Coordination Graphs for Constrained Multi-Agent Reinforcement Learning
Pith reviewed 2026-06-28 14:33 UTC · model grok-4.3
The pith
Coordination graphs with Lagrangian duality decompose constrained multi-agent RL into pairwise shared Q-functions whose count stays fixed as teams grow.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
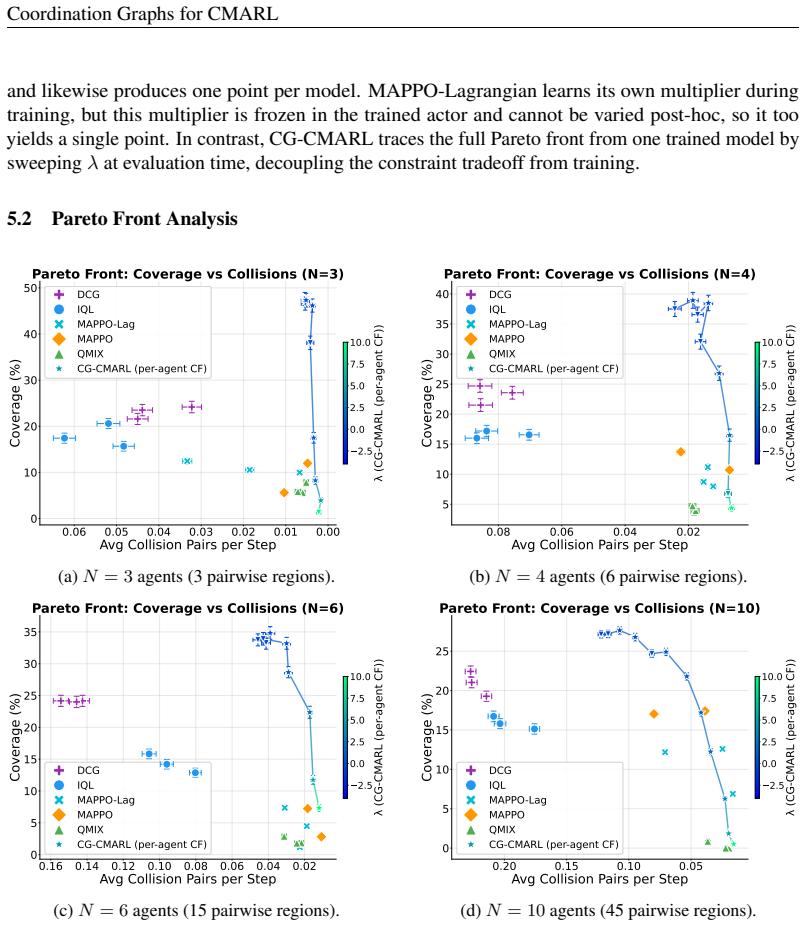
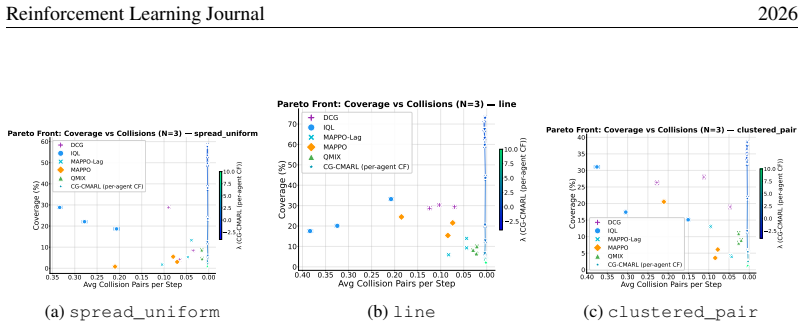
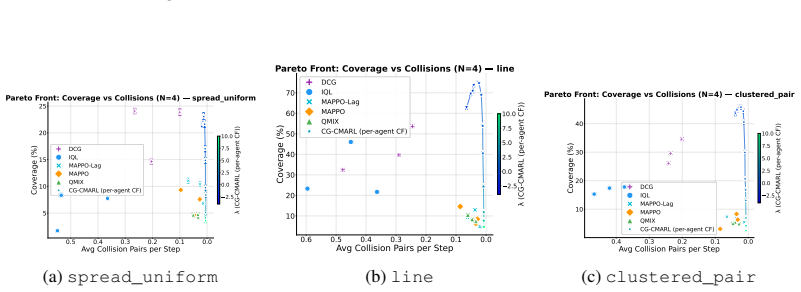
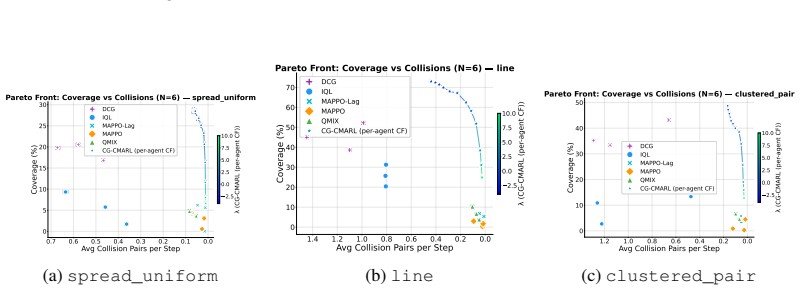
The joint constrained problem can be decomposed into pairwise regions each served by a set of shared Q-functions, one for the primary objective and one for each of the constraints, so that the number of learned models is independent of the number of agents. At execution time, Max-Sum message passing coordinates actions across the factor graph, while a Lagrangian multiplier controls the objective-constraint tradeoff, allowing a single trained model to trace a Pareto front without retraining. Convergence guarantees hold under mild conditions together with a compositional error bound that decomposes into separate interpretable sources.
What carries the argument
Coordination Graphs for Constrained Multi-Agent Reinforcement Learning (CG-CMARL) that factors the problem into pairwise regions served by shared objective and constraint Q-functions, coordinated by Max-Sum message passing and controlled by Lagrangian multipliers.
If this is right
- A single trained model traces an entire Pareto front by varying the Lagrangian multiplier at execution time.
- The number of Q-functions remains constant as the number of agents increases, enabling scaling beyond centralized methods.
- Pareto fronts produced by the method dominate those of baselines trained at fixed reward-shaping ratios.
- Convergence is guaranteed under mild conditions and the error bound separates into independently controllable sources.
- The approach applies to cooperative navigation tasks requiring up to ten agents to satisfy pairwise constraints.
Where Pith is reading between the lines
- The same pairwise decomposition could be tested on constraint types that are not strictly pairwise to measure how much coupling is lost.
- The fixed model size suggests the method could support dynamic addition or removal of agents without retraining the full set of functions.
- Because the error bound is compositional, targeted improvements to message passing or multiplier tuning could be evaluated separately.
Load-bearing premise
The joint constrained problem can be decomposed into pairwise regions each served by a set of shared Q-functions without losing the ability to capture the full constraint couplings between agents.
What would settle it
A navigation task with three or more agents where the pairwise decomposition produces constraint violations that a centralized solver satisfies at the same objective level.
Figures
read the original abstract
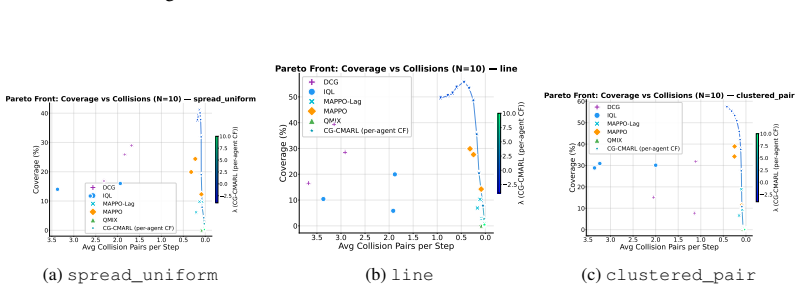
Constrained Multi-agent reinforcement learning (CMARL) faces two intertwined challenges: the joint action space grows exponentially with the number of agents, and additional requirements couple agents in ways that reward structure alone does not capture. We introduce Coordination Graphs for Constrained Multi-Agent Reinforcement Learning (CG-CMARL), a framework that addresses both challenges by combining coordination graphs with Lagrangian duality. The system decomposes the joint problem into pairwise regions, each served by a set of shared Q-functions, one for the primary objective and one for each of the constraints, so that the number of learned models is independent of the number of agents. At execution time, Max-Sum message passing coordinates actions across the factor graph, while a Lagrangian multiplier controls the objective--constraint tradeoff, allowing a single trained model to trace a Pareto front without retraining. We provide convergence guarantees under mild conditions, together with a compositional error bound that decomposes into separate interpretable sources, each traceable to a specific design choice and independently controllable. Experiments on cooperative navigation tasks (where teams of up to 10 agents must coordinate to reach target positions while satisfying pairwise constraints) show that our method produces Pareto fronts dominating established baselines trained at fixed reward-shaping ratios, while scaling to team sizes where centralized approaches become intractable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CG-CMARL, a framework that combines coordination graphs with Lagrangian duality for constrained multi-agent reinforcement learning. The joint constrained problem is decomposed into pairwise regions, each served by shared Q-functions (one per objective and per constraint), keeping the number of models independent of team size. Max-Sum message passing coordinates actions at execution time while a Lagrangian multiplier traces the objective-constraint tradeoff with a single trained model. Convergence guarantees are stated under mild conditions together with a compositional error bound; experiments on cooperative navigation tasks with up to 10 agents report Pareto fronts that dominate baselines trained at fixed reward-shaping ratios and scale beyond centralized methods.
Significance. If the pairwise decomposition preserves all relevant constraint couplings, the approach would meaningfully advance scalable CMARL by enabling larger teams and single-model Pareto exploration. The provision of convergence guarantees and a compositional error bound (decomposable into traceable sources) strengthens the contribution beyond purely empirical methods. Experimental dominance over fixed-ratio baselines on navigation tasks with explicit pairwise constraints is a concrete strength.
major comments (2)
- [Abstract and §3] Abstract and §3 (method): the central construction decomposes the joint constrained problem into pairwise regions with shared per-constraint Q-functions and Max-Sum coordination. When a constraint couples three or more agents simultaneously, this factorization plus shared Q-functions cannot represent the full joint feasible set, so the Lagrangian update optimizes an inexact relaxation. The reported experiments use only explicitly pairwise constraints and therefore do not probe this case, leaving the general claim about capturing “full constraint couplings” unsupported.
- [Abstract] Abstract: convergence guarantees are asserted “under mild conditions” and a compositional error bound is claimed, yet neither the precise conditions nor the decomposition of the bound into controllable sources are stated. Without these details the theoretical claims cannot be evaluated for restrictiveness or practical utility.
minor comments (2)
- [Abstract] Abstract: error-bar reporting, exact baseline implementations, and the precise reward-shaping ratios used for comparison are not specified, reducing reproducibility of the Pareto-front dominance claim.
- Notation: the distinction between the shared Q-functions for the primary objective versus each constraint should be made explicit in the first appearance of the factor-graph construction to avoid reader confusion.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, proposing targeted revisions for clarity while preserving the manuscript's claims.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): the central construction decomposes the joint constrained problem into pairwise regions with shared per-constraint Q-functions and Max-Sum coordination. When a constraint couples three or more agents simultaneously, this factorization plus shared Q-functions cannot represent the full joint feasible set, so the Lagrangian update optimizes an inexact relaxation. The reported experiments use only explicitly pairwise constraints and therefore do not probe this case, leaving the general claim about capturing “full constraint couplings” unsupported.
Authors: We agree that the pairwise factorization yields an exact representation only when all constraints admit a pairwise decomposition; higher-order couplings would result in an inexact relaxation. The manuscript and experiments are explicitly restricted to pairwise constraints (as stated in the experimental setup on cooperative navigation). The abstract does not assert capture of arbitrary higher-order couplings. We will revise the abstract and §3 to state the scope limitation explicitly and note that extension to higher-order factors would require additional graph factorization. revision: yes
-
Referee: [Abstract] Abstract: convergence guarantees are asserted “under mild conditions” and a compositional error bound is claimed, yet neither the precise conditions nor the decomposition of the bound into controllable sources are stated. Without these details the theoretical claims cannot be evaluated for restrictiveness or practical utility.
Authors: Section 4 provides the convergence result under standard MDP assumptions (finite spaces, appropriate step sizes, and coordination-graph compatibility with Max-Sum) together with the error bound decomposed into approximation, message-passing, and Lagrangian terms. To allow evaluation from the abstract alone, we will add one sentence summarizing the mild conditions and the traceable sources of the bound. revision: yes
Circularity Check
No circularity: derivation relies on independent decomposition and bounds
full rationale
The paper's core construction decomposes the constrained joint problem via coordination graphs and shared per-constraint Q-functions, then applies Max-Sum and Lagrangian updates. Convergence guarantees and the compositional error bound are presented as holding under stated mild conditions without any reduction to fitted parameters, self-citations, or ansatzes imported from prior author work. No step equates a claimed prediction or theorem to its own inputs by construction; the Pareto-front and scalability claims rest on the framework plus external experiments rather than self-referential definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Convergence guarantees hold under mild conditions
Reference graph
Works this paper leans on
-
[1]
Leopoldo Agorio, Sean Van Alen, Santiago Paternain, Miguel Calvo-Fullana, and Juan Andres Baz- erque. Cooperative multi-agent assignment over stochastic graphs via constrained reinforcement learning.arXiv preprint arXiv:2502.20462,
-
[2]
DOI: 10.1016/S0167-6911(97)90015-3. Vivek S. Borkar. An actor-critic algorithm for constrained markov decision processes.Systems & Control Letters, 54(3):207–213,
-
[3]
CUTMAP: Con- straining an unconstrained multi-agent policy with offline data.Neural Networks, 186:107253,
Reinforcement Learning Journal 2026 Cong Guan, Tao Jiang, Yi-Chen Li, Zongzhang Zhang, Lei Yuan, and Yang Yu. CUTMAP: Con- straining an unconstrained multi-agent policy with offline data.Neural Networks, 186:107253,
2026
-
[4]
Nikunj Gupta, James Zachary Hare, Jesse Milzman, Rajgopal Kannan, and Viktor Prasanna. Deep meta coordination graphs for multi-agent reinforcement learning.arXiv preprint arXiv:2502.04028,
-
[5]
A survey of safe reinforcement learning and constrained MDPs.arXiv preprint arXiv:2505.17342,
Ankita Kushwaha, Kiran Ravish, Preeti Lamba, and Pawan Kumar. A survey of safe reinforcement learning and constrained MDPs.arXiv preprint arXiv:2505.17342,
-
[6]
Ruohong Liu, Yuxin Pan, Linjie Xu, Lei Song, Pengcheng You, Yize Chen, and Jiang Bian. C-morl: Multi-objective reinforcement learning through efficient discovery of pareto front.arXiv preprint arXiv:2410.02236,
-
[7]
Human-level control through deep reinforcement learning.Nature, 518(7540):529–533, 2015
DOI: 10.1038/nature14236. Kevin P Murphy, Yair Weiss, and Michael I Jordan. Loopy belief propagation for approximate inference: An empirical study. InUAI, pp. 467–475,
-
[8]
Leibo, Karl Tuyls, and Thore Graepel
Peter Sunehag, Guy Lever, Audrunas Gruslys, Wojciech Marian Czarnecki, Vinicius Zambaldi, Max Jaderberg, Marc Lanctot, Nicolas Sonnerat, Joel Z. Leibo, Karl Tuyls, and Thore Graepel. Value- decomposition networks for cooperative multi-agent learning based on team reward. InProceedings of the 17th International Conference on Autonomous Agents and MultiAgen...
2085
-
[9]
URLhttps://dl.acm.org/doi/10.5555/3237383.3238080
International Foundation for Autonomous Agents and Multiagent Systems. URLhttps://dl.acm.org/doi/10.5555/3237383.3238080. Jordan Terry, Benjamin Black, Nathaniel Grammel, Mario Jayakumar, Ananth Hari, Ryan Sullivan, Luis S Santos, Clemens Dieffendahl, Caroline Horsch, Rodrigo Perez-Vicente, et al. Pettingzoo: Gym for multi-agent reinforcement learning.Adv...
-
[10]
7 Notation and Definitions This appendix provides a comprehensive reference for the notation, definitions, and assumptions used throughout the paper
Reinforcement Learning Journal 2026 Supplementary Materials The following content was not necessarily subject to peer review. 7 Notation and Definitions This appendix provides a comprehensive reference for the notation, definitions, and assumptions used throughout the paper. 7.1 Notation Summary Tables 2–7 collect the notation used in this paper, organize...
2026
-
[11]
Coordinated Exploration.During training, Gaussian noise scaled by the current exploration rate ϵt is added to the augmented Q-tablesbeforemessage passing begins
and ensures that messages evolve smoothly across iterations. Coordinated Exploration.During training, Gaussian noise scaled by the current exploration rate ϵt is added to the augmented Q-tablesbeforemessage passing begins. That is, all agents reason about the same perturbed utilities during Max-Sum, preserving coordination structure. This contrasts with ϵ...
2001
-
[12]
To mitigate this, we use parallel episode collection with 4–8 workers, each running independent environment instances and contributing transitions to the shared replay buffer
pairwise regions. To mitigate this, we use parallel episode collection with 4–8 workers, each running independent environment instances and contributing transitions to the shared replay buffer. 9 Proofs This appendix contains complete proofs of all theoretical results. Section 9.1 proves Q-learning convergence (Theorem 4.1). Section 9.2 proves primal-dual...
2026
-
[13]
quasi-static
−ρ diverges for ρ≤1 andP t(t+ 1)−2ρ converges forρ >0.5 . Property (iii) holds because ηk/αkH = (η0/α0)·(kH+1) ρα /(k+1) ρη, which tends to zero when ρη > ρ α (the episode index k grows slower than the step index t= kH). In practice, CG-CMARL uses a fixed dual learning rate η with per-episode updates and a decaying Q-learning rate, which achieves the requ...
2008
-
[14]
The dual function isd(λ) := max π L(π, λ), and a subgradient ofdatλis g(λ) =V πλ 1 (s0)− c1 1−γ
is L(π, λ) =V π 0 (s0) +λ V π 1 (s0)− c1 1−γ . The dual function isd(λ) := max π L(π, λ), and a subgradient ofdatλis g(λ) =V πλ 1 (s0)− c1 1−γ . Comparing with (25), the multiplier update performs projected subgradient descent on d(λ) (up to the(1−γ)scaling, which affects the rate but not the fixed point). Step 4: Convergence. By Assumption (A3) (Slater’s...
2015
-
[15]
coordination gap
Part (b): Overlapping regions. When regions overlap—that is, some agent i belongs to multiple regions—the joint max doesnot decompose in general. To see why, consider agent i belonging to regions R and R′. The action a′i appears in both QR(s′R, a′R) and QR′(s′R′ , a′R′ ). Optimizing a′i for QR alone may differ from optimizing it forQ R +Q R′ jointly. Henc...
2026
-
[16]
Coordination Graphs for CMARL Table 11: Scaling of problem dimensions withNagents. N|C R| |o R| |A| N Status 3 3 161.6×10 4 Tractable (brute force) 4 6 183.9×10 5 Tractable (brute force) 6 15 222.4×10 8 Intractable centrally 10 45 309.5×10 13 Intractable centrally 10.2 Reward and Constraint Decomposition 10.2.1 Primary Reward: Per-Agent Counterfactual Rew...
2001
-
[17]
Sparser graphs (pairwise or tree-structured): larger β but faster action selection and simpler mes- sage passing (Kcan be smaller;ϵ MS = 0for trees)
Practical Guidance.The choice of coordination graph involves a tractability–accuracy tradeoff: Richer graphs (larger regions, more hyperedges): smaller β, but larger per-region action spaces and denser factor graphs (slower Max-Sum, more parameters). Sparser graphs (pairwise or tree-structured): larger β but faster action selection and simpler mes- sage p...
2026
-
[18]
total safety burden on the system
than at N= 10 (where the maximum is 45). This means cross-Ncomparisons using the raw value understate how well the algorithm scales. To disentangle “total safety burden on the system” from “per-pair safety,” Tables 15–16 report both the raw metric and a normalizedper-pairrate defined as per-pair rate:= CollisionsN 2 .(33) The per-pair rate admits a clean ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.