Why Are DMD Students Lazy? Understanding the Copying Behavior in Few-Step Distillation
Pith reviewed 2026-06-28 15:30 UTC · model grok-4.3
The pith
High-dimensional DMD students copy their teacher's noise-data pairings because the student lacks geometric freedom to remap noise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
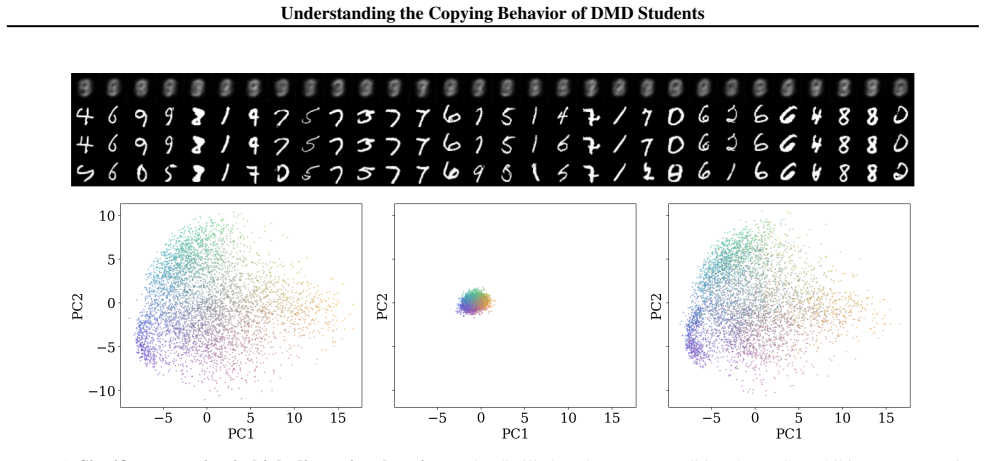
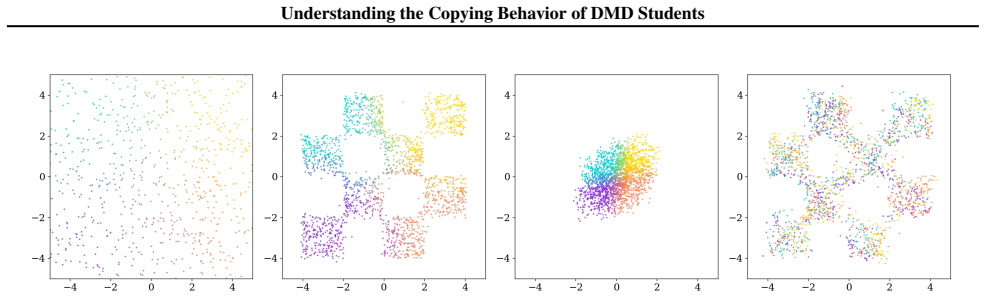
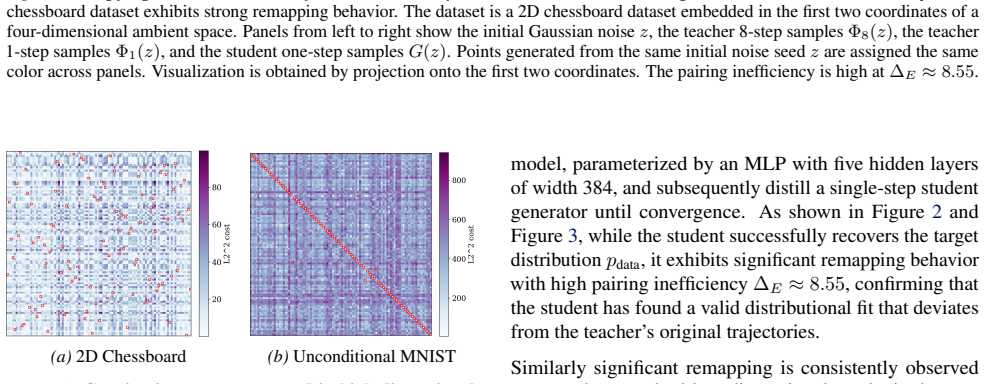
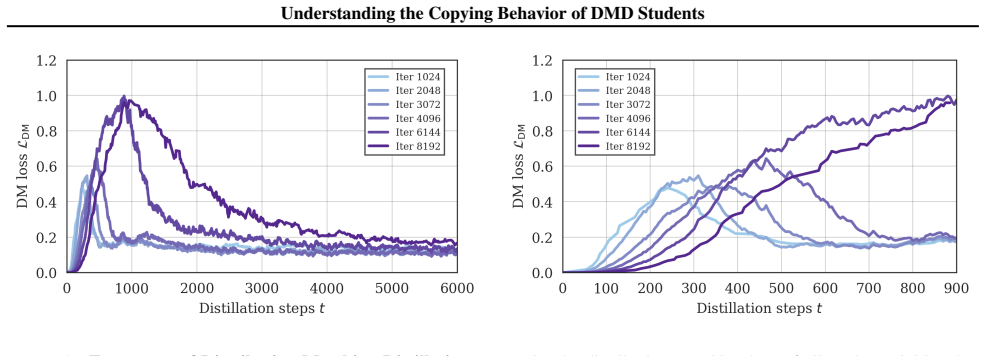
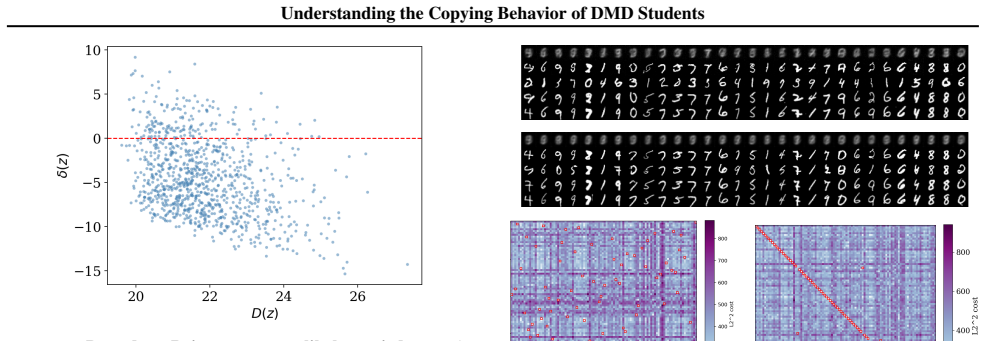
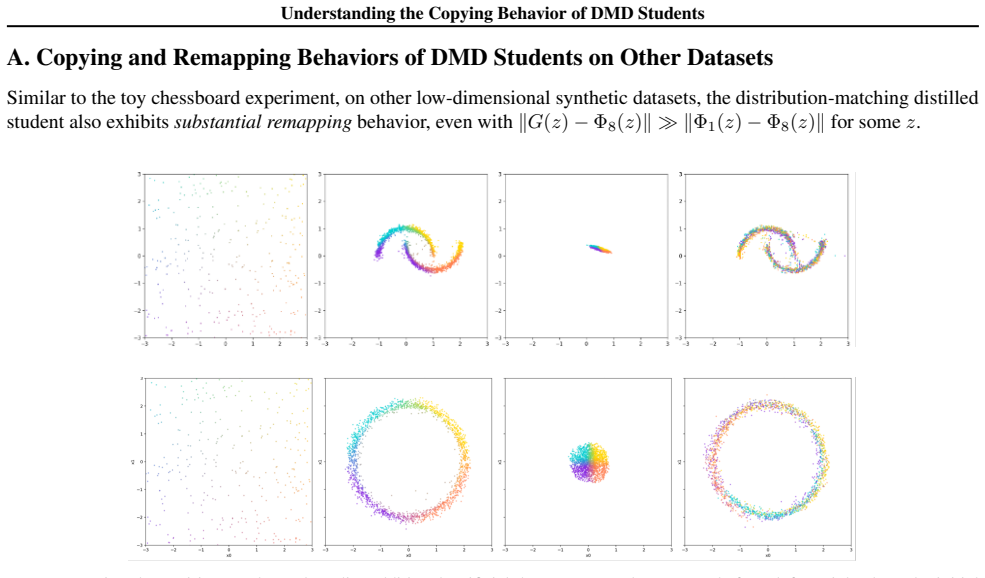
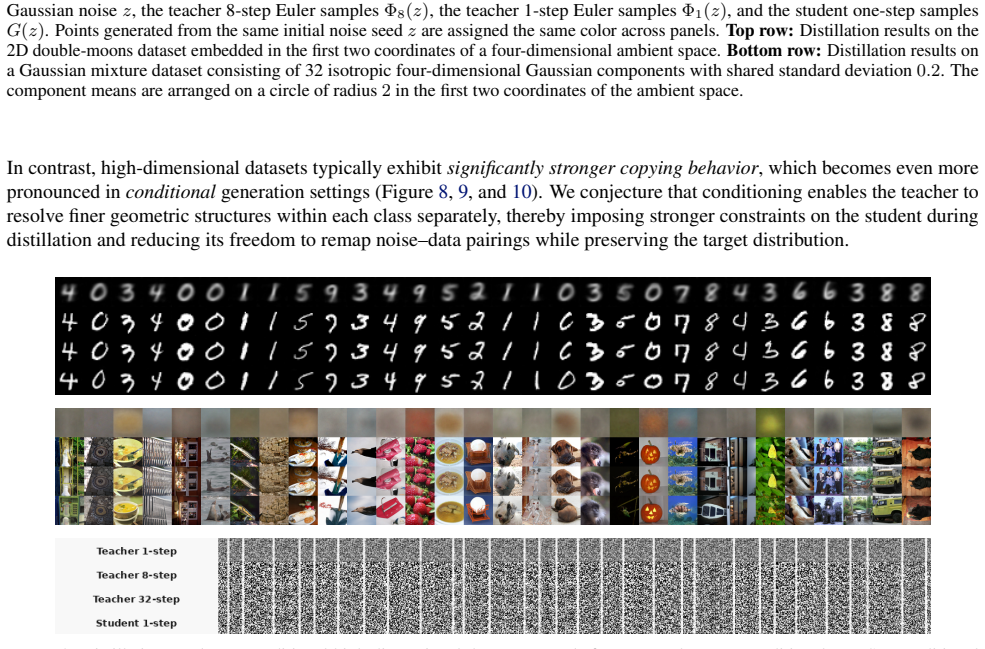
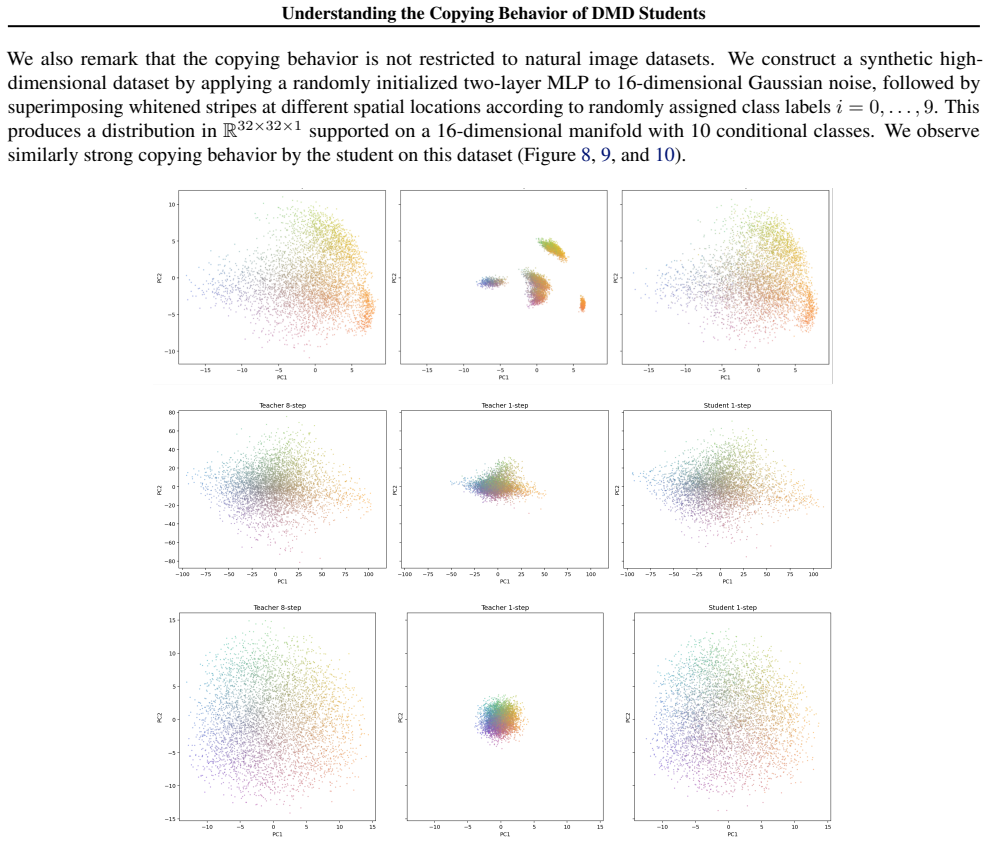
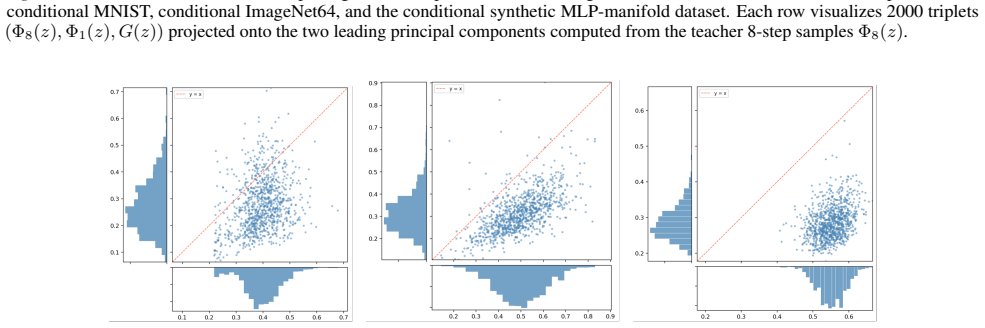
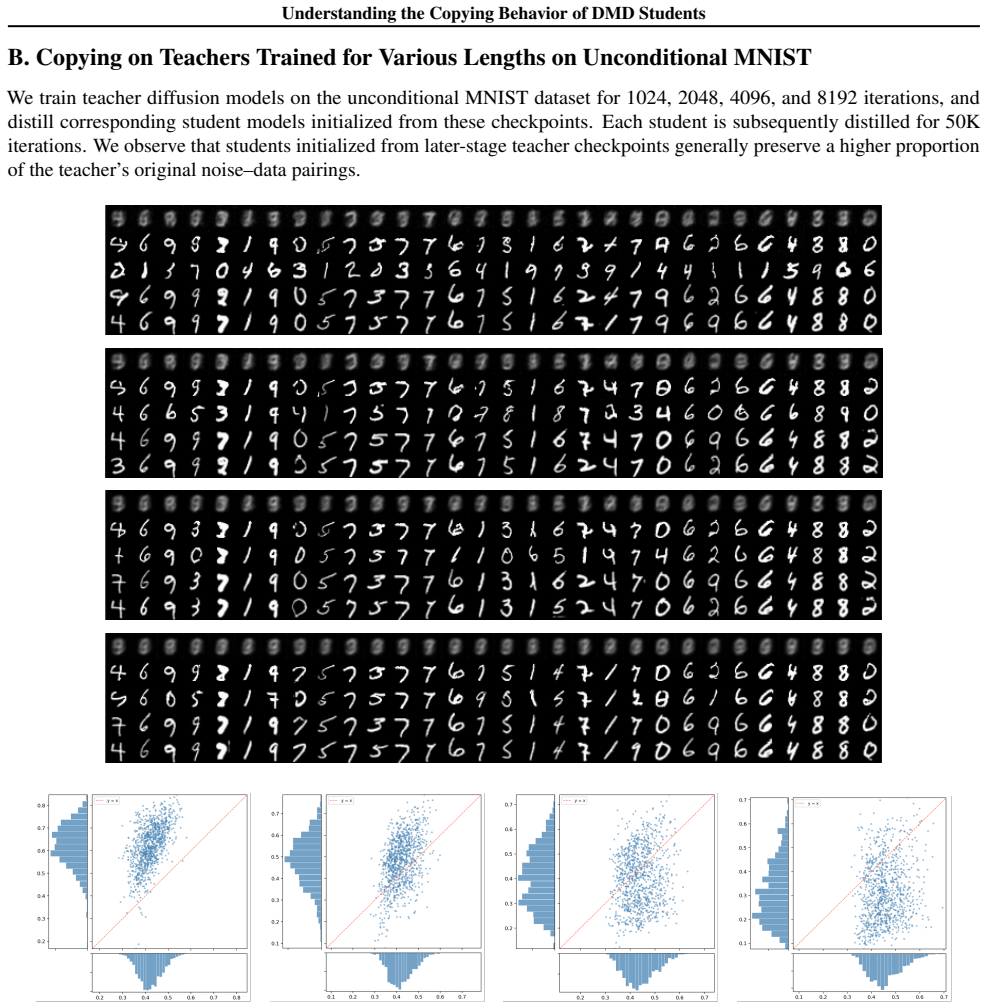
In high-dimensional settings, distilled students spontaneously reproduce the original noise-data pairings of the teacher, a phenomenon termed copying. Copying is neither a byproduct of adversarial objectives nor a result of teacher memorization. The evidence suggests copying is an emergent property arising from the limited geometric freedom of the student model during high-dimensional distillation.
What carries the argument
The limited geometric freedom of the student model, which restricts its capacity to choose noise-to-data mappings different from those of the teacher.
If this is right
- Copying appears only when the data dimension is high enough that the student cannot freely rearrange noise mappings.
- The same distillation procedure produces remapping rather than copying when the problem is low-dimensional.
- Adversarial training is not required for copying to emerge.
- Teacher memorization is not required for copying to emerge.
Where Pith is reading between the lines
- Architectures that increase the number of independent degrees of freedom in the student might reduce copying even in high dimensions.
- If copying persists across many training runs, it may limit the diversity of images the distilled model can produce compared with the teacher.
- The same geometric constraint could appear in other distribution-matching distillation methods beyond DMD.
Load-bearing premise
The observed copying is caused by the student having limited geometric freedom rather than by other unexamined parts of the training process, architecture, or data.
What would settle it
Train an otherwise identical student whose architecture or loss explicitly enlarges its effective geometric freedom in the same high-dimensional setting and check whether copying disappears.
Figures
read the original abstract
Distribution Matching Distillation (DMD) compresses pretrained diffusion models into efficient few-step generators by aligning their noised distributions across all scales. In principle, such distribution-level supervision remains agnostic to specific noise-data pairings of the teacher; this provides the student the freedom to remap latent noise, a behavior consistently observed in low-dimensional settings. Surprisingly, we find that in high-dimensional settings, distilled students spontaneously reproduce the original noise-data pairings of the teacher, a phenomenon we term copying. We demonstrate that copying is neither a byproduct of adversarial objectives nor a result of teacher memorization. Instead, our evidence suggests that copying is an emergent property arising from the limited geometric freedom of the student model during high-dimensional distillation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines Distribution Matching Distillation (DMD) of pretrained diffusion models into few-step generators. It observes that while low-dimensional settings allow students to remap latent noise, high-dimensional distillation leads to spontaneous reproduction of the teacher's original noise-data pairings, termed 'copying.' The work rules out adversarial objectives and teacher memorization as causes, instead attributing copying to an emergent property from the limited geometric freedom of the student model.
Significance. If substantiated with rigorous controls, the result would clarify an important limitation in high-dimensional few-step distillation, potentially informing architecture or objective modifications that increase student geometric freedom and reduce unwanted copying. The attempt to isolate causes by ruling out adversarial and memorization explanations is a positive step toward mechanistic understanding of distillation dynamics.
major comments (2)
- [Abstract] Abstract: the claim that 'evidence rules out adversarial objectives and teacher memorization' and points to geometric freedom is presented without any experimental details, controls, quantitative metrics, or ablation results, preventing evaluation of whether the central causal attribution holds.
- The manuscript does not isolate limited geometric freedom as the operative cause from alternative high-dimensional factors such as loss-landscape geometry, implicit regularization induced by the distillation objective, or properties of the data manifold; without such isolation the geometric-freedom account remains untested even if copying is reproducible.
minor comments (1)
- The title uses informal language ('Lazy') that may not align with the technical tone expected in the journal; consider a more descriptive title focused on the copying phenomenon.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below, providing clarifications on the experimental evidence presented in the manuscript and indicating revisions made to improve transparency.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'evidence rules out adversarial objectives and teacher memorization' and points to geometric freedom is presented without any experimental details, controls, quantitative metrics, or ablation results, preventing evaluation of whether the central causal attribution holds.
Authors: The abstract is a high-level summary; the full manuscript details the experiments in Sections 3-5. These include: (1) controls ruling out adversarial objectives via direct comparisons of DMD variants with and without adversarial terms, measuring copying rates; (2) memorization checks using data overlap metrics and out-of-distribution generalization tests showing copying persists on unseen data; (3) quantitative metrics such as noise-data pairing reproduction accuracy and dimensional scaling plots; and (4) ablations varying model capacity and dimension. We have revised the abstract to briefly reference these controls and metrics for better evaluability. revision: yes
-
Referee: The manuscript does not isolate limited geometric freedom as the operative cause from alternative high-dimensional factors such as loss-landscape geometry, implicit regularization induced by the distillation objective, or properties of the data manifold; without such isolation the geometric-freedom account remains untested even if copying is reproducible.
Authors: Our experiments focus on ruling out adversarial objectives and memorization through targeted ablations, while the geometric freedom account is supported by the sharp transition in copying behavior between low- and high-dimensional regimes under fixed objectives. We acknowledge that alternatives like loss-landscape geometry or data manifold properties are not fully isolated in the current work. We have added a discussion subsection outlining why geometric constraints are the most consistent explanation with the observed dimensional dependence, but agree that exhaustive isolation from all high-dimensional factors would require further experiments or theory. revision: partial
Circularity Check
No circularity; central claim rests on empirical disambiguation rather than self-definition or fitted inputs
full rationale
The paper presents copying as an observed phenomenon in high-dimensional DMD and offers limited geometric freedom as an emergent explanation after explicitly ruling out adversarial objectives and teacher memorization. No equations, parameter fits, self-citations, or ansatzes are shown in the abstract or described chain that would make the result equivalent to its inputs by construction. The claim is framed as arising from evidence rather than any of the enumerated circular patterns (self-definitional, fitted-input-called-prediction, self-citation load-bearing, etc.), so the derivation remains self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year=
Score-Based Generative Modeling through Stochastic Differential Equations , author=. International Conference on Learning Representations , year=
-
[2]
Advances in Neural Information Processing Systems , year=
ProlificDreamer: High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation , author=. Advances in Neural Information Processing Systems , year=
-
[3]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
One-step diffusion with distribution matching distillation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[4]
Advances in Neural Information Processing Systems , year=
Improved Distribution Matching Distillation for Fast Image Synthesis , author=. Advances in Neural Information Processing Systems , year=
-
[5]
Proceedings of the 41st International Conference on Machine Learning , pages =
The Emergence of Reproducibility and Consistency in Diffusion Models , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
-
[6]
arXiv preprint arXiv:2510.21890 , year=
The principles of diffusion models , author=. arXiv preprint arXiv:2510.21890 , year=
-
[7]
Why Diffusion Models Don
Tony Bonnaire and Rapha. Why Diffusion Models Don. Advances in Neural Information Processing Systems , year=
-
[8]
Proceedings of the 40th International Conference on Machine Learning , articleno =
Song, Yang and Dhariwal, Prafulla and Chen, Mark and Sutskever, Ilya , title =. Proceedings of the 40th International Conference on Machine Learning , articleno =. 2023 , publisher =
2023
-
[9]
Advances in Neural Information Processing Systems , year=
Mean Flows for One-step Generative Modeling , author=. Advances in Neural Information Processing Systems , year=
-
[10]
arXiv preprint arXiv:2507.16884 , year=
Splitmeanflow: Interval splitting consistency in few-step generative modeling , author=. arXiv preprint arXiv:2507.16884 , year=
-
[11]
International Conference on Learning Representations , year=
Consistency Models Made Easy , author=. International Conference on Learning Representations , year=
-
[12]
International Conference on Learning Representations , year=
Flow Matching for Generative Modeling , author=. International Conference on Learning Representations , year=
-
[13]
Advances in Neural Information Processing Systems , editor=
Elucidating the Design Space of Diffusion-Based Generative Models , author=. Advances in Neural Information Processing Systems , editor=
-
[14]
International Conference on Learning Representations , year=
Generalization in diffusion models arises from geometry-adaptive harmonic representations , author=. International Conference on Learning Representations , year=
-
[15]
Advances in Neural Information Processing Systems , year=
Understanding generalizability of diffusion models requires rethinking the hidden gaussian structure , author=. Advances in Neural Information Processing Systems , year=
-
[16]
Transactions on Machine Learning Research , issn=
Convergence of denoising diffusion models under the manifold hypothesis , author=. Transactions on Machine Learning Research , issn=
-
[17]
Proceedings of Thirty Eighth Conference on Learning Theory , pages =
Linear Convergence of Diffusion Models Under the Manifold Hypothesis , author =. Proceedings of Thirty Eighth Conference on Learning Theory , pages =. 2025 , editor =
2025
-
[18]
Advances in Neural Information Processing Systems , year=
Score-based generative models detect manifolds , author=. Advances in Neural Information Processing Systems , year=
-
[19]
arXiv preprint arXiv:2411.04100 , year=
Manifold diffusion geometry: Curvature, tangent spaces, and dimension , author=. arXiv preprint arXiv:2411.04100 , year=
-
[20]
Transactions on Machine Learning Research , issn=
Deep Generative Models through the Lens of the Manifold Hypothesis: A Survey and New Connections , author=. Transactions on Machine Learning Research , issn=
-
[21]
International Conference on Learning Representations , year=
Carr\'e du champ flow matching: better quality-generalisation tradeoff in generative models , author=. International Conference on Learning Representations , year=
-
[22]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Diff-Instruct: A Universal Approach for Transferring Knowledge From Pre-trained Diffusion Models , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[23]
International Conference on Learning Representations , year=
Progressive distillation for fast sampling of diffusion models , author=. International Conference on Learning Representations , year=
-
[24]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[25]
arXiv preprint arXiv:2210.02303 , year=
Imagen video: High definition video generation with diffusion models , author=. arXiv preprint arXiv:2210.02303 , year=
-
[26]
Advances in Neural Information Processing Systems , year=
Denoising diffusion probabilistic models , author=. Advances in Neural Information Processing Systems , year=
-
[27]
International Conference on Learning Representations , year=
Denoising Diffusion Implicit Models , author=. International Conference on Learning Representations , year=
-
[28]
Diffusion Models Beat
Prafulla Dhariwal and Alexander Quinn Nichol , booktitle=. Diffusion Models Beat
-
[29]
International Conference on Learning Representations , year=
Generalization of Diffusion Models Arises with a Balanced Representation Space , author=. International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.