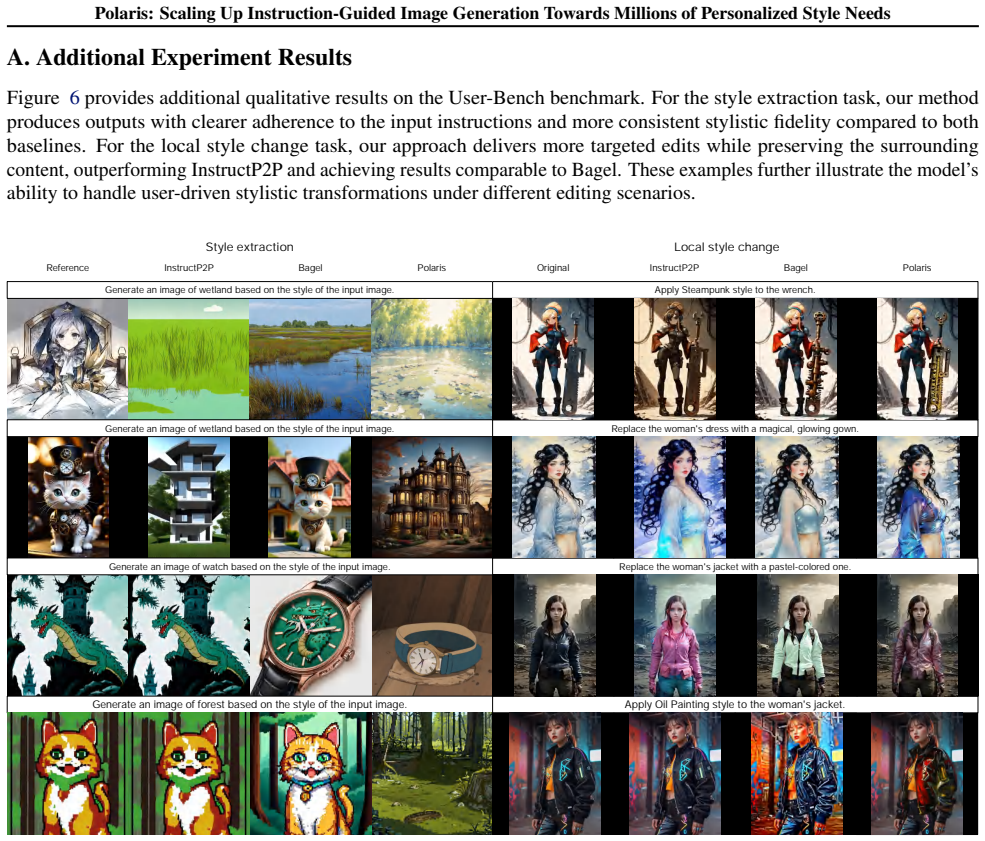
Significance. If the retrieval-plus-integration mechanism can be shown to work reliably, the approach would allow the community to exploit the growing ecosystem of fine-tuned models rather than retraining for each new personalized need, potentially reducing compute costs for instruction-guided generation at scale.
major comments (2)
- [Abstract] Abstract: the central claim that retrieval 'delivers ... well-aligned generation -- without any additional training' rests on the untested premise that an automatic selector can both identify the correct subset from a heterogeneous pool and combine the modules (via unspecified operator) without destructive interference; no retrieval representation, similarity metric, or merging procedure is described.
- [Abstract] Abstract: no evaluation protocol, dataset, or quantitative metric (e.g., alignment scores, user-study results, or comparison against fine-tuning baselines) is supplied to substantiate the 'well-aligned' and 'controllable' assertions, leaving the soundness of the core contribution unassessable from the provided text.
minor comments (1)
- [Title] Title claims 'Millions of Personalized Style Needs' while the abstract reports only 6,500 checkpoints + 75,000 adapters; clarify whether the indexed library is intended to grow to millions or whether the title is aspirational.
Simulated Author's Rebuttal
We thank the referee for the detailed comments on the abstract. We address each point below and indicate planned revisions to strengthen the presentation of the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that retrieval 'delivers ... well-aligned generation -- without any additional training' rests on the untested premise that an automatic selector can both identify the correct subset from a heterogeneous pool and combine the modules (via unspecified operator) without destructive interference; no retrieval representation, similarity metric, or merging procedure is described.
Authors: The abstract is intentionally high-level. The full manuscript details the retrieval representation (Section 3.2), similarity metric based on instruction embedding alignment (Section 3.3), and the merging operator that combines selected checkpoints and adapters while mitigating interference via weighted fusion (Section 4.2). We will revise the abstract to briefly reference these components so the central claim is better grounded in the described method. revision: partial
-
Referee: [Abstract] Abstract: no evaluation protocol, dataset, or quantitative metric (e.g., alignment scores, user-study results, or comparison against fine-tuning baselines) is supplied to substantiate the 'well-aligned' and 'controllable' assertions, leaving the soundness of the core contribution unassessable from the provided text.
Authors: Section 5 of the manuscript presents the evaluation protocol, including the datasets used, quantitative metrics such as alignment scores and controllability measures, user studies, and direct comparisons against fine-tuning baselines. We will update the abstract to explicitly note that these results support the claims of well-aligned and controllable generation. revision: partial
Circularity Check
No circularity: framework proposal with no equations or self-referential derivations
full rationale
The provided abstract and context describe a retrieval-based system for selecting and integrating pre-trained models/adapters. No equations, fitted parameters, or derivation chains are present. Claims rest on the engineering premise of retrieval plus integration rather than any mathematical reduction to inputs. No self-citations, ansatzes, or uniqueness theorems are invoked in the given text. This matches the expected non-finding for systems papers without load-bearing formal steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Implicit diffusion models for continuous super-resolution , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[2]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , volume=
-
[3]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Adding conditional control to text-to-image diffusion models , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[4]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[7]
ACM computing surveys , volume=
Diffusion models: A comprehensive survey of methods and applications , author=. ACM computing surveys , volume=. 2023 , publisher=
2023
-
[8]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Instructpix2pix: Learning to follow image editing instructions , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[9]
ACM SIGGRAPH 2022 conference proceedings , pages=
Palette: Image-to-image diffusion models , author=. ACM SIGGRAPH 2022 conference proceedings , pages=
2022
-
[10]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Deadiff: An efficient stylization diffusion model with disentangled representations , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[11]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Diffuse attend and segment: Unsupervised zero-shot segmentation using stable diffusion , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[12]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[13]
Advances in Neural Information Processing Systems , volume=
Stylus: Automatic adapter selection for diffusion models , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
and Lo, Wan-Yen and Dollar, Piotr and Girshick, Ross , title =
Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Dollar, Piotr and Girshick, Ross , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2023 , pages =
2023
-
[16]
2025 , eprint=
Qwen2.5-VL Technical Report , author=. 2025 , eprint=
2025
-
[17]
Forty-first international conference on machine learning , year=
Scaling rectified flow transformers for high-resolution image synthesis , author=. Forty-first international conference on machine learning , year=
-
[18]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Reproducible scaling laws for contrastive language-image learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[19]
International conference on machine learning , pages=
Zero-shot text-to-image generation , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[21]
arXiv preprint arXiv:2408.02657 , year =
Lumina-mgpt: Illuminate flexible photorealistic text-to-image generation with multimodal generative pretraining , author =. arXiv preprint arXiv:2408.02657 , year =
-
[22]
2024 , eprint =
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation , author =. 2024 , eprint =
2024
-
[23]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Analyzing and improving the image quality of stylegan , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[24]
Proceedings of the IEEE international conference on computer vision , pages=
Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[27]
arXiv preprint arXiv:2209.14491 , year=
Re-imagen: Retrieval-augmented text-to-image generator , author=. arXiv preprint arXiv:2209.14491 , year=
-
[28]
2024 , eprint=
Retrieval-Augmented Mixture of LoRA Experts for Uploadable Machine Learning , author=. 2024 , eprint=
2024
-
[31]
Advances in Neural Information Processing Systems , volume=
Model zoos: A dataset of diverse populations of neural network models , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[33]
2024 , eprint=
Text-to-image Diffusion Models in Generative AI: A Survey , author=. 2024 , eprint=
2024
-
[34]
Extended abstracts of the 2021 CHI conference on human factors in computing systems , pages=
Prompt programming for large language models: Beyond the few-shot paradigm , author=. Extended abstracts of the 2021 CHI conference on human factors in computing systems , pages=
2021
-
[35]
2025 , eprint=
Unified Multimodal Understanding and Generation Models: Advances, Challenges, and Opportunities , author=. 2025 , eprint=
2025
-
[40]
arXiv preprint arXiv:2505.14683 , year=
Emerging properties in unified multimodal pretraining , author=. arXiv preprint arXiv:2505.14683 , year=
-
[42]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Open-vocabulary semantic segmentation with mask-adapted clip , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[43]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Zone: Zero-shot instruction-guided local editing , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[45]
2015 , journal =
An Empirical Investigation of Catastrophic Forgetting in Gradient-Based Neural Networks , author=. 2015 , journal =
2015
-
[46]
2025 , journal =
Overcoming catastrophic forgetting in neural networks , author=. 2025 , journal =
2025
-
[47]
2022 , journal =
Gradient Episodic Memory for Continual Learning , author=. 2022 , journal =
2022
-
[48]
Journal of Big Data , year=
Survey on deep learning with class imbalance , author=. Journal of Big Data , year=
-
[49]
2022 , journal =
Self-Supervised Aggregation of Diverse Experts for Test-Agnostic Long-Tailed Recognition , author=. 2022 , journal =
2022
-
[51]
2023 , journal =
A Survey of Diffusion Based Image Generation Models: Issues and Their Solutions , author=. 2023 , journal =
2023
-
[52]
2024 , journal =
Rich Human Feedback for Text-to-Image Generation , author=. 2024 , journal =
2024
-
[53]
2025 , journal =
DreamOmni: Unified Image Generation and Editing , author=. 2025 , journal =
2025
-
[54]
2025 , journal =
Diffusion-4K: Ultra-High-Resolution Image Synthesis with Latent Diffusion Models , author=. 2025 , journal =
2025
-
[55]
2025 , journal =
Personalized Image Generation with Deep Generative Models: A Decade Survey , author=. 2025 , journal =
2025
-
[56]
A Survey of AI Text-to-Image and AI Text-to-Video Generators , DOI=
Singh, Aditi , year=. A Survey of AI Text-to-Image and AI Text-to-Video Generators , DOI=. 2023 4th International Conference on Artificial Intelligence, Robotics and Control (AIRC) , publisher=
2023
-
[57]
2023 , journal =
BLIP-Diffusion: Pre-trained Subject Representation for Controllable Text-to-Image Generation and Editing , author=. 2023 , journal =
2023
-
[59]
2024 , journal =
MM-LLMs: Recent Advances in MultiModal Large Language Models , author=. 2024 , journal =
2024
-
[60]
2020 , journal =
Denoising Diffusion Probabilistic Models , author=. 2020 , journal =
2020
-
[61]
2021 , journal =
Score-Based Generative Modeling through Stochastic Differential Equations , author=. 2021 , journal =
2021
-
[62]
2022 , journal =
Towards a Unified View of Parameter-Efficient Transfer Learning , author=. 2022 , journal =
2022
-
[63]
2024 , journal =
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey , author=. 2024 , journal =
2024
-
[64]
2024 , journal =
GPT-4o System Card , author=. 2024 , journal =
2024
-
[65]
Qwen2.5-vl technical report, 2025
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., and Lin, J. Qwen2.5-vl technical report, 2025
2025
-
[66]
Brooks, T., Holynski, A., and Efros, A. A. Instructpix2pix: Learning to follow image editing instructions. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 18392--18402, 2023 a
2023
-
[67]
Brooks, T., Holynski, A., and Efros, A. A. Instructpix2pix: Learning to follow image editing instructions. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 18392--18402, 2023 b
2023
-
[68]
Scaling rectified flow transformers for high-resolution image synthesis
Esser, P., Kulal, S., Blattmann, A., Entezari, R., M \"u ller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al. Scaling rectified flow transformers for high-resolution image synthesis. In Forty-first international conference on machine learning, 2024
2024
-
[69]
A model zoo of vision transformers
Falk, D., Meynent, L., Pfammatter, F., Sch \"u rholt, K., and Borth, D. A model zoo of vision transformers. arXiv preprint arXiv:2504.10231, 2025
arXiv 2025
-
[70]
Implicit diffusion models for continuous super-resolution
Gao, S., Liu, X., Zeng, B., Xu, S., Li, Y., Luo, X., Liu, J., Zhen, X., and Zhang, B. Implicit diffusion models for continuous super-resolution. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 10021--10030, 2023
2023
-
[71]
J., Mirza, M., Xiao, D., Courville, A., and Bengio, Y
Goodfellow, I. J., Mirza, M., Xiao, D., Courville, A., and Bengio, Y. An empirical investigation of catastrophic forgetting in gradient-based neural networks. arXiv preprint arXiv:1312.6211, 2015
Pith/arXiv arXiv 2015
-
[72]
Ha, D., Dai, A., and Le, Q. V. Hypernetworks. arXiv preprint arXiv:1609.09106, 2016
Pith/arXiv arXiv 2016
-
[73]
Han, Z., Gao, C., Liu, J., Zhang, J., and Zhang, S. Q. Parameter-efficient fine-tuning for large models: A comprehensive survey, 2024
2024
-
[74]
Towards a unified view of parameter-efficient transfer learning
He, J., Zhou, C., Ma, X., Berg-Kirkpatrick, T., and Neubig, G. Towards a unified view of parameter-efficient transfer learning. arXiv preprint arXiv:2110.04366, 2022
arXiv 2022
-
[75]
Hessel, J., Holtzman, A., Forbes, M., Bras, R. L., and Choi, Y. Clipscore: A reference-free evaluation metric for image captioning. arXiv preprint arXiv:2104.08718, 2021
Pith/arXiv arXiv 2021
-
[76]
Denoising diffusion probabilistic models
Ho, J., Jain, A., and Abbeel, P. Denoising diffusion probabilistic models. arXiv preprint arXiv:2006.11239, 2020
Pith/arXiv arXiv 2006
-
[77]
J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al. Lora: Low-rank adaptation of large language models. ICLR, 1 0 (2): 0 3, 2022
2022
-
[78]
Y., Pang, T., Du, C., and Lin, M
Huang, C., Liu, Q., Lin, B. Y., Pang, T., Du, C., and Lin, M. Lorahub: Efficient cross-task generalization via dynamic lora composition. arXiv preprint arXiv:2307.13269, 2023
arXiv 2023
-
[79]
Unified language-vision pretraining in llm with dynamic discrete visual tokenization
Jin, Y., Xu, K., Chen, L., Liao, C., Tan, J., Huang, Q., Chen, B., Lei, C., Liu, A., Song, C., et al. Unified language-vision pretraining in llm with dynamic discrete visual tokenization. arXiv preprint arXiv:2309.04669, 2023
arXiv 2023
-
[80]
Johnson, J. M. and Khoshgoftaar, T. M. Survey on deep learning with class imbalance. Journal of Big Data, 2019
2019
-
[81]
C., Lo, W.-Y., Dollar, P., and Girshick, R
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A. C., Lo, W.-Y., Dollar, P., and Girshick, R. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp.\ 4015--4026, October 2023
2023
-
[82]
Zone: Zero-shot instruction-guided local editing
Li, S., Zeng, B., Feng, Y., Gao, S., Liu, X., Liu, J., Li, L., Tang, X., Hu, Y., Liu, J., et al. Zone: Zero-shot instruction-guided local editing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 6254--6263, 2024
2024
-
[83]
Open-vocabulary semantic segmentation with mask-adapted clip
Liang, F., Wu, B., Dai, X., Li, K., Zhao, Y., Zhang, H., Zhang, P., Vajda, P., and Marculescu, D. Open-vocabulary semantic segmentation with mask-adapted clip. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 7061--7070, 2023
2023
-
[84]
Step1x-edit: A practical framework for general image editing
Liu, S., Han, Y., Xing, P., Yin, F., Wang, R., Cheng, W., Liao, J., Wang, Y., Fu, H., Han, C., et al. Step1x-edit: A practical framework for general image editing. arXiv preprint arXiv:2504.17761, 2025
Pith/arXiv arXiv 2025
-
[85]
Loke, B. S. Y., Quadri, F., Vivanco, G., Casagrande, M., and Fenollosa, S. Overcoming catastrophic forgetting in neural networks. arXiv preprint arXiv:2507.10485, 2025
arXiv 2025
-
[86]
Lopez-Paz, D. and Ranzato, M. Gradient episodic memory for continual learning. arXiv preprint arXiv:1706.08840, 2022
arXiv 2022
-
[87]
E., Salakhutdinov, R., Stoica, I., et al
Luo, M., Wong, J., Trabucco, B., Huang, Y., Gonzalez, J. E., Salakhutdinov, R., Stoica, I., et al. Stylus: Automatic adapter selection for diffusion models. Advances in Neural Information Processing Systems, 37: 0 32888--32915, 2024
2024
-
[88]
Michelessa, M., Ng, J., Hurter, C., and Lim, B. Y. Varif.ai to vary and verify user-driven diversity in scalable image generation. In Proceedings of the 2025 ACM Designing Interactive Systems Conference, DIS ’25, pp.\ 1867–1885. ACM, July 2025. doi:10.1145/3715336.3735847. URL http://dx.doi.org/10.1145/3715336.3735847
-
[89]
OpenAI et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024
Pith/arXiv arXiv 2024
-
[90]
Sdxl: Improving latent diffusion models for high-resolution image synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., M \"u ller, J., Penna, J., and Rombach, R. Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952, 2023
Pith/arXiv arXiv 2023
-
[91]
Deadiff: An efficient stylization diffusion model with disentangled representations
Qi, T., Fang, S., Wu, Y., Xie, H., Liu, J., Chen, L., He, Q., and Zhang, Y. Deadiff: An efficient stylization diffusion model with disentangled representations. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 8693--8702, 2024
2024
-
[92]
Ramesh, R. and Chaudhari, P. Model zoo: A growing" brain" that learns continually. arXiv preprint arXiv:2106.03027, 2021
arXiv 2021
-
[93]
High-resolution image synthesis with latent diffusion models
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 10684--10695, 2022
2022
-
[94]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Ruiz, N., Li, Y., Jampani, V., Pritch, Y., Rubinstein, M., and Aberman, K. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 22500--22510, 2023 a
2023
-
[95]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Ruiz, N., Li, Y., Jampani, V., Pritch, Y., Rubinstein, M., and Aberman, K. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 22500--22510, 2023 b
2023
-
[96]
Palette: Image-to-image diffusion models
Saharia, C., Chan, W., Chang, H., Lee, C., Ho, J., Salimans, T., Fleet, D., and Norouzi, M. Palette: Image-to-image diffusion models. In ACM SIGGRAPH 2022 conference proceedings, pp.\ 1--10, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.