It does what it says on the tin: safe synthetic data from coarsened margins
Pith reviewed 2026-06-28 12:49 UTC · model grok-4.3
The pith
Synthetic data can be created from margins that have already passed disclosure control by coarsening counts and applying iterative proportional fitting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that defining and curating margins for desired relationships, subjecting them to disclosure control including coarsening all counts to multiples of the limit, and then running iterative proportional fitting produces synthetic data whose statistical properties stay close to the safe margins while introducing no new disclosure vulnerabilities.
What carries the argument
Coarsened margins (counts adjusted to multiples of the disclosure limit after standard SDC) fed into the Iterative Proportional Fitting algorithm to generate synthetic data.
If this is right
- The recipient knows in advance which variable relationships will be approximately maintained.
- All input to the generator has already been cleared of disclosure risk by the data custodian.
- The method works with any margins to which standard top-coding, category combination, and count modification can be applied.
- An explicit worked example with 1901 Scottish census tables demonstrates the sequence of steps.
Where Pith is reading between the lines
- The same margin-coarsening step could be inserted before other synthesis algorithms that accept marginal constraints.
- In high-dimensional tables the coarsening threshold may need to be chosen jointly with the IPF convergence tolerance to control distortion.
- The approach naturally extends to repeated releases by reusing the same coarsened margins across multiple synthetic draws.
Load-bearing premise
Coarsening every count in the margins to multiples of the disclosure limit and then running IPF keeps the synthetic data close enough to those margins that transparency and safety guarantees hold without new risks or unacceptable distortion.
What would settle it
A reconstruction attack or statistical test on the generated synthetic data that recovers original small cell counts or other information not present in the coarsened margins.
Figures

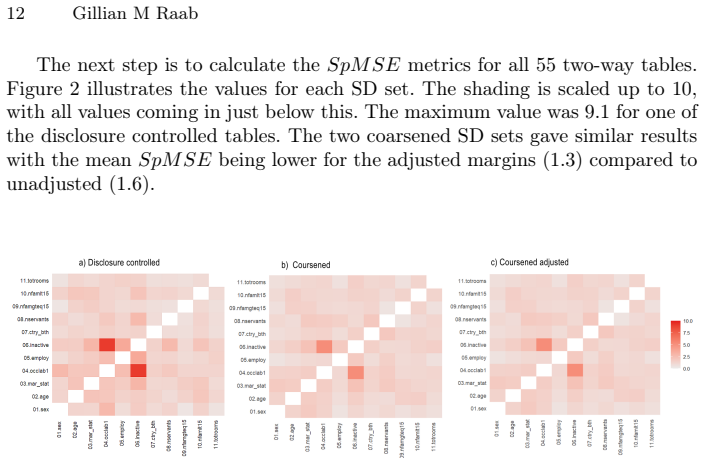
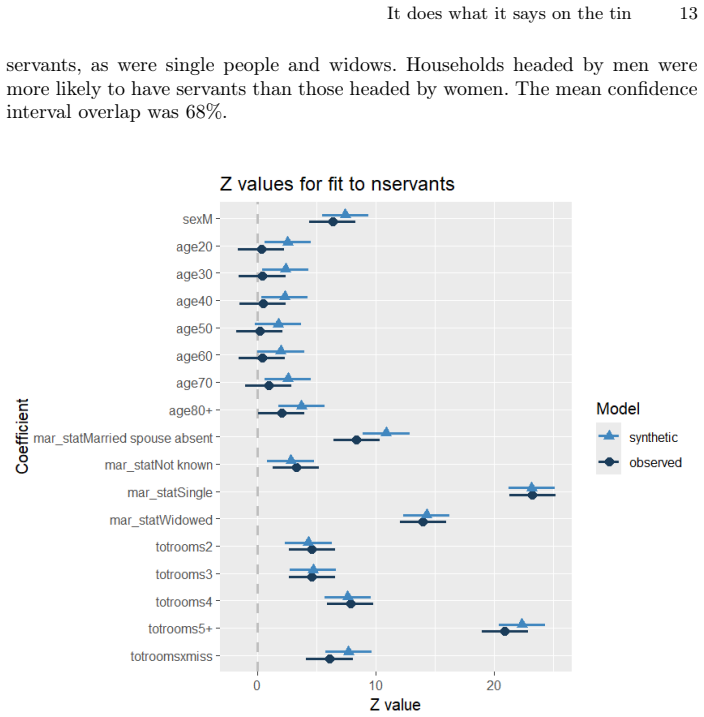
read the original abstract
This paper proposes a method of creating synthetic data (SD) that will have two important advantages for the user compared to other methods currently available. The first is transparency; unlike other methods, the person in receipt of the SD will know which of the relationships between variables in the original data will be approximately maintained in the SD. The second is a guarantee that the SD is derived from information that has already been judged to be free of disclosure risk. This is achieved by first defining and calculating the margins where relationships between variables will be maintained in the SD. Each margin will then be subject to statistical disclosure control (SDC) to the standards defined by the data custodian, e.g. top-coding and bottom-coding, combination of small categories and/or modifying small counts. Further adjustment of the curated margins is advised by coarsening all counts in the table to multiples of the disclosure limit. These adjusted margins are used to create SD by the Iterative Proportional Fitting (IPF) algorithm. The practical steps involved in creating such SD are illustrated using data from the 1901 Census of Scotland.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes generating synthetic data (SD) by first selecting margins to preserve relationships, applying statistical disclosure control (SDC) such as top/bottom-coding and small-count modifications, further coarsening all counts to multiples of the disclosure limit, and then applying the Iterative Proportional Fitting (IPF) algorithm to produce an SD table whose marginals exactly match the adjusted inputs. This is claimed to deliver transparency (recipient knows exactly which relationships are maintained) and safety (SD derived exclusively from already-approved safe margins), with the procedure illustrated on 1901 Scottish Census data.
Significance. If the central claim holds, the approach supplies a simple, auditable pipeline built from standard SDC operations and IPF that avoids auxiliary modeling assumptions or hidden parameters, potentially useful for official statistics settings where explicit control over preserved margins is required. The construction limits any inference from the SD to linear combinations of the supplied safe margins, which is a genuine strength.
major comments (2)
- [Abstract, paragraph describing the adjustment step before IPF] Abstract, paragraph describing the adjustment step before IPF: the claim that coarsening counts to multiples of the disclosure limit followed by IPF yields SD whose statistical properties remain sufficiently close to the adjusted margins (so that transparency and safety guarantees hold without new disclosure channels or unacceptable distortion) receives no derivation, error analysis, bounds on total variation or other distances, or comparison to the pre-coarsened margins.
- [The 1901 Census illustration] The 1901 Census illustration: the manuscript states that practical steps are illustrated with 1901 Scottish Census data but reports no quantitative results, no measured distortion from coarsening+IPF, and no assessment of how closely the generated SD reproduces the supplied margins or any other statistics.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and indicate where revisions will be made to clarify the method's properties.
read point-by-point responses
-
Referee: Abstract, paragraph describing the adjustment step before IPF: the claim that coarsening counts to multiples of the disclosure limit followed by IPF yields SD whose statistical properties remain sufficiently close to the adjusted margins (so that transparency and safety guarantees hold without new disclosure channels or unacceptable distortion) receives no derivation, error analysis, bounds on total variation or other distances, or comparison to the pre-coarsened margins.
Authors: The IPF algorithm guarantees that the output synthetic table exactly reproduces the supplied coarsened margins; there is therefore no discrepancy or approximation with respect to those margins. The coarsening step is an explicit, additional SDC operation performed on margins that have already received custodian-approved disclosure control. Safety follows because the SD is generated exclusively from this approved safe information. Transparency follows because the recipient is told precisely which margins (hence which relationships) are preserved. We will revise the abstract and methods to state the exact-matching property explicitly and to clarify that any distortion is confined to the intentional, pre-approved SDC steps. revision: yes
-
Referee: The 1901 Census illustration: the manuscript states that practical steps are illustrated with 1901 Scottish Census data but reports no quantitative results, no measured distortion from coarsening+IPF, and no assessment of how closely the generated SD reproduces the supplied margins or any other statistics.
Authors: The 1901 example is intended only to illustrate the workflow sequence. Because IPF enforces exact equality with the coarsened margins, no additional distortion is introduced by that step. We agree that a quantitative demonstration would improve clarity and will add a small table in the revised manuscript showing example margin values before and after coarsening, together with confirmation that the synthetic output matches the coarsened margins exactly. revision: yes
Circularity Check
No significant circularity; method is procedural and self-contained
full rationale
The paper outlines a sequence of standard operations: select margins, apply SDC (top/bottom coding, category combination), coarsen counts to multiples of a disclosure threshold, then apply IPF to generate synthetic data whose marginals match the adjusted inputs exactly. IPF is an external, well-known algorithm whose fixed-point property is independent of this paper. Safety and transparency claims rest on the external judgment that the input margins are already disclosure-safe and on explicit disclosure of which margins are used; neither reduces to a self-definition, fitted parameter renamed as prediction, or self-citation chain. No equations, uniqueness theorems, or ansatzes are introduced that would make any claimed property equivalent to the inputs by construction. The paper is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Iterative proportional fitting converges to a table consistent with the supplied margins.
- domain assumption Statistical disclosure control applied to margins renders the input information free of disclosure risk.
Reference graph
Works this paper leans on
-
[1]
Available from https://www.adruk.org/fileadmin/uploads/adruk/Documents/An_interim_ADR_UK_position_statement_on_synthetic_data.pdf accessed 31/05/2026
ADR UK (2023) An interim ADR UK posi- tion statement on synthetic data. Available from https://www.adruk.org/fileadmin/uploads/adruk/Documents/An_interim_ADR_UK_position_statement_on_synthetic_data.pdf accessed 31/05/2026
2023
-
[2]
(2025) A ReviewofSyntheticDataTerminologyforPrivacyPreservingUseCases,IntJPopul Data Sci.10:2:08
Bharat S.S., Frayling L., Stock J., LuggWidge F., Gordon E., Oliver E. (2025) A ReviewofSyntheticDataTerminologyforPrivacyPreservingUseCases,IntJPopul Data Sci.10:2:08
2025
-
[3]
(2018) The Creation and Use of the SIPP Synthetic Beta v7.0, CES Technical Notes Series from Center for Economic Studies, U.S
Benedetto G., Stanley J.C„ and Totty E. (2018) The Creation and Use of the SIPP Synthetic Beta v7.0, CES Technical Notes Series from Center for Economic Studies, U.S. Census Bureau
2018
-
[4]
DARE UK Synthetic data Community Group. Perspectives and Recommenda- tions on the Development of Synthetic Datasets in Trusted Research Environments https://portal.dementiasplatform.uk/reports/development of synthetic datasets in trusted research environments/, accessed 27/5/2026
2026
-
[5]
Deming, W. E. and Stephan, F. F. (1940). Ann. Math. Statist.,11, 427–444
1940
-
[6]
Drechsler J. Haensch C.A. (2024) 30 Years of Synthetic Data Statistical Science39, 2, 221—242 https://doi.org/10.1214/24STS927 , accessed 28/5/2026
-
[7]
Elliot, M., Little, C., Allmendinger, R. (2024). The Production of Bespoke Syn- thetic Teaching Datasets Without Access to the Original Data. In M. Önen and J. Domingo-Ferrer (Eds.), PRIVACY IN STATISTICAL DATABASES, PSD 2024 (Vol. 14915, pp. 144–157). Springer. https://doi.org/10.1007/9783031-696510_10
-
[8]
Fienberg, S. E. (1970). Ann. Math. Statist.,41, 907–917
1970
-
[9]
Fössing, E., Drechsler, J. (2024). An Evaluation of Synthetic Data Generators Im- plemented in the Python Library Synthcity. In M. Onen and J. Domingo-Ferrer (Eds.), Privacy in Statistical Databases, PSD 202414915,178–193. Springer
2024
-
[10]
Grath-Lone LM, Jay MA, Blackburn R, Gordon E, Zylbersztejn A, Wiljaars L, Gilbert R. (2022) What makes administrative data "research-ready"? A sys- tematic review and thematic analysis of published literature. Int J Popul Data 21 https://www.scotlandscensus.gov.uk/census-results/flexible-table-builder/ accessed 31/05/2026 It does what it says on the tin 1...
-
[11]
Green,E.,Ritche,F.,White,P.(2024).Thestatbarn:ANewModelforOutputSta- tistical Disclosure Control. In M. Önen amd J. Domingo-Ferrer (Eds.), PRIVACY IN STATISTICAL DATABASES, PSD 2024 textbf14915, 284—293. Springer
2024
-
[12]
(2023) Synthetic is all you need: Removing the auxiliary data assumption for membership inference attacks against synthetic data
Guepin, F., Meeus, M., Cretu, A.M., de Montjoye, Y.A. (2023) Synthetic is all you need: Removing the auxiliary data assumption for membership inference attacks against synthetic data. In ESORICS
2023
-
[13]
N., Daniel, O., Elliott, A., Geddes, J., Mole, C., Rangel-Smith, C., and Szpruch, L
Houssiau, F., Jordon, J., Cohen, S. N., Daniel, O., Elliott, A., Geddes, J., Mole, C., Rangel-Smith, C., and Szpruch, L. (2022) Tapas: a toolbox for adversarial privacy auditing of synthetic data. In NeurIPS SyntheticData4ML
2022
-
[14]
Domingo-Ferrer, J
Hundepool, A. Domingo-Ferrer, J. Franconi, L. Giessing, S. and Schulte N.E. Spicer, K. de Wolf, P. (2012) Statistical Disclosure Control, John Wiley & Sons, Ltd
2012
-
[15]
Mitra, B
Jackson, J., R. Mitra, B. Francis, and I. Dove (2022). Using saturated count models for user-friendly synthesis of large confidential administrative databases. Journal of the Royal Statistical Society: Series A (Statistics in Society)185, 1613-–1643
2022
-
[16]
P., Miranda, J., Jarmin, R., Abowd, J.M
Kinney, S.K., Reiter, J.P., Reznek, A. P., Miranda, J., Jarmin, R., Abowd, J.M. (2011), Towards Unrestricted Public use Business Microdata: The Synthetic Longi- tudinal Business Database, International Statistical Review,79 (3), 362-384
2011
-
[17]
(2024) USER GUIDE: Synthetic ASHE-2011 Census dataset DOI: http://doi.org/10.5255/UKDA-SN-9282-1
Little C., Elliot M., Allmendinger, M. (2024) USER GUIDE: Synthetic ASHE-2011 Census dataset DOI: http://doi.org/10.5255/UKDA-SN-9282-1
-
[18]
Nowok, B., Raab, G.M and Dibben, C. (2016). synthpop: Be- spoke creation of synthetic data in R. Journal of Statistical Software, 74(11), 1-26. doi:10.18637/jss.v074.i11. The documen- tation for the function syn.ipf can be found at https://cran.r- project.org/web/packages/synthpop/refman/synthpop.html#syn.ipf, Accessed 26/5/2026
-
[19]
N. Patki, R. Wedge and K. Veeramachaneni, "The Synthetic Data Vault," 2016 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Montreal, QC, Canada, 2016, pp. 399-410, doi: 10.1109/DSAA.2016.49
-
[20]
Raab, G., McCall, S. and Cavin, L. (2025) “Four checks for lowfidelity synthetic data: recommendations for disclosure control and quality evaluation”, International Journal of Population Data Science, 10(2). doi: 10.23889/ijpds.v10i2.2972
-
[21]
(2025) Confidentiality and disclosure risk from administrative data UNECE, Expert meeting on Statistical Data Con- fidentiality, Barcelona
Raab G.M., Dibben C., Krčo N. (2025) Confidentiality and disclosure risk from administrative data UNECE, Expert meeting on Statistical Data Con- fidentiality, Barcelona. Available from https://unece.org/sites/default/files/2025- 10/SDC2025_Sb_UnivEd-SLS_RaabDibbenKcro_D.pdf, accessed 26/5/26
2025
-
[22]
Raab, G. M. (2024). Privacy Risk from Synthetic Data: Practical Proposals. In M. Onen and J. Domingo-Ferrer (Eds.), PRIVACY IN STATISTICAL DATABASES, PSD 202414915, 254–273. Springer
2024
-
[23]
Shokri, R., M. Stronati, A. C. S., and Shmatikov, V. (2017) Membership inference attacks against machine learning models. In 2017 IEEE Symposium on Security and Privacy available from https://arxiv.org/abs/1610.05820, accessed September 2025
Pith/arXiv arXiv 2017
-
[24]
(2007) Disclosure detection in research environments in practice
Ritchie F. (2007) Disclosure detection in research environments in practice. Paper presented at UNECE/Eurostat work session on statistical data confidentiality - 2007
2007
-
[25]
(1993) Discussion: Statistical Disclosure Limitation
Rubin, D. (1993) Discussion: Statistical Disclosure Limitation. Journal of Official Statistics.9461—468. 16 Gillian M Raab
1993
-
[26]
(2025) A formal model for reasoning about output disclosure risks and mitigations
Smith, J., Padiya, T., Ritchie, F., Green, E., Tilbrook, A. (2025) A formal model for reasoning about output disclosure risks and mitigations. UNECE Expert meet- ing on Statistical Data Confidentiality, Barcelona. Available from https://uwe- repository.worktribe.com/output/15152512, accessed 26/5/26
arXiv 2025
-
[27]
General and Specific Utility Measures for Synthetic Data
Snoke J, Raab G, Nowok B, Dibben C, Slavkovic A (2018). “General and Specific Utility Measures for Synthetic Data.” Journal of the Royal Statistical Society B, textbf181(3), 663-–668
2018
-
[28]
(2022) Synthetic data – anonymisa- tion groundhog day
Stadler, T., Oprisanu, B., and Troncoso, C. (2022) Synthetic data – anonymisa- tion groundhog day. In 31st USENIX Security Symposium (USENIX Security 22) (Boston, MA), pp. 1451—1468
2022
-
[29]
Thomas, B., Guignard-Duff, M., Hettrick, S., Broadbent, P., and Murray, H. (2026). Skills for the curation of sensitive data. Zenodo. https://doi.org/10.5281/zenodo.19883038
-
[30]
Taub J, Elliot M, Raab GM, Chareset A, Chen C, O’Keefe CM, Pistner M, Snoke J, Slavkovic A (2019) Creating the Best Risk-Utility Profile: The Synthetic Data Challenge,JointUNECE/EurostatWorkSessiononStatisticalDataConfidentiality
2019
-
[31]
Evaluating Goodness-of-Fit Measures for Synthetic Microdata
Voas D, Williamson P (2001). “Evaluating Goodness-of-Fit Measures for Synthetic Microdata.” Geographical and Environmental Modelling,5, 177-–200
2001
-
[32]
Graham P
Young J. Graham P. Penny, R. (2009). Using Bayesian Networks to Create Syn- thetic Data. Journal of Official Statistics.25. 549–567
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.