Segment-driven Structural Induction and Semantic Alignment for Heterogeneous Tabular Representation
Pith reviewed 2026-06-28 15:16 UTC · model grok-4.3
The pith
NAVI pretrains on header-value segments to aggregate structural and distributional evidence across tables with varying headers but shared semantics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
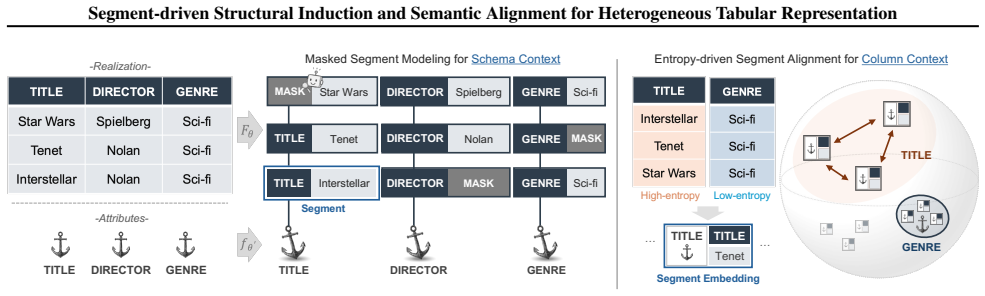
NAVI is a segment-centric pretraining framework that treats each header-value pair as the unit for aggregating schema-level structural evidence and column-level distributional evidence. We realize this design through Masked Segment Modeling and Entropy-driven Segment Alignment, which jointly enforce structured header-value coupling and semantic alignment across stable and instance-specific attributes.
What carries the argument
Masked Segment Modeling and Entropy-driven Segment Alignment applied to header-value pair segments, which aggregate structural and distributional evidence while enforcing couplings.
If this is right
- Improved reconstruction of masked table segments.
- Stronger semantic consistency across tables with different headers.
- Higher utility on downstream tasks that use the pretrained representations.
- Better handling of both stable and instance-specific attributes in the same model.
Where Pith is reading between the lines
- The segment unit could be tested on tables from additional domains to check if alignment holds beyond the evaluated in-domain cases.
- If the alignment mechanism works, it might reduce the need for manual schema mapping in data integration pipelines.
- One could extend the entropy alignment to measure consistency across more than two tables at once.
- The approach suggests that future encoders might benefit from explicit value-distribution modeling even when headers are noisy.
Load-bearing premise
That treating header-value pairs as segments and applying the two objectives will successfully capture and align the needed evidence without additional assumptions about table uniformity.
What would settle it
An experiment on heterogeneous in-domain tables that finds no improvement in reconstruction accuracy, semantic consistency metrics, or downstream task performance relative to existing tabular encoders.
Figures


read the original abstract
Real-world domains often contain heterogeneous tables whose headers vary while their underlying attribute semantics are shared, making it difficult to induce domain-specialized semantics from table-local evidence alone. Existing encoders model parts of this problem, but often underuse column-level value distributions and apply uniform objectives across attributes with different semantic roles. We propose NAVI, a segment-centric pretraining framework that treats each header-value pair as the unit for aggregating schema-level structural evidence and column-level distributional evidence. We realize this design through Masked Segment Modeling and Entropy-driven Segment Alignment, which jointly enforce structured header-value coupling and semantic alignment across stable and instance-specific attributes. Experiments on heterogeneous in-domain tables show improved reconstruction, semantic consistency, and downstream utility across evaluation settings overall.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes NAVI, a segment-centric pretraining framework for heterogeneous tabular data. It treats each header-value pair as the modeling unit to aggregate schema-level structural evidence and column-level distributional evidence. The framework is realized via Masked Segment Modeling and Entropy-driven Segment Alignment to enforce header-value coupling and cross-table semantic alignment. Experiments on heterogeneous in-domain tables are claimed to show improvements in reconstruction, semantic consistency, and downstream utility.
Significance. If the central claims hold with rigorous validation, the work could meaningfully advance tabular representation learning by addressing header heterogeneity and underused value distributions through a unified segment-based objective, offering a targeted alternative to uniform attribute modeling in existing encoders.
major comments (2)
- [Abstract] Abstract: no equations, training objectives, architectural diagrams, or quantitative results are provided, so it is impossible to check whether Masked Segment Modeling or Entropy-driven Segment Alignment actually aggregates the claimed evidence or reduces to a fitted quantity by construction; this prevents assessment of the central claim.
- [Abstract] Abstract: the weakest assumption—that segment-centric modeling with the two proposed objectives will successfully enforce structured coupling and cross-table alignment—is stated but not accompanied by any derivation, loss formulation, or ablation that would allow verification of internal consistency.
Simulated Author's Rebuttal
We thank the referee for their comments on the abstract. Abstracts are concise overviews by design; the detailed formulations, derivations, and empirical validations appear in the main text (Sections 3 and 4). We respond point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: no equations, training objectives, architectural diagrams, or quantitative results are provided, so it is impossible to check whether Masked Segment Modeling or Entropy-driven Segment Alignment actually aggregates the claimed evidence or reduces to a fitted quantity by construction; this prevents assessment of the central claim.
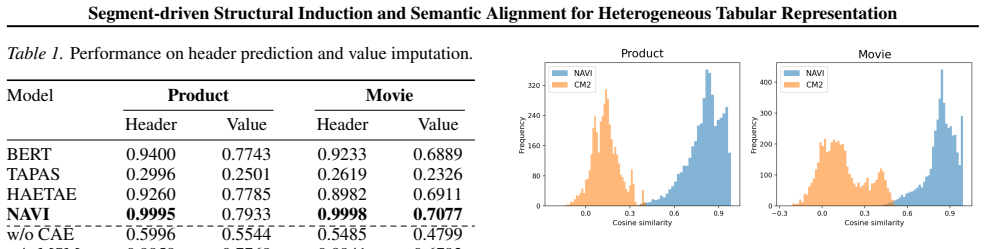
Authors: Abstracts are intentionally limited in length and omit equations, diagrams, and results. The Masked Segment Modeling objective (Eq. 3) and Entropy-driven Segment Alignment objective (Eq. 5) are fully specified in Section 3.2–3.3, with architectural diagrams in Figure 2 and quantitative results plus ablations in Section 4. These sections directly demonstrate how the objectives aggregate schema-level and distributional evidence rather than reducing to a trivial fit. revision: no
-
Referee: [Abstract] Abstract: the weakest assumption—that segment-centric modeling with the two proposed objectives will successfully enforce structured coupling and cross-table alignment—is stated but not accompanied by any derivation, loss formulation, or ablation that would allow verification of internal consistency.
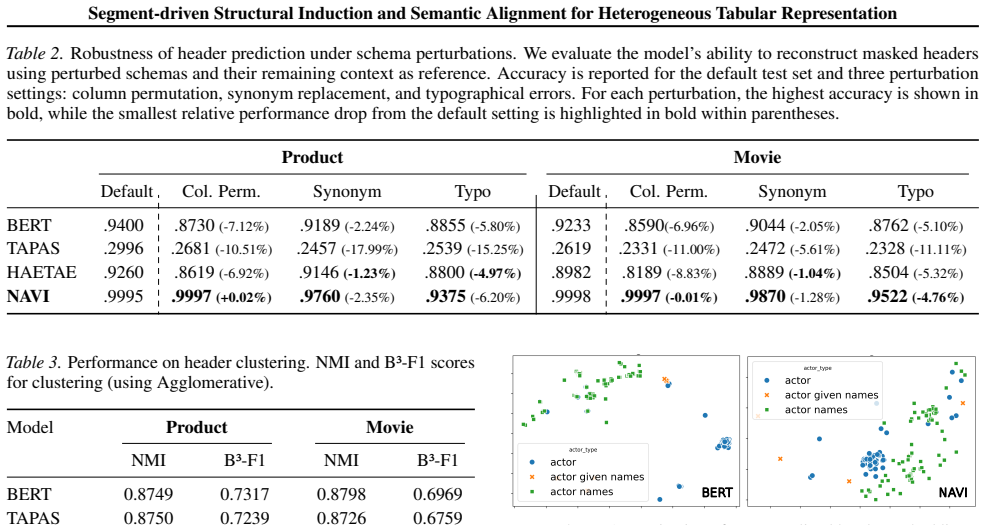
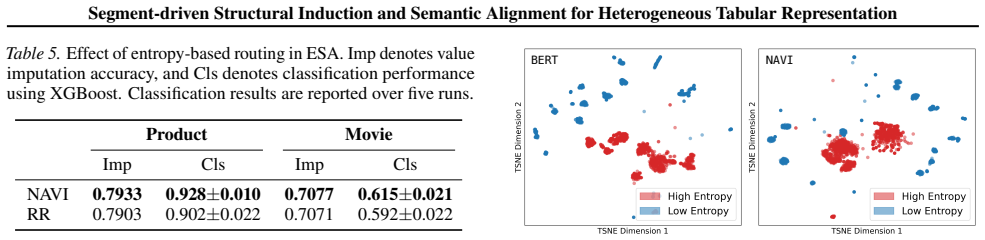
Authors: The segment-centric assumption is motivated in the introduction and formalized via the joint loss in Section 3.4. Derivations appear in Eqs. (3)–(6); internal consistency is verified through the ablation study in Section 4.3 (Table 3) that isolates the contribution of each objective to header-value coupling and cross-table alignment. The abstract states the modeling premise at a high level while the body supplies the requested verification. revision: no
Circularity Check
No significant circularity detected
full rationale
The abstract and available description present NAVI as a proposed segment-centric pretraining framework realized through Masked Segment Modeling and Entropy-driven Segment Alignment, with claims about aggregating structural and distributional evidence framed as design choices rather than derived results. No equations, training objectives, or derivation chains are visible that would allow identification of self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations. The central claims remain independent of any internal reduction to inputs by construction, rendering the approach self-contained at the level of the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ba, J. L., Kiros, J. R., and Hinton, G. E. Layer normalization. arXiv preprint arXiv:1607.06450,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Clark, K., Khandelwal, U., Levy, O., and Manning, C. D. What does BERT look at? an analysis of BERT’s atten- tion. InProceedings of the 2019 ACL Workshop Black- boxNLP: Analyzing and Interpreting Neural Networks for NLP, pp. 276–286,
2019
-
[3]
BERT: Pre-training of deep bidirectional transformers for lan- guage understanding
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. BERT: Pre-training of deep bidirectional transformers for lan- guage understanding. InProceedings of the 2019 Confer- ence of the North American Chapter of the Association for Computational Linguistics: Human Language Tech- nologies,
2019
-
[4]
A., Zhang, J., Hu, Z., Qi, Y ., Nick- leach, S., Socolinsky, D., Sengamedu, S., and Faloutsos, C
Fang, X., Xu, W., Tan, F. A., Zhang, J., Hu, Z., Qi, Y ., Nick- leach, S., Socolinsky, D., Sengamedu, S., and Faloutsos, C. Large language models on tabular data: Prediction, generation, and understanding–a survey.arXiv preprint arXiv:2402.17944,
-
[5]
TabTransformer: Tabular Data Modeling Using Contextual Embeddings
Huang, X., Khetan, A., Cvitkovic, M., and Karnin, Z. Tab- transformer: Tabular data modeling using contextual em- beddings.arXiv preprint arXiv:2012.06678,
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[6]
Tabbie: Pretrained representations of tabular data
Iida, H., Thai, D., Manjunatha, V ., and Iyyer, M. Tabbie: Pretrained representations of tabular data. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 3446–3456,
2021
-
[7]
and Yoon, S
Lim, Y . and Yoon, S. Multi-level diagnosis and evaluation for robust tabular feature engineering with large language models. InFindings of the Association for Computational Linguistics: EMNLP 2025, pp. 4630–4655,
2025
-
[8]
Representation Learning with Contrastive Predictive Coding
Liu, Q., Chen, B., Guo, J., Ziyadi, M., Lin, Z., Chen, W., and Lou, J.-G. Tapex: Table pre-training via learning a neural sql executor. InInternational Conference on Learning Representations. Loshchilov, I. and Hutter, F. Decoupled weight decay reg- ularization. InInternational Conference on Learning Representations. Mueller, M., Gruber, K., and Fok, D. C...
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
The web data commons schema.org table corpora
Peeters, R., Brinkmann, A., and Bizer, C. The web data commons schema.org table corpora. InCompanion Pro- ceedings of the ACM Web Conference 2024,
2024
-
[10]
B., and Goldstein, T
Somepalli, G., Schwarzschild, A., Goldblum, M., Bruss, C. B., and Goldstein, T. Saint: Improved neural networks for tabular data via row attention and contrastive pre- training. InNeurIPS 2022 First Table Representation Workshop. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., and Polosukhin, I. At- tention is all...
2022
-
[11]
Towards cross-table masked pretraining for web data mining
Ye, C., Lu, G., Wang, H., Li, L., Wu, S., Chen, G., and Zhao, J. Towards cross-table masked pretraining for web data mining. InProceedings of the ACM Web Conference 2024, pp. 4449–4459,
2024
-
[12]
Mixed- type tabular data synthesis with score-based diffusion in latent space
Zhang, H., Zhang, J., Shen, Z., Srinivasan, B., Qin, X., Faloutsos, C., Rangwala, H., and Karypis, G. Mixed- type tabular data synthesis with score-based diffusion in latent space. InInternational Conference on Learning Representations, volume 2024, pp. 52829–52857, 2024a. Zhang, T., Yue, X., Li, Y ., and Sun, H. TableLlama: Towards open large generalist ...
2024
-
[13]
11 Segment-driven Structural Induction and Semantic Alignment for Heterogeneous Tabular Representation A. Theoretical Analysis of Entropy-driven Segment Alignment We provide a geometric analysis of Entropy-driven Segment Alignment (ESA), the contrastive objective introduced in Section 3.3. Our goal is to analyze and characterize the local geometric forces...
2020
-
[14]
These methods are effective at modeling feature interactions, handling heterogeneous feature types, and achieving strong predictive performance under task-specific supervision
remain strong baselines for classification and regression on structured tables. These methods are effective at modeling feature interactions, handling heterogeneous feature types, and achieving strong predictive performance under task-specific supervision. More recent neural approaches (Huang et al., 2020; Somepalli et al.; Gorishniy et al., 2021; Hollman...
2020
-
[15]
These approaches typically assume fixed and well-defined feature spaces within a table or benchmark dataset
further explore attention-based architectures, self-supervised objectives, and in-context prediction for tabular data. These approaches typically assume fixed and well-defined feature spaces within a table or benchmark dataset. Our setting instead considers heterogeneous in-domain tables, where semantically related attributes may appear under different he...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.